{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
SCI/EI文献数据融合软件设计与实现
[于健1  , 许晨
, 许晨2 , 王媚君2 , 张旻浩2 , 岳桢干2 , 吴霞3 , 赵春梅3 ]
, 许晨|
|


作者贡献声明:
于健:软件功能设计实现和论文撰写;
许晨, 王媚君, 张旻浩, 岳桢干, 赵春梅, 吴霞:参与软件功能需求分析和软件测试。
【目的】设计一款具有SCI/EI数据库文献数据查重和数据融合功能的软件。【应用背景】帮助分析人员获得来自SCI/EI数据库的文献融合数据集, 更好地满足微观学科情报分析对灵活构建多来源期刊文献数据集的需求。【方法】利用两种自动算法和一种半自动算法实现SCI/EI文献数据的准确查重, 在对两者的全记录字段进行深入微观文本分析的基础上实现数据融合。【结果】可自动标记SCI/EI文献数据的重复记录并生成查重后的融合数据表。【结论】有效解决两个不同期刊文献数据源的统一分析数据集构建问题。
[Objective] A software is designed to implement duplication checking and data fusion of the papers indexed by SCI and by EI. [Context] The software can help paper analysts obtain a dataset in the same format and meet demand of micro-analysis of subject information.[Methods] Two automatic algorithms and one semi-automatic algorithm are used to complete accurate data duplicate checking on the papers indexed by SCI and EI. Data fusion is based on detailed analysis of text features of data fields of SCI and EI.[Results] It can mark papers which are duplicated between SCI papers and EI papers and create a de-duplicated data fusion sheet.[Conclusions] The construction problem of the dataset from different data sources is solved effectively and its design ideas also can be applied to other databases.
准确构建数据集是学科情报分析的关键基础。一直以来, 基于期刊论文的学科情报分析数据集往往采用来自单一文献数据库的数据源, 尤其是文献数据格式较为规范的SCI或EI数据源[1, 2, 3, 4]。近年来, 随着交叉学科的日益兴起和微观学科情报分析的深入发展, 仅仅依靠单一数据源容易造成分析数据集不够全面或文献数据量过少的问题, 分析需求往往无法满足, 特别是在进行偏工程类学科或交叉学科的情报分析时, 越来越多的分析人员都希望整合SCI/EI(或本学科其他常用数据库)的文献数据进行分析, 因此准确查重和融合不同数据库的文献数据显得尤为必要, 这需要依赖有效的软件技术实现。
国内外已有许多关于不同数据库文献数据查重和融合方法的研究, 这些研究的应用对象集中在文献跨库检索系统[5]和近年来日益兴起的资源发现系统[6]的检索结果查重和合并展示方面, 而不断提高查重准确性一直以来都是这两类系统所面临的挑战[7, 8]。
文献跨库检索系统通常使用的数据整合方式有三种:元数据、中间件和基于代理的跨库检索[9]。文献跨库检索系统的查重方法往往采用全自动匹配查重算法, 主要分为两类:一类是采用固定文献数据字段(题名或题名作者等)进行查重匹配, 该类查重算法的优点在于运行效率较高, 但是准确性存在很大不足[10, 11]; 另一类是采用多维匹配的自动查重方法, 如郝丹等[12]在进行不同数据库文献数据查重时, 在借鉴网页查重算法的基础上设计了跨库ID多维匹配的自动查重算法, 其中对英文数据库的跨库ID设计为“ 第一作者姓的拼音+其他作者姓的首字母+出版年+起始页码” , 该方法应用于多数据库的专家/单位发文检索时得到了较好的准确性和运行效率。不过, 这些针对跨库检索系统对象所设计的查重和融合方法仍然无法满足微观学科情报分析对高准确性文献数据查重和融合的需求, 其原因如下:
(1) 与专业文摘数据库相比, 跨库检索系统往往不具有复杂检索功能, 在准确构建分析数据集方面有一定局限性, 学科情报分析人员对分析数据集的准确性要求较高的情况下, 通常并不希望使用跨库检索, 更愿意自行进入专业文摘或全文数据库中进行检索。
(2) 跨库检索系统平台均采用全自动查重算法, 无法保证查重和融合的高准确率。由于不同数据库的文献数据字段标引规则不同(如文献题名字段中化学式和粒子符号的写法不同等)以及数据库中可能存在标引字段缺失等人为标引错误, 任何全自动查重算法都不可能做到真正的查重。
(3) 跨库检索系统平台为了保证从多数据库返回格式统一的检索结果, 往往只合并展示少量文献数据字段, 这种少量字段的简单数据集不适合学科情报多维度分析的需求。
自2008年OCLC发布首个资源发现系统WorldCat Local以来, 其使用率不断提高[13, 14], 这类系统还包括ProQuest Summon、Ex Libris Primo、Primo Central和EBSCO Discovery Service等。在这类发现系统中, 采用元数据集中索引方式整合不同数据库资源成为主流趋势, 其查重方法相较跨库检索系统也有了很大程度的改进, 如Primo采用基于作者和题名字段的书目记录功能需求(FRBR)查重算法[15, 16], OCLC WorldCat Local采用重复记录检测与解析(DDR)查重算法[17], 同时使用FRBR[18]和全球图书馆载体表现标识符(GLIMIR)[19]来聚类合并展示检索结果。由于资源发现系统建立了统一的元数据索引库, 因此其元数据查重类似于传统图书馆编目系统的元数据查重, 可以利用长期以来编目人员针对文献编目系统元数据查重方法上的研究成果[20], 资源发现系统中元数据查重准确性的提高也强烈依赖于元数据质量的规范控制和查重算法的改进, 这类查重算法的准确性改进可以归纳为元数据字段多种写法的规范化、标准化和针对不同类型对象建立合适实体模型两个层面。
虽然以OCLC WorldCat Local为代表的资源发现系统的文献数据查重方法有了长足发展[21], 但是目前仍然有很大的改进空间[17], 而且它们均无法直接应用于不同文献数据库的文献数据查重和融合, 也不能满足微观学科情报分析数据集的构建需求。不过, 从这类元数据查重方法的发展可以看出, 提高文献数据查重准确率的关键在于有针对性地深入分析具体查重对象存在重复文献数据的原因, 尽可能多地挖掘出具体查重对象的字段和字段写法差异, 同时还要综合利用多种查重方法和技术途径。
目前, 一些工具类软件具备期刊论文查重或数据融合的功能, 如文献管理工具EndNote[22]和文献分析工具TDA[23], 不过这些工具的查重功能也是基于固定文献数据字段的直接匹配, 如作者、题名、期刊等, 用户在使用时往往会面临难以确定合适查重匹配字段的问题:如果匹配字段选择过多会造成查重标准过于严格, 从而漏掉重复文献, 而匹配字段选择太少则会导致查重错误, 并且它们没有标记相互重复文献的功能, 无法确保查重和融合的准确率。
本文设计的软件是针对微观学科情报分析发展过程中所呈现出的高准确性文献数据查重和融合的技术瓶颈问题, 充分挖掘期刊论文数据字段重复特征, 构建多种查重算法, 并采用人工交互的半自动查重方式确保查重和融合效果, 以帮助分析人员准确构建来自不同期刊论文数据库的分析数据集。
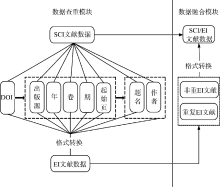
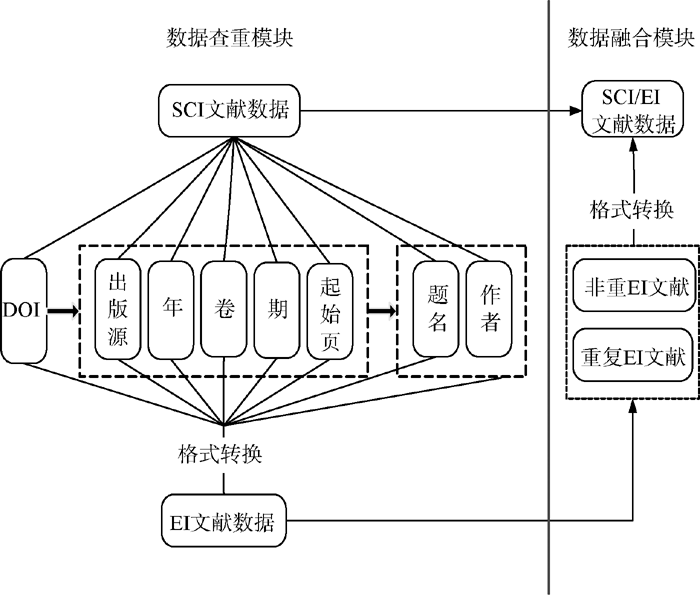
本软件主体架构由“ 文献数据查重” 和“ 文献数据融合” 两个模块构成, 如图1所示:
本模块需要解决的第一个关键问题是如何针对特定对象SCI/EI数据库中的文献数据, 充分挖掘两者文献数据的字段对应关系以及各字段微观文本特征, 以构建高准确率的查重算法, 这也是本软件设计和实现的核心问题。为了实现该目标, 笔者结合工作实践, 总结SCI/EI文献数据库中存在重复文献数据的原因并构建相应的查重算法, 包括:
(1) SCI和EI作为文摘数据库收录了部分相同出版源, 这是SCI/EI 数据库中存在重复文献数据的主要原因。
(2) SCI/EI文献数据标引规则存在差异, 如表1所示:
| 表1 SCI/EI数据库字段标引差异和处理方法 |
(3) SCI/EI文献数据存在人为标引错误, 如拼写错误或字段缺失等。
由重复因素(1)所产生的SCI/EI同一出版源重复文献的查重, 可以依靠确定SCI/EI文献数据唯一性的单文献数据字段或字段组合匹配自动实现, 即文献唯一标识符字段DOI以及出版源、年、卷、期和页的字段组合匹配, 相应构建DOI查重算法和出版源年卷期页查重算法。在构建出版源年卷期页查重算法时, 基于SCI和EI文献数据字段特征, 采用出版源全称、简称、ISSN、ISBN和会议名称5种出版源匹配方式, 其中任意一种方式匹配成功都表示文献数据的出版源相同, 以提高查重准确性。表2为SCI/EI文献数据查重所需字段。
| 表2 SCI/EI文献数据查重所用字段 |
由重复因素(2) SCI/EI文献数据标引差异所产生的重复文献有两种查重方法:
(1) 对于字段出版源全称、ISSN和ISBN的标引差异, 这些字段进行数据格式标准化预处理后仍然很有可能通过出版源期刊年卷期页自动查重算法实现查重。
(2) 对于字段题名和作者的标引差异, 则可以通过构建题名作者查重算法实现查重。
题名作者查重不具有唯一性, 该算法是一种半自动查重算法, 是对前两种算法的补充, 即在由于DOI字段为空或SCI/EI文献数据写法差异而造成前两种查重算法无效的情况下, 根据题名和作者相似性自动查找相似文献数据, 所得查找结果还需要进一步通过人机交互确认是否是重复文献。该算法不仅可以查出因数据库标引加工错误而造成前两种算法查重失败的重复文献, 还可以查出一稿多刊的文献, 分析人员可以根据实际情况判定它们的重复性。
而对于由因素(3)即文献数据人为拼写错误或字段缺失所产生的假象重复文献, 采取对自动查重算法执行严格精确匹配的措施, 即在执行不需人工交互确认的自动精确匹配算法查重时, 必须所有字段不为空且匹配文献数据的全部所需字段才能被确定为重复文献, 同时将上述三种查重算法设计为递进关系依序执行, 即首先执行严格精确匹配自动查重算法, 待模糊匹配查重时通过人机交互确认假象重复文献数据的重复性。
本模块中三种递进查重算法实现伪代码如下:

本模块需要解决的另一个关键问题在于如何将SCI/EI文献数据中题名和作者相似的文献提取出来供人工确认, 即设计和实现两篇文献的题名作者模糊查重算法。
题名相似性判定是通过构建余弦相似性函数实现的, 计算公式[24]为:
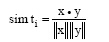
其中, x和y分别代表待查重的SCI, EI文献题名文本的词频向量。题名相似性判定过程为将待判定文献题名以空格进行切词, 然后利用余弦相似性函数计算相似度。
作者相似性的判定公式为:
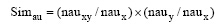
其中, nauxy表示两篇文献相同作者数, naux表示SCI文献全部作者数, nauy表示EI文献全部作者数, 该公式可避免因数据库文献数据标引错误即遗漏个别作者时查重失败的情况出现。
SCI文献数据含两个作者字段AU和AF(见表2), 其中AU是作者简写, AF与原文中作者写法一致, 而EI文献数据作者字段与原文中作者写法相同, 因此本模块分别采用SCI的AF字段和EI的Authors字段来进行作者相似性判定。
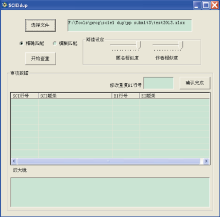
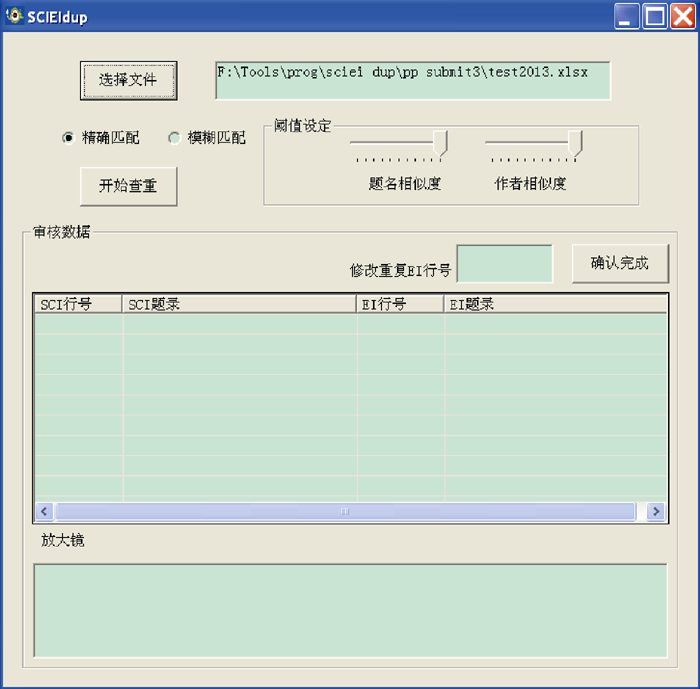
为了实现本模块的题名作者模糊查重算法, 在软件界面上使用两个Slide滑块控件, 如图2所示, 其最小值和最大值均分别设为0和1, 允许用户根据分析文献特征灵活调节题名和作者判定的相似性阈值。人工交互确认重复文献的界面使用ListView控件, 呈现通过半自动查重算法查找到的相似文献数据。该控件共含4列, 包括SCI文献行号和该文献详细信息(包括出版物名称、出版年、作者和题名)以及EI文献行号和该文献详细信息。在软件界面上同时使用富文本控件显示文献的详细题录信息, 允许用户放大查看详细信息并确认选择重复文献数据。还允许用户自行输入与某SCI文献相重复的EI行号, 此处允许多篇重复。
此外, 软件界面上还设计“ 精确匹配” 和“ 模糊匹配” 两个单选按钮控件实现精确匹配和模糊匹配两种查重方式, 选择精确匹配方式表示软件仅使用DOI和出版源年卷期页的两种全自动精确查重算法进行查重, 适合在查重准确性要求不高的情况下使用, 而模糊匹配方式表示软件除了使用两种精确匹配方式以外, 还将使用题名作者半自动查重算法对文献数据进行查重, 这种匹配方式可以获得更高的准确性。
该模块需要解决的关键问题是如何将两种文献数据的格式统一。考虑到大多数文献分析软件均支持SCI文献数据格式, 本模块设计为将EI文献数据中与SCI不重复的数据转换为SCI文献数据格式并生成查重和融合后的总数据表。目前SCI/EI文献数据所共有的全记录字段如表3所示:
| 表3 SCI/EI文献数据融合所用字段 |
由表3可知, SCI、EI文献数据融合所用的共有字段中, EI文献数据大多数字段与SCI字段格式相同, 可直接赋值完成转换。有以下字段(斜体加黑)的格式存在不同程度差异, 需要在特定处理后再进行赋值转换。具体如下:
(1) 附加关键词和学科类别字段, 需要进行简单的格式转换, 将EI中的分隔符“ - ” 转换为SCI中的“ ; ” 。
(2) 作者关键词字段, 合并EI文献数据字段Main heading和字段Controlled terms并进行类似附加关键词的格式转换。
(3) 开始页和结束页字段, 需要将EI中的Pages字段进行拆分。
(4) 国际标准期刊号(ISSN)字段, 合并EI文献数据字段ISSN和字段E-ISSN。合并原则为若字段ISSN为空, 则补充赋值字段E-ISSN并进行格式转换, 即该字段若不足8位则补足8位并在前4位后添加分隔符“ -” 。
(5) 国际标准书号(ISBN), 需要将EI文献数据字段ISBN-10和字段ISBN-13进行合并, 合并原则为若字段ISBN-13为空, 则补充赋值字段ISBN-10并转换为ISBN-13。
(6) 作者地址字段, 需要合并EI文献数据字段Authors和字段Author affiliation, 将同一地址的作者进行同类归并, 如表4所示:
| 表4 SCI/EI作者地址字段格式示例 |
(7) 通讯作者地址字段, 由于目前EI文献数据的通讯作者地址字段不全, 因此需要从字段Author affiliation中提取通讯作者地址并进行格式转换。
(8) 通讯作者邮箱字段, 需要从Author affiliation字段中进行拆分。
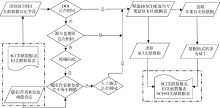
本软件是在VB 6.0环境下开发的, 完整流程从调用含SCI/EI文献数据表的Excel文件对象开始, 到写入包含与EI重复行号的SCI文献数据表、与SCI重复
行号的EI文献数据表以及融合数据表的Excel文件对象结束, 如图3所示:
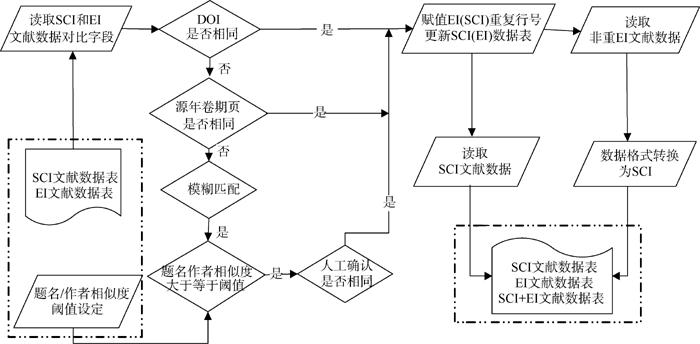 | 图3 软件实现流程 |
笔者使用该软件测试查重和融合“ 碲镉汞高性能红外焦平面技术” 2000-2012年间的1 987篇SCI文献数据和2 668篇EI文献数据, 以构建碲镉汞高性能红外焦平面技术分析数据集。
首先, 制作融合数据所需Excel文件(含SCI/EI两个原始数据表)。
在SCI数据库中保存文件格式为Tab-delimited (win)并导入Excel文件的第一个数据表中。在EI数据库中保存文件格式为Excel并导入Excel文件第二个数据表中。
若已保存文件格式为Plain Text, 则需要使用笔者制作的SCI文献数据格式转换工具或EI文献数据格式转换工具转换为本软件所需的Excel文件格式[25, 26]。
在图1所示的软件界面中选择准备好的Excel文件, 默认打开文件路径为软件所在文件夹, 然后点击选择查重匹配方式, 默认为精确匹配方式, 即软件将采用DOI和出版源年卷期页两种全自动查重算法进行查重, 不需要人工审核。若点击模糊匹配方式, 则除了使用全自动查重算法外, 还会使用题名和作者半自动查重算法进行查重, 半自动查重算法所查到的相似文献数据需要通过人工审核确认重复性。
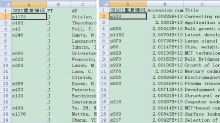
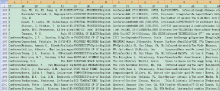
图4和图5分别显示了精确匹配方式查重标记结果和数据融合结果。从图4中可以看出, 软件在SCI数据表的第一列已填写了与EI重复的文献数据行号, 在EI数据表的第一列已填写了与SCI重复的文献数据行号。图5为新生成的融合数据表, 共含3 271篇文献数据, 其中包含1 987篇SCI文献和经格式转换后的1 283篇非重EI文献数据。将融合数据表使用SCI文献数据格式转换工具[25]转换为Plain Text格式后, 可以导入TDA或CiteSpace等软件进行进一步分析。
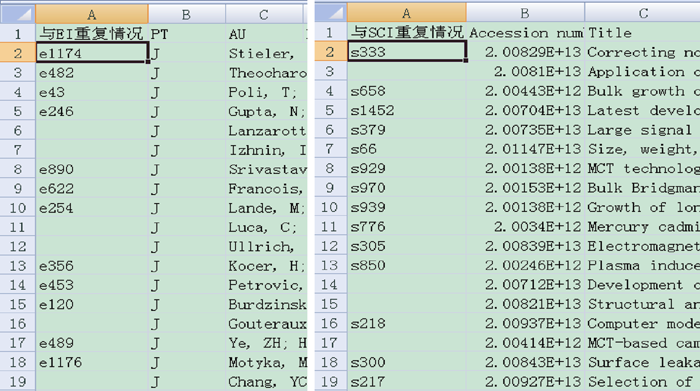 | 图4 SCI/EI测试文献数据查重标记结果 |
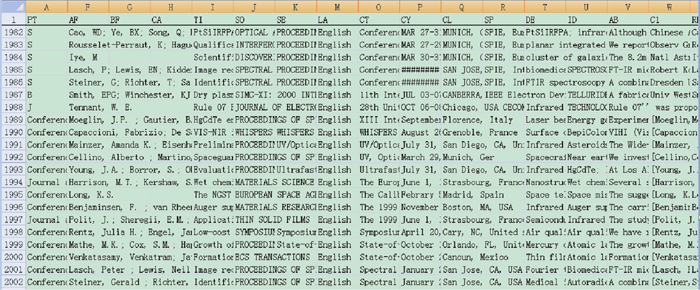 | 图5 SCI/EI测试文献数据融合数据表 |
表5展示了1 987篇SCI和2 668篇EI测试文献数据查重和融合效果。本软件为满足多次查重需求设计了重新查重和补充查重两种模式, 重新查重模式即覆盖之前查重结果从头开始查重和融合, 补充查重即在之前查重结果的基础上进行查重。为了方便呈现测试效果, 表5为重新查重模式下的测试结果, 且临时在软件中加入计时器以获得测试运行时间。
| 表5 SCI/EI文献测试数据查重和融合效果 |
由表5可知, 在精确匹配模式下, 软件融合所花时间最少, 但是所得融合数据表的文献数量最多, 说明里面仍然可能存在重复的文献, 而在模糊匹配方式下, 加入了人工交互的题名作者半自动查重, 因此所得融合数据表中的文献数量较少, 融合准确度较高, 且题名和相似度阈值设定得越宽松, 人工交互确认重复的文献数据量越多, 融合准确度越高。
本文从实际需求出发, 结合工作实践设计开发了一款SCI/EI文献数据查重和融合软件。该软件可以辅助文献情报分析人员构建来自不同数据源的分析数据集, 保证分析数据集的全面性。该软件还可以标记相互重复的文献数据记录行号, 辅助论文统计者掌握所统计论文在两个数据库的重复收录情况。此外, 可以在标记文献数据重复记录号的基础上将非重EI文献数据转换为统一的SCI文献数据格式, 最终生成融合数据表。辅以笔者开发的SCI文献数据格式转换工具, 将该融合数据表转换为纯文本格式后, 可以方便导入TDA、CiteSpace等分析软件中进行进一步分析, 从而拓展微观学科情报分析的全面性和准确性。该软件可直接应用于与SCI数据库文献数据格式相似的ISTP等Web of Science数据库, 其设计思路同样也适用于其他数据库; 还可以通过增加多维匹配等其他模糊匹配查重算法进行改进, 并允许通过设置阈值实现全自动匹配查重, 以适应准确性要求不太严格的大批量SCI/EI文献数据的查重和融合需求。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|