用户查询意图的层次化识别方法
[唐静笑1  , 吕学强
, 吕学强1 , 柳成洋2 , 李涵2 ]
, 吕学强|
|


作者贡献:
唐静笑:进行实验以及论文起草;
吕学强:提出研究思路,设计研究方案;
柳成洋:采集、清洗和分析数据;
李涵:论文最终版本的修订。
【目的】向搜索引擎提交的查询均有其潜在的查询意图, 准确识别查询意图可以提高查询的效率。【方法】针对有明显意图的查询, 采用滑动窗口寻找最大公共子串的策略抽取用户的意图模板, 然后用模板匹配的方法识别用户查询意图。对无明显意图的查询, 采用多特征融合的分类方法进行识别。【结果】实验结果表明, 采用层次化识别方法和单独使用分类器方法相比, 识别查询意图的实验结果正确率得到19.04% 的提升。【局限】可获得的意图模板是有限的, 因此显式意图查询的识别存在局限性。大规模数据情况下, 模式匹配及机器学习算法的运算量很大, 需要进一步优化算法。【结论】实验证明该方法在Web意图识别中是有效的, 对意图识别率的提高有积极意义。
[Objective] Any query search engine has its potential query intention, and accurate intention identification can improve the efficiency. [Methods] For the explicit intent queries, the authors employ sliding window strategy to find the maximum common substring for extracting user intent templates and then use the templates to identify the user intention. For implicit intent queries, the authors use a multi-feature integration method to build classifier for the final query intention recognition. [Results] Experimental results show that the hierarchical intention recognition framework can achieve better precision comparing with methods based on classifier, and the accuracy enhances 19.04%. [Limitations] Intention template obtaining is limited, so explicit intention recognition has limitation. For large-scale data, complexity of the pattern match and machine learning algorithm is very high, the algorithm need further optimization. [Conclusions] Experiment shows that this method is valid in Web intention recognition, which has a positive significance for improvement of intention recognition rate.
互联网上数据庞大, 以指数级形式增长, 搜索引擎已经成为人们浏览互联网信息的一个主要手段。获取用户查询意图以及对用户查询意图分类是当前的热点研究问题。如果能够理解隐藏在用户查询背后的意图, 就能够帮助搜索引擎自动将查询提交到相对应的垂直搜索引擎上, 得到更加准确的返回结果, 从而提高用户的满意度。然而, 目前的检索技术决定了搜索引擎只能返回一些和查询相关的结果列表, 用户还需要在列表中查找符合自己真正查询意图的结果。通用搜索引擎在理解用户的真正查询意图方面显得比较薄弱, 不能针对查询的隐式意图来返回更加相关、准确的答案。原因是较短的查询本身包含信息量少, 存在的歧义多, 需要在一定的语境下才能体现其语义。目前, 主流的查询意图分类方法是基于统计的机器学习方法, 根据查询本身和查询的扩展信息抽取特征, 构建训练和测试集, 选择合适的分类算法训练分类器完成分类。由于用户查询方式多样、用语不规范、查询串中新词不断涌现, 用户的真正意图很难从表面获取, 如用户输入“甄嬛传”时, 其意图是找到这部电视剧的观看地址, 通常情况下, 这类查询很难被准确识别, 需要考虑抽取的信息特征能否精确地刻画该意图类别, 是否和其他的意图类别具有区分性, 以及这样的表示能否完全概括这一意图。
本文基于Broder[1]的Web查询分类体系, 提出一种层次化策略识别查询意图的方法, 根据搜索引擎返回内容提取查询意图模板, 这些模板识别事物类的查询效果显著, 抽取意图模板方法能够解决靠传统的方法获取查询意图识别特征使用单一资源的弊端, 也能解决查询简短、新词多、抽取的特征不能表达查询的真正意图的问题。
大多数用户在进行信息检索时, 不能十分准确地表达其意图, 最早研究中, Broder[1]将搜索引擎用户的查询意图分为三类:导航类、信息类和事务类;Jansen等[2]将上述三种意图作为分类标签, 研究准确的分类算法;文献[3]通过分析用户在搜索结果中的鼠标移动轨迹推断查询意图属于导航型还是信息型;Herrera等[4]统计了查询日志中Query Popularity特征, 通过实验证实了查询分类的正确率有一定的提高;文献[5]把每一个意图和维基百科的概念联系起来, 把Query映射到维基概念, 基于概念进行意图预测;文献[6]将查询意图通过聚类进行重构来识别查询意图;文献[7]和文献[8]总结出一些识别意图的规则、句子和短语等。然而, 查询意图词库只能解决查询语句中出现显式意图特征词的情况, 而对于“NBA 赛事”、“回家的诱惑”等没有明显意图的查询, 则需要进一步搜集用户查询的扩展语义信息来明确用户的真实查询意图。查询意图识别也可以看成短文本分类问题, 特征的提取分为两类:事先方法, 即在查询被提交给搜索引擎以前, 利用查询自身的特征词汇、词与词之间的关系等特征信息来表示查询;事后方法, 利用查询提交给搜索引擎后的相关数据获取相关查询的统计信息, 搜索引擎针对该查询返回的检索结果等, 如文献[9]采用半监督学习方法快速地增加训练数据信息, 通过点击图的方法来提高查询意图分类效果。文献[10]根据日志中网页内容泛化处理, 把URL分成主页导航和非主页导航, 但是需要用户使用明确的查找词才能准确地找到URL地址。
目前, 无论是事先还是事后方法都有一定的局限性, 主要存在两个问题:
(1)分词后导致的歧义问题。在查询意图识别前, 需对查询串和上下文进行分词, 分词本身存在歧义, 分词歧义有两种类型[11]:覆盖型和交叉型歧义。无论是哪种类型, 都有损查询本身的意义, 如:“励志当上海贼王”分词结果为“励志/当/上海/贼王”, 错误分词结果导致不能判断用户的真实意图。
(2)新词较多造成特征不明显问题。目前对查询意图识别大多采用机器学习方法, 训练之前需要抽取特征, 有些查询如“甄嬛传”“杜拉拉升职记”中包含新词, 这些新词使得无法提取有效的特征来区分查询意图, 识别不能达到应有的效果。
针对以上问题提出一种层次化识别查询意图的方法:第一层采用模板匹配对有明显意图的查询进行判断, 不需要对摘要文本进行分词, 直接匹配;第二层采用查询自身信息和对应的链接信息作为特征, 训练分类器对没有明显意图的查询进行分类。第一层之所以选择从摘要信息中抽取, 是因为它是概括查询条件的简要文本, 相比正文内容信息和标题内容更能反映查询意图。第二层采用SVM作为分类器和伍大勇等[12]方法类似, 需要人工标注训练集, 根据选取的特征训练模型。
本文参照Broder[1]的分类体系, 将三大类别进一步细化分析, 给出定义。根据2012版搜狗搜索日志的统计, 频繁出现的查询有:电子书籍、软件下载、游戏服务、问题解答、电影观看等, 将这些类别都映射到三大类别体系下, 如表1所示。根据用户输入查询词语的含义, 总结出大部分用户输入的查询都有明显意图, 明显意图查询即是在查询提交给搜索引擎后返回的摘要信息中包含能明确表达该搜索意图词语的一类查询, 这类词语具有相通性和代表性, 抽取这些具有代表性的词语作为查询意图识别的模板。
| 表1 查询意图层级类目情况 |
如表1的分析, 影视、歌曲、游戏类查询含有新词和未登录词较多, 并且这类查询通常不出现显式意图查询词, 不能根据其表义判断出用户的查询意图, 电影电视剧这类查询尤其含义模糊不清。将这类查询提交到搜索引擎中, 返回的摘要中含有相同的文本信息, 将这些信息作为查询意图识别的模板, 如:全集下载、全集观看、高清在线观看等, 即为意图识别的后缀模板。
据2012版搜狗搜索日志统计, 50.09%查询是娱乐信息, 其中影视类占娱乐信息的比例为73.8%。本文将利用这些查询在搜索引擎中返回的摘要信息抽取候选意图模板, 模板质量的好坏直接影响查询意图识别的正确率, 为保证模板的优质性, 对候选意图模板去噪。
(1)候选意图模板获取
抽取意图模板分两种情况:搜索引擎返回的摘要信息中能直接匹配到用户输入的查询内容, 称为完全匹配;很多用户输入的查询具有不完整性, 这类查询的特点是查询意图明确, 但是输入词语不完整, 一些地名简称尤为常见, 如:“安徽濉溪中学网站”, 提交到搜索引擎, 返回的摘要信息如下:
“安徽濉溪中学网站”的摘要片段:
安徽省濉溪中学简介教育, 淮北新闻网
安徽省濉溪中学是一所省级示范高中。装备示范学校, 一校两部……
安徽濉溪中学搜搜百科
采用完全匹配法, 前三条“安徽”和“安徽省”, 最后一条“搜搜百科”和原始查询都匹配不上, 这给模板的抽取带来了困难。但是查询和摘要的信息在一定程度上存在相关性, 因而采用滑动窗口匹配极大公共子串的策略抽取不能完全匹配的查询意图模板:先对查询进行逐字匹配, 若在某个位置上无法匹配成功, 跳过该字, 从下一个字继续进行匹配, 直到查询或摘要的结尾。
设摘要字符串为A, 查询字符串为Q, A[i]表示A中第i个字符, Q[i]表示Q中第i个字符, Len(s)表示字符串s的长度, 滑动窗口匹配抽取模板的方法如下:
WHILE A包含Q[0]
Q'←Q
WHILE Len(A)!=0且Len(Q')!=0
IF A[0]==Q'[0] THEN
匹配字数++
A去掉第一个字符
Q'去掉第一个字符
ELSE THEN
IF A包含Q'[0] THEN
A去掉第一个字符
ELSE THEN
BREAK
END WHILE
IF 匹配字数>0.5*Len(Q) THEN
IF A包含符号, 。?!等, THEN
截取A标点之前子串, 提取为下文
A←截取A标点之后的子串
ELSE THEN
A为下文
BREAK
END WHILE
上例中, 经过滑动窗口策略得到的匹配结果如表2所示:
| 表2 用户返回摘要模板匹配结果 |
表2中“[ ]”内的文字代表根据滑动窗口策略匹配得到的查询内容。若匹配的字数占查询总字数的比例大于一定阈值x时, 则认为匹配成功, 最右一栏为抽取的模板结果。
(2)基于TFIDF精选模板抽取
候选模板集中有些模板有很好的意图区分度, 而有些模板与查询意图不相关且在不同的意图类别中通用性较强, 对意图类别区分度很低, 三种类别共同拥有的意图模板示例如下:
三种类别共同的意图模板:
百度百科
百度知道
百度贴吧
的最新相关信息
百度经验
搜搜问问
百度文库
为了在模板集中找出能更好地表示查询意图的模板, 必须对模板进行过滤, 本文采用TFIDF算法来计算每个模板的权重:
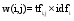 | (1) |
其中, i为某一模板, j为某一查询意图类别, tfi, j为模板i在类别j中的频率, idfi为逆向类别频率:
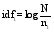 | (2) |
其中, N为意图类别总数, 本文取值为3, ni为包含模板i的意图类别个数。若权重w(i, j)小于某一阈值y, 将候选模板i从候选模板集中删除, 否则将其选为精选模板。
经过对候选模板的筛选处理, 过滤掉对查询意图类别区分度不高的模板, 得到精选模板集T= {T1, T2, …, Tk}(本文k=3, 代表三个类别)。对输入查询q, 将q提交到搜索引擎返回的摘要信息为A, 若 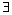
(1)Web查询意图分类
模板匹配的方法能识别具有显式查询意图的查询, 对于隐式查询意图的查询在用词规则、意图表达方面比较分散, 无特定规则可循。本文将Web查询的意图识别看成一个分类问题, 采用SVM作为分类器, 如何选取分类特征是查询意图识别的关键。当给定Web查询类别体系C={c1, c2, …, cm}和用户输入的1个 查询q, 通过学习得到分类器f:{q}→C。根据这些特征选择机器学习算法学习到分类器f来识别查询q的意图类别ci。每个查询串表示成形如q=〈t1: w1;t2: w2;…; tn: wn〉的向量, 其中ti表示词条项, wi表示ti能否代表该查询串特征的布尔值, 算法在特征提取中给出。
(2)Web查询意图分类特征分析
本文在文献[11, 13]选择特征基础上, 进一步梳理了查询意图分类的研究成果, 并将其分为如下三类特征。
特征1 基于查询表达式的特征。参考文献[12]方法中直接使用查询串分词后的词汇作为意图识别的特征。
特征2 基于检索结果的特征。该特征基于一个假设:搜索引擎针对特定查询检索出的最靠前的一系列检索结果与查询相关。在搜索引擎返回的前50个标题信息和摘要信息中抽取这类特征, 抽取方法参考文献[12]的特征4方法的抽取。
特征3 基于查询词上下文特征。针对查询日志中的查询记录, 这些相关查询中的上下文信息是对需要识别意图查询的属性或特征的描述。为了获取查询语句的上下文词汇特征, 先将查询进行分词, 然后在查询日志中找到包含查询分词后所有词汇的相关查询记录, 将这些相关查询记录进行分词处理, 将除了原查询之外的其他词汇作为描述该查询词汇的特征。
传统的召回率和F值都只能针对单个类别进行评价, 不能代表所有类别的性能, 因此采用正确率评价正确识别的分类结果数量占所有识别分类结果总数的百分比:
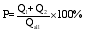 | (3) |
其中, P表示采用层次化模型后的查询分类的总的正确率, Q1表示用模板匹配方法识别正确的查询个数, Q2表示用多特征融合训练分类器方法正确分类出的查询个数, Qall表示总查询数量。
实验数据为搜狗实验室提供, 随机抽取7 000条查询, 对其进行人工标注类别, 其中去掉模糊类99条, 其余6 901条数据划分为训练集和测试集两部分, 训练集占整个文档集70%, 测试集占30%, 如表3所示:
| 表3 数据作为测试和训练的各个意图数量分配 |
首先给出综合意图识别的实验结果, 然后分析导致该实验结果的原因, 进而列出层次化方法中第一层模板识别的结果, 分析采用模板识别的有效性。第一组实验是本文的Baseline, 基于单层的多特征融合SVM(Single Features SVM, SFS)分类实验, 第二组和第三组都是本文提出的层次化方法, 分别是基于多层候选模板识别(Layering No Optimize, LNO)、基于多层经过TFIDF优化后模板识别(Layering TFIDF Optimize, LTO)。
表4表明, 本文提出的层次识别方法相对于较单一的SVM方法, 识别效果更好, 具体分析如下:
| 表4 意图识别方法综合实验结果对比 |
(1) LNO模型比SFS模型平均正确率提高6.66个百分点, 原因是使用模板能识别出具有明显意图的查询, 如“婆婆来了”“战神”等影视类查询, 它们的摘要中含有大量共同的内容, 模板匹配起了一定作用;
(2)LNO模型和LTO模型的平均正确率相差12.38个百分点, 验证了经过TFIDF筛选模板的必要性。原因是采用TFIDF过滤掉没有区分度的模板, 正确率会大大提高。如果候选模板没有进行TFIDF优化, 那么“百度百科”“百度一下”这类模板, 将查询任意识别为事务类、导航类和信息类。
在相同数据集下, 采用模板匹配比SVM识别意图的正确率高, 这验证了模板匹配的重要性, 没有被SVM识别的大部分查询为事物类中影视相关的查询, 如:“战神”“宫锁心玉”, 这类查询只采用SVM识别, 特征无法明确表示查询意图, 模板匹配的一些例子如表5所示:
| 表5 查询及所属类别 |
表5中的查询5和查询6识别错误, 因为完全匹配要求查询在搜索引擎中返回的摘要信息必须一字不差地匹配意图模板, 具有一定的局限性。查询5和查询6的摘要信息没有准确匹配, 因此需要用分类模型训练以进一步得到查询意图。
按照表4中实验数据的分配, 把训练数据和测试数据分成三份, 每一份数据都事先找到有明显意图的查询条数, 然后分别用SVM和模板方法进行实验, SVM识别需要训练数据, 模板匹配只需要测试数据, 两种方法的正确率计算结果如表6所示:
| 表6 采用模板匹配识别查询意图的结果对比 |
SVM分类, 通常不涉及召回率, 并且模板抽取方法更重视正确率, 表6列出了同一数据两种方法的结果。SVM平均正确率为62.69%, 模板识别的平均正确率为93.64%, 导致差距的原因是“特征维度太多, 关键特征作用不明显”。有明显意图的查询某一特点能准确表达其意图, 如果训练特征太多, 反而将具有区分性的特征削弱, 以影视剧的查询为例, 该类查询通常和信息类查询有交叉意图, 如:“婆婆来了”是表示“婆婆来访, 需要准备什么饭菜信息咨询问题”, 还是“电视剧的名字”;“真实的谎言”是表示“什么是真实的谎言信息咨询问题”, 还是“电视剧的名字”, 仅通过SVM训练特征识别查询意图是很困难的, 但是通过模板匹配方法就能做到准确识别。因此如果在机器学习训练之前, 就明确这类查询意图, 正确率将会有所提升。4.2节抽取的3个特征共20万维, 特征虽多, 对查询意图的识别却没有应有的效果, 但是结合模板先进行识别查询效果却有了明显的改善。
本文提出一种层次化的策略识别查询意图, 先利用搜索引擎返回的摘要信息识别有明显意图的查询, 再训练多个特征进一步识别查询意图, 该方法不仅解决了当前查询意图分类方法选取意图特征不能准确分类的问题, 还解决了特征太多造成关键特征削弱这一缺陷。进一步的研究是总结出更细致的查询分类体系, 同时扩大模板库, 针对特定领域训练专门模板库。另外, 模板获取方法增加模板实体的内部位置制约, 获得更高的模板正确率, 并且对信息抽取模板库进行有效的评估。
| 1 |
|
| 2 |
|
| 3 |
|
| 4 |
|
| 5 |
|
| 6 |
|
| 7 |
|
| 8 |
|
| 9 |
|
| 10 |
|
| 11 |
|
| 12 |
|
| 13 |
|