{kind=link}
{kind=link}
{kind=link}
半监督的网络科技信息分类模型
[李传席 , 张智雄, 刘建华, 钱力]
, 张智雄, 刘建华, 钱力]
, 张智雄, 刘建华, 钱力]
|
|


作者贡献声明:
李传席, 张智雄:提出研究问题, 设计研究框架;
李传席:研究方法的设计和实现, 以及论文的撰写;
刘建华:提供部分实验数据和研究思路的讨论;
钱力:参与实验过程的设计与分析。
【目的】开放的网络科技信息网页内容之间区分度较小, 传统基于规则和统计学习的方法无法满足网络科技信息网页分类的具体应用需求。【方法】通过深入分析网络科技信息主题网页的内容和结构, 利用开放本体等资源实现领域特征的学习, 构建半监督的网络科技信息分类模型。【结果】实验结果表明提出的方法在网络科技信息分类实验中的精度、召回率和F1值分别达到0.9016、0.8756和0.8884, 相比贝叶斯方法具有明显优势。【局限】该方法在应用到其他类别的网络科技信息分类时, 仍然需要领域专家提供相关领域的核心种子特征。【结论】该方法可以满足网络科技信息深度加工的需求, 实现有效的网络科技信息网页分类。
[Objective] Considering the difference of open Web scientific and techical information is minor, general rule-based and statistical learning methods cannot classify the information effectively for the practical application demands.[Methods] By analyzing the content and structure of Web pages, and utilizing the open resources (such as domain Ontology and thesaurus etc.) to perform the self-learning of domain features, this paper proposes a semi-supervised classification model of scientific and technical information.[Results] The experiment results show that the proposed method achieves the precision of 0.9016, recall of 0.8756 and F1 score of 0.8884 respectively, which are superior to Naive Bayes classification.[Limitations] Applying the proposed method to new domain, the domain seed features need be supplied still.[Conclusions] The proposed method can classify the scientific and technical information effectively and satisfy the demand of the information deep analysis and process.
互联网深入发展的同时也产生了大量的网络科技信息, 采用高效的方法实现开放的网络科技信息的分类, 有助于深度挖掘网络科技信息所蕴含的知识, 满足科技信息加工处理的需求。网络科技信息资源监测系统[1]的目标是帮助战略情报研究人员全面及时地跟踪监测特定领域内一些重要科研机构发布的网络信息资源, 网络科技信息资源监测可以洞察科技领域的发展态势, 是文献情报研究的重要任务, 而对网络科技信息的分类则是网络信息监测系统的重要环节之一。
为了深度挖掘网络科技信息资源中蕴含的知识, 提升资源的利用价值, 陈旭玲等[2]使用聚类学习算法分析科技文献中蕴含的创新研究方向, 挖掘科技文献信息之间的关联。宋丹等[3]通过借鉴话题识别与跟踪方法中的技术, 采用基于词包特征(BOW)的K近邻分类方法, 利用文献之间的引用关系, 实现科技主题的自动识别与跟踪。而刘勘等[4]则采用关键词技术聚类科技文献, 利用特征词的词频等统计特征, 构建文本向量, 采用基于密度的方法实现科技文献的聚类, 从目标科技文献中发现热点研究领域和研究方向, 开展科技文献中知识挖掘的专题研究。贺亮等[5]利用科技文献元信息, 采用LDA模型, 通过自动分析科技文献的话题, 实现相关科研领域的发展趋势和研究动态的挖掘。楚存坤等[6]采用模糊聚类技术, 探索文献的自动分类技术。谢新洲等[7]讨论了网络信息资源的分类特征, 并分析传统分类方法的适应性等问题。而刘建华等[8]则采用基于规则的方法对网络资源的标题进行分析识别, 研究标题的来源和特征等方面在网络文本资源的标题快速识别分析上的效果。此外, 网络科技信息的分析和处理研究中, 王飞跃[9]阐述了面向大数据和开源信息环境下, 科技信息向科技情报的实现过程中, 也需要对科技信息进行深入的分析和处理, 实现科技发展态势的预测和科技决策的制定与评估。刘云等[10]则分析科技资源研究的相关手段和方法。
Qi等[11]对网页信息的分类方法进行概述, 并与基于文本的分类方法相比较, 包括KNN、Naive Bayes、SVM等机器学习方法在网页分类上的效果, 特征涉及词包特征BOW、N-Gram特征等在网页分类算法中的应用。Tsukada等[12]给出Naive Bayes、BayesNets、Trees、LinearSVM等方法基于特定语料集训练后的分类效果, 采用BOW和N-Gram作为特征的无监督学习方法却无法很好地实现网络科技信息的分类。与本文在实现科技网页分类时相似, Bartik[13]在网页分类时采用网页结构信息和网页内容相结合的方式。此外, Dumais等[14]单独采用特征共现技术实现对网页文本的分类。
面对Web规模的网络科技信息, 应采用有效的分类方法定位特定需求背景下的网页内容, 加速信息获取的质量和效率, 满足网络科技信息的深度分析和处理需求。但是由于这些网页的内容之间区分度较小, 传统基于规则和统计学习的方法无法很好地对其进行分类。而与科技文献的分类方法相比, 网络科技信息不具备结构化特性, 分类方法不能得到很好的应用。本文通过深入分析网络科技信息网页的内容和结构, 通过对Web资源进行了深度的剖析, 利用开放本体等相关资源, 构建一种半监督的网络科技信息分类方法, 实现对网络科技信息的分类, 并通过实验验证了本文方法在网络科技信息分类方面优于传统基于学习的分类方法。
图1是基于领域特征的半监督网络科技信息分类模型框架。该框架主要由网页数据块划分、数据预处理、特征选择与抽取、网页块隶属度计算、网页类别隶属度计算等部分构成。
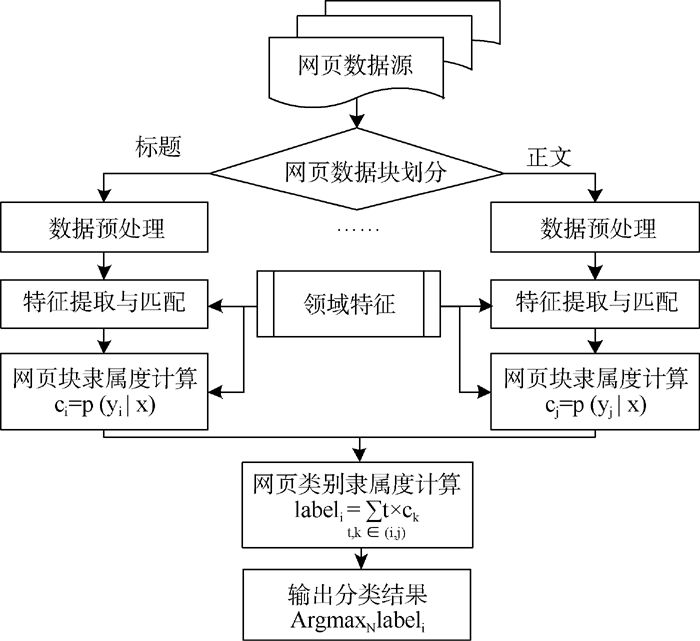 | 图1 半监督网络科技信息分类模型框架 |
根据特征重要性和表现形式的不同, 将领域特征分成三类:核心特征词, 由领域专家提供的领域词表组成, 具有较强网页类别区分度; 扩展特征词, 包括采用特定方法对核心特征词进行扩展得到的特征词(见表1), 对类别的标注起辅助作用, 强度弱于核心特征; 规则特征, 即采用规则表达式形式呈现的领域特征。领域特征主要来源于以下三个方面:
(1) 核心特征词, 由领域专家整理对类别具有高区分度的核心特征词。例如, 对于研究报告, 如果网页的标题中含有词汇特征“ 报告(Report)” , 或者名词词组“ 某某报告(如Technique Report)” , 则此网页隶属于研究报告类别的强度很高, 同时可以认为“ 报告(Report)” 为核心特征词。
(2) 通过学习的方法结合不同的知识源, 对领域核心词进行扩展学习, 形成扩展特征词。考虑到领域专家整理的核心词虽然对于类别的区分度很高, 但是存在一定的局限性, 不能处理未登录词等特征, 无法实现领域特征的全面广泛覆盖。因此, 对核心特征从以下三个方面进行扩展:
①基于WordNet[15]的同义词扩展。本文中采用WordNet对核心特征词进行语义扩展, 获取同义词。例如, 对于词汇announce, 可以扩展得到特征 announce denote, declare, annunciate, harbinger, foretell, herald。
②基于词典和叙词表的扩张。通过获取和分析词典与叙词表中的同义词, 作为扩展领域特征, 如在线词典①(①http://www.thefreedictionary.com.)和在线叙词表②(②http://thesaurus.com.)等。
③基于维基百科③(③http://en.wikipedia.org/wiki/Policy.)的扩展。通过查询维基百科中含有的与核心词相关的词条, 对其进行分析并抽取相关特征, 形成扩展领域特征。
(3) 对领域专家提供的领域科技文献语料进行整理、标注得到的结果, 形成规则特征。
| 表1 特征词统计 |
根据网页HTML结构信息, 分析科技信息网页的结构和内容, 获得网页中表达主要内容的网页数据块。根据实际需要选取网页中的标题块(Title)和正文块(Body)两部分作为有效信息内容块。
网页标题块和正文块的预处理步骤主要包括:去除网页块中的无关噪声信息, 如HTML标签、样式、脚本等内容; 对显示文本内容进行规范化处理, 包括Stem、Lemmatize等。预处理步骤完成后, 获得用于匹配领域特征的规范化网页文本块。
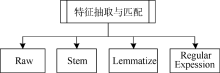
根据领域特征的内容, 对数据预处理之后得到的规范化网页文本块进行分析与处理, 抽取与匹配其中所包含的特征, 形成网页内容的特征项表示, 并提供给网页块隶属度计算组件。特征抽取与匹配的过程如图 2所示, 分别抽取网页块的原始表示特征(Raw)、Lemmatize特征、词根特征(Stem)和规则特征(Regular Expression)等形式。
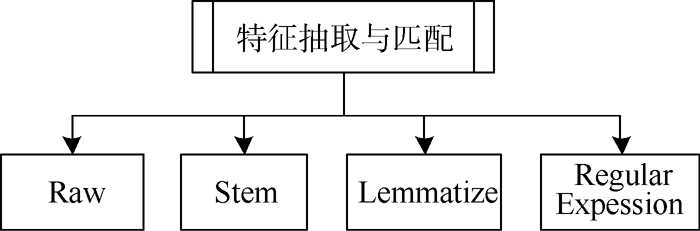 | 图2 特征抽取与匹配过程 |
根据网页的特征及领域特点, 本文提出并构建如公式(1)、公式(2)和公式(3)所示的网页分类模型:
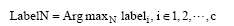 |
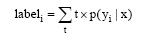 |
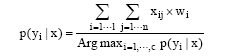 |
LabelN表示根据公式(2)和(3)计算得到网页的类别隶属值Labeli后, 根据实际应用需求返回分值位于前N的主题网页类别。t表示网页中不同网页块(网页标题、网页正文等)对于类别辨析力差异度, 在此取 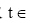
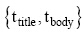
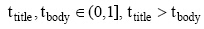
p(yi|x) 表示网页x属于类别yi的隶属值, xij表示领域特征中属于类i的特征j。wi表示第i类特征的权重值, 用于度量特征的重要性, 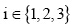
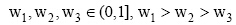
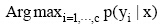
根据网络科技信息标注的需求, 分类模型最终计算出网页属于每一类别的隶属值, 形式为: 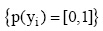
选取网络科技信息监测服务平台①(①信息监测服务平台http://stm.las.ac.cn/STMonitor.)中的900条数据(5/01/2012-10/01/2012), 由相关领域专家进行标注, 得到的结果如表 2所示:
| 表2 评估样本数据量 |
实验过程中, 根据实际应用需求, 抽取网页中的标题部分(Title)与正文部分(Body), 过滤去除网页中与目标内容无关的信息。实验参数设置如下:
网页中不同网页块的参数重要性根据经验值进行设置。参数ttitle=1表示网页中的标题对于信息的类别具有较高的辨析度, 而tbody=0.4表示相对于标题内容而言, 正文部分特征具有的辨析程度较小。而用于度量特征重要性的参数w1, w2, w3分别设置为1、0.8和0.6。
在实验结果的评估上, 参数N取值为2, 表示同一个网页, 可以同时属于一个或两个类别(主类别和候选类别), 对于属于两个类别的网页, 由领域专家判断分类是否合理。算法的实验结果如表 3所示:
| 表3 基于领域特征的分类方法的结果 |
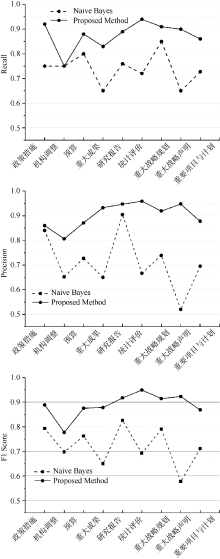
为了更好地说明本文方法的效果, 与贝叶斯方法(Naive Bayes)[16]进行了比较, 训练二元分S类器对网页内容进行分类, 训练过程采用留一交叉验证策略。特征包括BOW、POS和Bigram, 相应的领域特征也加入到贝叶斯方法的训练过程中, 实验结果的评估采用三种度量指标, 包括Precision、Recall、F1 Score, 如图3所示:
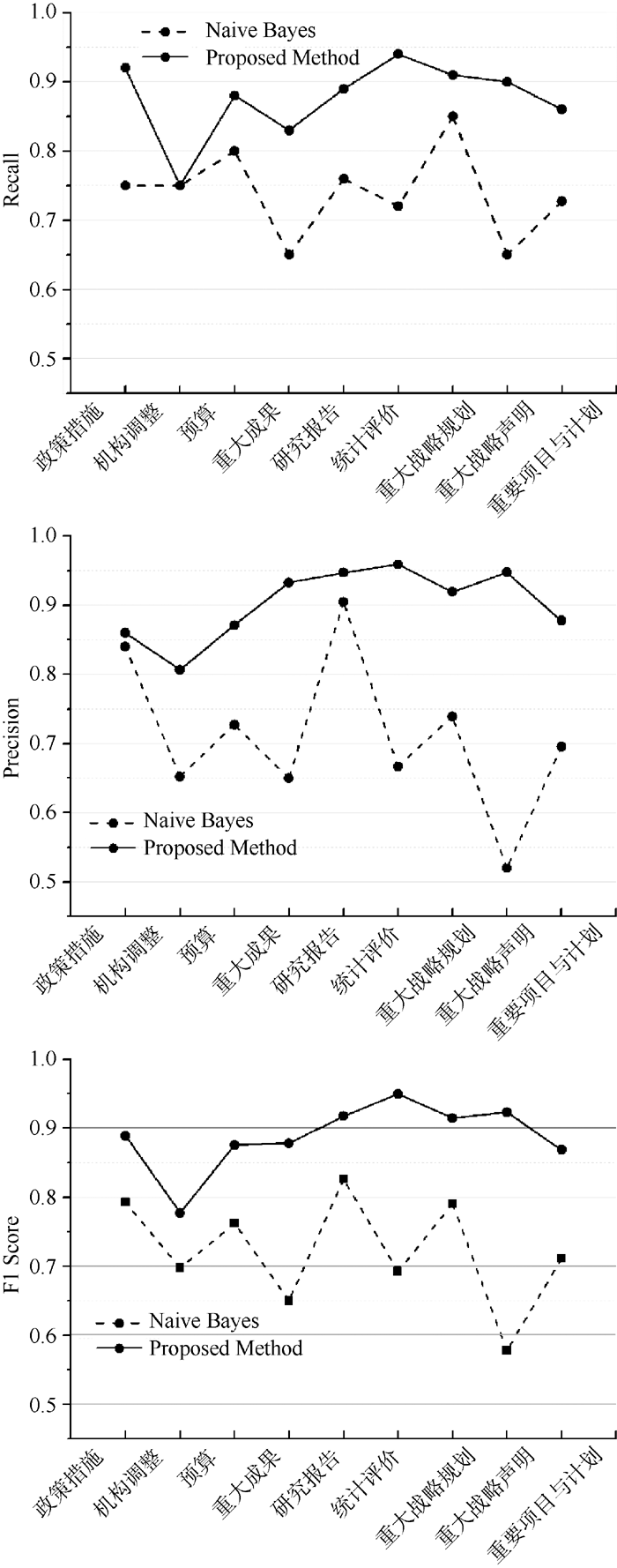 | 图3 贝叶斯分类方法与本文方法的结果比较 |
从图3的结果可以看出, 虽然在贝叶斯方法中加入了领域特征, 但本文提出的分类模型在科技领域网页分类结果上明显优于采用贝叶斯方法得到的效果。此外, 经过领域专家整理出的背景知识在区分领域类别时具有更重要的作用, 这也与Rajaraman 等[17]的观点一致, 即领域背景知识, 例如关键词、短语以及规则等, 对于区分领域内容具有重要的特征作用。通过检查误分类的网页发现, 利用领域词典和叙词表对人工选取的领域特征进行扩展, 可以弥补基于学习的方法在样本标注方面的缺点, 能够发挥现有领域资源的作用。
另外, 通过分析分类结果可以发现, 一些启发式的专家经验规则对于提升分类效果起到积极的作用。与Kan等[18]中描述一致, URL信息也只可以作为网页分类的特征使用, 例如, URL地址的目录信息, 具有相同父目录的网页资源通常在类别上相同或相近:美国宇航局的网站(http://www.nasa.gov), 在URL目录news/budget/下分布的信息多为预算或与其相关的信息。
网络科技信息资源监测是洞察科技领域的发展态势和文献情报研究的重要任务, 有助于战略情报研究人员全面及时地跟踪监测特定领域内重要科研机构发布的网络信息资源, 实现科技信息的深度分析, 网络科技信息分类作为网络科技信息资源监测系统的组成部分, 是实现网络科技信息加工分析的重要基础。由于科技信息网页的内容之间区分度较小, 导致传统基于规则和统计学习的方法无法有效地对其分类。本文通过深入分析网络科技信息主题网页的内容和结构, 结合领域专家知识, 挖掘领域类别中含有的不同形式和类型的特征, 利用已有的开放本体等相关领域主题资源, 构建一种半监督的网络科技信息分类模型, 实现对网络科技信息的分类标注。最后, 通过与贝叶斯分类方法进行比较, 验证本文方法在网络科技信息分类上的有效性。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|