{kind=link}
面向文本挖掘的植物生长发育实体识别研究
汪润, 何琳 , 王东波, 黄水清, 范远标
, 王东波, 黄水清, 范远标
, 王东波, 黄水清, 范远标
|
|


作者贡献:
何琳,黄水清:提出研究思路,设计研究方案;
汪润:进行实验;
范远标:数据采集和清洗;
汪润,何琳:论文起草;
王东波:最终版本修订及数据结果评价分析。
【目的】 研究从文本中识别植物生长发育实体(Plant Growth and Development Stage Named Entity, PDSE)的抽取。【应用背景】PDSE从本质上来说是一种命名实体。目前有关命名实体的识别已经成为自然语言处理领域最有价值的基础技术之一, 被广泛应用于多种自然语言处理系统中。【方法】采用基于条件随机场和规则的混合策略, 提出并实现针对PDSE特征的CRF特征模板、特征函数以及抽取规则的方法, 并利用PubMed数据库收录的论文进行抽取效果测试。【结果】实验表明本文提出的混合策略能取得较高的准确率和召回率。【结论】本研究对生物学文本抽取具有一定的借鉴意义。
[Objective] This paper researches in the extraction that identifies plant growth and development stage entity from text. [Context] PDSE is a kind of named entity essentially. Named entities recognition has become one of most valuable basic technologies in Natural Language Processing field, which is used widely in many Natural Language Processing systems. [Methods] It adopts multiple strategies based on conditional random field and rules, with putting forward and realizing a method of CRF template, characteristic function and extraction rules for the features of plant growth and development stage entity. Also, it tests the extraction effect by articles from the PubMed database. [Results] The experiment shows that the proposed hybrid strategies can obtain high accuracy and recall rate. [Conclusions] This research has a certain significant reference for biology text extraction.
植物的生长是指植物的营养生长, 包括种子萌发及根、茎、叶等营养器官的出现和生长, “发育”则是通常指生殖生长, 包括成花、开花、结实的过程。植物整个生长发育时期涉及到不同细胞间信号代谢通路、不同基因的表达以及基因网络的调控, 因此, 从文本中抽取相关的植物生长发育时期对于生物医学文本挖掘研究具有重要的意义, 不仅可以辅助建立植物基因表达数据库、规范化实验过程数据, 而且更有助于基于文本的非相关文献知识发现, 为科研人员提供潜在的研究方向。
植物生长发育时期从本质上来说是一种命名实体, 目前有关命名实体的识别(Named Entity Recognition, NER), 如地理行政、产品和基本名词短语实体[1, 2, 3]等的识别已经成为自然语言处理领域最有价值的基础技术之一, 被广泛应用于自动问答、信息提取、信息检索、文本自动摘要等自然语言处理系统中。专门针对植物生长发育时期进行命名实体识别的研究还非常少见。本文通过对植物生长发育时期命名实体的特性识别和分析, 利用已有的命名实体研究成果, 将植物生长发育时期视作包含时间表达式的命名实体进行研究和抽取, 专门针对植物生长发育时期的识别和抽取进行研究。
对时间信息的关注最早出现在消息理解会议(Message Understanding Conference, MUC)的评测, 随后MUC把时间信息识别作为命名实体识别的一个子任务。MUC-7会议上相对时间的识别扩展成为时间信息抽取命名实体的时间识别子任务。真正推进时间信息抽取研究的是美国政府高级研究计划署(Defense Advanced Research Projects Agency, DARPA)的跨语言信息检测、抽取和摘要项目(Translingual Information Detection, Extraction and Summarization, TIDES)以及美国国安局(National Security Agency, NSA)的自动内容抽取项目组建的时间表达式识别和归一化(Time Expression Recognition and Normalization, TERN)评测[4]。其中TERN的目标是根据TIMEX2标注规范标注英文和汉语源文本中的时间表达式, 并解释时间短语的含义[5]。时间短语抽取主要分为以下4种方法:
(1)基于规则的方法是较早使用的传统方法。Saquete等[6]在关于西班牙语时间表达式抽取中获得较好成绩。一般而言, 当提取的规则能比较准确地反映语言现象时, 基于规则的方法性能会优于基于统计的方法。但是规则制定往往依赖于语言种类、所属领域和文本风格, 编制规则比较耗时, 且很难覆盖所有语言现象。
(2)基于自动机和词典的方法需要使用有穷自动机, 并包含时间相关的词汇字典。Schilder等[7]使用此方法获得简单时间表达式标注结果优于复杂时间表达式。该方法中自动机建造一般需要手工完成, 特别是自动机的语义定义, 因此工作量仍然很大。
(3)错误驱动学习算法[8]容易学习一些潜在的语言规则, 具有将语言学特性与其他模型很好耦合的优点。贺瑞芳等[9]研究发现启发式搜索A*算法的策略在耗时和测试成绩两方面综合性能最好。但启发式错误驱动学习只对时间表达式的正面特征进行学习, 并没有学习其负面特征。
(4)基于机器的学习方法是将时间表达式识别看作一个序列标注的过程。Hacioglu等[10]使用支持向量机(Support Vector Machine, SVM)对中文和英文文本进行识别。Ahn等[11]首次使用条件随机场(Conditional Random Field, CRF)抽取时间表达式。欧阳佑等[12]实验发现由于SVM没有考虑类似CRF的序列信息, 使用相同特征情况下SVM效果要逊于CRF。朱莎莎等[13]在融入POS词性、词典和位置特征后, 中文时间短语识别准确率和召回率均大幅提高。许旭阳等[14]在使用CRF识别的基础上加入自定义规则, 同样使机器识别效果增强。但目前机器学习易受训练语料规模和范围的限制。
以上4种方法中, 结合时间、效率、抽取精度及抽取全面性等角度考虑, 基于规则和基于机器学习的方法是最为常用的两种方法。由于植物生长发育时期包含部分本质为时间信息, 但不同于单纯的时间信息, 标注对象需要与植物的生长和发育紧密相关。所识别对象可以看作时间信息和植物本体组成的整体, 即包含时间和植物信息的命名实体。因此本文采用机器学习和规则相结合的方法, 通过规则的叠加使用来降低机器学习方法对大规模训练语料的要求, 并通过概率的计算来减少规则观察和总结的盲目性与复杂性[15]。在研究生长发育时期命名实体识别任务的基础上, 考虑到领域植物本体PO对命名实体识别的支持, 提出了融合词性特征、左边界词特征、中心词特征以及本体特征的多特征统计模型进行植物生长发育时期命名实体(Plant Growth and Development Stage Named Entity, PDSE)的识别。
本文首先对植物生长发育实体进行人工标注, 通过统计分析总结植物生长发育实体的特征和上下文环境特点, 为建立CRF的特征函数和抽取规则提供依据。虽然部分PDSE之间具有共同语言现象, 但大部分之间并不具有。考虑到识别的准确性和召回率, 本文采取基于CRF和规则的混合策略进行植物生长发育实体的识别。首先对文本进行预处理, 包括篇章文本断句、词性标注、特征添加。使用GENIA Tagger(
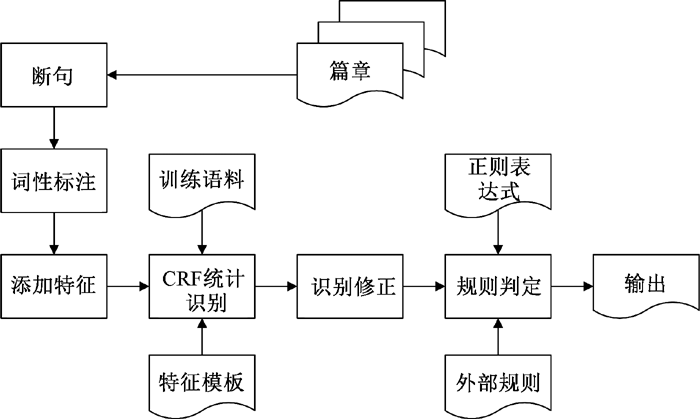 | 图1 PDSE系统架构 |
自CRF的概念被Lafferty等[16]提出以来, 它便在自然语言处理和图像处理等领域取得广泛应用。本文把PDSE识别问题看作一个序列标注任务。对于一个句子, 可将其看作一个由有序的词组成的序列, 该句中PDSE的用法与上下文之间有着紧密的联系。不同的上下文中, 同一个PDSE的用法可能不同。
CRF可被视作一个无向图模型, 在给定输入节点的条件下该模型计算输出节点条件概率, 其训练目标是使得条件概率最大化。最简单的CRF形式是线性CRF, 即模型中各节点构成线性结构。一个线性CRF对应一个FSM(Finite-State Machine), 适用于线性数据序列标注。
对于植物生长发育时期命名实体识别, 给定一个序列X=(x1, x2, …, xn)为输入观测序列和一个长度与X相等的序列Y=(y1, y2, …, yn)为状态序列。对于输入序列X和标记序列Y, 定义一个CRF模型如下:
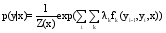
其中, Z(x)是归一化因子;n表示给定词序列的长度; fk(yi-1, y, x)是特征函数, 既可以表示无向图边的转移特征 e(yi-1, y, x), 也可以表示节点的状态特征 v(yi, x, i);λk是第k个特征函数的权重系数。
实验采用B、I、O三个标注符号的表达方法来表示每个输入单元。在字一级进行PDSE识别时定义了三种标记的集合L={B-PDS, I-PDS, O}。每个标记的意思分别是:PDSE开始, PDSE内部以及其他。
例如, 输入序列:
X={flag, leaves, from, 5, days, after, flowering}
对应的标注序列为:
Y={O, O, O, B-PDS, I-PDS, I-PDS, I-PDS}
通过对植物生长发育描述实体的标注和统计分析, 选取词特征(Word)、词性特征(POS)和左边界词特征(LBd)、提及中心词特征(Head)4个特征函数来对植物生长发育实体进行描述。
(1)词特征:考虑观察值来自于输入观察序列本身, 涵盖很多语言信息。通过大量的实验结果表明, 如果训练集合的规模比较大, 只用考虑词本身就可以获得比较好的效果。
(2)词性特征:观察值来自观察序列的词性信息, 文中的词性信息对提取实体具有启发作用。
(3)左边界词特征:根据PDSE所提及的信息以及收集语料的统计数据, 左边界词主要为介词, 如for、after、at等。
(4)提及中心词特征:从语料中观察和提取出实体的中心词作为特征, 如days、old、stage等。
图2选取的标注实例片段, 第1列为词特征, 第2列为词性特征, 第3列为左边界词特征, 第4列为提及中心词特征, 第5列为人工Chunk标记。
图2语料标注片段详例
特征的定义直接影响到实验结果的好坏, 但特征融合的方法也不容忽视。通过定义一个模板来筛选特征, 目的是为了更大限度囊括语言现象, 构建反映语言内在规律的模型。特征模板能体现对上下文特定位置乃至特定信息的考虑。CRF模型最大的优点是不仅能综合利用字词、词性等上下文信息, 还能融合各种外部特征, 避免碎片化的同时还可以集成任何知识源。因此, 本文在特征模板的选取中融合了一元特征、二元特征以及多元特征, 并经过多次实验择优选择。结合图2标注的语料, 假设当前位置为单词“days”所在位置, 表1说明了特征模板的含义。本文主要结合表1所列特征类型进行抽取, CRF的训练和测试工具采用CRF++ Toolkit[17]。
| 表1 特征模板项示例 |
| 图2 语料标注片段详例 |
植物生长发育时期实体中部分具有共同语言现象, 它们包含相同的构造特点。因此需要根据时间实体的特点以及上下文语境信息建立植物生长发育实体的抽取规则。
(1)包含数字、时间单位的三段式规则
实体呈现出“<1>-<2>-<3>”的形态。其中“<1>”为数字(CD), 包括阿拉伯数字形态和单词数字形态的数字;“<2>”表示时间单位的名词(NN), 例如day, week, month, year, d等;“<3>”是单词old。“-”代表半角短线符号, 下同。
(2)包含数字、植物组成结构部分的三段式规则
实体呈现出“<1>-<2>-<3>”的形态。其中“<1>”为数字(CD), 包括阿拉伯数字形态和单词数字形态的数字;“<2>”表示植物组成结构部分名词(NN), 例如leaf, growth等;“<3>”是单词stage。
(3)包含植物生长发育阶段的两段式规则
实体呈现出“<1>…<2>”的形态。其中“<1>”表示植物生长发育阶段名词(NN), 例如booting, flowering, booting, tillering等;“<2>”是单词stage或stages。“…”代表半角空格符号。该结构可由介词引出, 例如at、after等。并可以介词短语结尾, 例如before flowering等。
当PDSE单独做句子主语时, 其后多跟随were等谓语动词。
(1)使用英文分词系统对测试文本进行切分, 得到连续的单词初步切分;
(2)针对三段式和两段式的规则创建正则表达式;
(3)从左至右扫描初步切分的单词, 查找出满足正则表达式字段作为待判别实体;
(4)根据外部规则, 判定待判别实体是否符合规则。若判别成功, 则将其标记为成功判别实体;
(5)继续扫描后续的文本。若至文本末, 结束扫描;若未至文本末, 则转至步骤(3)。
使用rice、corn、maize等检索词检索PubMed Central数据库(http://www.ncbi.nlm.nih.gov/pubmed central)从2000年至今所有研究论文。随机抽取300篇论文, 根据生物医学论文研究的特点, 描述植物生长发育实体的句子基本出现在实验材料部分, 因此抽取Material部分进行人工标注, 共提取出516句含有植物生长发育实体描述的句子, 约15 594个词语料, 按照比例8: 2将语料分为训练语料和测试语料。
本文采用通用的评价指标准确率、召回率和F1值对抽取结果进行评价。
准确率(P)=正确标注的实体提及个数/标注的实体提及总个数×100%
召回率(R)=正确标注的实体提及个数/正确的实体提及总个数×100%
F1=(2×P×R) ×100%/(P+R)
本文利用训练语料生成的模型, 对测试语料进行了实体识别, 将其分成6组进行实验, PDSE识别效果如表2所示:
| 表2 PDSE识别结果 |
从以上实验结果的准确率、召回率和F1值可以看出, 本文所选特征对PDSE识别取得了较好的效果。CRF对特征具有较强的融合能力, 随着特征集的增加, 实体识别效果有所提高。其中POS词性特征对实体识别效果的提高起到了重要的作用。LBd和Head特征的加入也提升了识别效果。引入向量空间模型筛选出的中心词, 例如词“leaf”和“leaves”对PDSE的识别效果也起到了积极的作用。
从实验结果不难发现, 单纯采用CRF方法进行抽取可以获得较高准确率但召回率偏低。主要原因是观察被机器标注后的语料发现, 由多个单词组成的复合词形式的PDSE很少被机器标注, 如three-leaf-stage, two-week-old等, 这些复合词形式的PDSE是具有共同语言现象的实体, 如包含数值和时间单位, 这些词在训练语料中Chunk被标注为B-PDS, 同时没有I-PDS的Chunk紧跟其后, 形如{…, O, B-PDS, O, …}, 这种独特的构造形式使得其内部规则不能被CRF发现, 从而很大程度上影响了机器识别效果。
为了提高召回率, 本文同时使用包含正则表达式的规则方法, 按照事先自定义的规则, 如之前提到的“三段式”结构, 优先判定复合词形式实体内部规则, 如单词内是否包含“-”短线符号, 是否包含数值和类似week、day的时间单位等。然后结合上下文进行外部规则判定, 从而很好地解决复合词内部规则无法被捕获的问题。实验证明加入规则约束后, 机器能够标注更多复合词形式的PDSE, 召回率显著提升。与单纯CRF相比, 准确率有所损失, 原因包括含有词“stage”的个别非PDSE复合词被误选, 如developmental stage, 但F1值的有效提升说明规则在消除机器学习对大规模语料依赖方面贡献突出。将来引入POS词性的联合结构, 可以进一步提高识别的精度。
本文通过对植物生长发育时期命名实体的统计和分析, 提出基于条件随机场和规则的混合策略进行植物生长发育实体的识别方法, 并设计了有效的特征模板和特征函数集合, 针对基于统计方法的不足, 建立了专门的抽取规则和实现方法, 提高抽取的准确率和召回率。通过测试表明本文提出的植物生长发育实体识别方法能够取得较好的效果。下一步的研究工作则是针对一些漏识、误识的缺陷进行修正, 并结合语义特征信息来提高植物生长发育实体识别效果。
| 1 |
|
| 2 |
|
| 3 |
|
| 4 |
|
| 5 |
|
| 6 |
|
| 7 |
|
| 8 |
|
| 9 |
|
| 10 |
|
| 11 |
|
| 12 |
|
| 13 |
|
| 14 |
|
| 15 |
|
| 16 |
|
| 17 |
|