
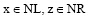
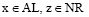
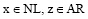
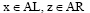
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
扩展搜索日志上下文的新词识别
[李雪伟1  , 吕学强
, 吕学强1 , 刘克会2, 3 ]
, 吕学强|
|


作者贡献声明:
吕学强:提出研究命题;
李雪伟:提出研究思路, 设计实验方案和完成实验, 起草、撰写论文;
吕学强, 刘克会:提供数据, 修订论文。
【目的】大规模搜集、整理新词扩充现有词典, 提高汉语分词准确率, 推动中文信息处理的发展。【方法】根据搜索日志查询串特征及新词特点, 提出扩展搜索日志上下文的新词识别方法。首先, 通过分析查询串的特点获取种子词集合, 利用种子词集在搜索日志中进行全文扩展, 提取候选新词。其次, 根据新词的时间属性发现新词串, 最后基于词语的边界信息, 提出改进左右熵方法抽取语料中存在的新词语。【结果】在搜狗日志上进行实验, P@100的平均准确率达到89.60%。【局限】对比词串集合的规模会在一定程度上影响新词的正确率。【结论】实验表明该方法适用于搜索日志这种缺失上下文信息的文本的新词识别。
[Objective] Collect and collate new words to expand the current dictionary, which can improve the accuracy of Chinese segment and promote the development of Chinese information processing.[Methods] A new word recognition method of context extension is proposed depending on features of query strings and new words. Firstly, get the seed collection based on features of query strings and obtain candidate new words through full extension. Secondly, get candidate new words according to the words time span. Finally, filter candidates by the use of improved left-right entropy according to the boundary information of words.[Results] Experiments on Sogou log show that precision rate of P@100 can reach 89.60%.[Limitations] The scale of contrast strings affects the accuracy of new words, to a certain extent.[Conclusions] Experiment results demonstrate that the method is suitable for the search logs of which context information to identify new words is missed.
当新鲜事件发生时, 人们通常利用搜索引擎来检索, 以获取更多更全面的信息, 以致于搜索日志中存在着大量的新词。但由于词典修订存在一定的延迟, 新词往往不能及时被词典收录, 严重影响了中文分词的发展, 而中文分词是中文信息处理的基础, 这给中文信息处理带来了挑战。
本文通过分析搜索引擎中的用户查询日志, 从中抽取新词, 弥补词典中的新词匮乏问题。针对缺失上下文信息的用户查询日志, 提出扩展搜索日志上下文的新词识别方法。首先, 基于查询串的上下文缺失的特点, 获取种子词集合, 利用种子词集在整个搜索语料范围内进行全文扩展抽取候选新词; 其次, 利用新词的时间属性, 过滤旧词串, 发现新词串; 最后基于词语的边界信息, 提出改进左右熵方法过滤新词串中的垃圾串(不能形成词语的字串), 抽取新词语, 实现搜索日志中新词识别。
用户查询日志作为囊括大众智慧的海量数据资源, 成为广泛关注的对象。许多研究者[1, 2, 3, 4, 5]均是针对搜索日志中的命名实体和专有名词进行挖掘研究。余慧佳等[6]利用大规模查询日志对网络搜索引擎用户行为进行研究; Liu等[7]基于用户的搜索行为, 利用查询日志进行用户查询推荐; 刘奕群等[8]基于用户行为分析研究搜索引擎的自动性能评价。而在查询日志中进行新词识别工作的研究很少。Zheng等[9]在用户查询日志中, 提出基于用户行为的协同过滤新词识别方法。但该方法需要维护大量的专家词典, 前期准备工作复杂。
以往对新词识别的研究主要集中在文本领域[10, 11, 12, 13, 14, 15]。与文本领域中的新词识别不同, 用户查询串通常都很简短(一般只有2-3个词), 缺失上下文信息, 因此文本领域中的新词识别技术不能直接有效地应用到查询日志上。这给基于用户查询的新词识别的研究工作提出新的挑战。
本文针对查询日志这种上下文缺失的语料, 提出扩展搜索日志上下文的新词自动识别方法。该方法无需人力劳动, 完全自动实现。
邹刚等[11]认为, 新词语就是已有汉字或词语的一种组合, 有两个特征:具有重复出现的规律; 具有时间规律, 即新词语总是在某个时间点之后出现并且流行。
对用户查询日志中的查询串进行分类, 可分为以下4类:

通过分析这些查询串, 发现无上下文信息的词语可以作为其他词语的上下文, 如无上下文的查询串“ 新亮剑” , 在“ 新亮剑下载” 中为“ 下载” 的上文, 而在“ 电视剧新亮剑” 为“ 电视剧” 的下文。由于用户查询日志中查询串长度较短, 且汉字数为2或3的查询串均为用户输入的不可再分的词语, 这些查询串均为无上下文信息的词语。本文直接提取这些查询串, 将其作为种子词, 利用种子词继续提取其他查询串中将其作为上文或下文的2或3字的汉字串, 以此类推, 抽取候选新词。例如:利用“ 新亮剑” 可以提取“ 新亮剑下载” 、“ 电视剧新亮剑” 中的“ 下载” 、“ 电视剧” , 此时, 它们成为无上下文信息的词语, 利用它们再次提取将其作为上文或下文的词语。
(1) 种子词发现
本文将汉字数为2或3的查询串作为种子词。由于用户在检索时, 可能会输入“ 新亮剑 下载” 这种形式的查询串, 在预处理阶段, 本文将这种查询串分割为两个独立的查询串:“ 新亮剑” 、“ 下载” 。
通过对搜狗查询日志语料的观察及统计, 发现长度为2或3的查询串占全部语料的12.82%, 因此提取汉字数为2或3的查询串, 将其作为全文扩展方法的种子词。
(2) 全文扩展的候选新词提取
利用上文已提取的种子词, 循环迭代扩展获取候选新词。
为方便描述, 定义如下概念:
Update方法:已知查询串集合Q={q1, q2, ..., qj-1, qj, qj+1, ..., qn}, 种子词集合S={s1, s2, ..., si, ...sn}, 对于 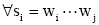
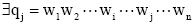
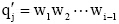
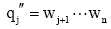
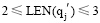
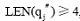
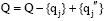
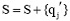
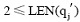

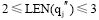
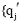
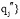
其中, LEN(q)表示q中含有汉字的数目; wi表示一个汉字, 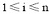
对查询串集合中的每一条查询串应用Update方法, 以此循环迭代, 直到不再产生新的种子词为止。最后提取查询串集合中的4或5字连续汉字串, 将其与种子词集合合并, 得到候选新词。
如现有查询串集合Q={“ 凰图腾下载” 、“ 国门英雄” 、“ 云轩阁小说下载” }, 种子词集合S={“ 郭美美” 、“ 小说” 、“ 电视剧” }, 对于种子词“ 小说” , 存在查询串“ 云轩阁小说下载” , 包含种子词“ 小说” , 对查询串应用Update方法, 可得新的种子词集合S={“ 郭美美” 、“ 小说” 、“ 电视剧” 、“ 云轩阁” 、“ 下载” }, 新的查询串集合Q={“ 凰图腾下载” 、“ 国门英雄” }。
在对查询串应用Update方法过程中, 应注意种子词使用的顺序:先使用长种子词, 后使用短种子词, 如现有查询串“ 电视新亮剑” 和种子词“ 亮剑” 、“ 新亮剑” , 如果先对查询串使用种子词“ 亮剑” , 则会得到新种子词“ 电视新” , 从而提高了垃圾串的产生率。
提取的候选新词, 其中包含大量非新词和非词语的串, 以下利用新词的特点提取新词。
(1) 基于时间的信息
新词的一个特点为“ 新” , 提取出的词语中没有利用任何有关时间的信息, 其中必包含许多旧词语, 新词发现的目标是过滤旧词语, 得到新词语。
本文利用新词的时间特点识别新词。基本思想为:给定一个时间, 在该时间点之前出现的词语为旧词语, 该时间点之后出现的词语为新词语。具体方法如下:
通过判断该候选新词是否出现在对比词串中, 以此获得新词串。为便于描述, 本文定义在给定时间点之前出现的词串为对比词串。
假设用CompareS表示对比词串集合, 用CandidateS表示候选新词集合, 其中CompareS={q1, q2, ..., qN}, 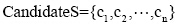
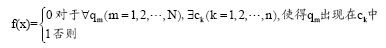
输出1表示该词是新词串。对于每一个候选新词运用以上函数判断, 即可得到新词串。
(2) 基于词语的边界信息
由于候选新词的提取是由种子词的迭代扩展得到的, 其过程经历了查询串的多次拆分, 拆分过程中可能会将一些固定的词语拆分开, 从而得到拆分字串, 这些拆分字串在候选新词中大量存在, 对这些拆分字串进行分析, 发现它们的上文或下文均为一个或几个固定字。由于字串的左右熵[16]是从该字串的外部结合度即对上下文环境的依赖度来确定分割界限, 体现了该字串的灵活性。但是左右熵的计算需要用到字串的上下文信息, 而本文在查询日志中提取的候选新词S多缺乏上下文信息, 如表 1所示, 导致普通左右熵方法不适用于搜索日志。据此, 本文提出改进左右熵方法抽取字串中的词语。
| 表1 候选词串分类 |
改进左右熵方法的基本思想为将候选词分为两类:一类是有上下文信息的候选词, 一类是缺失上下文信息的候选词, 对其分别用不同的方法计算左右熵值, 计算方法公式如(2)和公式(3)所示。该方法认为缺失相应上下文的候选词, 其缺失的上下文可以为任何内容, 即上下文丰富多样, 所以公式(2)和公式(3)相当于为上下文信息缺失的候选词补充了不同的上文或下文信息, 类似表2中的解决办法。
| 表2 上下文信息缺乏相应解决办法 |
字串S的改进左右熵定义为:
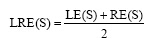 |
其中, 字串S的改进左熵定义为:
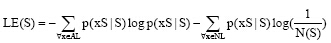 |
字串S的改进右熵定义为:
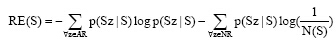 |
其中, AL表示S左边出现的所有非空字符, 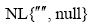
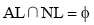
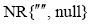
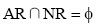
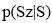
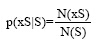 |
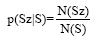 |
实验数据为2011年12月30日-12月31日两天的搜狗日志[17], 使用其中的查询串作为实验数据来源。查询串总数为43 545 423条; 独立不重复查询串总数为609 497条。共进行5组实验, 每组实验随机选取50 000条独立不重复查询串, 然后将查询串按照重复次数展开, 获得查询串总数量如表3所示, 在此基础上分别进行新词识别实验。
| 表3 各组实验查询串数量 |
对比语料采用搜狗日志2008年6月1日-6月29日共29天的查询日志数据。
由于搜索日志数据量大, 产生的新词量也很大, 且本文研究目的是为了扩充词典, 减少新词检测的人工干预。为了使提取新词的准确率尽可能高, 评价指标主要使用正确率。正确率的计算如下:
 |
在提取语料中的种子词阶段, 需要注意搜索用户在输入过程中, 会由于粗心和不确定造成输入错误, 从而导致错误的种子词出现, 为保证新词识别的准确率, 只提取词频数大于3的种子词。
不同的方法对新词的定义不同, 会影响到新词检测的结果, 而且在搜索日志中进行新词识别的很少, 可重现的实验也很少, 本文提出的方法和前人的工作缺乏统一的对比平台。由于NLPIR[18]即ICTCLAS2013版新增了新词发现模块, 其中采用的新词识别算法为文献[19]中所用的方法, 为了证明本文方法的有效性, 将其与NLPIR提取的新词作对比, 实验结果如表4所示:
| 表4 搜索日志中提取的新词准确率 |
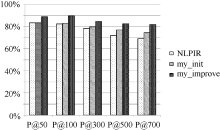
从表4的5组实验结果可以看出, 本文方法优于NLPIR方法, 每组实验结果均有提高。分析实验结果, 发现主要原因有:
(1) NLPIR方法主要是基于上下文信息进行新词识别, 而搜索日志缺失其所需的上下文信息, 从而导致识别效果不好。
(2) NLPIR采用的新词识别算法没有利用新词的时间属性进行提取, 导致大量非新词的存在。
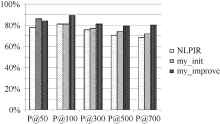
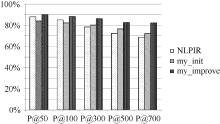
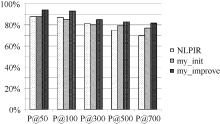
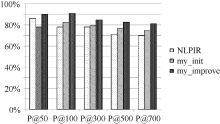
将每组实验结果表示为柱状图, 如图1至图所示:
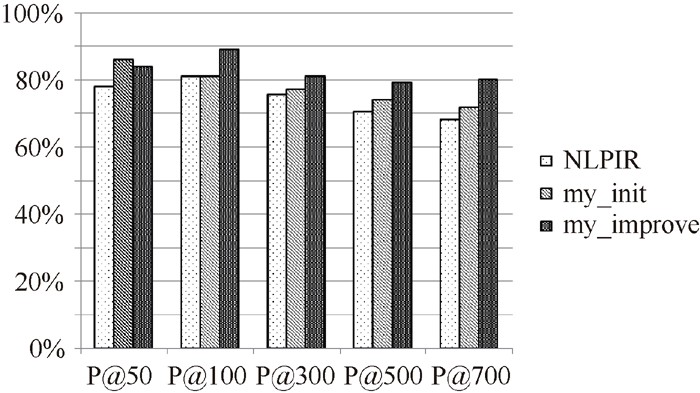 | 图1 第1组实验结果对比 |
 | 图2 第2组实验结果对比 |
 | 图3 第3组实验结果对比 |
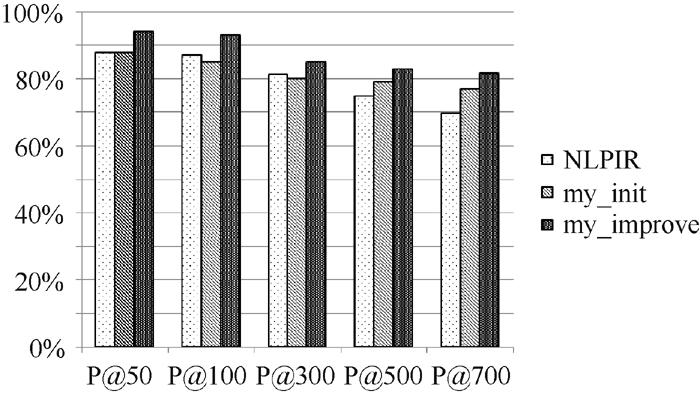 | 图4 第4组实验结果对比 |
 | 图5 第5组实验结果对比 |
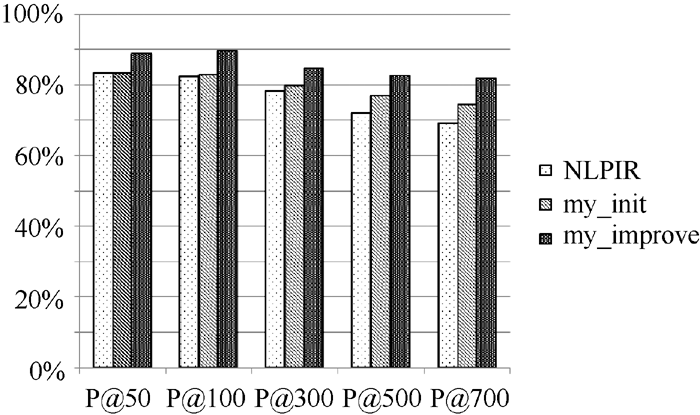 | 图6 平均正确率对比 |
从图1至图6可以看出, 使用普通左右熵的本文方法实验结果不稳定, 其中在第1组、第3组、第5组是呈稳定上升趋势, 平均正确率也均比对比实验高, 整体结果好于对比实验NLPIR。说明全文扩展的候选新词提取方法在搜索日志这种上下文缺失语料中是适用的。使用改进左右熵的本文方法实验结果均比前两种方法好, 且呈稳定上升趋势。说明改进左右熵方法适用于搜索日志。对实验结果进行分析发现, 使用普通左右熵方法, 大量的上下文缺失的词语被过滤掉, 如“ 新亮剑” 、“ 蘑菇街” 、“ 张馨予” 、“ 百里挑一” 、“ 怪侠欧阳德” , 致使许多非新词的词语被保留, 从而导致新词的正确率下降。而使用改进的左右熵计算方法可以将这些上下文信息缺失的词语识别出来, 在保证新词正确率的同时提高了识别召回率。
利用本文方法提取的部分新词结果如表5所示:
| 表5 新词识别结果示例 |
由表 5中的新词识别结果可以发现:
(1) 识别出的新词类型有:中文人名、外文译名、网站名、娱乐节目名、热点事件、网络流行用语、缩略语等。说明本文方法可以识别各种类型的新词语。
(2) 识别的新词中包括“ 十二五” 、“ 喂奶门” 等热点事件词语, 可以为网络舆情的监控提供一定的参考。
(3) 识别的新词以用户输入的主体词为主, 完全符合搜索用户利用搜索引擎进行检索的特点, 通过这些词语, 可以快速发现搜索用户的兴趣所在, 并为其推荐相关信息。
由此可见, 本文提出的方法对于识别搜索日志中的新词是行之有效的。
本文提出了扩展搜索日志上下文的新词识别方法, 根据查询串特点及新词特点, 首先提取种子词, 利用种子词进行全文扩展抽取候选新词; 利用新词的时间特点, 发现新词串; 最后提出改进左右熵方法对非词语进行过滤, 最终得到搜索日志中存在的新词。实验表明, 本文提出的方法在保证较高准确率的前提下大大减少了人力劳动的工作量, 同时可以提取不同类型的新词语, 为相关领域的研究提供了一定的参考。由于对比词串集合不可能将所有的词都收录进去, 因此在新词识别过程中, 存在很多旧词也就是非新词的词语, 为了尽可能地去除这些旧词, 后续工作将进一步扩大对比词串集的规模, 使提取的新词更加准确。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|