
{kind=link}
{kind=link}
{kind=link}
{kind=link}
文本分类中基于类别数据分布特性的噪声处理方法
[李湘东1, 2 , 巴志超1 , 黄莉3  ]
]
]
|
|


作者贡献声明:
李湘东:提出命题和研究思路, 论文定稿;
巴志超:采集和分析数据, 完成实验以及起草、撰写论文;
黄莉:设计研究方案及分析实验结果。
【目的】为减少语料库中训练样本构建时因噪声样本对分类性能的影响, 提出一种基于训练样本中类别数据分布特性的文本分类噪声处理方法。【方法】通过定义训练样本中各类别的聚类密度来表征类别下文档间的相似程度, 并对文档对相似度分布进行正态归一化处理; 采用近似置信区间估计以及统计相结合的方法获取含有噪声样本的文档对; 基于分布的相对熵和类别聚类密度实现对噪声样本识别的正确性验证。【结果】利用该方法在公开及自建语料库中进行测试, 与噪声样本处理前相比, 分类性能平均提高1.21%至4.83%。【局限】样本丰富度有待进一步扩展, 在多领域、多类型数据环境下对该噪声处理方法进行更全面的实验。【结论】实验结果表明该方法是有效、可行的, 能够有效挖掘训练样本中的噪声样本, 且可一次处理批量检测, 不必事先判断各个噪声样本后再进行检测。
[Objective] In order to reduce the impact of the noisy samples on the classification performances during the construction of the training samples, this paper proposes a process method of noise based on the distribution characteristics of category data in training samples.[Methods] The method represents the degree of similarity among the documents in one category by defining Category Cluster Density, and then it conducts a normal unitary processing on the similarity distribution. Afterwards, combined with the method of statistics, the paper adopts the method of approximate confidence interval estimation to get pairs of documents that contain noisy samples. Based on the relative entropy of distribution and Category Cluster Density, the paper realizes the verification of correctness of the noisy documents recognition.[Results] The classification performances on the specialized and self-built corpus is higher than before by 1.21% to 4.83% respectively.[Limitations] The paper will expand the richness of samples and test the samples in various fields and multi-type data environments.[Conclusions] The method is feasible and it could effectively detect the noisy documents. Meanwhile, it could realize panel testing on large amount of samples at one time.
文本分类是指在给定的分类体系下, 根据文本的内容自动判定到相应预定义类别的过程[1], 是人工智能领域的核心研究内容之一。在采用机器学习的方法进行文本分类时, 需要分类器通过事先类别标注完毕的训练样本学习分类的知识并形成特征空间, 从中自动挖掘出能够有效分类的规则, 然后将此规则用于对测试样本的分类。因此, 训练样本和分类算法一样, 是形成文本自动分类系统的基础和关键, 其质量的好坏直接影响分类器的训练结果和识别性能。
为验证算法的有效性, 通常也需要使用一定的类目构成、准备相应的文本作为分类材料,并在由此所组成的试验环境中进行分类试验。而在对分类材料进行标注或获取的过程中, 难免会引入噪声, 如样本内容与所标记的类别不符、样本属性缺失等[2]。这些噪声样本会使训练样本中类别概念模糊, 其提供的分类先验知识不足, 导致分类器构建的分类决策不明确, 从而对测试样本所属类别进行误判, 影响最终的分类性能。因此, 本文从语料库中训练样本的类别数据分布特性出发, 通过计算样本的类别聚类密度这一属性特征, 获取不同类别下的文档对间相似度分布; 采用对数正态化变换进行归一化处理, 以获取噪声样本所服从的正态概率分布; 采用近似置信区间估计和噪声样本度量方法, 实现对噪声文本的有效挖掘和裁剪, 从而提高文本分类器的分类性能。
目前, 研究训练样本集合中噪声样本对分类性能的影响已有相当数量的成果[3, 4, 5, 6, 7, 8]。文献[3]通过实验验证了含有噪声样本的数据会对分类结果产生不良影响, 并提出一种通过降低召回率来保证分类结果准确率的方法。但该方法只得到待分类数据中部分数据的分类结果, 并未提出针对剩余待分类数据进行处理的方法。文献[4]提出一种针对粗分类文档中噪声数据的修正算法NNRA, 该算法通过构建文档关联网络模型, 把类别标记错误的文档重新归到正确的类别中, 以获得精分类的训练数据, 从而提高分类器的分类性能。但该算法计算复杂度较高, 算法效率较低。文献[[
在信息检索领域, 另一部分研究者[2, 9, 10, 11, 12]从对训练样本噪声敏感度出发, 探究不同分类算法针对不同数据集的抗噪性。如文献[2]通过实验验证对不同数据集上的噪声敏感度与训练数据的某些特性有关, 得出训练集文档对的分布是影响噪声敏感度的根本原因。文献[9]描述RankSVM、SVMMVP等算法在部分数据集上有较好的抗噪性, 且随着噪声水平的增加性能变化不大, 而在其他数据集上即使噪声水平很小性能也有很大程度下降。文献[10]采用两阶段优化策略对任何线性排序模型进行非凸优化, 从而使得学习到的模型对噪音不敏感。采用恰当的文档选择策略可以提高训练集的质量[13]。综上所述, 本文提出通过计算训练样本类别聚类密度获取文档对属性的概率分布这一特征, 并通过研究该特征获取训练样本中的噪声样本, 以提高分类器的分类性能。
由于噪声样本的内容与所标记的类别概念信息不符以及噪声属性缺失等特点, 使得这类样本代表其所在类别的程度较弱, 与其他样本之间的相似度较低。这些样本的存在模糊了类别的概念, 使得其类别概念信息不明确。基于以上两点, 本文首先计算训练样本的类别聚类密度揭示样本中类别概念信息, 然后通过类别概念信息反映该类别下文档之间的相似程度, 同时用该指标来评测噪声样本对类别信息以及分类性能的影响。
训练集样本由不同类别构成, 而类别的信息则由其所标注的文本完全决定, 即文本的内容完全决定类别的概念。因此, 可以采用类别的聚类密度来衡量类别下文档特征在表示该类别时的适用程度[14]。其基本思想是:如果文档集合能够更好地表达类别的信息, 那么该类别概念应该更加清晰, 在该类别下对应的文档之间应该更加相似, 类别对应文档集合的平均相似度应该更高。因此, 对于某一类别的聚类密度, 本文采用该类别的文档对间的平均相似度表示, 计算公式如下:
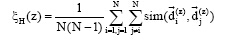 |
其中, 
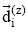


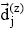
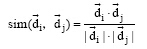 |
其中, 对于每个语料库H, 用类别集合 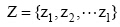


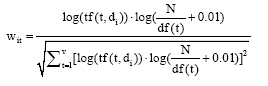 |
其中, tf(t, di)表示特征词t在文档di中的词频, df(t)表示特征词t的逆向文档频率, V为总特征项数, N为总文档数。
本文用类别的聚类密度反映语料中预先设定的分类类别概念的明确程度。如果一个语料中各类别的聚类密度越高, 说明该语料各类别概念越明确, 类别中的文档集合越能代表该类别的信息, 其分类效果越好。另外, 一个类别下噪声样本数量越少, 其所有文档对间的平均相似度越高, 类别概念越清晰明确。
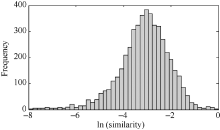
在获取样本类别聚类密度的同时, 可获得该类别下文档对间的相似度分布。通过公式(1)可以看出, 聚类密度实质是文档对间的平均相似度。由于不同类别下样本内容特征不同, 聚类密度值分布的参数也不同, 在比较不同类别的聚类密度以及噪声样本处理前后的聚类密度变化情况时, 无法直接采用聚类密度值进行比较, 因此需要对文档对平均相似度的分布进行归一化处理。根据研究发现, 通过估计分布的均值和方差, 不同类别下文档对相似度的分布可以统一归一化为对数正态分布, 如图1所示(训练样本200篇)。只有在正态归一化处理后, 不同类别的聚类密度才具有可比性[14]。
 | 图1 不同类别下文档对相似度分布 |
另外, 本文通过正态分布的偏度和峰度检验法[17]来检验文档对相似度分布是否属于正态分布。偏度系数是表征分布形态与平均值偏离的程度, 作为分布不对称的测度; 峰度系数是表征分布形态图形顶峰的凸平度, 当两者都为零时, 变量变为理想正态分布。其中, 偏度系数g1和峰度系数g2计算公式如下:
 |
 |
其中, Xi表示文档对相似度值, 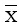
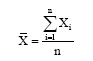 |
 |
在获得两个系数后给定显著性水平α 值(本文取α =0.05), 进一步确定对应的Uα 值。若|g1|< U1α 且|g2|< U2α , 则表示接受正态性假设, 可认定在α =0.05的显著水平下, 该类别下文档对的相似度分布近似服从正态分布。
在通过正态化变换确定文档对相似度服从正态分布后, 需要获取包含噪声样本的文档对, 并对噪声样本进行裁剪, 以减少其对分类性能的影响。本文先计算所服从概率分布的置信区间, 根据正态分布的特性[18], 对给定的置信水平1-α , 有:
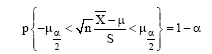 |
即:
 |
可得μ 的置信水平为1- α 的置信区间为:

通过查表求得 
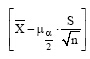
 |
其中, pi表示第i个文档占总文档对数的比例, mi表示第i文档出现的文档对数。
通过上述方法获得噪声样本后, 需要对噪声样本的识别进行正确性检验, 进一步验证挖掘的有效性。本文提出通过采用Kullback-Leibler散度即相对熵指标来度量原始的含有噪声样本的文档对分布(记为f(x))与不含噪声样本的文档对分布(记为f ° (x))间的差异, 如公式(11)所示[19]。利用Kullback-Leibler的定义, 可以对这种差异从数量上进行比较。
 |
其中, n° 表示不含噪声样本的文档对数(n° < n), 为保证两个分布能够进行差异度量, 从f(x)选择n° 个文档对使两个分布文档对数相同。相对熵指标是用来度量相同事件空间下两个概率分布的差异情况, 当两个概率分布完全相同时, 即f(x)=f ° (x), 其相对熵值为0。若计算得到的相对熵值越大, 说明噪声样本裁剪前后两个概率分布差异越大, 噪声样本对相似度分布的影响越大, 基于该方法对噪声识别的有效性越高。
另外, 同时采用噪声样本裁剪前后类别的聚类密度变化情况, 来反映噪声样本识别的有效性。一个类别下噪声样本数量越少, 其对应的该类别的聚类密度应该越高, 类别概念越清晰, 分类效果越好。若在噪声样本识别时, 将正确标注的样本错误地识别为噪声样本时, 会使得该类别的聚类密度降低。
为验证本文方法在不同领域、不同类型数据上的有效性, 实验数据采用搜狗实验室语料库(Sogou Labs)、复旦大学自然语言处理实验室基准语料库以及自建语料库进行分类实验。其中自建语料库主要包括自建图书类型的文献以及自建期刊类型的文献, 由笔者取自某大学图书馆的馆藏目录OPAC和选自中国知网的电子期刊数据库, 分别选取分类在《中图法》体系下体育、计算机技术和军事三个类别中的部分图书的书目信息和部分期刊文献作为实验材料。
由于本研究需确保分类过程中各环节透明化, 以减少中间过程的不可控因素, 因而选取支持向量机(Support Vector Machine, SVM)[20]算法构造分类器, 选取信息增益方法进行特征选择。
自动分类研究中对分类性能的评价通常采用分准率、分全率以及综合指标F1值来描述, 在对分类性能进行评价时, 存在微平均(Micro-average)和宏平均(Macro-average)[21]两个不同的测度方法。本文选择通用的宏平均F1(Macro-average F1)评价分类性能。
针对搜狗、复旦大学两种公开语料库, 选取其中6个类别进行实验, 主要包括计算机、体育、经济、军事等类别信息。针对自建图书、期刊语料库, 选取计算机、体育、军事三个类别进行实验。每个类别都随机选取400篇文档作为训练样本, 200篇作为测试样本, 以排除类别不均衡因素对分类性能的影响, 且保证训练样本与测试样本之间没有重复文本。首先计算搜狗、复旦大学两种语料库各类别的聚类密度, 然后对各类别聚类密度进行归一化处理获取样本所服从的正态分布, 最后按样本所占比例获取噪声样本。如对于搜狗语料库中的“ 计算机” 类别, 通过公式(4)、公式(5)计算出分布的偏度、峰度的值分别为-0.26、0.45, 根据SPSS描述统计分析结果, 该分布通过正态性检验。计算得到均值为-3.44, 均方差为1.16, 并根据公式(8)计算均值的95%置信区间为[-3.49, -3.32]。设定阈值ε =0.50, 则在区间[-8, -3.49]上, 计算得到噪声样本数为17, 针对搜狗、复旦大学两种公开语料, 计算各类别的噪声样本数以及各类别的聚类密度如表1所示:
| 表1 搜狗、复旦语料库各类别噪声样本分布情况 |
通过表1可以看出, 这两种公开语料库各类别中均含有一定的噪声样本, 且通过计算看出复旦大学语料库的聚类密度要高于搜狗语料库的聚类密度。
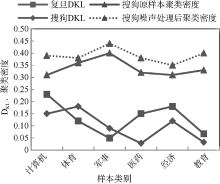
在获得噪声样本后进行裁剪, 然后计算裁剪后文档对所服从分布的相对熵以及类别的聚类密度, 以检验噪声识别的有效性, 如图2所示:
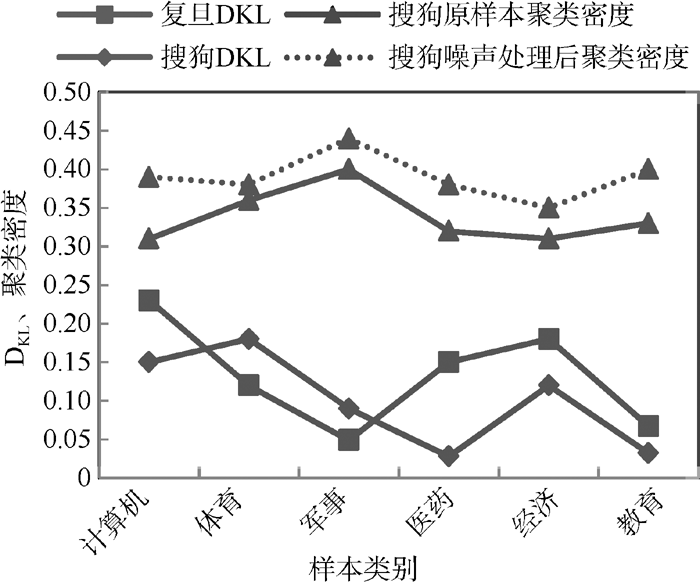 | 图2 搜狗、复旦语料库噪声处理后相对熵及聚类密度变化 |
通过计算噪声样本裁剪前后相对熵以及类别聚类密度变化发现, 噪声样本的删除对每个类别的文档相似度分布都有较大的影响, 其中类别“ 计算机” 、“ 体育” 、“ 经济” 相对熵值较高, 说明噪声样本处理使得两个概率分布差异较大。另外, 噪声样本的裁剪也使得各个类别的聚类密度都有所增大。限于篇幅, 本文只列出搜狗语料库噪声样本处理前后聚类密度的变化情况。图2说明该方法能够有效挖掘噪声样本, 使语料中各个类别的概念信息更加清晰、明确, 从而更有利于文本分类器的分类。
为进一步验证该方法的有效性, 计算搜狗、复旦语料噪声处理前后各类别上的分类准确率, 如图3所示:
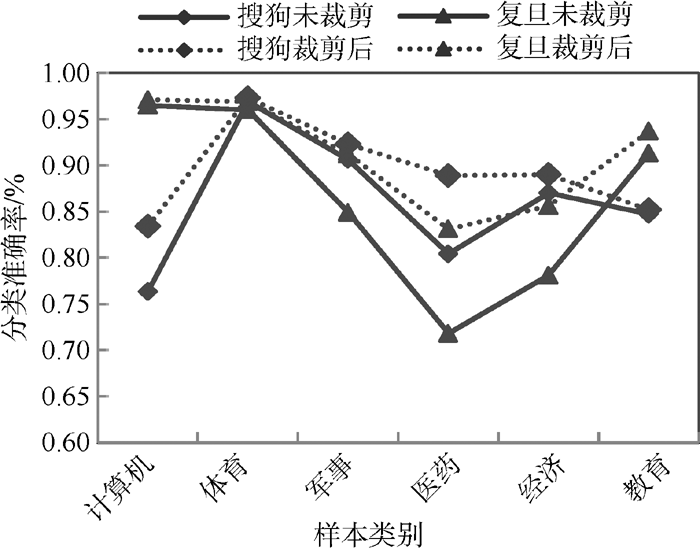 | 图3 搜狗、复旦语料噪声处理前后分类准确率比较 |
从图3可以看出, 通过删除噪声样本, 使得搜狗、复旦语料库各类别的分类准确率都得到提高, 搜狗语料库各类别分类准确率平均提高3.37%, 复旦语料库各类别分类准确率平均提高4.83%。噪声样本的裁剪使得类别的概念信息变得清晰明确, 从而使得分类器的分类性能得到提高, 验证了该方法的有效性。
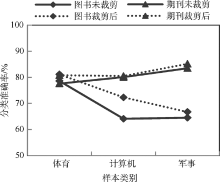
另外, 为验证本文方法在不同领域、不同类型数据上的有效性, 针对图书、期刊自建语料采用该方法进行噪声样本识别, 分类效果如图4所示:
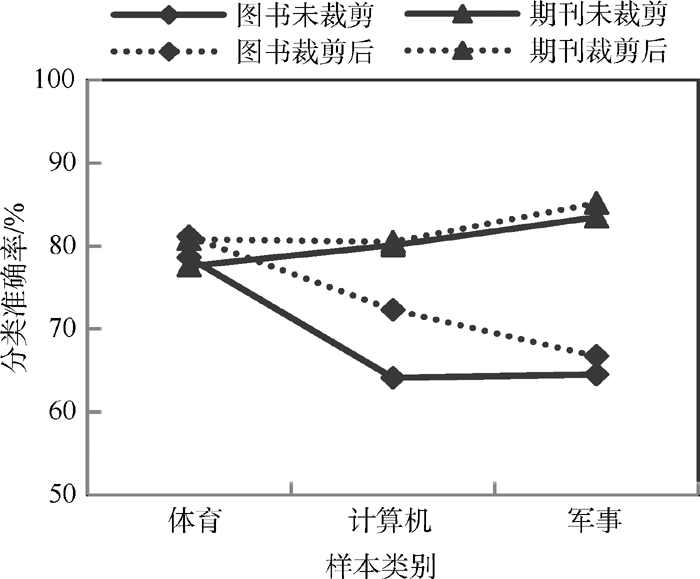 | 图4 图书、期刊自建语料噪声处理前后比较 |
通过图4可以看出, 搜狗、复旦语料库的分类效果均高于图书和期刊自建语料库, 这在一定程度上说明机器学习分类算法在应用到专门语料库时, 往往会显示出较高的分类正确率, 而一旦应用到现实世界的文本分类时, 这些系统的有效性就远远低于专门语料库中证明的结果。原因是搜狗、复旦语料取自专门的语料库, 各个样本的类别属性相对比较准确, 使其训练样本的三个类别间的界定较为清晰。而图书和期刊类型文献的实验材料是笔者直接取自于馆藏目录或电子期刊数据库资源, 对各篇文本的类别属性没有经过特别的考证。然而采用该方法删除噪声样本后, 采用SVM分类器进行分类时, 其类别“ 体育” 、“ 计算机” 、“ 军事” 的分类准确率也有所提高。
训练样本和分类算法一样, 是形成文本自动分类系统的基础和关键, 研究以数据特性驱动的分类学习方法对实际应用具有重要的意义。本文提出一种基于训练样本类别聚类密度的文本分类噪声处理方法, 通过研究该特征属性获取训练样本中的噪声样本, 以达到提高分类器分类性能的目的。通过在真实语料中的实验, 验证了该方法的有效性。该方法可以正确地识别噪声样本, 且可一次处理批量检测, 不必先判断各个噪声样本后再进行检测。今后的研究工作中, 将在依据数据特性驱动的噪声识别方法的基础上, 提出更多衡量语料类别信息的指标以提高识别噪声样本的准确性, 以及提出更多的挖掘评测方法来对噪声识别方法进行科学评价, 从而对这种方法进行可行性的改进。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|