
{kind=link}
用户查询日志中的中文机构名识别
关晓炟1  , 吕学强
, 吕学强1 , 李卓1 , 郑略省1, 2
, 吕学强|
|


作者贡献:
吕学强:提出研究命题;
关晓炟:提出研究思路、论文最终版本修订;
关晓炟,郑略省:设计实验方案;
吕学强,李卓:提供数据;
李卓,郑略省:采集、分析数据;
关晓炟,吕学强,李卓:论文起草。
【目的】解决在用户查询日志中识别机构名的标注语料资源匮乏及信息不对称问题。【方法】提出一种自动构建用户查询日志机构名训练语料的方法, 解决目前用户查询日志语料资源匮乏的问题。提出粘合度概念解决信息不对称问题, 结合上下文等信息, 采用条件随机场模型进行机构名识别。【结果】该方法在搜狗用户查询日志上的开放测试结果显示, 机构名识别的正确率为72.80%, 召回率为86.73%, F值为79.16%, 比传统机构名识别方法在日志上的F值提高30%。【局限】语料构建方法仅仅是模拟查询日志的特点, 但训练模型的误差仍然会大于规范化标注的查询日志语料;机构名表的数据量大小会影响模型对上下文知识学习的完备性。【结论】实验表明该方法应用于用户查询日志中的机构名识别是有效的。
[Objective] To solve the problems of query log annotated data shortage and information asymmetry in user query log organization name recognition. [Methods] The paper proposes an automatic method to create training data, which abates the insufficient of user query log annotated data. The authors cite the adhesion features and constructed CRF model to recognize organization names by integrating context information. [Results] Experiments on Sogou user query log show that precision rate can reach 72.80%, recall rate can reach 86.73% and F-measure can reach 79.16%. The method improves F-measure by 30% comparing with the traditional organization name recognition method. [Limitations] The model error using auto-created training set will be greater than standard annotated user query log data.The scale of organization name set will affect the completeness of the model’s context knowledge. [Conclusions] Experiment results demonstrate that the method is effective.
机构名与人名、地名并列为三大常见命名实体。机构名识别是命名实体识别任务中的重点和难点。机构泛指机关、团体或其他企事业单位, 包括院校、公私企业、政府部门、宗教组织、科研部门、国际组织、体育团队、音乐团体、军队等[1]。机构名识别效果对词法、句法分析等自然语言处理研究有着直接影响, 是信息抽取、问答系统、机器翻译等自然语言处理相关应用中的关键技术。
近些年, 随着计算机技术和互联网的飞速发展, 搜索引擎已经成为人们在日常学习生活中获取网络信息的主要途径。用户查询日志包含海量的数据资源, 日益成为数据挖掘领域研究者们关注的对象。研究用户查询日志中的命名实体识别技术, 能够使搜索引擎更好地分析用户的查询意图, 提供给用户准确的检索结果, 改善用户的检索体验。
相对于普通文本, 用户查询串通常很简短, 简称和缩写使用频率高, 口语化程度高, 语法结构不严谨, 语义模糊、不连贯。用户查询日志与普通文本中机构名的上下文在内容上有相当大的差异性, 这给用户查询日志中的机构名识别带来了很大困难。
由于以上特点, 传统的机构名识别方法直接移植到基于用户查询日志的机构名识别往往识别效果较低。如能解决用户查询日志中机构名识别问题, 不但能大大提高搜索引擎分析用户查询意图的能力, 也能抽取出更完备的知识供其他理论研究或应用技术所用。
已有的识别手段主要是基于统计和规则以及二者相结合的方法。
规则方法方面, 张小衡等[2]在大量语料中分析总结机构名内部构成规则, 对高校名称进行识别, 达到97%的正确率和召回率。沈嘉懿等[1]提出了以形成机构名的词性序列做规则集合, 利用贝叶斯概率模型进行规则决策, 在识别全称的基础上, 进行简称的识别, 该方法应用在中文关系的抽取系统中, 取得了较好的效果。周昆[3]基于本体构建中文人名知识库的层次分类体系, 将中文人名领域的知识分成若干个层次, 并构建命名实体识别的规则库, 采用规则匹配的方法识别命名实体。
统计方法方面, 俞鸿魁等[4]提出一种角色标注的方法, 采用隐马尔科夫模型和韦特比算法进行机构名识别, 取得了很好效果。周俊生等[5]采用双层条件随机场模型, 首先在低层识别人名和地名, 再在高层进行机构名的识别, 综合性能有较大提高。黄德根等[6]将SVM与CRF相结合, 分层地识别机构名并将结果融合。金朝等[7]根据首词对机构名进行分类, 并使用隐马尔科夫模型进行识别。冯丽萍等[8]基于SVM提出了一种多特征的机构名识别模型。胡文博等[9]提出了一种基于多层条件随机场的命名实体方法, 有效改善了复杂机构名的识别效率。付春元[10]采用基于条件随机场的双层模型对嵌套命名实体进行识别, 在此基础上对错误结果提出一种基于互信息的后处理方法, 很大程度上解决了嵌套命名实体边界识别错误的问题。蔡月红等[11]利用Tri-training学习方式将基于条件随机场的分类器、基于支持向量机的分类器和基于记忆学习方法的分类器组合成一个分类体系, 并依据最优效用选择策略进行新加入样本的选择。邱莎等[12]基于条件随机场模型, 提出一种将词性和词边界合成为一个特征项的方法, 在山西大学标注语料库上开放测试结果得到了95%以上的F值。
统计和规则结合方面, 杨晓东等[13]提出了一种CCRF与规则相结合的中文机构名识别方法, 以CCRF为基础融合规则库, 为复杂机构名识别提供决策。鞠久朋等[14]先用CRF对满足条件的片段做地名及机构名识别, 识别出的命名实体进一步解构, 用CRF及知识判断该命名实体是否表示事件发生地的地理空间信息, 有效提升了地理空间命名实体识别的性能。
基于规则的方法需人工构建规则库, 对用户查询日志中的机构名提取规则需要投入巨大的人工, 而搜索引擎中不断出现新的机构名, 需要不断对规则库进行更新才能保证识别效果。基于统计的方法往往需要训练语料, 目前用户查询日志缺少带标注的语料资源, 而日志语料的内容与常规文本(如人民日报语料)存在很大不同, 若以常规文本训练模型对日志中机构名进行识别难以达到理想的效果。为此本文提出一种自动构建用户查询日志训练语料方法, 并引入粘合度概念, 以解决用户查询日志中机构名识别的问题。
使用条件随机场方法[15, 16]对用户查询日志中的机构名进行识别的实质是将机构名识别问题转化为已分词文本的序列标注问题。一个关键的问题是如何针对特定任务选择合适的标记集合, 并尽量使用最简单的特征描述复杂的语言现象。本文采用类似目前流行的BIEO标记方法表示序列的标注结果。用户查询日志中的机构名内部特点与普通文本相类似, 其内部构成模式十分复杂。通过对语料的分析, 发现机构名的内部构成及其上下文环境有一定的规律可循, 从结构上看, 大多数机构名最后一词具有明显的机构名特征, 如:“北京 大学”、“方正 科技 有限公司”中的“大学”、“有限公司”, 一般作为机构名的标识词。而不同标识词的前一词的词性与特征词往往具有一定的关联, 如“大学”的前一词往往为地名词或一般性名词。此外机构名上下文词也有一定的指示性, 如类似“XX年 XXXX 分数线”的上下文环境中, 其中XXXX部分通常为某高校名字。根据以上特点, 本文设计的标记集如表1所示:
| 表1 中文机构名识别标注集 |
按照以上标记集, 对语料进行转换, 如表2所示。通过以上处理, 中文机构名的识别问题就转化成了序列标注问题, 其中分词和词性标注采用NLPIR汉语分词系统2013版(NLPIR汉语分词系统 http://ictclas.nlpir.org/)。提取结果中[(B)(I)[P_NS/ P_NT/P_J/P]E]模式部分, 即为识别所得机构名。
| 表2 语料转换样例 |
用户查询日志中查询串具有随意性、简洁性、表达方式多样性等特点, 与类似人民日报的长文本语料相比, 缺乏一定的语境信息。但目前还没有针对用户查询日志的实体识别标注语料, 为此本文基于人民日报标注语料, 根据用户查询日志的相关统计特征, 设计一种训练语料自动生成方法, 获取与用户查询日志特征尽量吻合的训练语料。
传统机构名识别方法常常在一定程度上依赖于机构名的上下文。在普通文本中, 几乎全部的机构名的出现伴随着上下文环境, 但在搜索引擎用户查询日志中, 以搜狗用户查询日志2008版(搜狗实验室资料 http://www.sogou.com/labs/dl/q.html)(约5 000万条查询串)的统计数据为例, 95%以上的机构名存在上下文缺失情况, 如表3所示:
| 表3 中文机构名上下文缺失情况 |
方括号内部部分为机构名, 在用户查询日志中常见查询串形式“[北京科技大学]分数线”, “分数线”为“北京科技大学”的下文, 但“北京科技大学”并不存在上文, 即上文缺失;但在人民日报语料中, 机构名上下文缺失情况较少, 详见表3数据。因此, 从普通文本训练语料中学习得到的上下文知识并不适用于用户查询日志语料中的机构名识别。
观察发现用户查询日志中查询串的长度分布具有一定的规律, 经对2008年6月版的搜狗日志语料统计, 如图1所示, 搜狗用户查询日志中的查询串所占比例随着长度的增加而逐渐减少, 几乎绝大多数查询串长度在2-32之间。
 | 图1 搜狗用户查询日志中查询长度比例分布 |
针对人民日报与用户查询日志的差异性, 可对人民日报语料进行特殊长度子串截取, 以期在形式上尽量模拟用户查询日志。假设已分词的句子S=W1W2W3…Wn, 其中Wi代表句子S中的一个词, 若S中包含机构名Nt=WiWi+1…Wj(1≤i
如图1所示, 对句子中排除机构名之后的剩余部分子串S1=W1W2W3…Wi-1、S2=Wj+1Wj+2Wj+3…Wn、……, 或不含机构名的句子进行汉字字数在2-32之间随机长度的截取。
经过上述处理构建模拟用户查询日志形式的训练语料库, 例如:
人民日报标注语料:
中国/ns 三/m 个/q 著名/a 交响乐团/n -/wp [中国/ns 交响乐团/n]nt、/wn
查询日志的训练语料:
中国/ns 三/m 个/q 著名/a 交响乐团/n -/wp
[中国/ns 交响乐团/n]nt(72%的概率保留)
-/wp [中国/ns 交响乐团/n]nt(22%的概率保留)
[中国/ns 交响乐团/n]nt、/wn(1%的概率保留)
-/wp [中国/ns 交响乐团/n]nt、/wn(5%的概率保留)
基于统计的机构名识别方法主要依赖于机构名内部的结合紧密程度及其上下文信息。由于用户查询日志与人民日报语料的差异性, 使用前文所述训练语料训练得到的模型识别用户查询日志中机构名时, 上下文信息不能正确发挥作用。为解决这一问题, 本文引入粘合度概念, 表示机构名上下文词与机构名的粘合程度, 词语的粘合度越大, 则该词作为机构名上下文的可能性越高, 左右粘合度分别表示词语作为机构名上下文词的可能性。
粘合度的计算需要机构名表。综合一些网络资源(包括搜狗细胞词库“中国高等院校大全”、“中国医院大全”、“政府机关团体机构大全”、常用机构名列表等)以及从人民日报1998年1月标注语料中提取出的机构名称, 组建了一个机构名词典, 其中包含不重复的机构名60 293个。在用户查询日志中, 根据机构名表, 获取每个机构名的上下文词, 方法如下:设搜狗用户查询日志Q{Q1, Q2, …, Qm}, 机构名表L={L1, L2, …, Ln}, 对于给定一条Qi∈Q, 若 
在构建上下文词表之后, 通过以下公式计算某一词W的粘合度:
左粘合度:
 | (1) |
右粘合度:
 | (2) |
其中, C(WQx)为词W在上文词表中的频次, 即作为上文出现的频次, C(QxW)为词W在下文词表中的频次, C(W)为该词在日志语料中的出现总频次。
将粘合度转换为对应的特征符号如表4所示:
| 表4 上下文词概率对应特征符号 |
例如当词语W的左粘合度处于区间[0.1, 1]时, 则将该词的左粘合度信息标记为L1。通常一个给定词语的左右粘合度只有一个非零值, 特殊情况若一个词语的左右粘合度皆为非零值, 则取其中数值较大的一个, 并将其映射到相应符号。非上下文词表中词标注为N。
此外, 用户查询日志中机构名的出现还会受上下文信息及位置信息的影响, 为此本文选用表5所示特征集作为机构名识别候选特征集。
| 表5 中文机构名识别候选特征集 |
本文实验的训练语料取自人民日报1998年1月份标注语料, 经前文所述方法自动构建的训练语料, 共计包含词1166047个, 机构名22713个。测试语料选自搜狗实验室提供的用户查询日志2008年6月版本, 从搜狗用户查询日志中, 经过垃圾过滤、去重, 随机抽取12000条用户查询, 分为6组, 作为6组测试集。
实验中采用正确率P、召回率R、F值来评价机构名识别效果:假设识别出的机构名总数为B, 其中正确的机构名个数为A, 测试集中机构名的总数为C, 相应的正确率(P)、召回率(R)、F值(F)计算公式如下:
 | (3) |
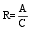 | (4) |
 | (5) |
文献[12]提出了一种针对普通文本的命名实体识别方法, 基于条件随机场模型, 将词性和词边界合为一个特征项。将该方法应用于测试集, 作为本文的Baseline, 实验结果如表6所示:
| 表6 Baseline实验结果 |
从表6中可以看出, 传统机构名识别方法在用户查询日志中的直接应用正确率较高, 原因是机构名内部构成模式规律性强、结合的紧密程度高。但由于普通文本中机构名基本都伴随着上下文环境, 而日志中大部分机构名缺少上下文, 模型从训练语料学习的知识与测试语料之间的差异性较大, 因此召回率较低。
为验证自动构建语料的有效性, 以及通过加入粘合度特征强化指界能力对用户查询日志中机构名识别结果的影响, 本文根据候选特征集, 设计两类特征模板:模板一为未引入粘合度特征的特征模板;模板二为引入粘合度特征后的特征模板。模板一由候选特征集中1-12构成, 模板二在模板一的基础上, 加入粘合度特征, 即由特征集中1-13构成。
(1)模板一实验结果与分析
采用3.2节所述语料自动构建方法生成训练数据, 并训练机构名识别模型。在测试集上进行了实验, 结果如表7所示:
| 表7 模板一实验结果 |
从表7中可以发现, 使用由自动构建训练语料方法生成的语料进行实验, 与Baseline相比, 正确率有所降低, 但召回率大大提高, F值提高了26.41%, 这是由于自动构建语料模拟了用户查询日志中上下文的环境, 使得模型能够一定程度上从训练语料中学习机构名上下文缺失知识, 因此召回率大幅提高, F值也有了较大的提升, 与预期的结果一致。
(2)模板二实验结果与分析
在上文中, 训练语料在形式得到了与测试语料对齐的处理。但人民日报语料与查询日志语料在内容上仍存在极大的差异, 这种差异也存在于上下文中, 对查询日志中机构名的识别效果造成影响。因此在后续实验中, 加入了用户查询日志中机构名上下文粘合度特征, 所得实验结果如表8所示, 模板一、模板二对不同上下文缺失情况的识别效果对比如表9所示:
| 表8 模板二实验结果 |
| 表9 模板一、模板二不同上下文缺失情况的识别效果 |
实验结果表明, 在将粘合度特征加入CRF机构名识别模型以后, 对比模板一的实验结果, 正确率提高了4.58%, 召回率提高了2.37%, F值达到79.16%, 与Baseline相比提高了30.13%。其中对于上下文均缺失的部分并无提升, 但对于缺失上文或下文, 或具有上下文的机构名, 效果提高较大。这是由于粘合度特征对于用户查询日志中的上下文词起到指示作用, 强化了模型对于日志中机构名边界的判别能力, 这些知识在引入粘合度特征以前, 无法由基于人民日报语料的训练数据获取。通过引入粘合度特征, 减少普通文本与查询日志内容上的差异性带来的影响, 提高了机构名的识别能力, 达到了预期的效果。
本文充分分析了搜索引擎用户查询日志的特点以及在用户查询日志中挖掘机构名的难点。实践已有研究方法并针对用户查询日志总结其不足, 提出了一种利用普通标注文本自动生成用户查询日志形式标注语料的训练语料自动构建方法, 并使用自动构建的训练语料, 在用户查询日志上进行开放测试, 取得了很好的效果。进一步针对用户查询日志与普通文本在机构名上下文内容上的差异提出了粘合度概念, 将粘合度特征引入条件随机场并融合多特征进行训练, 大幅提高了在用户查询日志中机构名的识别效果。
本文方法通过自动构建语料及融合粘合度特征, 实现了用户查询日志中的机构名识别, 综合性能大大高于已有方法, 并且具有较强的可移植性及可扩展性。在接下来的工作中, 可以进一步利用本方法的机构名识别结果, 辅以人工校对, 形成具有一定规模的用户查询日志标注语料。也可从机构名的内聚性作为切入点, 进一步过滤识别错误的机构名, 提高日志中机构名识别的正确率。此外, 本文方法可方便地移植到日志中其他命名实体的识别, 召回率的大幅提高意味着系统不仅仅能够提取常见的、规律性强的实体信息, 也能提取更多较为生僻、不规则的实体。由于本文方法具有较好的综合性能, 可以为相关研究工作提供更好的帮助。
| 1 |
|
| 2 |
|
| 3 |
|
| 4 |
|
| 5 |
|
| 6 |
|
| 7 |
|
| 8 |
|
| 9 |
|
| 10 |
|
| 11 |
|
| 12 |
|
| 13 |
|
| 14 |
|
| 15 |
|
| 16 |
|