
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于特征翻译和潜在语义标引的跨语言文本聚类实验分析
邓三鸿 , 万接喜, 王昊, 刘喜文
, 万接喜, 王昊, 刘喜文
, 万接喜, 王昊, 刘喜文
|
|


通讯作者 邓三鸿, E-mail: sanhong@nju.edu.cn
作者贡献:
邓三鸿: 提出研究思路;
王昊:设计研究方案;
万接喜:采集数据、进行实验、论文起草;
邓三鸿,刘喜文:论文最终版本修订。
【目的】通过多组实验来分析跨语言文本聚类中的基于特征翻译和潜在语义标引性能、注意事项和发展方向。【方法】从有关双语站点选取2 736篇中英文对齐的双语新闻语料, 以基于特征翻译和潜在语义标引这两种方法分别进行文本聚类实验, 并进行各自召回率、准确率、F值的对比。【结果】基于特征翻译的方法处理相对简单, 能明显提升多语言文本的聚类效果;基于潜在语义标引的方法由于方法自身在时间和空间复杂度以及其他固有缺陷, 最终结果差强人意。【局限】样本丰富度有待进一步扩展, 期待在高性能计算环境下对LSI方法进行更全面的实验。【结论】基于特征翻译的方法需进一步提高翻译系统的性能, 而LSI方法则需要解决计算复杂度、K值选取等问题。
[Objective] Analyzing the performance, the crucial points and direction of characteristics translation and LSI in cross-language text clustering.[Methods] Selecting 2736 Sino-British bilingual news text from some bilingual websites, complete the clustering test with these two methods and compare the parameters, such as recall rate, accuracy and F value.[Results] Characteristics translation method improves clustering while the LSI method doesn’t get a good result for its time and space complexity. [Limitations] Samples need to be expanded and the LSI experiment need to be repeated in a high-performance computing environments.[Conclusions] Characteristics translation method need some more effective translation system, and the LSI method need to solve the calculation complexity and the select of the K value, etc.
多语言文本聚类是指在多语言的环境下(即文档集中各文档所使用的语言是不同的)完成文档的聚类操作, 其关键在于如何消除语言的不同所带来的特征项权重标记的问题, 以汉英双语为例, 传统的文本挖掘技术在统计“计算机”和“Computer”时, 会将其分别统计, 而实际上它们应该作为等同词汇参与聚类, 它们所在的文档同属于一个类别的可能性也比较大。
早期的文本聚类主要是在单语言环境下进行, 而多语言的文本聚类研究则不够成熟。章成志等将多语言文本聚类方法划分为“先聚类再合并”以及“先转换再聚类”[1, 2], 前者将多语言文本分别聚类然后再合并类簇, 后者将多语言转换为单语言实现聚类或者对多语言语义空间进行变换实现聚类[3]。Chen等采用先聚类再合并的方法对英汉双语新闻语料进行聚类实验, 结果表明先聚类再合并的方法有着明显的缺陷, 由于需要先在单语言环境下分别聚类, 导致不能从全局上考虑文档与特征项的关系, 特征项权重的计算缺乏全局性考虑[2, 4]。
先转换再聚类的方法是目前研究的主流, 其又可以分为基于翻译的方法以及基于语义分析的方法。前者可以再细分为两种:基于全文翻译或者是特征提取之后再翻译。2003年, Leftin[5]的研究指出基于全文翻译的方式严重依赖于翻译系统的性能, 而海量文本的实时全文翻译也是一个问题。相比而言, 特征提取之后再翻译似乎更加合理, 因为, 翻译工具在词语方面的翻译性能和效果显然要优于全文翻译。Wu等[6]提出通过结合跨语言领域对准模型和特定领域词项翻译模型, 实现了跨语言文本聚类, 实验取得了不错的效果。Montalvo等[7]进行了基于特征翻译和命名实体作为特征表示文档这两种方法优劣的比较研究。Denicia-Carral等[8]利用外文之间在拼写上的相似性, 实现了多语言文本的聚类, Negri等[9]则详细阐述了如何使用WordNet实现多语言命名实体的识别, 将英文命名实体识别的系统扩展到印度语, 并且取得了不错的效果。
除了基于翻译的方法, 也有许多学者试图从语义层面分析多语言文本, 主要方法有:隐含语义分析的方法以及基于知识库的分析方法。Dumais等[10]使用了潜在语义标引的方式来规避语言的不同来实现检索任务, Wei等[11]通过潜在语义标引的方法实现了多语言文本的聚类。金千里等[12]研究了弱指导的统计隐含语义分析及其在跨语言检索系统中的应用, 通过机器学习的方法自动进行基于语义层面的文本聚类。Montalvo 等[13]采用命名实体作为特征实现了西班牙语和英语的双语文本聚类, 计算文本相似度的时候, 提出了一种基于模糊系统的方法, 该模糊系统基于一个知识库, 对命名实体做出了知识层面的定义。Kumar等[14, 15]使用Wikipedia的可比语料进行了英语和印地文(Hindi)双语文本聚类实验, 利用跨语言链接、类别标签、外部链接等丰富了文档的表示。
本文在对国内外多语言文本聚类相关研究总结分析的基础上, 以实验的方式探究中英文双语文本聚类主流处理方法的实际效果、存在的缺陷以及可能的改进方向。同时, 实验中选择的是新闻语料, 而新闻文本是目前最为庞大的多语言数据资源, 也希望本文的研究对跨语言新闻数据资源自动化组织与发掘有一定的指导作用。
鉴于目前多语言文本聚类主要从两个方面研究:先翻译再聚类的方法及以LSI为主的语义分析方法, 本文主要采用这两种方法实现多语言文本的聚类, 并进行对比:
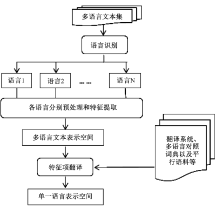
(1)方法一:将多语言文本通过翻译的方式映射到单一语言空间, 一般过程包括:
①文本识别:以汉英双语为例, 可以将汉英双语文本统一UTF-8编码, 然后利用它们各自编码范围的不同(英文UTF-8编码范围在00000000-0000007F, 中文UTF-8编码范围在00000080-000007FF和00000800-0000FFFF之间)进行识别;
②将多语言文本分别进行预处理和特征提取, 通过翻译等方式将特征项转换成单一语言下的特征项;
③在单语言环境下实现文本表示, 生成对应的文本表示空间。
其过程如图1所示:
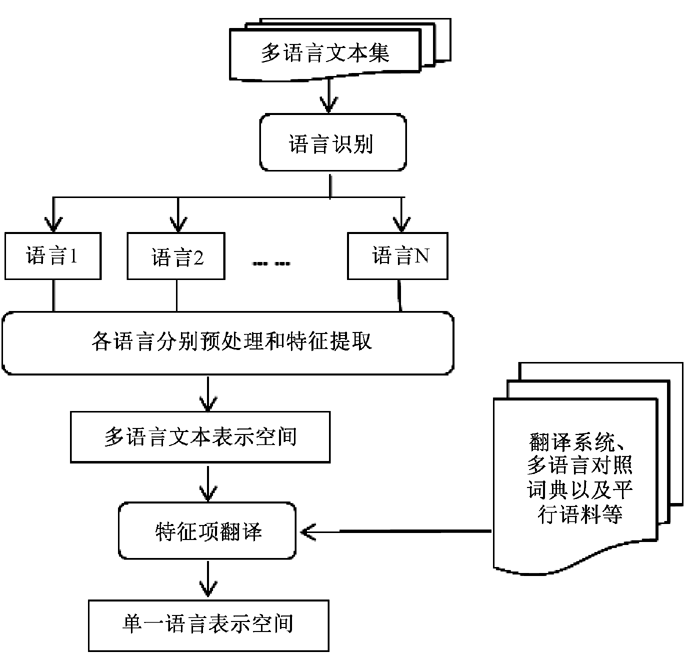 | 图1 先特征提取然后翻译的多文本表示过程 |
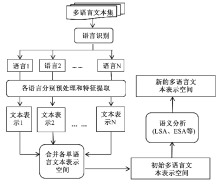
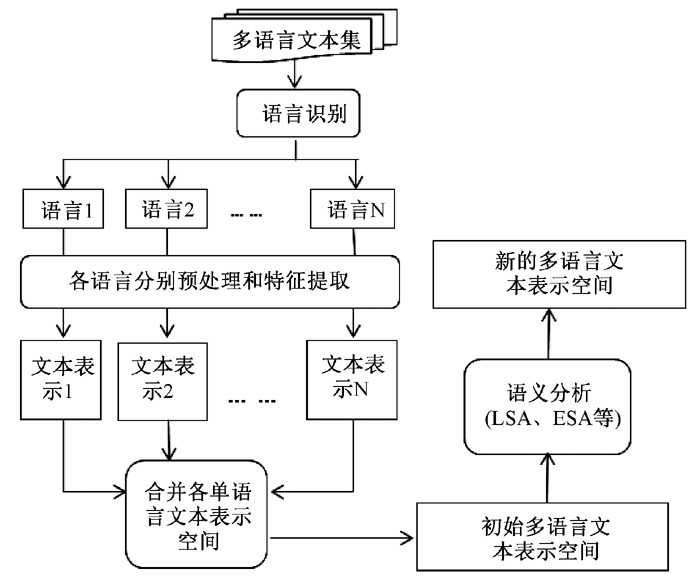
(2)方法二:通过潜在语义标引的方法, 直接将多语言文本映射到多语言的语义空间, 实现多语言文本的跨语言表示。其过程一般包括如下几个步骤:
①进行文本的语言识别;
②按照各语言的特点, 分别做预处理和特征提取操作, 实现各语种文本的特征表示;
③合并步骤②中得到的所有文本表示, 得到一个初始的多语言文本表示空间;
④对步骤③中的初始表示空间进行隐含语义分析、基于知识库的语义分析等语义分析操作, 这样就可得到一个新的多语言文本表示空间。
其过程如图2所示:
同向量空间模型一样, LSI首先也需要从输入文档集构建一个“特征项-文档”的关联矩阵, 该矩阵被认为是文档集合的原始语义空间。之后将该矩阵做奇异值分解(SVD)和矩阵降维, 剔除掉次要的联系, 变换得到一个新的语义空间(矩阵)[16]。降维的过程去除了原始语义空间中的噪声信息, 提高了语义层面的表示度。
 | 图2 多语言文本映射到多语言空间的过程 |
LSI在信息检索方面得到了广泛应用, 然而其在应用过程中一直未能解决的一个问题便是SVD 运算的高复杂度, 以致这种方法一直不能在大规模数据上得到成功应用, 包括计算最快的LAS2算法、替代LSI的半离散矩阵分解(SDD)方法, 都无法在空间和时间上同时优化LSI的计算复杂度[1, 17]。
(1)种子站点
本文选择的种子站点如表1所示:
| 表1 种子站点 |
使用开源爬虫程序Hertrix[18]进行网页资源抓取, 为减少无关网页的数量, 在分析各个网站链接层次的基础上, 针对各个站点设定特定的抓取策略, 以酷悠双语阅读(
(2)抽取策略
将爬虫程序抓取到的网页, 经过人工筛选之后, 整理成以类别划分的各个文件放在类别文件夹中。本实验中设定只抽取标题和正文文本, 并且在抽取这一步的时候就完成了中英文的识别工作, 将一篇文章的中英文文本表述分别抽出。
抽取工具选择开源工具包HTMLParser[19], 它提供了解析网页文本的接口, 可以针对网站正文的标签特性设置不同的过滤器提取相关的中英文正文文本。
(1)预处理
先将中文文本做分词, 英文做词干化处理, 同时, 再将分词后的中文词汇翻译为对应的英文词汇, 通过这种方式实现多语言文本到单语言文本的转换。由于主题词表、平行双语词典等翻译资源获取比较困难, 本实验中使用在线翻译系统(有道在线翻译[20]), 实现特征项的翻译工作。语料统计说明如表2-表4所示:
| 表2 中文分词后的语料 |
| 表3 英文词干化后的语料 |
| 表4 中文分词后翻译成英文后的语料 |
(2)设定实验策略
①对比策略:本实验通过对比“中英混合文本直接聚类”、“中文分词后翻译成英文后的文本和原始英文文本聚类(单一英语环境)”以及“中英双语文本分别聚类(各自的单语环境)”三种方式聚类的结果, 探索基于翻译系统的双语聚类的效率问题;
②聚类工具:开源工具Weka[21];
③聚类算法选择Weka提供的K-means[22], K-means是一个标准的聚类算法, 其中初始种子的选择:每一组实验选择seed为20、50和100三个数据, 并以最佳结果作为本组最终的聚类结果;
④特征表示:TF-IDF[23], 由于实验语料文本长度差异较大, 该方法进行了文本长度的归一化处理;
⑤特征选择部分按照每篇文档保留top3, top5, top10, top15, top20, top30, top50个特征项进行选择, 每一种特征选择作为一组;
⑥聚类效果衡量:R(召回率)、P(准确率)、F-measure(F值)[2]。
(3)实验结果分析和说明
①单一中文
单一中文, 文档总数1 368, 最大可能特征项数18 863个。取原始聚类结果每一组中的最佳结果作为本组的最终聚类结果, 如表5所示:
| 表5 单一中文聚类结果 |
②单一英文
单一英文, 文档总数1 368, 最大可能特征项数18 922个。取原始聚类结果每一组中的最佳结果作为本组的最终聚类结果, 如表6所示:
| 表6 单一中文聚类结果 |
③中英混合文本
中英混合文本, 文档总数2 736, 最大可能特征项数37 774个。取原始聚类结果每一组中的最佳结果作为本组的最终聚类结果, 如表7所示:
| 表7 中英混合文本聚类结果 |
④基于翻译的双语聚类(统一转换为英文)
翻译后的统一英文文本, 文档总数2 736, 最大可能特征项数25 698个。取原始聚类结果每一组中的最佳结果作为本组的最终聚类结果, 如表8所示:
| 表8 基于翻译的双语聚类结果 |
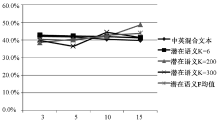
将表5-表8的数据作一综合, 以每篇文档保留特征项数目为横轴, F值为纵轴, 如图3所示。由图3可以很清楚地得出以下结论:
(1)基于翻译系统的聚类结果明显高于直接将中英文本进行混合聚类的方式, 且实际聚类效果上有很大的提高, 也就是说, 在翻译系统性能不断提高的前提下, 这一方法将有很大的应用前景。
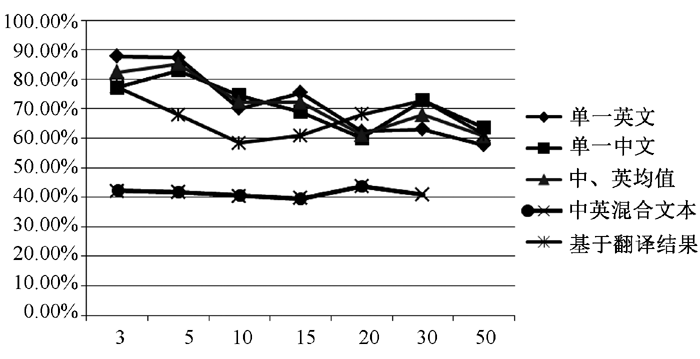 | 图3 各聚类策略下F值走势图 |
(2)由于翻译后的文本表达上会与原始文本有所出入, 因此, 基于翻译方法的聚类结果无法达到原始单一语言环境下的聚类效果, 即该方法严重依赖于翻译系统的性能。
(3)随着每篇文档保留的特征项数目的增加, 单一中文、单一英文、基于翻译的聚类三种方式聚类的F值呈现出下降的趋势, 表明在实际的聚类应用中, 特征项的选择需特别谨慎。不能过多保留特征项, 由于某些特征项只会出现在少量文档中, 过多保留这类特征项会明显增加特征化矩阵的稀疏程度, 导致噪声信息增多, 影响聚类结果。同样, 也不能过少保留特征项, 过少的特征项导致不能完整表达文档的主题, 造成语义上的丢失, 也会影响最终的聚类结果。实际聚类操作中, 需要在认真分析文档长度的基础上, 选择一个合适的特征项保留数目。
(1)预处理
实验中发现做矩阵变换时, 转换后的矩阵占用内存增大数倍, 由于机器性能和所选择的聚类工具性能的限制, 最终选取原始语料的一半作为本部分实验的语料, 如表9所示:
| 表9 基于隐含语义分析的中英混合语料 |
(2)设定实验策略
对比策略:本实验通过对比“中英混合文本直接聚类”、“基于隐含语义分析的中英文混合文本聚类”两种方式聚类的结果, 探索基于隐含语义分析的双语聚类的实际效率问题。基于隐含语义分析的双语聚类, 在完成奇异值分解(SVD)之后, 需要通过降维来完成新语义空间的构造, 假设S为SVD分解后对角线矩阵, 则S对角线上的元素为原始语义空间的奇异值。设K为降维后对角线矩阵保留的维度数, 实际中K的选择对于转换后的语义空间影响很大, 根据文献[16]指出, K值的选择一般在100-300, 本实验分别选取K=6、K=200以及K=300三种情况实现降维。其他设定参见3.2小节。
另外, 同样由于机器性能的限制, 本实验中特征项的选择只是选取每一篇文档分别保留top3, top5, top10, top15个特征项4种情况。
(3)实验结果分析和说明
中英混合文本, 文档总数1 368, 最大可能特征项数26 793个。取原始聚类结果每一组中的最佳结果作为本组的最终聚类结果, 如表10-表12所示:
| 表10 基于隐含语义分析的中英混合文本聚类结果(K=6) |
| 表11 基于隐含语义分析的中英混合文本聚类结果(K=200) |
| 表12 基于隐含语义分析的中英混合文本聚类结果(K=300) |
将表7、表10-表12数据作一综合, 以每篇文档保留特征项数目为横轴, F值为纵轴, 如图4所示:
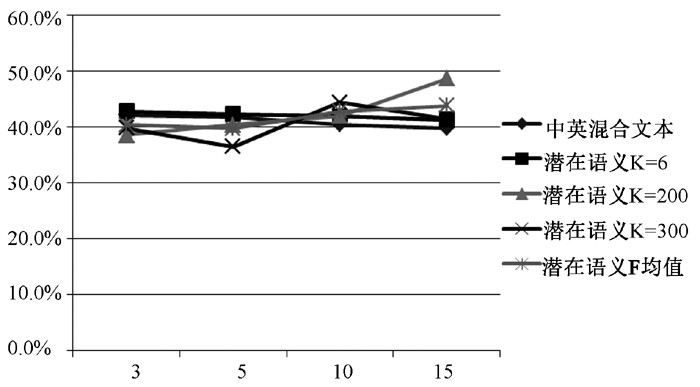 | 图4 各聚类策略下F值走势图 |
本实验中, 使用潜在语义标引的方法实现了多语言文本语料到多语言文本空间的映射, 通过降维的方式消除了原始语义空间中的噪声信息, 实现了跨语言的语义关联。然而, 实验结果显示, 潜在语义标引对于双语混合文本的聚类结果并没有实质性的提高。其原因可能如下:
①K值的选择问题。潜在语义标引中, K值的选择对于最终的聚类结果影响很大, 本实验中只选取了3个值(分别是6、200和300), 而实际列的维度在2 050-8 328, 远高于K的取值, K值选择过小, 可能导致原始矩阵奇异值信息忽略得过多, 影响了最终的聚类结果, 本实验中K值可能并非理想的取值。
②不做任何改进的LSI可能并非能够很好地用于多语言混合文本的聚类操作。在多语言混合文本的“文档-特征项”矩阵中, 由于诸如“Computer”与“计算机”不作为同一个词统计, 因此会出现大量的0元素, 这些0元素在经过奇异值分解和矩阵变换后, 有一大部分被赋予一个负值, 表示特征项和文档之间存在负的相似性, 这种问题的存在可能严重影响了聚类效果, 而使用LSI是无法规避这个问题的, 这可能是LSI当前的一个缺陷。
本文在梳理国内外相关研究的基础上, 总结出多语言文本表示的两种基本思路:
(1)将多语言文本通过翻译、转换等方式映射到单语言空间;
(2)将多语言文本通过隐含语义分析技术、基于知识库的语义分析技术等映射到多语言的语义空间。在上述两种基本思想的指导下, 选取中英双语对照语料2 736篇, 使用最基本的K-means算法实现了中英双语的文本聚类实验研究。
实验一“基于翻译系统的中英双语新闻文本聚类”采用了“转换到单一语言空间”的思想。实验结果表明, 基于先特征提取然后再统一语言的方式极大提高了混合文本的聚类效果, 在翻译系统性能进一步提升的情况下, 该方法将具有很好的应用前景。
实验二“基于潜在语义标引的中英双语新闻文本聚类”采用了“转换到多语言空间”这一思想。最终的实验结果并不理想, 没有显示出该方面对于混合文本聚类效果的显著提升。通过分析发现潜在语义标引模型的奇异值分解存在一定的缺陷:
(1)SVD算法的时间和空间复杂度很高, 对机器以及聚类工具的要求很高, 难以应用于网络海量的信息资源处理;
(2)消除噪声后的语义空间中出现了部分负值, 体现出特征项与某些文档之间不但不相似, 反而是“互相排斥”, 说明噪音消除可能消除了部分文档的特征项, 因此, 噪音的选择或者特征项的选择还存在一定优化空间;
(3)K值的选择是个问题, 目前尚无统一的参照标准, 对不同样本, 可能需要更多的实验场景来验证和选择。
由于两种实验的样本数不同, 难以直接对比二者的结果, 不过明显可以看出, 在本研究样本中, 实验二的方法在样本少一半的情况下, 各性能指标比实验一要差很多, 表明基于LSI的聚类方法还有很大改进空间, 也期待在更先进的计算环境下对此两种方法进行更详尽的对比。
本文主要的贡献在于系统梳理了目前学术界关于跨语言文本聚类的研究方法和思路, 并且以实验的方式探究了两种主流方法的实际效果、存在的缺陷、可能的改进方向以及可能的应用前景。
| 1 |
|
| 2 |
|
| 3 |
|
| 4 |
|
| 5 |
|
| 6 |
|
| 7 |
|
| 8 |
|
| 9 |
|
| 10 |
|
| 11 |
|
| 12 |
|
| 13 |
|
| 14 |
|
| 15 |
|
| 16 |
|
| 17 |
|
| 18 |
|
| 19 |
|
| 20 |
|
| 21 |
|
| 22 |
|
| 23 |
|