

{kind=link}
{kind=link}
{kind=link}
结合内容和标签的Web文本聚类研究
[顾晓雪, 章成志 ]
]
]
|
|


作者贡献声明:
顾晓雪:设计研究方案, 实验设计与实施, 数据清洗与分析, 论文起草;
章成志:提出研究思路, 设计研究方案, 数据采集及分析, 论文最终版本修订。
【目的】探索社会标签与文本内容的结合对文本聚类的影响。【方法】采用Engadget中英文博客数据, 使用TF×IDF、TextRank、TextRank×IDF三种特征抽取方法, 线性函数和Sigmod函数进行相似度加权, AP算法进行聚类。【结果】结果表明, TF×IDF的聚类效果最好, 两种加权对英文博文聚类有不同程度的改善, 但在中文博文聚类中, Sigmod加权结果稍有下降, 线性加权比Sigmoid加权方法效果更好。【局限】没有找出标签相似度与内容相似度最佳的权重系数。AP聚类算法不能应用于大数据, 聚簇过多影响聚类结果的展示。【结论】社会标签与文本内容相似度的线性加权能改善Web文本聚类结果。
[Objective] This paper explores the infulence of the combination of social tagging and text content.[Methods] In this paper, taking the English and Chinese blogs for example, using TF×IDF, TextRank and TextRank×IDF as text feature extraction method, basing on tags combining with text content where two types weighted methods is used, and AP clustering algorithm is used to cluster samples.[Results] The results show that
随着Web2.0时代的推进, 网络上出现了大量有价值的信息资源, 同时用户产生了大量的文本资源, 如博文、微博、标签等。在用户组织和管理及搜索大量的文本时候, 文本聚类能自动帮助用户对文本进行有效的分类, 从而进行有效和便捷的知识获取。所谓文本聚类, 是将文档集合全自动归类的过程, 是一种无指导的文本自动归类方法[1]。
传统基于内容的文本聚类只关注文本内容, 有些研究者观察到新型网络信息组织方式— — 社会标签, 并初步尝试将社会标签应用于网络文本聚类, 也有些研究者将文本内容和用户标签结合起来, 但仅将标签视为文本内容的补充。本研究从文本内容和用户标签两个角度计算文本相似度, 并用加权方法将其结合起来, 比较其聚类结果的差异。
首先基于传统的基于内容的文本聚类, 给出了文本表示和三种特征抽取方法, 计算得到文本之间相似度, 用AP聚类算法对其聚类, 并比较三种特征抽取方法的聚类结果。然后将基于内容的文本相似度与基于标签的文本相似度选用Sigmoid函数进行加权重新计算, 最终得到基于文档内容与标签的Web文本聚类, 讨论社会标签对传统的文本聚类的影响和效果。
传统的基于文本内容的文本聚类, 将文本表示为文本模型, 如VSM(Vector Space Model)模型[2]、N-gram模型、基于短语的模型、基于概念的模型、文本的图表示及概率模型[3]。文本特征抽取与权重计算的方法主要有TF× IDF函数、布尔函数、频度函数、互信息(Mutual Information)、期望交叉熵(Expected Cross Entropy)、二次信息熵(QEMI)、信息增益(Information Gain)等。其中使用较多的是由Salton等[4]提出的TF-IDF函数[5]。然后应用标准的聚类算法(如K-means算法[6]、谱聚类[7]等)对文本进行聚类[8]。
Zhao等[9]提出了一种受约束的层次凝聚算法, 将基于划分和基于凝聚的方法结合起来, 能够减少差错, 从而提高聚类结果质量。Jing 等[10]提出了一种新方法聚类大型和复杂的文本数据, 结果显示新方法优于标准 K-means 和二分法K-means算法, 同时仍然保持 K-means聚类过程的效率。Kummamuru等[11]修改了模糊聚类算法, 用来进行聚类大型文本语料库, 证明改进算法具有可扩展性, 并产生有意义的集群。毛嘉莉[12]基于多次采样一次预聚类搜索初始聚类中心的思想, 提出一种改进的K-means文本聚类方法。李星毅等[13]提出一种基于单词相似度的文本聚类算法, 具有较好的聚类效果。李云等[14]从Web文本抽取特征词形成基于文本的形式背景, 从中提取概念来表示文本并度量文本之间的相似度, 取得了良好的聚类效果。
有些研究者观察到新型网络信息组织方式— — 社会标签, 大量的社会标签被用于网页标记、协作分类、网页导航、信息分类等。他们开始关注标签对网络文本聚类的作用。何文静等[15]以社会标签和关键词两种特征抽取方法, 采用K-means聚类算法对文本资源进行聚类, 通过实验证明基于社会标签的文本聚类是一种较传统关键词进行聚类更为有效的聚类方法, 能够提高文本聚类的效果。杨鲲等[16]在分析社会标注系统中用户、标签及被标注Web资源之间的关联关系的基础上, 提出了基于用户标签的Web资源语义描述获取算法。Li等[17]针对互联网上网页标签过少的问题, 提出了一个与用户相关的标签扩展的方法, 添加标签到原文件, 设计了Folk-LDA模型有效地阻止主题漂移并得到更好的聚类效果。贺秋芳等[18]提出一种挖掘用户标签的增强型社区网页聚类算法, 用多种距离度量挖掘网页链接关系, 将网页的内容信息相似度和链接关系结合起来进行聚类。Lu等[19]用聚类方法Tripartite Clustering, 对网络资源中三种类型的节点(资源、用户和标签)进行聚类, Tripartite Clustering显著优于基于内容的K-means方法, 并产生更加有用的信息。
叶宇飞等[20]提出一种Web中文文本聚类方法。在基于知网(HowNet)的概念空间基础上过滤非名词, 分析文本中重要词汇的语义, 对标签特征集与正文特征集进行特征集聚类, 再利用改进的TF× IDF算法选取两个集合中的特征, 最终将文本表示为选取的标签特征集与正文特征集的并集, 降低了特征的维度, 可以高效地表示文本。Trivedi等[8]提出了基于子空间的特征提取方法, 利用标签信息补充网页中的内容, 提取更有代表性的特征, 从而提高网页聚类效果。Ramage等[21]讨论如何使用生成的大规模标签的社会书签网站作为页面文字和锚文字的补充数据源, 从而提高网页的自动聚类。李鹏等[22]提出基于Tag的网页关键词抽取方法— — Tag-TextRank, 该方法通过目标文档中的每个Tag引入相关文档估计词项图的边权重, 计算得到词项的重要度, 最后将不同Tag下的词项权重计算结果进行融合。Tag-TextRank在各项评价指标上均优于经典的关键词抽取方法TextRank, 并具有很好的推广性。
传统的文本聚类研究, 引入单词之间的语义, 确定聚类初始中心等方法对传统文本聚类进行优化。传统的文本聚类研究中的优化方法只基于内容中的特征选项或者算法的改进, 实现聚类结果的提高。基于用户标签的文本聚类研究中, 用标签取代了文本关键词, 还考虑了用户、链接、被标注资源之间的关系等, 对网页进行聚类。但研究者只考虑了用户标签以及其链接关系, 没有将用户标签和文本内容结合起来。在基于文本和标签的文本聚类中, 研究者选取标签与关键词的并集或基于子空间的提取方法对文本进行聚类, 仅仅将标签视为文本内容的补充。因为本文的重点是研究标签对文本聚类的提升作用, 而不是在某种特征提取方法的比较上。所以采用标准TextRank算法。
鉴于此, 本文以中英博文语料为例, 使用三种特征抽取方法对文本进行特征抽取, 不仅仅将标签视为文本关键词的补充, 而且使用两种加权方法对基于内容和基于标签的相似度进行加权, 从而计算出新的文本相似度, 最后用AP聚类算法对样本进行聚类并对聚类结果进行评测。本文比较不同标签相似度的加权对不同的特征抽取, 不同语种文本的聚类结果的影响。
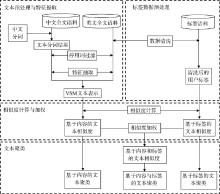
本文研究思路如图1所示。左上角为基于内容的文本相似度计算模块, 右上角为基于标签的文本相似度计算模块, 针对基于内容的文本相似度和对两个相似度进行加权进行文本聚类, 并对聚类结果进行评测。
 | 图1 总体研究思路图 |
选取Engadget中文版①(①http://cn.engadget.com/.)与对应的英文版②(②http://www.engadget.com/.)博文(中英文对应且有分类)作为实验数据, 共4 906对, 采集博文全文和用户标签等信息。使用中国科学院计算技术研究所的中文分词软件ICTCLAS③(③http://www.ictclas.org/.)对中文博文进行中文分词, 并对其进行停用词过滤, 英文博文用空格进行分词和停用词过滤, 统一为小写, 过滤符号和标点, 使用PorterStemmer④(④http://tartarus.org/martin/PorterStemmer/.)对英文进行词干提取。用户标签全部为英文, 统一为小写, 使用PorterStemmer对其进行词干提取。
本文中博文的文本表达使用Salton等[2]提出的向量空间模型VSM。该模型的主要思想是:将每一文档都映射为由一组规范化正交词条矢量组成的向量空间中的一个点。对于每个文档Dj, 都可以用文档中的词来表示, 这些词及其对应的权重构成“ 空间” 中的一个向量, 对于文档Dj, 可以用此空间中的词条向量(W1j, W2j, …, Wtj)来表示, 其中, Wij为Dj中词条i的权重[23]。
本文主要运用三种特征抽取和权重计算方法:TF× IDF, TextRank, TextRank× IDF。
(1) TF× IDF
Salton等[4]提出的TF× IDF函数如下:
Wij=TFij× IDFi (1)
TF指Term Frequency, 表示词条i在文档Dj中出现的次数, 称为词频; IDF指Inverse Document Frequency, 即逆文档频率。IDF定义如下:
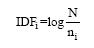 |
其中, N表示文档集合中所有的文档数目, ni表示整个文档集合中出现过的词条i的文档的总数, 称为特征的文档频率[23]。
(2) TextRank
TextRank算法是Mihalcea等[24]提出的一种基于图的关键词抽取方法。用G=(V, E)表示具有V个顶点集合和E个顶点集合的有向图, E是V× V的子集。对于一个给定的顶点Vi, 用In(Vi)表示指向该顶点的顶点集合(Predecessors), 用Out(Vi)表示点Vi指向的顶点集合(Successors)。那么顶点Vi的重要性分数被定义为:
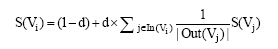 |
(3)
由于TextRank算法只对单篇文章进行关键词抽取, 没有考虑到多文档集中关键词的逆文档频率, 会产生大量的无意义的高权重关键词, 所以将TextRank和IDF相乘, 选取第三种特征抽取方法:
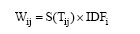 |
其中, S(Tij)为词条i在文档j中的TextRank的值。
本文采用基于向量余弦值[2]的方法进行文本聚类, 用三种特征向量表示文档, 对于任一特征表示文本集中的两个文本向量为 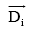
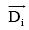
 |
其中, m为第i篇文档和第j篇文档共同的不重复的特征数量, Wik表示第i篇文档中第k个特征项的权重, Wjk表示第j篇文档中第k个特征项的权重。当两向量余弦值越大时, 两文本的相似度越高, 被归为同一类别的可能性越大[15]。
对于文本相似度和标签相似度的加权, 本文选择两种加权方案, 线性加权和Sigmod函数加权。线性加权, 即对两个相似度线性加权, 两个相似度权重系数都为0.5。
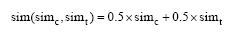 |
其中,
根据文献[25], 多个相似度的结合可以用如下公式表示[26]:
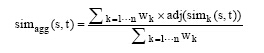 |
其中, wk是各策略的权重, adj(x)是Sigmoid 函数, 该函数是一个平滑函数, 使得合并结果偏向于预测值高的策略[25]。函数adj(x)的定义为:
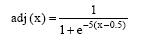 |
其中, x是某一相似度的值, 0.5是Sigmoid 函数中心[27]。
Frey等[28]在《Science》杂志上提出一种聚类算法Affinity Propagation(AP)。AP算法不需要指定聚类数目, 它将所有的数据点都作为潜在的聚类中心, 称之为Exemplar。AP需要输入一个数据点之间的相似度集合, 用s(i, k)表示索引点k和Exemplar之间的相似度。它根据N个数据点之间的相似度进行聚类。这些相似度组成N× N的相似度矩阵S(其中N为有N个数据点)。以S矩阵的对角线上的数值s(k, k)作为k点能否成为聚类中心的评判标准, 若该值越大, 则这个点成为聚类中心的可能性就越大, 这个值又称作参考度p(Preference)。AP算法中传递两种类型的消息, Responsibility和Availability。r(i, k)表示从点i发送到候选聚类中心k的数值消息, 反映k点是否适合作为i点的聚类中心。a(i, k)则表示从候选聚类中心k发送到i的数值消息, 反映i点是否选择k作为其聚类中心。r(i, k)与a(i, k)越强, 则k点作为聚类中心的可能性就越大, 并且i点隶属于以k点为聚类中心的聚类可能性也越大。AP算法通过迭代过程不断更新每一个点的吸引度和归属度值, 直到产生m个高质量的Exemplar, 同时将其余的数据点分配到相应的聚类中。聚类的数量受到参考度p的影响, 如果取输入的相似度均值作为p值, 得到聚类数量是中等的。如果取最小值, 得到类数较少的聚类。
Engadget是一个专注于数码产品报道、评测的博客。Engadget提供了中文版内容, 而且更新同样迅速、及时, 新闻几乎与主站同步。本文分别选取Engadget中英文网站中各4 906篇博文(中英文对应且有35个分类)作为实验数据, 采集博文全文和用户标签等信息。其中具体的博文分类如表1所示:
| 表1 博文类别表 |
本文采用纯度和熵值评价博文聚类结果。这是面向分类的度量, 这些度量评估簇包含单个类对象的程度。
(1) 熵:每个簇由单个类对象组成的程度。对于每个簇, 首先计算数据的类分布, 即对于簇i, 计算簇i的成员属于类j的概率:
 |
其中, mi是簇i中对象的个数, 而mij是簇i中类j的对象个数。使用类分布和标准公式计算每个簇i的熵, 公式如下:
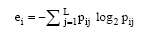 |
其中, L是类的个数。簇集合的总熵用每个簇的熵的加权和计算, 即:
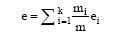 |
其中, K是簇的个数, 而m是数据点的总数[29]。一般而言, 熵值越小, 聚类效果越好。
(2) 纯度:簇包含单个类的对象的另一种度量程序。纯度越大, 聚类效果越好。簇i的纯度是:
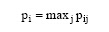 |
而聚类的总纯度是[29]:
 |
实验结果如表2所示。首先, 单独使用标签的文本聚类效果不太理想。基于标签的中文博客聚类的熵值为2.710 33, 大于基于内容的聚类结果和基于内容和标签的聚类熵, 而纯度为0.392 38, 均比后两者小(已在表2中加黑显示)。而基于标签的英文博客用AP聚类算法的结果未收敛, 没有聚类结果。笔者认为产生这种结果的原因在于, 对于博客这种网络数据, 标签个数的稀缺和质量的参差不齐不能很好地反映出原文的主题。并且从图2和图3的比较中可以看出, 基于内容的聚类结果较好, 所以, 从博客原文中抽取出关键词或者特征词显得尤为重要。但是标签作为博客的另一个社会化特征也不容忽视。对不同语言的博客, 将基于内容的聚类结果和基于内容和标签的聚类结果给出结果比较图, 并分析实验结果。
| 表2 中英博文聚类结果 |
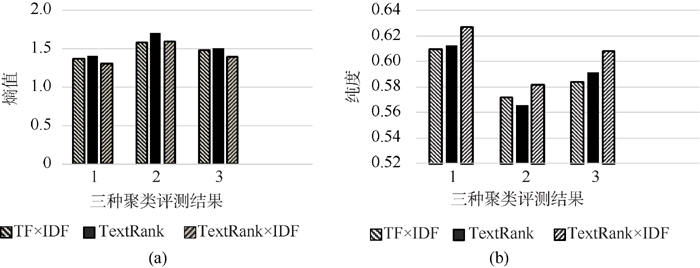 | 图2 中文博文聚类结果比较 |
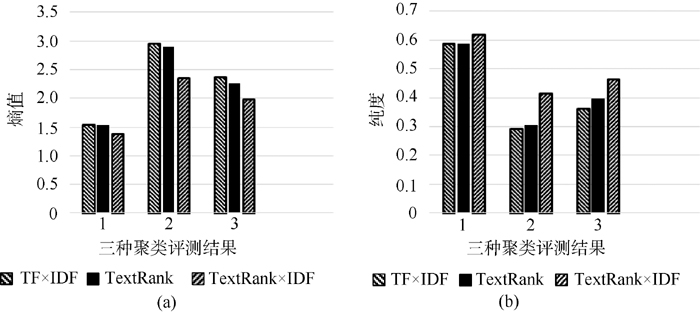 | 图3 英文博文聚类结果比较 |
在图2和图3中, 横坐标从左到右分别为:基于文本内容的聚类, 基于文本内容和标签(Sigmod加权)的聚类, 基于文本内容和标签(线性加权)的聚类。首先从特征提取来看, 无论是中文还是英文,
其次标签的加权都对文本聚类有了一定的提高。在中文博文标签加权聚类结果中, Sigmod加权对文本聚类效果并没有改进反而有稍许下降, 而在英文博文标签加权聚类结果中, Sigmod加权对文本聚类效果有了一点提高。因为用Sigmod函数加权时, 基于标签的相似度对基于内容的相似度的影响较小。由于中文博文标签全部是英文标签, 所以对中文聚类没有提高, 反而产生了一定的干扰作用。
而线性的标签加权对中英博文聚类的结果都有很大的提高。因为线性加权中, 基于标签的相似度对基于内容的相似度的影响较大, 从而使得聚类效果都有了明显的提高。但是实验中只选取一组线性系数, 没有对多组线性系数进行实验从而找出标签相似度与内容相似度最佳的权重系数。AP聚类算法中, 由于其迭代次数多, 计算量较大, 不能应用于大数据, 而且聚类的结果中, 聚簇过多, 影响了聚类结果的展示。
本文以带分类的具有社会标签的中英文博文为聚类样本, 用三种方法对博文进行特征抽取, 用两种加权方法对基于内容和标签的相似度进行加权, 用AP聚类算法对样本进行聚类。并评估了三种特征抽取的聚类结果和标签对文本聚类的作用。通过实验证明 TF× IDF在文本聚类中的表现优于TextRank和 TextRank× IDF, 基于文档内容和标签的Web文本聚类对传统的文本聚类有一定的改善。但是在相似度的加权中, 线性加权优于Sigmod加权函数, 应该更加重视社会标签在文档聚类中的作用和意义。标签是用户在数字资源上标记的关键字, 在一定程度上能实现对信息的分类和搜索。在对Web文本聚类中, 社会标签的引入能得到更好的文本聚类结果。本文的不足之处在于, AP聚类算法不适用于大数据的Web文本聚类, 对多组线性系数实验尚未进行系统的研究, 这是未来的研究工作。此外, 测评数据集分布很不均衡, 下一步工作将优化聚类测评数据集, 更加合理地评价聚类效果。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|