{kind=link}
社会化网络中信任推荐研究综述
[谭学清, 黄翠翠 , 罗琳]
, 罗琳]
, 罗琳]
|
|


作者贡献声明:
谭学清:对重要的学术内容进行关键性补充修改, 负责论文最后审阅及定稿;
黄翠翠:设计构思论文, 收集、整理、分析相关文献, 撰写论文初稿;
罗琳:提出论文研究思路, 设计研究方案及相关的修改工作。
【目的】探讨社会化网络的发展对解决传统的个性化推荐系统面临的诸如数据稀疏性、冷启动等问题的作用。【文献范围】以社会化网络作为分析背景, 从Springer、Google Scholar检索2004年至今国内外关于信任推荐的研究文献。【方法】基于信任与不信任两方面对相关文献进行梳理总结, 形成综述。【结果】指出当前研究中存在信任计算方法不足, 缺乏对不信任因素的深入研究等问题。【局限】由于研究因素单一, 应结合社会化网络中出现的其他因素进行深入对比分析。【结论】未来的研究可以从基于情境信任的推荐、挖掘社会化网络中的弱连接关系等方向开展。
[Objective] Discuss the role of social networks to solve problems such as data sparseness and cold start of traditional personalized recommendation systems. [Coverage] This paper retrieves research literatures about trust recommendation at home and abroad from Springer and Google Scholar since 2004.[Methods] It summarizes the related literatures from perspectives of trust and distrust.[Results] Based on the summary, this paper demonstrates the existing problems such as the deficiency of calculation method for trust and lack of in-depth study of distrust and so on. [Limitations] Other factors in social networks should be combined with trust in an in-depth comparative analysis.[Conclusions] Context-aware trust recommendation, mining the value of weak relationship in social networks can be new valuable research directions in future.
21世纪是一个信息爆炸的时代, 人们迷失在信息的海洋里, 很难找到自己真正感兴趣以及适合自己的信息。为了缓解这种现象, 推荐系统应运而生。传统的推荐系统可以分为:基于内容的推荐系统、协同过滤推荐系统、基于知识的推荐系统以及混合推荐系统[1]。虽然传统的推荐系统一定程度上解决了信息冗余的问题, 但是个性化推荐仍存在诸如冷启动、数据稀疏性等问题, 社会化网络的发展给该研究带来了新的契机。
在社会化网站中, 每一个用户都可以参与创造、传播、分享信息。社交媒体的日益普及极大地丰富了人们与家人、朋友以及同事之间的社交活动, 因而产生了丰富多样的社交关系, 例如Facebook中的好友关系, Twitter中的追随关系以及Epinions中的信任关系。人们借助社交关系与朋友分享彼此的观点和看法, 过滤海量信息。于是, 研究者开始挖掘社交网络中出现的有价值的信息技术和模式, 将其运用到推荐过程中。在社会化推荐研究中, 信任因素备受关注。一方面, 在如今这个信任匮乏的时代, 人们越来越珍惜彼此的信任, 彼此之间的感情需要信任来维系。另一方面, 科学网研究结果显示:与家庭成员相比, 朋友会对人的行为和发展产生更深远的影响[2], 朋友间的信任关系对提高推荐系统的性能有非常重要的作用[3]。本文主要以信任推荐为研究点, 整理和分析目前关于信任研究的相关文献, 在此基础上形成综述。
在数字化媒体时代的今天, 人们将现实社会的关系移植于互联网上, 个人社会关系网络主要分为强关系网络(例如QQ、微信)和弱关系网络(例如新浪微博、论坛), 人们依据这两类社交关系实现网络互动。通常强联结关系的网络成员相互之间的关心程度高, 更愿意毫无保留地分享其观点和经验, 而弱联结关系则相反。实证研究结果发现, 用户之间关系强度越高, 彼此之间更加信任[4]。
根据Mui等对信任的定义, 信任是一个主体根据与另外一个主体的历史交互经验, 而对其未来行为决策的主观期望[5]。一个拥有内置推荐机制的Web应用程序首先通过社交网络组件促使其中的用户形成一个信任网络, 组合用户配置文件(评分信息)与来自用户信任网络的信任信息, 最后产生个性化的推荐结果, 这就是所谓的基于信任的推荐系统。其工作原理如图1所示:
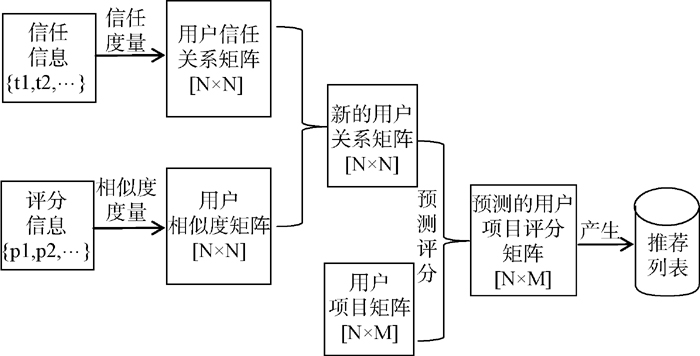 | 图1 基于信任的推荐系统工作原理 |
在社交网络时代, 用户很容易建立自己的信任网络。通过信任网络发现用户信任的朋友集合要比找到与目标用户相似的用户集合容易, 而且数量更多[6], 将信任信息加入到推荐过程中则可以有效地解决传统的推荐系统面临的问题。笔者将协同过滤推荐与基于信任的推荐进行了比较, 如表1所示:
| 表1 协同过滤推荐与基于信任的推荐比较 |
早期的基于信任的推荐只考虑信任因素, 而Massa等论述了不信任因素对于推荐系统的有效性[7]。本文将从基于信任的推荐和基于信任-不信任推荐两个方面阐述。
对信任的度量有很多种方法, 早期主要采用二分数值法表示, 用数字1表示信任, 数字0表示不信任。这种表示方法过于粗糙, 特别是不适用于信任的传播计算。另外一种表示方法则使用0到1之间的一组表示程度级别的数字来度量用户之间的信任程度, 数值由高到低依次表示为:非常信任-信任-不信任-非常不信任。
在将信任运用于个性化推荐中并进行推荐建模时, 信任的度量一般采用第二种表示方法— — 使用0到1之间的数字表示。将信任值作为推荐用户的推荐权重, 并运用信任的传播和聚合规则计算非相邻用户之间的信任值。目标用户对推荐用户的信任值越高, 则推荐用户给出的推荐结果所获得的权重越大[8]。这种信任推荐建模方法在研究中被广泛采纳, 有助于提高推荐的准确率。
(1) 基于显性信任的推荐
基于显性信任的推荐利用用户与邻居的显性信任关系, 根据信任邻居对项目的偏好来预测目标用户偏好。一些典型的基于显性信任推荐方法的应用实例有:滑雪登山社区网站Moleskiing[9]、电子商务商品推荐网站Epinions[10]、电影推荐网站FilmTrust[11]等。
在显性信任网络中, 最关键的是计算信任网络中非相邻用户节点之间的信任值, 运用信任的传播与聚合规则。比较著名的信任计算模型有Golbeck提出的TidalTrust模型[12], 以及Massa等提出的MoleTrust模型[13]。Papagelis等在信任传播路径选择过程中引入个体信任主观属性(可信度和不确定性)[14]。Jø sang等将主观逻辑概念运用于信任估算过程中[15]。在国内, 针对信任的传播可能会来自多条路径, 研究者提出不同的路径融合算法, 曾赛提出基于概率的信任计算方法对串联、并联路径的信任值进行计算[16], Zhang等提出多路径(串行、并行、重叠)推荐信任计算方法[17]。
Golbeck和Massa等提出的依据信任传播理论计算信任值的方法给研究者带来很大的启发, 后续的研究也多是在此基础上的改进。然而对于如何从多条信任传播路径中筛选出最优的路径, 还是需要深入研究。另一方面所谓的信任传递性规则通常假设信任可以传递。但是信任的传递是有条件的, 信任传递计算必须在用户感兴趣的领域进行, 这样得到的推荐结果才具有实用价值。
(2) 基于隐性信任的推荐
在隐性信任网络中, 信任的形成依据系统用户的历史交易行为。Yuan等提出以用户相似度来表示隐性的信任关系[18]。Martin-Vicente等基于领域运用语义知识自动形成用户间的隐性信任关系[19]。基于隐性信任的推荐就是利用隐性信任关系, 将信任邻居喜爱的项目推荐给目标用户, 例如eBay的基于声誉的推荐系统[20]。
目前最著名的隐性信任度的计算方法是O’ Donovan等提出的全局信任度量模型, 即依据历史记录中正确推荐的次数来评估信任值[21]。O’ Donovan等介绍了两种信任度量模式:用户级别信任和用户-项目级别信任, 分别表示特定用户的全局信任度和用户对特定项目的全局信任度。Lumbreras等基于用户之间的交互关系提出MarkovTrust模型来评估信任值, 并抓取Twitter网站上的数据验证模型的有效性[22]。Ziegler等借鉴社会心理学扩散激活模型中的相关理论和方法提出Appleseed信任度量模型[23]。
早期的研究利用传统的相似性值来计算用户之间的信任值, Ziegler等使用电影和书籍的推荐数据验证了信任和相似度存在正相关关系[24], 也有研究表明相似用户集合与社交关系用户集合并没有很大的重叠[25], 因而需要更深一步划分这两类关系用户。另外, O’ Donovan等提出全局信任度量模型在度量信任时并没有考虑个体之间的差异, Golbeck也指出全局信任值并不适用于推荐。
(3) 基于信任的评分预测方法
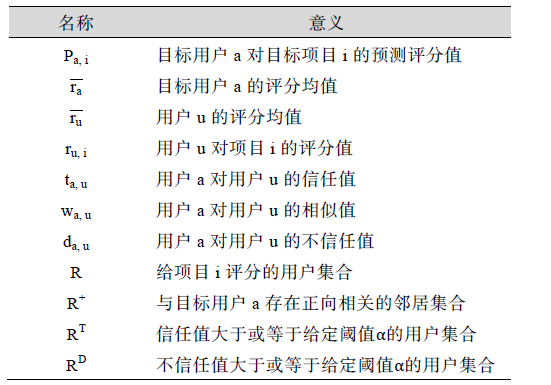
如何将信任值运用于预测评分是推荐系统的关键, 以下介绍几种预测模型。为便于阅读, 表2列举了算法中的字母符号及其含义。
|
|
表2 算法中出现的字母符号及其对应的含义 |
① Golbeck等提出的Trust-based Weighted Mean方法, 目标用户高度信任的邻居用户获得更高的评分权重[12]。
定义1:Trust-based Weighted Mean
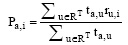
② Massa等提出的Trust-based Collaborative Filtering方法, 采纳传统的协同过滤推荐模式, 以用户之间的信任值作为权重系数[13]。
定义2:Trust-based Collaborative Filtering
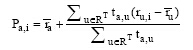
③ O’ Donovan等提出的Trust-based Filtering方法, 信任值作为一种过滤手段, 只有目标用户信任的邻居用户才能参与推荐[21]。
定义3:Trust-based Filtering
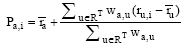
④ Victor等提出的EnsembleTrustCF方法, 由于完全基于信任的评分预测方法, 在某些情况下准确率和覆盖率并非最优, 该模型充分利用基于信任的推荐算法和协同过滤推荐算法各自的优点[26]。
定义4:EnsembleTrustCF

实验表明EnsembleTrustCF算法具有更高的性能, 这种混合采纳思想被后续的研究者借鉴。例如Jamali等在信任网络里, 通过图随机游走算法, 获取目标用户与朋友用户对目标项目以及相似项目的评分信息, 最后预测项目评分[27]。Birtolo等借鉴Burke提出的权重分配模型[28], 采用加权线性组合信任值和相似度的协同过滤模式来预测评分[29]。
将信任值运用于推荐系统中的研究已经成为热点, 但是单一的信任机制不能全面地考虑现实的社会关系, 有些学者认为引入不信任因子, 可以提高推荐系统的精确度。目前将不信任因素运用于推荐中的方式主要有利用不信任值过滤不信任的用户集合或者是将不信任值作为负向权重值[30]。下面详细介绍Victor等提出几种不同的基于不信任的推荐算法[26]。
① 采纳O’ Donovan提出的基于信任的过滤算法思想, Victor等同样提出基于不信任过滤算法。
定义5:Distrust-based Filtering
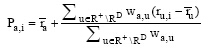
② 在信任的传播过程中会存在这种情况:a完全信任b, b完全信任c, 依据信任的传递性可以得到a信任c, 但是如果实际上a完全不信任c, 这就会产生矛盾。为解决这种矛盾, 有研究者提出运用不信任因素作为调节器, 来防止这种错误的推论[23, 31]。
定义6:Debugged Trust-based Weighted Mean

定义7:Debugged Trust-based Collaborative Filtering
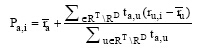
③ 修正上述提到的EnsembleTrustCF算法:对于存在于信任集合而不存于不信任集合的用户, 使用信任值来调节评分权重; 对于与目标用户a存在正相关但是既不属于信任集合又不属于不信任集合的用户, 用皮尔逊相似性值来调节评分信息权重。
定义8:Debugged EnsembleTrustCF

④ 借鉴Golbeck等的思想, 使用信任值作为邻居用户的权重, 同时作为阈值过滤邻居用户, 信任程度的表示由两部分组成:信任值和不信任值。
定义9:Trust Score-based Weighted Mean

⑤ 将不信任值直接作为一种负向的权重值运用于推荐算法中。
定义10:Distrust-based Collaborative Filtering
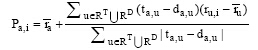
国外对基于信任-不信任的推荐研究起步较早, Guha等首次在信任的传播过程中考虑了不信任因素的影响[31], Ziegler等在其提出的Appleseed信任度量模型中引入了不信任因素[23], Victor等通过实验验证了不信任因素对于推荐的效用[32], 并在之后的研究中提出几种基于不信任的推荐策略。在国内, Yuan等基于信任评分空间并保留了信任来源因素, 在信任关系形成中区分部分信任、部分不信任、部分忽视和部分不一致相关概念[33]。韩丽根据信任传播与聚合规则得到的信任和不信任集合对用户进行筛选, 并结合用户之间的兴趣相似度算法实现推荐[34]。
在社会化推荐中消极的关系比积极的关系更加重要[35], 不信任在一定程度上也表示不相似, 在信任的推荐中引入不信任因素的考量是一个比较重大的突破, 挖掘不信任因素对推荐研究具有重要的价值, 尤其是综合考虑信任和不信任因素可以提高推荐系统的准确性, 这方面还需进一步深入研究。
现阶段信任计算是基于信任的传递性, 然而信任传递必须在用户关注的领域进行。虽然Liu提出不同朋友在不同情境下对同一项目有不同的推荐, 即考虑情境会影响信任值[36]; 而且Wang等提出了情境相似性概念[37]。但是, 还需考虑如何有效划分情境以及相应的信任值计算。此外, 用户对邻居用户的信任值会随着时间改变或者因为某一次推荐结果而变化, 这也需要考虑。
在信任推荐中, 用户信任好友的推荐建议固然重要, 但作为唯一的因素考虑可能就有些片面。Victor等提出社交网络三类值得信任的人物:专家、社交达人(拥有很多连接关系的人)、频繁评分者, 并通过Epinions数据集证明这三类关键人物在不影响推荐系统准确率的前提下能够显著提高推荐系统的覆盖率[38, 39]。然而, 只考虑社交网络中类似信任这种强依赖关系, 虽然得到的推荐结果会更符合用户的喜好, 却不利于发掘用户兴趣的多样性[40]。实际上, 弱依赖关系可以为发掘用户的潜在兴趣提供重要的情境信息。
虽然有很多研究指出对不信任概念模型的挖掘有重要的价值, 但是综合考虑信任和不信任因素的研究还很少。此外现阶段的研究中, 不信任值都是通过显性的方式获取。针对如何有效地衡量用户之间的不信任值的研究还比较少。在度量信任和不信任程度时, Ginsberg提出的Bilattices模型有效地区分了完全不信任(0, 1)和完全不知道(0, 0), 以及完全信任(1, 0)和意见不一致(1, 1), 需在之后的研究中注意[41]。
传统的推荐系统根据与目标用户最相似的用户集合的评分数据来预测评分, 但是社交网络的异构性导致了用户关系的异构性, 也有研究表明相似用户集合与社交关系用户集合并没有很大的重叠[25]。从信任与相似性角度考虑, 用户可以被划分为4类:相互信任但不相似的用户; 相互信任又相似的用户; 相互不信任但相似的用户; 既不信任又不相似的用户。不同类别的用户对推荐的作用不同, 例如信任值可以提高对冷启动用户推荐的准确性, 相似性又可以提高推荐的覆盖率。故而应该对用户关系进行细分, 让不同类别的用户发挥不同的作用。
基于信任的推荐主要的问题之一是缺少包含信任和不信任描述和评分的数据集。CouchSurfing数据集包含多种信任和不信任的陈述, 但是缺少足够的评分信息。Epinions网站上的数据仅用1、0来区分信任和不信任, 也无法运用于信任的传播和聚合研究。有学者提出运用像Facebook和LinkedIn中的社交数据、电子邮件交互数据或声誉系统中用户之间的信任关系数据。另外, 一个用户通常会在多种社交网站上注册账号, 如果可以整合不同社区的信息, 不仅可以节省时间还可以解决冷启动问题, 但用户信息匹配仍需注意[42]。
本文归纳总结了基于信任的推荐研究现状, 并分析了当前的研究中出现的不足。未来信任推荐研究的可以从以下5个方向开展:
(1) 针对人们对情境感知的需求日增, 基于情境信任的推荐也会是一个很重要的课题, 需要考虑情境如何划分以及基于情境的信任值如何计算。
(2) 对不信任因素的深入研究, 包括如何设计算法度量用户之间的不信任程度, 以及挖掘不信任值作为过滤不信任用户集合以外的其他作用。
(3) 发现社交网络中的关键人物, 并将其不同影响力运用于推荐算法中。
(4) 怎样将基于信任的推荐运用于人们的生活中?针对不同的领域, 信任推荐的应用会有什么差异?
(5) 挖掘社交网络中除了信任因素以外的其他因素应用于推荐, 例如弱联结关系可以应用于深度挖掘用户的兴趣, 增加推荐结果的多样性。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|