
{kind=link}
{kind=link}
{kind=link}
医学学术信息自动采集系统的设计与实现
[武海东 , 何晓阳, 张精理]
, 何晓阳, 张精理]
, 何晓阳, 张精理]
|
|


作者贡献声明:
武海东, 何晓阳:提出研究思路, 设计研究方案;
武海东, 张精理:提出网站系统架构, 负责系统开发;
武海东:论文撰写及修订。
【目的】针对高水平期刊文献的中文导读这类特定的新闻信息, 构建一套自动汇聚医学网站新闻系统, 实现关键词提取、分类及期刊导航等二次数据加工功能。【应用背景】为图书馆开展主动推送及学科服务提供国外学术研究信息源。【方法】利用HttpClient 与HtmlParser构建主题网页采集器, 实现新闻列表页及内容采集。利用IK Analyzer2012分词器及医学主题词表实现关键词提取及学科分类。【结果】系统实现指定网站新闻的自动采集、关键词提取、学科分类归属等功能。【结论】为图书馆员开展学术信息推送及学科化服务等提供一套行之有效的工具, 为医学研究者纵览学术进展提供一站式访问。
[Objective] Aiming at Chinese news of medical research literature published on top journals, design an automatic gathering system which can gather news from different medical news websites, extract content and keywords, realize the subject classification and journal navigation. [Context] Provide information source of foreign academic research for active push and subject services.[Methods] Using HttpClient & HtmlParser to build Web-page collector, realize the news list page and content acquisition. Using IK Analyzer 2012 and MeSH to realize medical keywords extraction and subject classification.[Results] The system achieves automatic gathering, keyword extraction and subject classification of specified website news.[Conclusions] Librarians can use this system to provide effective medical academic information push service for medicine researchers.
及时关注追踪前沿信息, 提供最新学术研究动态, 是图书馆学科服务的重要工作之一。外文期刊是了解跟踪国际科研成果、水平、方向以及发展动态的重要信息载体, 是现代科技创新的重要信息源。据统计, 科技知识和成果最新信息主要是通过期刊报道的。
在生命科学与医学学科领域内, 许多医学网站开设栏目报道SCI期刊特别是高水平期刊(影响因子超过5.0)的科研动态信息, 且增加了中文解读及评论, 如:丁香园的最新资讯、生物谷的研究趋势、爱唯医学网的国外资讯、医脉通的最新进展等。这些新闻来源分散, 读者只能单个访问或定制RSS访问, 图书馆承担知识整序的职能, 因此及时汇聚最新的学术期刊报道, 并实现本地的采集、组织与分类, 主动为研究人员提供及时、全面、简捷的信息, 成为新的工作内容。
本文针对国外高水平期刊文献的中文导读这类特定的新闻信息, 自主开发了一套实现采集、组织、分类、浏览、检索等功能的系统, 旨在实时汇聚多个生物医学网站刊载的国外学术研究动态, 并实现关键词自动标引及学科分类, 为研究人员提供一站式访问服务, 节省研究人员的精力和时间, 以期带给研究人员更好的体验。
新闻采集系统是根据用户自定义的任务配置, 批量而精确地抽取网站栏目中的新闻, 转化为结构化记录并保存到本地数据库, 快速实现外部信息的获取。核心技术主要包括网络爬虫和Web页面解析技术。
基于主题网络爬虫的搜索引擎(专业搜索引擎)是当前搜索引擎和Web信息挖掘中的一个研究热点和难点。专业搜索引擎除具备通用爬行器的基本功能外, 主要能对链接及页面内容进行识别, 将目标定位于抓取与某一特定主题相关的网页, 为面向主题的用户查询准备数据资源[1]。在不同学科领域内, 国内已有针对特定领域、特定人群、资源消耗相对较小的新闻系统。贺苏伟[2]设计了一个教育新闻采集系统, 为教育新闻聚合平台提供准确、及时、整洁的教育新闻数据。系统基于链接块锚文本的主题过滤方法, 按照HTML中的< div> 和< table> 标签提取链接块。韩朝阳[3]基于国内政治新闻的三大权威网站, 通过结构分析、网页下载、语料汲取、语料XML 结构化重组等技术, 构建了中国政治新闻语料库。笔者通过检索中国知网、维普、万方等数据库, 未查询到有关医学学术新闻采集系统设计的相关文献。
新闻Web页面解析比较复杂的原因是夹杂广告信息、导航信息、评论信息等噪声内容。国内外关于去除网页噪声内容提出了许多方法, 大多采用基于块和DOM树的分析方法, 通过构建解析模板库完成主题型新闻网页正文内容的提取[4], 或者手动分析及识别页面源码, 利用正则表达式标记各新闻信息块的开始和结束标志, 实现定位抽取[5]。
本系统采取基于站点分类的新闻采集策略, 定向从指定医学新闻网站抓取最新新闻。正文页仅需采集内容文本, 无需保持源网页原框架, 可采用正则表达实现要素抽取。
医学网站网页类型和结构不同, 但数据库驱动的Web查询页面结构布局极其相似, 通常以一种半结构化的方式来组织, 因此结合正则表达式, 依据Web页面结构的模式匹配实现新闻数据采集与抽取。
基于上述思路, 笔者提出如下设计方案:
(1) 设计一个基于Web结构的新闻采集器, 采集多个网站特定栏目的新闻列表页及链接块解析;
(2) 定义页面及信息块采集算法实现新闻详细内容采集;
(3) 依据美国国立医学图书馆的MeSH词表, 实现基于新闻标题的主题词/关键词提取;
(4) 实现新闻信息的学科分类及信息来源期刊的名称抽取;
(5) 建设医学学术信息的门户网站, 为读者提供新闻浏览、检索及定制。
系统架构如图1所示。系统设计的技术重点包括Web新闻采集器、正文内容采集、关键词提取、学科及来源分类等4个方面。
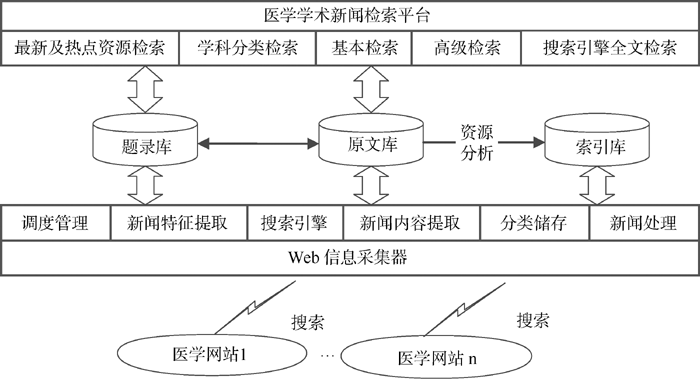 | 图1 系统架构示意图 |
系统利用HttpClient①(①http://hc.apache.org/.)与HtmlParser②(②http://www.oschina.net/p/htmlparser.)开源组件, 首先构建一个轻量级的主题网页采集器, 从指定网站或其频道栏目下的种子网页URL爬行开始, 实现该网站指定栏目下全部新闻列表页的采集。本文实现的简易采集器采用广度优先爬行策略, 仅识别抓取那些符合过滤规则的目标网页(新闻列表页)。以爱唯医学网国际资讯为例, 将采集器采集对象限定为URL以“ http:// www.elseviermed.cn/news/international/” 为前缀的网页[4]。
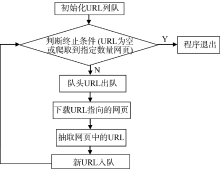
新闻列表页采集流程如图2所示:
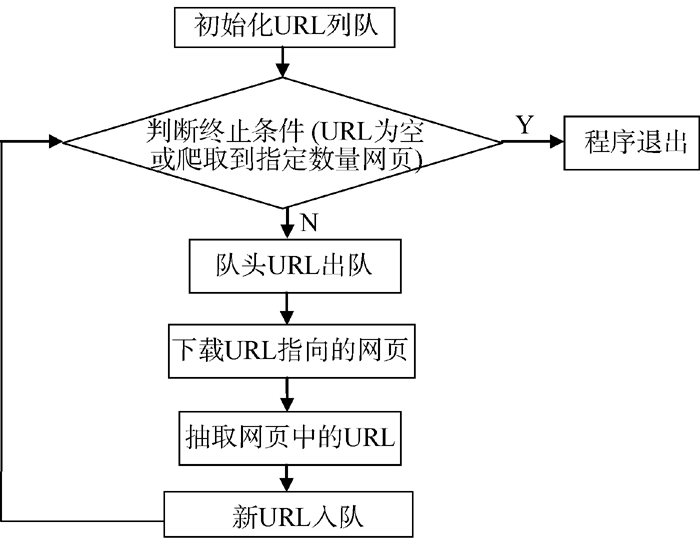 | 图2 新闻列表页采集流程 |
然后鉴别保存在本地的目标网页中新闻标题列表块的开始和结束标志, 采用HtmlParser迭代遍历新闻列表块的节点, 即解析出网页中的新闻标题与URLs, 并同步写入数据库等待处理。
部分爬取代码如下:

从数据库中循环加载待采集新闻的URLs, 利用HttpClient读取新闻正文页的源文件。手动分析页面源码, 标记新闻要素的开始和结束标志, 如:来源、内容、发表时间、编者等。系统依据每条新闻的网站来源, 分别调用对应的正则表达式, 通过页面结构的模式匹配, 实现要素抽取且同步写入数据库中。
采集医学新闻详细内容时, 通常遇到模拟登录、重定向识别及图片下载等问题。模拟登录利用HttpClient完成。首先构造网站访问的HttpPost实例, 然后填充实例的表单域类NameValuePair值, 最后将表单值(网站注册账号及密码)设置到实例方法setRequestBody中。
登录成功后可能跳转其他页面, 但HttpClient对要求接受后继服务的请求(如POST和PUT), 不支持自动转向, 因此需要判断处理页面转向, 可利用getStatusCode()方法的返回值判断是否跳转。如果跳转, 则读取HTTP头中的location属性获取新地址。
利用HtmlParser组件的NodeClassFilter过滤器抽取网页正文的所有img标签, 根据图像文件的SRC属性值读取流文件, 实现本地保存。同时替换新闻内容中图像文件的指向地址, 实现图像文件的本地浏览。
根据2011年版研究生学科专业目录, 抽取生物学与医学两大门类的二级学科名称作为导航, 系统需要自动建立起每条新闻与所属二级学科(栏目)的从属关系。
目前国内文本自动分类多依据内容进行, 需对整篇文章预处理, 包括分词、停用词过滤、关键词抽取等。处理过程繁琐耗时, 计算量庞大, 且占用大量存储空间, 抽取的关键词质量精度不高。学术文献的标题代表文章的中心主旨, 这一特点在新闻中体现的尤其明显。撰稿人使用言简意赅的字词表达整篇新闻的中心思想与主题, 达到吸引读者的目的。因此标题中术语都有特别的意义, 且非常重要[6]。系统基于新闻标题实现自动分类, 首先使用开源软件IK Analyzer2012中文分词器①(①http://www.oschina.net/p/ikanalyzer.)对采集的学术新闻标题进行普通分词, 然后以《医学主题词表》的款目词及主题词作为二次分词字典, 将匹配词作为该新闻的关键词, 旨在不仅提
高新闻分类的专指度,而且为后续的信息推送服务做好基础。主题分类的实现思路为:系统预先建立主题词树状结构号与新闻分类栏目的从属关系。例如将肿瘤(树状结构号为C04)分属于“ 肿瘤” 栏目, 而将各部位的肿瘤, 如:骨组织肿瘤(C04.557.450.565.575)分属于“ 骨科” 栏目。这样“ 骨肉瘤” (C04.557.450.565.575.650)一词同时分属于肿瘤与骨科两个栏目, 实现同一新闻归属于多个分类栏目的问题。关键词提取后, 系统将其对应的主题词及树状结构号写入数据库, 通过SQL模糊查询实现新闻的分类浏览。
医学新闻标题中通常含有期刊名称信息, 如:“ jama:妊娠期超重及肥胖或增加早产风险” , 这条新闻就包含杂志名称缩写jama(美国医学会杂志)。利用正则表达分隔字符串, 通过抽取期刊名称信息实现期刊聚类。其正则表达如下:
^([A-Za-z0-9_\\-& < > 《》. ]* +)(:|:)[\\s\\S]* //期刊名称提取正则表达
还有部分新闻标题未涉及期刊来源, 而在正文出现相关信息, 如:“ 文章发表在《中国神经再生研究(英文版)》杂志” 、“ 刊登在国际杂志The Journals of Gerontology Series A上” 等, 对于此类新闻需建立一组如上的正则匹配规则, 尽力获取新闻来源信息。
系统采用Java实现, 数据库管理选用SQL Server 2005。为提高系统性能, 网页采集器通过线程池管理活动线程。为防止给被采集网站带来单位时间的并发压力, 将同一采集区域的任务放在同一队列。目前系统运转良好, 在被搜索网站响应速度及网络速度足够快的情况下, 单台工作站每天采集约200万个网页。
系统不仅实现基本的采集功能, 而且在准确度、完整性方面也有较高要求。为了测试系统的采集性能, 选用系统配置好的丁香园、生物谷和爱唯医学网等网站进行性能测试, 测试服务器型号为IBM 3650。测试结果如表1所示。另外从系统发布的新闻中随机抽取150条记录进行人工检查, 发现系统抽取正文内容完全正确的网页达到了98%, 仅有2%的网页因频繁访问受限而未采集到正文内容, 表明系统能较好地完成自动采集任务。
| 表1 采集测试结果 |
从表2测试结果可知, 系统能准确抽取标题的关键词。但仍存在两点问题:
(1) 分词词库中缺乏对应的医学术语, 如:未提取到“ 胰岛素抵抗” (新闻1)、“ TNNI3K” (新闻3)。
(2) 部分关键词属于医学术语, 但无法确定学科分类归属, 如:发作、危险因素等, 因此建议从分词词库中去除。分词词库直接决定新闻分类的最终效果, 但并非抽取的关键词越多越好, 如新闻5。
| 表2 关键词提取测试结果 |
如何分析不同关键词在文章标题中的权重, 或者哪些关键词应被抽取是下一步工作的重点。
选择研究生学科专业目录中生物学(代码:0710)与医学(代码:10)两大门类的部分二级学科名称作为分类导航, 构成新闻网站子栏目(共17个)。系统依据抽取的关键词树状结构号自动建立每条新闻与栏目的从属关系。图3展示了“ 肿瘤” 分类下的新闻列表。
 | 图3 学科分类浏览 |
利用Java开源组件, 本文设计了一套医学新闻采集器, 通过指定网站栏目的新闻列表块采集、新闻详细内容采集、主题词/关键词提取、学科分类归属及来源期刊聚类等步骤, 自动汇聚多个医学网站发布的研究动态, 让读者及时跟进了解全球医学研究动态, 为图书馆开展学术信息推送及学科服务等工作提供一套行之有效的工具。在应用该系统及方法时, 请尊重信息提供方的知识产权, 在技术和流程上要严格遵循信息提供方提出的采集约束要求。
本系统尚处于基础研究阶段, 测试过程及结果仍存在不足, 可从以下方面改进:修正分类所需的医学主题词库, 增加款目词, 提高分类准确率; 优化采集策略, 遵守网站的知识产权要求; 解决医学特殊字符中的编码问题; 建立新闻与原文的链接, 使读者更快捷地获取源信息; 实现新闻面向个人邮箱的自动推送。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|