

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于本体的云服务语义检索系统研究
[唐守利1, 2  , 徐宝祥
, 徐宝祥1 ]
, 徐宝祥|
|


作者贡献声明:
徐宝祥: 提出研究思路, 设计研究方案;
唐守利: 采集、清洗和分析数据, 完成实验, 论文起草和最终版修订。
【目的】因用户可应用的云服务数量呈指数级增长, 进而产生云服务发现和选择相关问题。【方法】语义检索技术采取信息检索、语义分析和信息融合等方法提高云服务检索效率, 并结合本体技术保持检索内容的准确性和一致性, 实现用户基于关键词发现和选择云服务。【结果】实现对云服务的语义表示和标注, 根据标注结果进行术语抽取, 采用向量值创建语义索引, 利用语义搜索引擎计算索引与关键字之间的相似度, 得出关键字与文本之间的相似度。【局限】语义检索系统中部分模块涉及的相关算法仍有待深入研究, 本文从整体性研究语义检索系统, 各模块仅应用基本算法, 没有涉及算法改良。【结论】经过实证评估分析, 本体技术应用于语义检索系统能够有效提高云服务检索精准度, 特别适用于非结构化信息检索, 但需要保持本体与语义变化的一致性。
[Objective] As the number of available cloud services increases exponentially, the problem of cloud service discovery and selection arises.[Methods] Semantic retrieval technology in use of information retrieval, semantic analysis and information fusion can improve retrieval efficiency. Combined with Ontology technology can ensure search processes accuracy and consistency, and realize cloud service discovery and selection.[Results] This paper can semantically represent and semantically annotate cloud services. According to extracting semantically annotate terms, it applies vector value to create semantic indexing. Using semantic search engine calculate vector space value between query sentence and index data, and obtain documents similarity.[Limitations] Relevant algorithms involved in some semantic retrieval system are still in development. This paper researches semantic retrieval system as a whole, every module just applies these basic algorithms, algorithm improvement is not involved.[Conclusions] Empirical research proves Ontology technology applied in semantic retrieval system achieves good effects. Especially it is suitable for retrieval of unstructured information, when changes between Ontology and semantic need to keep consistency.
互联网技术快速发展使得云服务资源激增, 传统信息检索技术难以满足用户复杂多变的需求, 语义检索技术能够解决在庞杂无序的海量信息中快速定位用户需要检索的信息, 提高信息检索查全率和查准率。语义检索分为基于本体的语义检索和基于概念的语义检索。其中基于本体的语义检索成为关注的热点, 因为本体能够表现概念的层次结构和语义模型, 适用于众多领域。本文提出一种基于本体的框架, 该框架能够语义化标注现有云服务, 对已标注云服务实现语义检索, 最终提高云服务检索能力。该框架提出基于本体的语义检索系统实现的基本原理和方法:
(1) 利用语义标注技术标注云服务资源;
(2) 基于关键字采用语义索引检索云服务资源。
(1) 研究现状
国外对基于本体的语义检索研究较早, 其中比较知名的研究包括: (ONTO)2Agent帮助用户获取万维网已有的本体信息[1]; OntoBroker按照用户关注内容检索万维网中网页信息[2]; SKC利用代数方法合成不同领域本体, 消除语义异构本体互操作问题, 斯坦福大学研究的本体代数项目, 提供一种新方式检索海量语义且互斥的信息资源[3]。阿姆斯特丹自由大学和荷兰Elsevier出版社合作开发一个医学文献语义检索工具, 其中本体以EM树状叙词表作为术语结构, 提供与疾病相关的药物本体信息检索[4]。ITTALKS是美国马里兰大学开发的一个基于本体的Web门户系统, 主要对IT领域内各种会议信息进行智能集成和智能在线检索[5]。TAMBIS是英国曼彻斯特大学为生命科学研究者提供的一个单独访问结点, 利用本体对生物信息学各种资源进行描述, 帮助用户返回具有一致性的检索结果[6]。
国内研究起步较晚, 浙江大学CADAL项目— — 数字图书馆与海量信息搜索引擎, 实现以海量文本、图像、视频、书法和数字化文物分析、理解、索引、知识挖掘为核心的检索共享服务[7]。中国科学院数学研究所陆汝钤院士提出基于本体的常识知识库研究, 建立一个大规模基于本体的常识知识库, 并尝试利用常识知识解决一些实际问题[8]。中国科学院计算技术研究所基于本体论和多主体的信息检索服务器, 集成多个主体对文档进行领域分类, 具有较好的信息检索引导能力[9]。
国内研究以理论方法居多, 系统应用性研究相对国外较少, 这一现状决定国内未来一段时间本体与语义检索是重点研究内容。本文根据国内外研究现状, 立足于云服务领域, 提出一种基于本体的语义检索系统。
(2) 研究基础
目前云服务[10]数量呈指数级增长, 而云服务供应商现有应用程序需要满足不同用户的需求, 手动服务发现严重阻碍了云服务的发展, 用户很难准确检索适合的云服务, 因此云服务需要解决检索与提取的问题[11]。采用语义化自动检索方式是云服务未来的发展方向, 云服务需要采用语义技术表示。语义技术可以添加语义化数据, 使机器能够自动处理这些数据[12]。本体[13, 14]提供一种形式化、结构化知识表示方式, 并且具有可重用和共享的特性。因此, 运用本体和语义技术可以克服传统检索技术的局限性。
标注将属性、内容或描述注释在文档中, 作为补充信息关联其他文档。标注具有三种类型: 手动标注、半自动标注和全自动标注[15]。将应用自然语言描述的云服务文档中插入注释进行语义标注, 注释表示本体元素(属性、概念、关系和实例)之间的联系[16]。对已标注云服务信息进行术语抽取的方法主要有三种类型: 基于语言学规则的方法、基于统计学的方法和基于规则与统计的方法[17]。C-value方法基于统计方法实现术语自动抽取, 主要计算术语的单元性(Unithood)[18]。NC-value方法将词语本身统计特征和词语出现的上下文环境特征相融合, 提高术语识别准确性, 融合上下文词汇权重[19]。
云服务实现用户或云应用程序通过网络请求调用执行任务的一系列功能, 语义检索通过自然语言处理技术提升检索质量和性能, 将语义检索技术应用在云服务领域, 有助于用户快速、准确地获取相应服务。由于云服务是新兴技术服务, 目前提供服务的各类应用程序没有形成统一标准和接口, 因此, 设计面向云服务的语义检索系统需要考虑标准转换, 以及接口集成。通过对语义检索系统特征分析实现云服务研究, 同时, 通过云服务特征研究改进语义检索系统。本文设计的语义检索系统旨在实现自动发现云服务, 其中语义标注机制能够支持本体, 采用自动化标注云服务有别于其他自然语言描述的效果, 能够处理非结构化文档。应用C-value和NC-value算法实现术语自动抽取, 并提高术语抽取准确率。采用TF-IDF算法计算语义索引, 提高云服务检索精度。
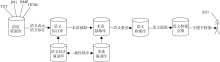
系统框架主要由4个模块组成: 语义表示和标注模块; 术语抽取模块; 语义索引模块; 语义检索引擎模块。其中语义标注模块和术语抽取模块, 为保证语义标注变化和本体变化一致性, 分别对应语义标注演进模块和本体演进模块, 但这两部分内容在其他文献中已进行了研究, 具体内容本文不再体现。该系统工作原理如下: 语义化表示和标注应用自然语言描述的云服务; 对语义标注的术语进行抽取; 对候选术语采用向量空间模型创建语义索引; 语义搜索引擎基于关键字检索进行匹配服务, 计算关键字与文档之间的相似度。各模块功能如图1所示。
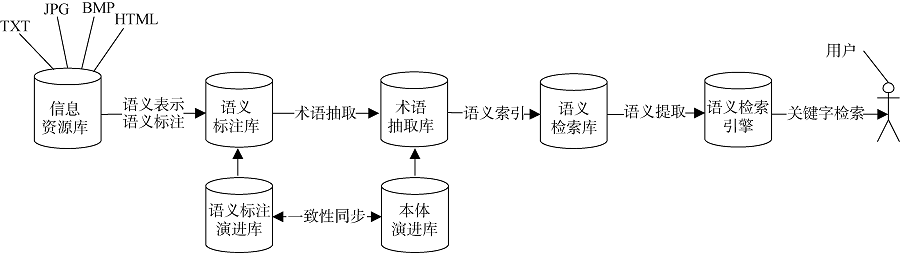 | 图1 系统体系框架 |
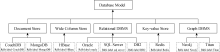
该模块主要有两个阶段: 自然语言描述阶段和语义标注阶段。自然语言描述阶段抽取每个句子形态语句结构, 获得对文本语法结构的语义表示。本系统选择GATE框架, GATE是开发和部署软件组件处理人工语言的基础①(① https://gate.ac.uk/.)。语义标注阶段将自然语言描述的云服务标注为本体的类和实例。具体方法如下: 借助统计学方法验证语言表达式的语法结构; 对于每个语言表达式, 系统检测该表达式是否为本体的一个类, 采用RDFS建立类和属性、值域和定义域、在属性上的约束以及子类和子属性的包蕴关系。图2表示一个数据库模式的本体摘要, Database Model相关的一些类和实例。其中概念Document Store、Wide Column Store、Relational DBMS、Key-value Store和Graph DBMS 具有共同的祖先。这些概念既可以表示上层概念Database Model的直接孩子结点, 也可以表示上层概念Database Model的间接孩子结点。
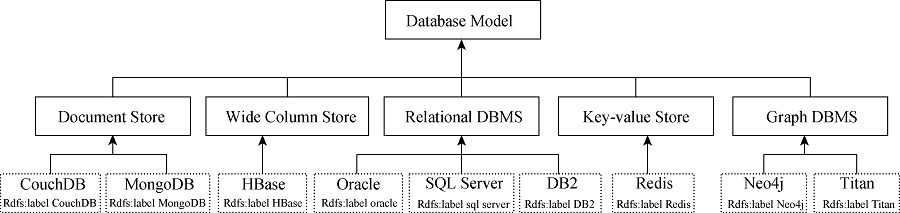 | 图2 数据库模式的本体摘要 |
假设存在图3和图4中两个云服务文本描述信息。图中加黑斜体文字表示根据GATE工具对本体实例进行的标注。
 | 图3 云服务描述信息1 |
 | 图4 云服务描述信息2 |
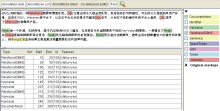
应用GATE工具对图3和图4中云服务文本描述信息进行标注, 各类颜色文字表示标注结果, 如图5所示。
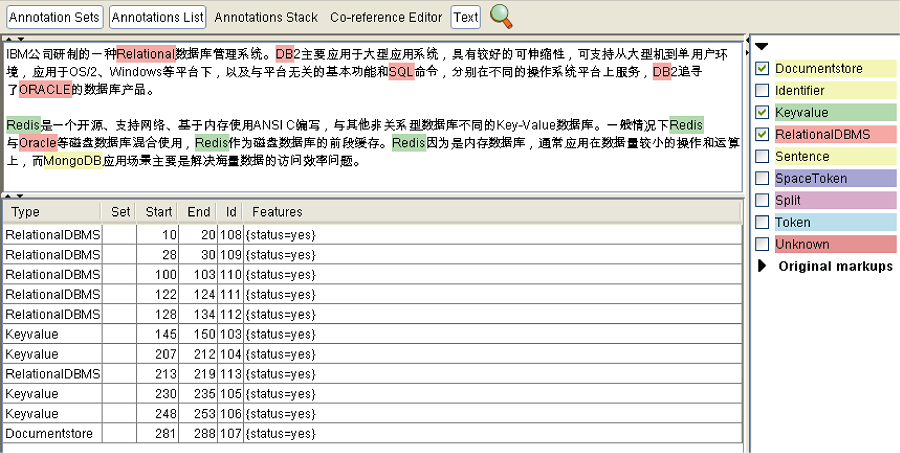 | 图5 基于GATE的语义标注结果 |
通过本模块识别最重要的术语。采用C-value算法处理上下文单词, 根据语法范畴划分这些单词。对术语列表分类并计算: 候选术语在较长的候选术语中出现频率; 该段较长的候选术语出现频率; 候选术语长度; 候选术语在语料库中出现次数总和。C-value算法如公式(1)所示[18]:
其中, a表示候选字符串; |a|表示候选字符串长度; f(a)表示候选字符串a出现频率; Ta表示包含候选字符串a的候选术语; P(Ta)表示包含候选字符串a的术语总数。
利用C-value方法进行术语抽取时, 既要计算C-value值, 另外需要构建词性过滤规则, 只有符合词性过滤规则的术语参与C-value值计算。由于多数术语由名词、形容词、动词组成[20], 因此本文构建的过滤规则主要考虑上述三种词性。
通过C-value算法生成候选术语列表, 需要在候选术语列表中获得一个较高的精确度, 然后通过在上下文术语中应用NC-value算法过滤列表。计算上下文单词, 再根据语法类别划分(例如: 形容词、动词或名词), 获取一个“上下文加权因子” 的权重, 这种方法可以计算术语上下文词的出现概率, 权重获取如公式(2)所示[19]:
其中, w表示候选字符串a的上下文中的词汇(名词、动词或形容词), t(w)表示与词汇w一起出现的术语数目, n表示所有候选术语总数, weight(w)表示上下文加权因子。
获取权重分数后, NC-value可以通过公式(3)计算[19]:
其中, a是候选字符串; Ca是a的一组上下文单词; b是Ca中的一个单词; fa(b)是b在上下文a中出现频率; weight(b)表示b作为上下文a的权重。
公式(3)中, 第一部分因子是“0.8” ; 第二部分因子是“0.2” , 此因子经过多次检测后赋值[21]。如果候选术语的C-value乘以“0.8” , 对应上下文单词的单个权重总和乘以“0.2” , 候选术语按照NC-value结果从高到低排列。
在此模块中, 系统检索术语提取模块获取的候选术语, 并且分配这些候选术语一定的权重。其反映本体的实例与文档的含义之间的相关性。权重计算方法采用TF-IDF算法[22] , 如公式(4)所示:
其中, ni, d是本体实例i在文档d中出现次数,
根据上述情况, 云服务描述需要分析文档。对每一个描述, 提出基于向量空间模型计算索引。每个服务都表示为一个向量, 每个维度对应本体中的概念。计算每个本体概念维度的值[23], 如公式(5)所示:
其中, dist(i, j)表示本体中概念i和概念j之间的语义距离。采用本体概念的分类(subclass_of)关系计算语义距离。一个概念与其本身的语义距离是0; 一个概念与其分类的父结点或子结点之间的语义距离是1, 以此类推。
语义索引模块应用公式(4)和公式(5)计算每个服务相关的索引。应用TF-IDF值和向量值算法计算每个文档的向量分量, 如表1所示:
| 表1 空间向量模型的概念维度 |
表1中TF-IDF值为0 的概念没有出现在文本描述中, 在实际的服务描述中, 由于与本体中其他概念的语义距离, 反而使其获得较高的向量值。因此, 假设如果用户采用关键字“CoughDB” 检索一个服务, 系统将推荐第二个文档。例如: 第一个服务中“Oracle” 的向量值和TF-IDF值高于第二个服务中的值, 因此, 如果用户检索关键字“Oracle” , 系统将首先推荐第一个文档。实际上, 与“Oracle” 相关的其他概念总是出现在这些服务的文本描述中。利用本体中概念之间的语义距离可以提高准确率, 并减少不确定性。
此模块主要基于关键字检索云服务, 云服务在被检索之前按照2.1节内容逐步抽取生成一个本体库。用户选择一系列关键字查询, 搜索引擎识别出本体库内与关键词关联的概念。2.3节中已经说明每个服务“s” 表示一个向量, 该向量的每个维度对应本体中的一个概念。同时, 每个检索“q” 也表示一个向量, 该向量是搜索引擎抽取的一个概念, 与本体库中的概念在检索时进行匹配。为保证向量s与q的维度一致, 向量“q” 对应本体库中其他概念的向量分量值为0。语义搜索引擎采用余弦相似性原理计算某个检索q和每个服务s之间的相似值[24]。如公式(6)所示:
余弦相似原理解释如下: θ 是一个角度, 表示检索q与服务s之间相似值。如果夹角为0° , 表示基于关键字检索两篇文本完全相似; 如果夹角为90° , 则两篇文本完全不相似; 通过夹角大小, 可以基于关键字检索判断文本内容相似程度。夹角越小, 表示文本越相似, 反之文本越不相似。
根据上述内容, 假设用户输入关键字“DB2” , 搜索引擎识别出已经创建云服务本体(见图2)中与其关联的概念, 在图3和图4的云服务描述中, 都检索到相应的概念“DB2” , 再根据公式(6)计算关键词与云服务文本描述之间相似度, 图3中cosθ = 0.622, 则夹角θ 为51.5° ; 图4中cosθ = 0.041, 则夹角θ 为87.6° 。余弦夹角越小表示关键字与云服务文本描述越相关, 因此语义搜索引擎会推荐图3表示的云服务。
根据图1的系统架构分别实现语义检索系统中的语义表示和标注模块、术语抽取模块、语义索引模块和语义检索引擎模块。针对IaaS领域云服务, 按照语义检索系统各模块功能设计, 实现基于关键词检索进行系统性能评估。
(1) 根据云服务语料库选择自然语言描述的IaaS领域云服务(表2为部分IaaS领域云服务), 对IaaS领域云服务按照语义表示和标注模块实现方式进行语义标注, 将标注结果作为一个本体的新实例插入本体中, 逐步完善本体的类和实例;
| 表2 IaaS领域云服务实例表示 |
(2) 根据术语抽取模块中实现算法, 获取IaaS领域云服务相应的候选术语;
(3) 按照语义索引模块实现算法计算IaaS领域云服务候选术语的向量值, 作为语义搜索引擎查询的基础数据;
(4) 根据语义搜索引擎原理实现基于关键字查询, 由搜索引擎识别出本体库内与关键词关联的概念, 计算关键字与IaaS领域云服务文本描述的相似度。
IaaS领域云服务实例部分如表2所示。每一列表示云服务IaaS领域本体的一个属性: 第一列表示云服务实例的名称; 第二列表示云服务的供应商; 第三列表示自然语言描述的云服务。
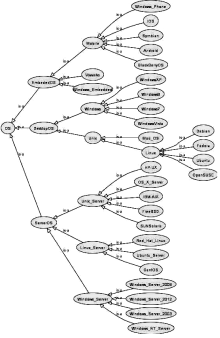
近几年, IaaS领域云服务已经开发了数个本体和词汇表。本文根据云服务语料库选择约100种自然语言描述的IaaS领域云服务, 然后根据2.1节应用GATE工具对这些自然语言描述的云服务进行语义标注, 再利用Proté gé 工具②(② http://protege.stanford.edu/.)将这些标注结果作为新实例插入本体中, 逐步完善本体的类和实例。按照上述步骤逐步生成一个表示OS(操作系统)IaaS领域云服务本体摘要, 如图6所示:
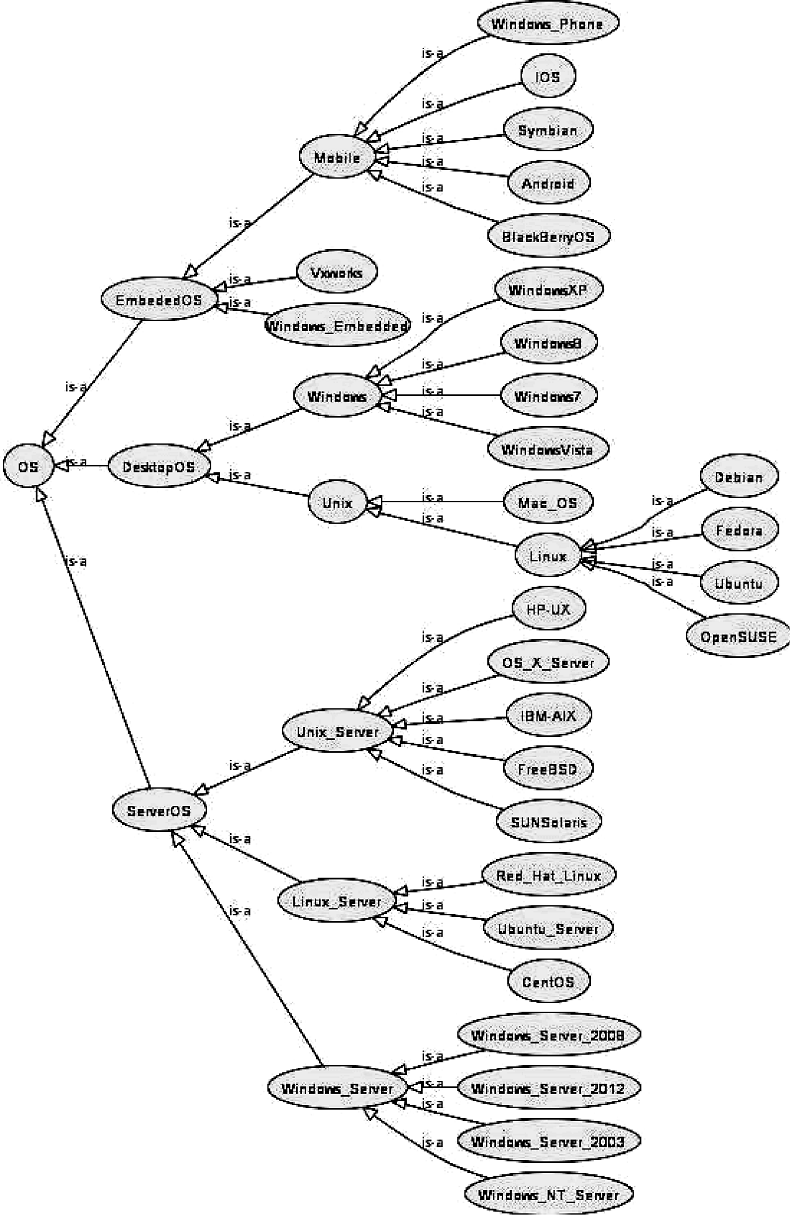 | 图6 IaaS领域云服务本体摘要 |
在3.1节中对IaaS领域云服务进行语义标注, 在3.2节中逐步构建完善一个IaaS领域云服务本体, 再根据术语抽取算法和语义检索算法分别得到候选术语和候选术语的向量值。完成上述工作, 可以通过语义检索模型计算相应的语义索引, 实证评估通过语义索引计算基于关键词查询的精准度、召回率和F值。
实证分析采用的语料库为搜狗语料库2.0①(① http://www.sogou.com/labs/dl/t.html.), 其中与云服务领域相关的200篇文本作为前景语料, 选取与云服务领域无关的600篇文本作为背景语料, 背景语料涉及新闻、文化、教育等领域。对云服务语料采用ICTCLAS5.0②(② http://www.ictclas.org/.)工具进行文本预处理(分词、去停用词等), 语料共包含65 387个词语。按照(名词、动词或形容词)组合规律进行过滤, 从语料中抽取出2 463个候选术语。对术语进行筛选, 最后选择适用于IaaS云服务领域的357个候选术语。基于“Linux” 、“应用软件” 、“系统平台” 、“数据库” 、“Windows” 这5个关键词进行查询, 对5个关键词查询在IaaS云服务领域的精准度、召回率、F值进行评估。以“Linux” 关键字为例, 随机抽取100篇云服务前景语料和300篇云服务背景语料, 其中关键字分布在23篇云服务前景语料中, 最终在21篇云服务前景语料中检索到表达精准度的关键字; 另外, 关键字出现在云服务背景语料1次。按照上述算法计算基于关键字抽取相应的IaaS领域云服务的精准度、召回率和F值, 评估结果如表3所示:
| 表3 5个关键词查询的精准度、召回率、F值 |
表3中的准确率、召回率都取平均值。对于“Linux” 这个查询获得精准度为0.95, 表示相关查询中95%是云服务列表中推荐的; 召回率是0.91, 表示系统没有抽取到9%的云服务实际上是非常相关的查询; F值为0.93, 表示“Linux” 获得了较好的准确率与召回率的平均权重值。
通过分析可以得出, 整体上这5个关键词检索结 果较好。总结这些结果较好的原因, 因为这些检索的云服务背景语料与IaaS云服务领域非常相关, 所以抽取的服务数准确率较高。另外“Linux” 和“Windows” 获得了较好的检索结果, 因为在语料库中抽取的英文术语其上下文多数是中文, 因此能够相对准确地抽取到其服务, 所以获得较好的检索结果。
本文提出一个基于本体的云服务语义检索系统, 系统自动标注应用自然语言描述的云服务, 包含多种文本格式, 例如: TXT、JPG 或者XLSX。构建一个云服务本体库, 从而发现满足一定约束条件的云服务。本文相关研究的优势在于应用语义检索与本体结合, 提出的观点能够解决普遍性问题, 即从非结构化文档中生成语义标注, 并采用C-value和NC-value算法实现对语义标注的术语进行抽取, 再利用TF-IDF算法计算候选术语向量值, 通过创建语义索引实现基于关键字检索云服务资源, 利用语义搜索引擎计算索引与云服务文本之间的相似度。最后, 本文结合IaaS领域云服务的部分实例, 在构建IaaS领域云服务本体基础上, 对关键词检索进行实证评估。
在今后研究中还有一些重要的内容需要持续关注。例如: 如何进一步保持自然语言描述和标注之间的一致性, 已标注的内容如何存储, 持续更新的本体如何保持变化的准确性等问题。这些需要实时适应本体变化的研究领域, 需要研究更深层次的本体演进和语义标注演进等内容。另外, 本文应用本体和语义信息分析了对自然语言描述的云服务, 今后可以深入研究推荐系统, 在特定的领域能够根据用户设定的偏好信息返回相关的服务, 从而满足一定分类需求的服务, 进而提供非功能化属性的信息。此外, 进行对关键词查询的精准度与召回率评估时, 可以考虑不同长度的关键词, 对比查询效果。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|