

{kind=link}
{kind=link}
{kind=link}
{kind=link}
论文引文检索与分析自动化系统的构建
张素芳1, 2  , 宋虎
, 宋虎1
, 宋虎|
|


作者贡献:
张素芳,宋虎:研究命题的提出、设计,研究过程的实施;
宋虎:数据获取,提供;
张素芳:数据分析;
张素芳,宋虎:论文起草与最终版本修订。
【目的】探讨一个论文引文检索与分析自动化系统的构建, 包括其基本原理、架构、功能模块、具体实现和使用效果。【应用背景】基于引文检索与分析过程中人工操作过多、用户需求各异的特点设计, 系统可供图书馆工作人员、教学科研人员和科研管理人员使用。【方法】采用Perl语言, 在Linux环境下进行开发。【结果】实现引文检索结果的自动获取、引文数据的统计分析、引用清单的格式化生成和他引标准的多样化选择等功能。【结论】能够提高检索人员的工作效率。
[Objective] To discuss the construction of a citation retrieval and analysis automation system, the design principles, the basic structure, function modules, the realization and the results are described. [Context] Due to the characteristics of too many manual operations and the diversity of users’ demands in citation retrieval and analysis, the system is designed for librarians, teaching and research staff, and research management personnel. [Methods] The system is developed by using Perl language in the Linux environment. [Results] The automatic acquisition of search results, statistical analysis of citation data, citation list formatting and various choices of other-citing standards can be realized. [Conclusions] The system can improve the retrieval efficiency.
一直以来, 论文引文信息的检索都是国内各大高校图书馆和科技查新机构的主要日常工作之一。近年来, 随着引文信息的广泛应用, 用户对于引文检索的要求越来越具体和深入。许多用户要求区分自引和他引, 而“他引”的定义是多样的[1];除引用次数外, 用户还要求查看引文中的期刊种数、作者人数等统计分析信息;用户一般还会要求附上每篇文章的详细引用清单作为检索报告附件。目前利用一些常用引文数据库的分析功能, 虽然可获取到指定文章的总引次数、总他引次数等, 但数据库中的他引标准是唯一的;且现有数据库无法直接对各项引文数据进行分类、汇总统计;详细引用清单的生成也需要手动逐篇操作。这些手工整理和数据统计, 不但费时费力, 而且极易出错;一旦用户的他引标准有变, 整个检索工作必须全部重新来过。因此, 笔者结合日常工作实践, 总结开发了一个论文引文检索与分析系统, 以实现检索结果的获取、整理、统计等过程的自动化。
目前对引文检索、查收查引方面的探讨较多, 主要侧重讨论国内外数据库的检索技巧[2, 3, 4, 5], 研究利用和设计引文检索自动化系统或工具软件的文献较少。比较有代表性的是:李晓东等[6]提出论文查收查引工具软件, 概要介绍了工具软件的5项基本功能, 但对论文数据的查询、比对等方面的原理性描述较少, 未提及进行引文数据的各项分类统计, 也未给出软件使用前后的具体效果对比;樊亚芳等[7]利用Excel和EndNote Web相结合的方法来提高查收查引效率, 但其中仍需不少人工干预。
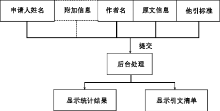
本系统旨在最大限度地减少人工参与, 提高工作效率, 正常使用的工作过程如下:创建被检索者信息——选择他引标准——上传原文信息——获取检索结果。系统开发具体满足以下实践需求:
(1)提供使用界面, 用户将需要检索的文章信息上传到系统, 后台便自动进行处理, 之后用户可获得检索结果, 系统处理过程中不再需要人为操作数据库或软件、进行复制粘贴等重复性劳动。
(2)后台处理引文方便快捷, 引文检索结果的获取、整理、统计等过程耗时短, 准确度高, 不再耗费大量时间成本和人力成本, 可缓解查新中心工作人员经常加班的状况。
(3)针对用户对他引、引文统计、引用清单的个性化要求, 分别配置不同的“他引”标准供用户选择;引文统计表格参照常见的“论文被收录与引用情况统计表”, 按照最详细的类目加以配置;引用清单根据查新中心要求, 设置成规范的检索报告所需的附件样式。
(4)为方便检索结果的保存、更新和二次利用, 系统提供检索数据的保存和调用功能。用户可直接输入被检索者信息, 即可调出之前的检索记录。
系统的基本原理是:客户端通过约定的协议向服务器端发起请求, 服务器端根据请求的内容在其本地进行检索, 然后把结果以约定的格式返回显示到客户端, 由客户端进行下一步处理。发送请求的模式采用向服务器端发送XML字符串的方式。
系统的架构是典型的网页CGI编程, 当前流行的编程语言有Perl、JSP、PHP、ASP, 本系统采用Perl语言。除了CGI模块, 还用到了XML、表格内容挖掘、数组比较、数据库以及时间函数等, 将来还可以使用网页模板函数, 以美化系统界面。系统的使用流程如图1所示:
 | 图1 论文引文检索与分析自动化系统使用流程 |
系统主要功能大致可以分为三大模块:输入信息部分、输出信息部分和后台处理部分。
(1)输入信息部分。包括:输入作者信息及其他附加信息, 如作者姓名、单位、工资号等;上传原文信息, 如原文的WOS入藏号(Web of Science中的18位文献识别号, 以下同)、原文的标题;选择引用要求, 如是否区分自引、他引以及他引标准的选择。
(2)输出信息部分。包括:引文统计信息, 如引用次数、他引次数、期刊种数、作者人数、第一作者/通讯作者论文数等;引用清单, 即罗列出每篇文章的详细引文信息, 可自定义输出格式, 方便输出保存或打印, 直接形成最终的引文检索报告。
(3)后台处理部分。为系统的核心设计部分。目前笔者已实现了面向常用引文数据库——WOS(Web of Science)和CSCD(中国科学引文数据库)的系统设计, 两者设计思路类似, 下面以WOS为例来介绍具体的实现。
(1)引文数据的自动获取与保存
在WOS中,首先通过使用其文章链接服务(Links Article Match Retrieval,LAMR)[8]来获取原文相关信息。原理是:先构造XML字符串,生成XML字符串后,再利用Perl的LWP: : UserAgent模块把这个字符串Post到LAMR的服务地址,可以得到响应的XML字符串,对其进行解析即可得到每篇文章的被引频次、DOI等信息。
然后进行引文数据挖掘。根据WOS入藏号, 得到对应的原文网址和它所有引文的网址, 利用Perl的WWW: : Mechanize模块来模拟浏览器访问原文网址, 得到页面内容, 再利用Perl的HTML: : TableExtract模块, 从页面的表格中挖掘出所需要的任何信息。其中最重要的是作者信息和来源信息。同样地, 用Perl的WWW: : Mechanize模块模拟浏览器里的表单提交操作, 就可以保存所有的引文记录成HTML格式。代码示例如下:
$mech->submit_form(
form_name => 'output_form',
fields => {
format => 'saveToFile',
filters => 'ISSN CONFERENCE_SPONSORS CONFERENCE _INFO SOURCE TITLE AUTHORS',
mark_to => $res_count,
mark_from => 1,
'value(record_select_type)' => 'range',
markFrom => 1,
markTo => $res_count,
save_options => 'html',
},
);
再用Perl的HTML: : TableExtract模块得到所有引文的信息, 包括题名、作者、来源、入藏号等。通过上述操作, 每篇原文和它的所有引文数据都被保存。
(2)引文数据的统计分析
一旦原文和其引文数据都保存在本地数据库中, 系统就可以自如地进行统计分析。对于每篇原文, 首先取出其所有的作者, 保存成数组authors_orig, 然后取出其所有的引文作者, 保存成数组authors_ref。根据这两个数组的交集, 来判断自引、宽松他引和严格他引。系统中“宽松他引”定义为:引用文献中不含有被检索作者, “严格他引”定义为:引用文献和被引用文献中没有相同的作者。两组数组如果交集为空, 表示严格他引;如果交集包含被检索者本人, 表示自引;其他情况则表示宽松他引。代码示例如下:
my $lc = List: : Compare->new('-a', \@authors_orig, \@authors_ ref);
my @inter=$lc->get_intersection;
if(@inter==0){ $strict=2; }
elseif(/^$applicant$/i~~ @inter){ $strict=0; }
else { $strict=1; }
根据引用的类型来标记每篇引文, 同时将原文作者信息、引文作者信息和引用类型的关联保存到数据表中。有了这些数据, 就可以通过SQL查询语句, 得到他引次数、引用期刊种数、引用作者数以及单篇他引最高次数的数据统计。
(3)引用列表的格式化生成
利用SQL查询语句, 从数据表中取出每篇原文的信息和相应的引文信息, 根据预设的规则对数据进行处理, 可以生成格式化后的引用列表。代码示例如下:
$authors=separate_authors($applicant, $authors, '');
$source=fmt_source($source, 'default');
$refli_header=fmt_refli_header($i, $total, $title, $authors, $source,
$ut, $times_cited, $total1, $style, 'default');
...
$refli_content.=fmt_refli_content($i, $j, $authors, $title, $source, $year, $volume, $issue, $begin_page, $end_page, 'default');
…
print $refli_header.$refli_content;
(4)检索结果的调用
利用jQuery UI的Autocomplete功能自动匹配数据表内的作者信息, 然后调用统计模块, 即可实现检索结果的调用功能。用户可以随时调出以前的检索人信息, 直接查看引文检索结果, 无需重新上传原文信息, 如图2所示:
 | 图2 检索结果的调用 |
系统同时允许对CSCD数据库的引文进行自动检索和分析。与WOS不同的是, 系统是直接以模拟表单提交的方式(使用Perl的WWW: : Mechanize模块)去获取每篇原文的引文页面链接, 进而抓取页面内容、获得引文信息。
以检索作者“胡隆华”19篇论文的WOS引用情况为例, 输入作者的相关信息, 选择“宽松他引”标准, 再上传包含文章信息的.txt附件后, 系统便自动运行, 只需110秒, 检索结果即可呈现, 如图3所示。结果包括各项数据统计表格, 下方默认给出文章收录引用的简要格式信息, 并可查看详细引文清单。
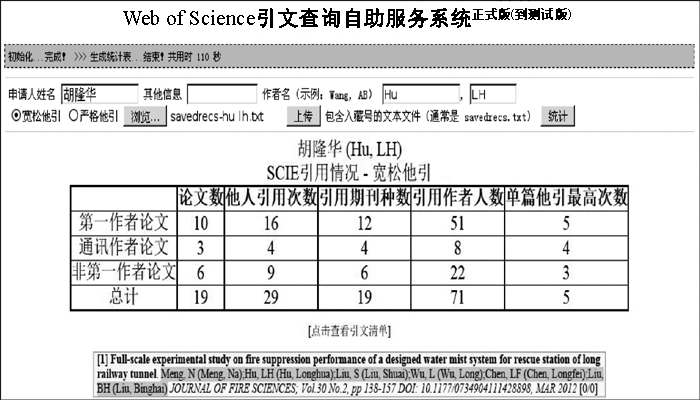 | 图3 系统的具体运行界面 |
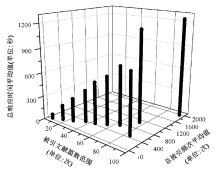
目前该系统已投入批量检索的实际使用中, 通过不断测试与完善, 从整体效果而言, 准确度可达99.5%以上。由于系统使用的是来自引文数据库的数据, 因此影响系统准确率的因素主要包括:引文数据库中的数据有误, 比如作者姓名拼写错误;引文数据库中的数据不全面, 比如通讯作者信息不全。这些会造成发文统计、引文统计等分类统计数据有误。系统可进行相应算法设置, 将可能出错的部分高亮显示, 以便于人工修正保存。笔者从系统已有的数据中, 随机挑选出350余次的检索数据, 绘制时间效率三维图, 如图4所示:
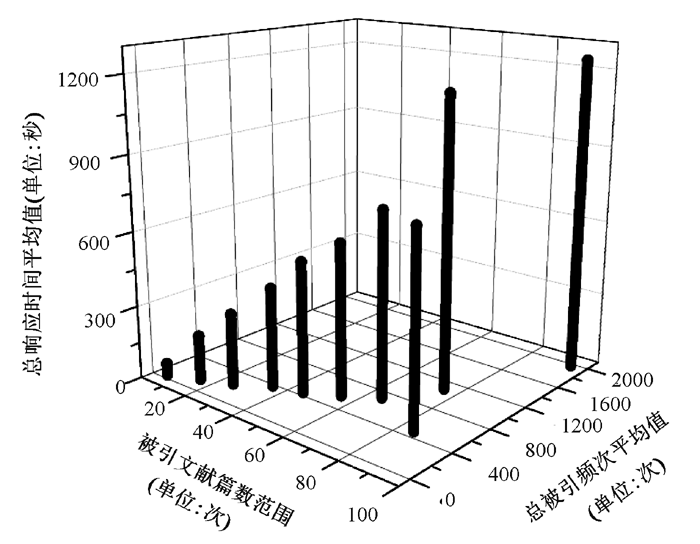 | 图4 100篇以内文献引文检索时间平均值 |
从图4可以看出, 原文篇数越多, 被引次数越高, 系统完成时间越长, 但相对手工检索节约了更多的时间。假设完成相同检索, 在获取、整理、统计引用信息的过程中, 系统完成平均时间与传统手工检索估计时间的对比情况如表1所示:
| 表1 系统完成平均时间与手工检索估计时间对比 |
从表1可以看出:对于被检索者而言, 获得引文检索结果, 利用系统至少可以节省86%以上的时间;对于查新机构工作人员而言, 虽然系统运行需要一段时间, 但在此期间无需人工干预, 检索人员可以同时处理其他工作, 完全从传统的手工操作中解脱出来。除此以外, 系统通过日常检索数据的积累与科研管理系统的人事、论文数据进行对接, 可以帮助科研管理人员:查看本机构总体发文和引文情况, 也可具体到按学院、系别来查询数据;对本机构重点人才的发文和引文情况进行动态跟踪、监测, 建立机构人才库, 为人才引进、人才评估等提供必要的数据支撑。
总体而言, 系统实现了高效快捷的引文检索, 解决了人工检索耗时多、重复性劳动的问题;并可与机构论文库、科研管理评价系统等进行一定的对接, 扩大其使用效果。但系统也存在一些局限, 如考虑到设计的可行性, 文章引文信息的获取, 使用文章的“被引频次”来进行, 深究起来, 这与严格意义上的“引文检索”入口得到的信息会有些许差别[9];另外, 系统检索速度会受到网速和数据库并发用户数量的影响, 这些还有待于在以后的研究中逐步完善。未来, 系统将在数据预处理、界面交互性、友好性、结果定制性以及架构的模块化、数据的API接口等方面进行改进和开发。
| 1 |
|
| 2 |
|
| 3 |
|
| 4 |
|
| 5 |
|
| 6 |
|
| 7 |
|
| 8 |
|
| 9 |
|