

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
依存句法模板下的商品特征标签抽取研究
[聂卉 , 杜嘉忠]
, 杜嘉忠]
, 杜嘉忠]
|
|


作者贡献声明:
聂卉: 论题拟定, 修改完善论文, 最终版本修订;
杜嘉忠: 提出研究思路, 设计研究方案, 数据采集与实验, 初稿撰写。
【目的】面向在线商品评论, 通过探索“产品特征-观点”对应关系的识别方法, 抽取商品特征标签, 凝练评论精华。在网络资讯良莠混杂的环境下, 帮助用户有效获得有价值的资讯。【方法】引入依存语法关系, 对评论模板实现自动分类、过滤、泛化并形成模板库。基于模板库和外部词典提取特征标签, 同时确立候选标签的筛选过滤机制。【结果】面向真实的网络评论集, 本文方法的性能优于单纯过滤与泛化的抽取方法。F值最优达到56.5%, 调整参数后, 准确率达到65%。【局限】需要在特征抽取前依据评论语句质量进行前期过滤, 考虑特征词库的自动化获取, 在模板形成过程中, 还需添加更多的句法关系, 进一步提高特征标签的抽取准确度。【结论】单纯依据句法模板频率进行模板过滤的方法有提升空间。特征抽取过程考虑模板的长度特征, 设定抽取窗口, 对特征标签进行筛选、合并特征能获取更好的抽取结果。
[Objective] The method of association recognition for features and the relevant opinions is investigated in order to extract features tags and summarize users’ generated online reviews, which is helpful for Web users to access useful information effectively, especially when online information normally varies greatly in quality.[Methods] The dependency parsing is employed to obtain the extraction templates, the template library is constructed after the processes of classifying, filtering and generalization. In terms of the templates and the corresponding external lexicons, feature tags are extracted and sifted out according to the filtering rules.[Results] The experiment results indicate that the method outperforms the similar one which is only based on templates filtration or generalization. The performance of F-measure achieves 56.5% and the accuracy could reach 65% by adjusting the corresponding parameters.[Limitations] The filtering strategy for improving the quality of review data is not conducted in the research. Building feature lexicon automatically and adding more syntactic relations need to consider to extend the library of templates and make improvement of extraction accuracy further.[Conclusions] The better performance can be achieved by finding the most appropriate values for the template-specific parameters, such as the length of template, or by adopting an effective filtering window strategy to detect the noise templates.
近年来随着电子商务的发展, 消费者开始倾向于通过网络进行购物。截至2014年6月, 我国网络购物用户规模达到3.32亿, 网民使用网络购物的比例升至52.5%[1]。许多消费者在电子商务网站购买商品后都会在网站或论坛上发表评论, 对购买的商品进行评价。这些评价形成了巨大的商品“在线口碑” 。研究表明[2], 网络环境中, 社区发展、情感分享、信息回报、支持/惩罚商家、改进服务、感知有用性影响了消费者传播口碑的意愿。因此在一个成熟的电子商务平台, 用户会更加愿意表达自己的观点。作为有商业利用价值的 “在线口碑” , 其真实、信息量丰富的特点使之成为商家和消费者共同关注的网络资讯。然而, 大量涌现的“在线口碑” 导致信息过载问题日益严重, 无论用户还是商家, 要从海量的评论数据中及时准确地发现有用信息的成本也变得越来越高。因而, 如何在大量涌现的商品评论中提取有价值内容, 确保不损失评论主旨和观点的前提下, 将其凝练为更简洁、形式结构化的特征描述, 方便消费者和商家的利用, 以及如何深度挖掘“网络口碑” 的应用价值, 成为电子商务业界和学术界共同关注的热点问题之一。
本研究直接面向在线商品评论, 即商品的“网络口碑” , 研究提炼产品特征及对应评价的方法, 通过引入特征标签的概念, 尝试抽取“特征” 与“评价词” 之间的对应关系, 整合评论内容, 精炼评论人对产品细节的观点, 生成基于特征评价的产品描述。研究目的在于通过探索产品特征、观点评价及“特征-评价词” 对的识别方法, 构建面向内容的信息抽取模型, 汇总用户观点, 提升评论内容质量, 在网络资讯良莠混杂的环境下, 帮助用户有效获取在线商品评论中具有高信息量和重要参考价值的内容, 促进网络信息效用最大化, 并为深层次的后续应用研究奠定基础。
具体而言, 本文研究面向特定产品的评论文本。例如, 一条典型的手机产品评论, “手机刚开始使用就发现听筒有电流声, 也就是噪音非常大, 像听筒的喇叭坏掉一样。” 研究目标就是提炼出“听筒-电流声” , “噪音-大” 这样一组描述产品特点和对应观点的特征标签。研究任务主要涉及以下两个关键问题:
(1) 特征词和评价词搭配关系的识别, 明确评价内容及相应观点。
(2) 复杂的自然语句中往往蕴含多个特征和多个评价词, 多重对应关系的辨别, 确保对内容的准确理解。
另外, 面向海量内容, 提取过程要求自动化。因而, 本研究被描述为从商品评论中自动抽取“特征-评价词” 标签的评论挖掘子任务。
与特征标签抽取相关的研究工作, 大多嵌入到情感分析和观点挖掘的子任务中[3], 总结起来可分为基于统计特征和基于语义特征两类方法。统计特征方法运用统计分析提取特征词, 再依据邻近原则辨识相应观点[4, 5]。语义特征方法则将语言学知识引入分析过程[6, 7, 8, 9, 10, 11, 12, 13]。由于英文单词间存在自然分隔, 语法和句法相对规范, 国外研究中, 相关研究多为基于语言层面的探索。早期策略是模板匹配, 如直接选取距离特征词最近的形容词[4, 5]为评论观点词, 但因为忽略了语义关联, 提取精度并不十分理想。进一步, 有研究利用句子结构, 通过特征词与观点词的修饰关系提取特征标签, 语言特征的引入明显改善了抽取效果。只是人工定义的语言模式面向特定句型, 过度泛化导致生成大量候选词对, 后序往往需要手工筛选[5]。于是, 自动化方法受到关注。计算语言学的句法分析被引入, 根据依存句法分析, 获得抽取规则[6], 发现和构建有效句法规则成为影响系统效能的关键[7]。
由于中英文在形式、语法、结构上的差别, 中文领域相关研究略滞后, 目前主流方法是模板抽取。模板特指特征词和对应评价词间的修饰或句法关系。模板抽取涉及模板库构建及评价搭配抽取两个主要任务。模板库构建依据语料提炼符合逻辑的句法结构, 可采用手工或自动模式。手工模式通过归纳常见的句法修饰关系, 如主谓搭配[9], 利用组块概念提炼组合搭配模式[10]。方法精确, 但比较简单, 对复杂句法关系的覆盖有限。为更好适应更多领域应用, 针对中文, 陈炯等[12]提出了自动提取模板的方法。他们采用依存句法分析, 根据句法树路径识别特征和评价词的关联, 模板具有通用性。但自动抽取会导致精度降低, 降噪和泛化是需要解决的主要问题。过滤机制往往被用于降噪, 如频率过滤[11, 12]和置信度过滤[13], 以剔除错误模板, 提高抽取精度。频率过滤直观简单, 但受语料质量的影响。置信度搭配相似度的方法主要存在实效问题。本研究面向源自网络的真实评论数据, 数据量大, 基于实效考虑, 采用频率过滤。模板泛化则为提高查全率, 有基于编辑距离[11], 总结泛化规则[12]以及基于相似度等方法[11], 在存储与识别匹配阶段均可采用, 增强模板的涵盖力。对评价搭配的这类抽取任务, 模板匹配策略更实用。一方面, 模板匹配基于语言规则, 不受训练语料影响, 效果比较稳定。另一方面, 如果能够较好地提取抽取模板, 方法无需复杂计算, 效率高。要获得覆盖广且精准的抽取规则, 可辅助人工参与, 但如果需要更有效率的抽取表现, 则可尝试规则的自动提取。面向海量评论资源, 需要的是快而相对精准的抽取方法, 模板匹配策略具有更多灵活性。
可见, 模板质量是保障系统效能的关键。相关研究[11, 12]中, 重点探讨的是模板过滤和泛化处理, 缺少对识别匹配阶段筛选优化的思考。针对这一问题, 本文借助中文句法分析, 尝试通过依存句法提炼过滤规则模板, 同时在构建模板和候选标签匹配识别两个阶段引入优化过滤机制, 解决“特征-观点词” 的识别提取问题, 以期对特征标签获得更好的提炼效果。
(1) 句法模板定义
计算语言学中, 依存句法的基本假设是: 句法结构本质上包含词对间的关联, 这种关联称为依存关系。一个依存关系通常涉及两个词, 核心词(Head)和依存词(Dependent)。商品评论中, 消费者对产品的评价观点, 通过一组修饰词描述中心词形成, 精炼为“评价对象-评价词” 形式的特征标签。
对评论文本的词性标注与句法分析发现特征词和评价词的词性规律。例如, 评价特征通常是名词或动名词, 观点描述则形容词居多。评价特征和评价词语的关联主要存在以下三种依存关系:
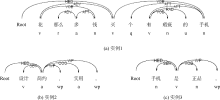
①特征词为依存关系中的核心词。如图1(a)所示, “手机” 和“瑕疵” 之间存在单向句法路径“n-ATT-v-VOB-n” , 核心词为“手机” , 这种关系定义为直接正向关系。
 | 图1 分析实例(句法分析截图) |
②评价词作为依存关系中的核心词。如图1(b)所示, “设计” 与“简约” 存在依存句法路径 “a-SBV-v” (SBV为主谓关系), 核心词为“简约” , 这种关系定义为直接反向关系。
③特征词和评价词均不是核心词, 但存在间接关系。如图1(c)所示, 句子存在特征标签“手机-正品” 。对于这对关系, 存在两条句法路径, “v-SBV-n” 和“v-VOB-n” 。特征词和评价词间有同一核心词为路径节点, 这种关系定义为间接关系。
由分析可知, 评价特征、评价词在评论中不仅存在着一定的词性规律, 而且两者间的修饰关系也表现出一定的规律。为描述评价特征与评价词间的这种关联, 本文的句法模板采用词性标注与依存句法标注标签组合的模式。
(2) 模板库构建
基于上述三种关系描述, 利用依存句法分析工具, 笔者从训练集中抽取句法模板。模板库构建分为三个步骤: 预处理、模板提取过滤与模板泛化。预处理涉及分句, 词性标注以及句法分析, 并在模板抽取过程中确认候选评价词和候选特征词。本研究中, 选取名词为候选特征词, 并利用词典匹配提取评价词和观点词。模板的提取与过滤指剔除噪音模板。若句中有m个评价词和n个特征词, 经过句法模板的抽取, 会生成m× n个句法模板。显然, m× n个模板中大部分是噪音, 问题演化成如何从m× n个候选模板中提取出有意义的抽取模板。对此, 笔者从训练集(900多条原始评论文本)中生成了27 000多个评论模板。观察模板的分布情况发现, 直接正向关系和直接反向关系模板所占比重较小(两类累计占27%), 但抽取出的大多都是合乎逻辑的正确修饰关系。间接关系类模板所占比重最大(73%), 但抽取出大量混乱和错误的关系对。原因是依存句法分析中, 任何两个词根据其语法路径寻找核心词, 最后总会终止于一个虚拟的根节点, 如图1(a)中的“Root” 节点。观察后还发现很多没有语义的关联通过第三类模板抽取获得。因此, 如需提高准确性, 应在“特征-观点词” 抽取阶段, 对模板匹配引入约束, 优化模板匹配模式。
尽管如此, 评论者发表评论采用的语法或者句法存在错误不可避免, 但是基于大规模的训练语料, 仍会普遍表现出正确的语法和句法规律。一些错误的句法模板, 由于失去语义, 或因本身的不规律性, 在大规模语料中出现的频率非常低。而正确的句法模板, 反映出语言的一般规律和搭配关系, 出现频率会普遍较高。基于上述考虑, 笔者对模板分布进行了统计, 并且设定模板过滤阈值Threshold, 选取阈值以上的高频模板构建模板库。
低频模板也可能是正确的, 因此通过模板泛化, 使得模板拥有更好的概括能力。文献[11-13]对模板泛化都有各自的处理方式。本研究特别针对特征词并列的模板形式泛化进行探讨。将“n-COO-n” 的模板(表示两个名词之间是并列关系)转换成“n” (名词), 以及把所有模板的特征词位置的词性都转换成名词形式“n” 。另外还采用一些通用泛化方法, 如将“a-COO-a” 泛化成“a” , “n-ATT-n” 泛化成“n” 等处理方式。
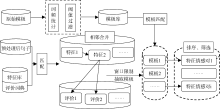
为方便描述, 设模板库为PatternSet = {P1, P2, …, Pi, …, Pn}, Pi代表模板库中第i个模板, n为模板库中模板的数量。评论句集合为SentenceSet = { S1, S2, …, Sj, …, Sm}, Sj代表评论集合中第j个评论句, m表示评论文本的数量。匹配的任务描述为: 对于任意一个评论句, 抽取出“WFjk-WSjl” 形式的特征标签。抽取过程如图2所示:
 | 图2 基于模板匹配策略的特征标签抽取流程 |
(1) 提取评论句Sj, 经过分词、词性标注、依存句法分析, 形成句法树。
(2) 对句法树上每一个词语, 均与产品领域特征库进行匹配, 形成候选特征集CandiFeatureSet ={WFj1, WFj2, …, WFjk}。若当前词语与特征库不匹配, 则把当前词语与评价词典进行匹配, 形成候选评价词集CandiSentimentSet = { WSj1, WSj2, …, WSjl}。
(3) 评价词与特征词之间有可能存在一对多的搭配关系, 例如“手机屏幕” , “手机” 和“屏幕” 都会单独作为候选特征词, 为了提高分析精度, 本文把候选特征集CandiFeatureSet两个相邻特征的合并作为词组进行抽取。
(4) 在句法树中, 按照三种模板类型, 针对候选特征词集和候选评价词集, 抽取出所有的句法模板。直接关联的两种模板采用直接抽取的方式, 不设限制。而对于间接关联的模板, 设置过滤窗口, 限制特征词和评价词间的距离。本文定义的窗口大小为句法模板的长度。若两评价词间的距离超过窗口大小, 则视为不存在搭配关系。
(5) 把抽取到的句子模板与模板库进行匹配,若匹配成功, 则把模板中蕴含的“WFjk-WSjl” (“特征-观点” )对添加至候选特征标签集。
(6) 评论文本中存在特征词与评价词多对多关系, 形成噪声。因此, 对于一个评价词生成的所有候选特征标签, 按频次排序, 取最高频次模板生成的特征标签作为最终提取结果。
本文从亚马逊①(① http://www.amazon.cn/.)抓取3 000条手机产品的原始评论文本作为语料。采用中国科学院计算技术研究所的ICTCLAS[15]进行分词和词性标注, 依存句法分析使用哈尔滨工业大学社会计算与信息检索研究中心研制的语言技术平台(LTP)[14]。情感词集采用中国台湾大学NTUSD简体中文情感极性词典②(② http://www.datatang.com/data/11837/.)、HowNet③(③ http://www.keenage.com/.)评价词、情感词三个词典。评测指标为同类实验[11, 12]中常用的评价指标— — 准确率, 召回率和F值。
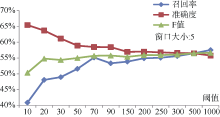
选取348个评论句, 手工分句, 并且标注特征标签。同时利用依存句法分析, 生成句法模板27 186个, 经频次统计, 共计9 645种不同模板, 长尾分布特征明显, 频次低于10的比例达97.1%, 如图3所示。
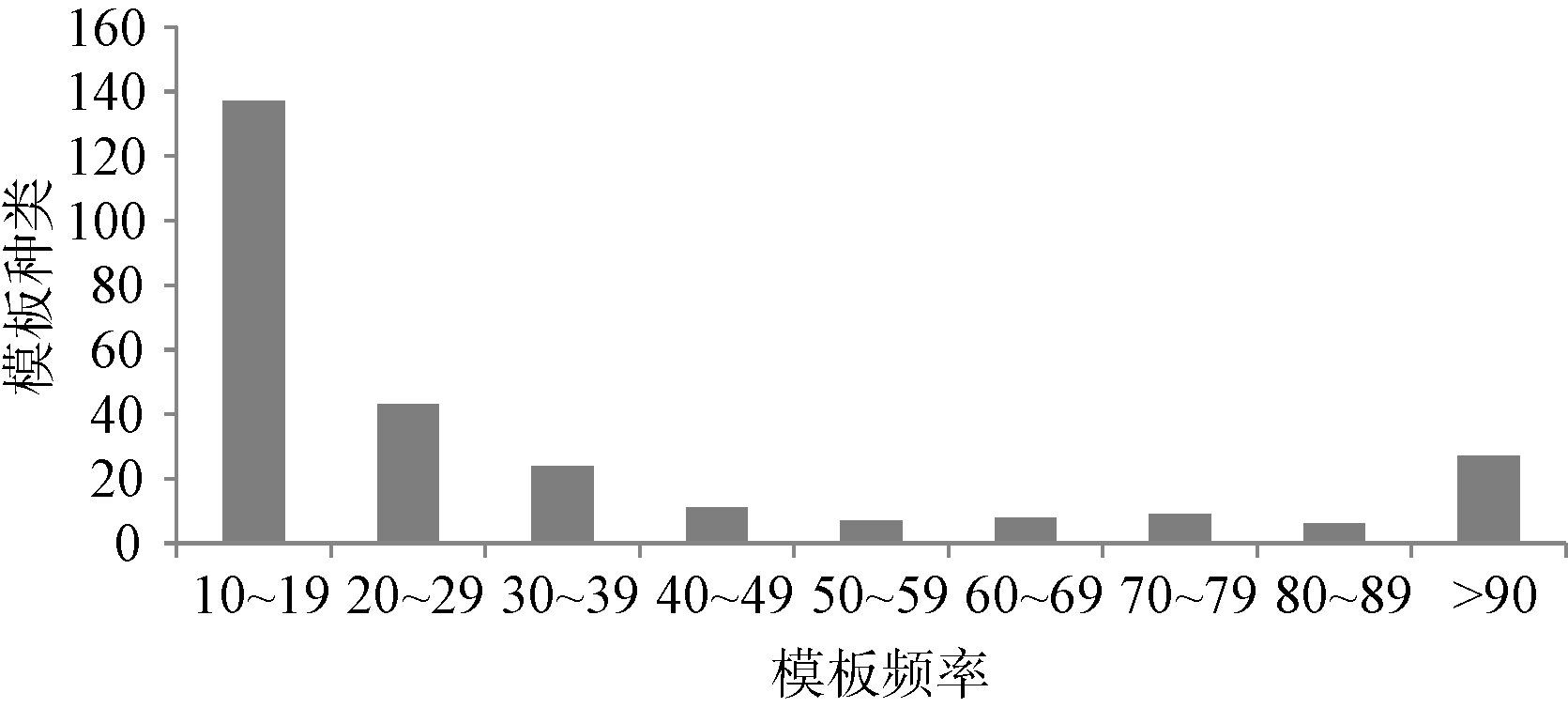 | 图3 模板频率分布 |
由图3观察到高频模板数量稳定在30个左右, 体现出一定的语言规律。低频模板类中也应包含较多的特征评价描述, 不可忽视。为此需选取适合的模板数量阈值。实验以手工标注的特征标签为测试标准, 评测不同阈值情况下抽取系统的性能。由图4可知, F值与模板数量的关系呈现正相关, 且阈值大于70后, F值基本稳定在56%左右, 说明系统对模板的容错能力较好。系统在阈值500时, 获得最优性能, 召回率和准确度都达到了56.5%左右。
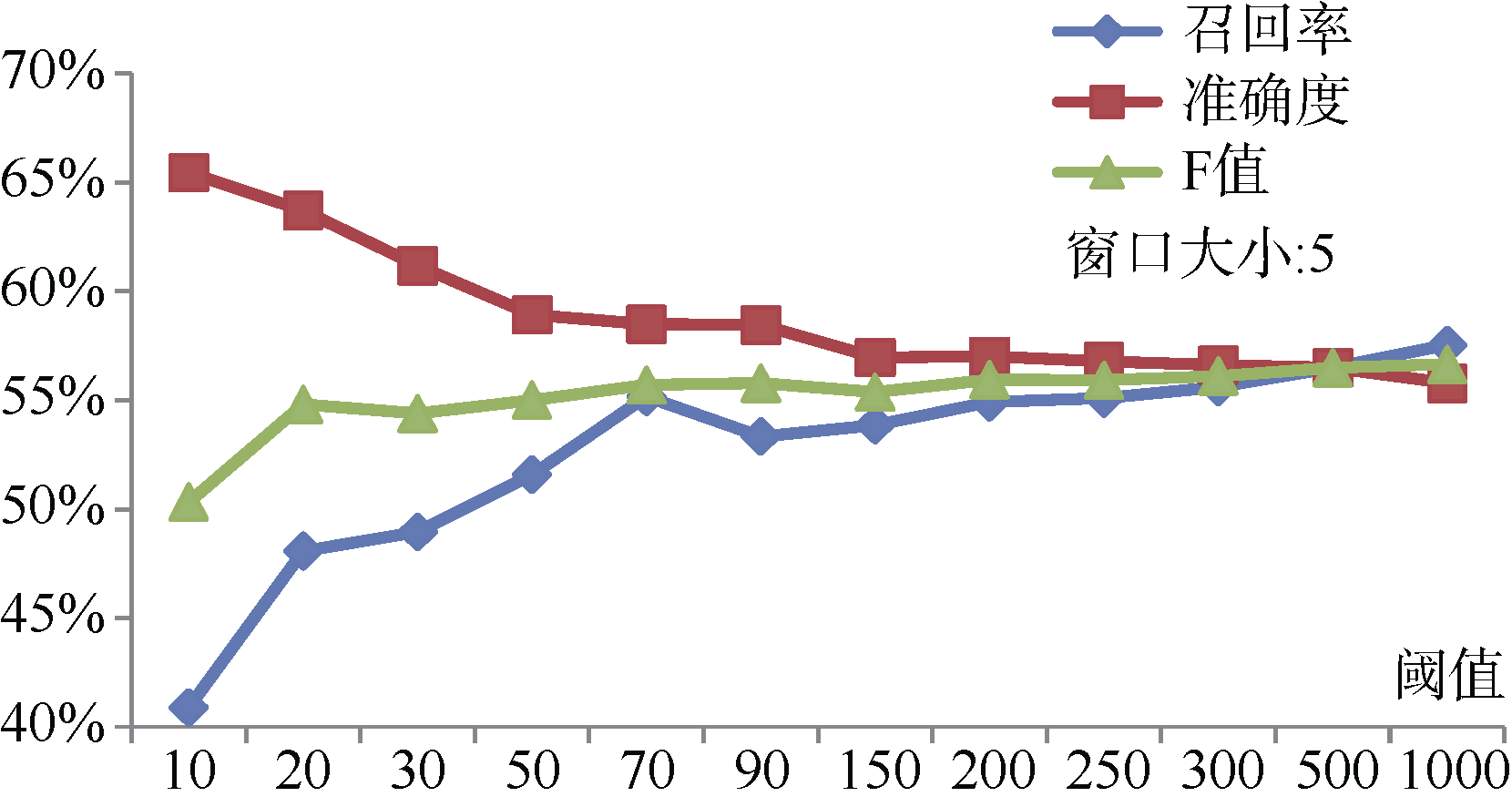 | 图4 本文方法实验结果分析 |
如3.1节所述, 本文对间接关系模板进行约束。取句法模板阈值70, 设置不同的限制窗口, 进行测试。发现当窗口设置为5时, 能够获得最好性能(F=55.79)。对比无窗口限制, 系统综合性指标提高了2.3%。原因是第三类模板中, 错误模板通常过长而不规则, 5是一个合适的窗口尺寸, 有效过滤了大量错误模板, 尽量确保抽取的正确率。
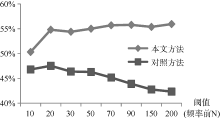
设置最佳约束窗口5, 按照3.2节的方法与流程进行特征标签抽取实验, 并以陈炯等[12]的评价搭配抽取方法进行对比, 结果如图5所示。可以看出, 对照实验的最优性能仅有47.53%, 而本文方法阈值为200时F值达到了56.49%, 总性能提高约9%。随着模板数量不断增多, 对照实验的性能不断下滑, 由于频率较低的模板不断添加到模板库中, 导致大量错误模板被引入到分析过程中。因此, 有较多的错误特征标签被抽取。本文方法测试结果基本保持稳定, 而且随着模板数量的增多, 性能有小幅提升。说明本文方法对错误模板过滤能力较好。
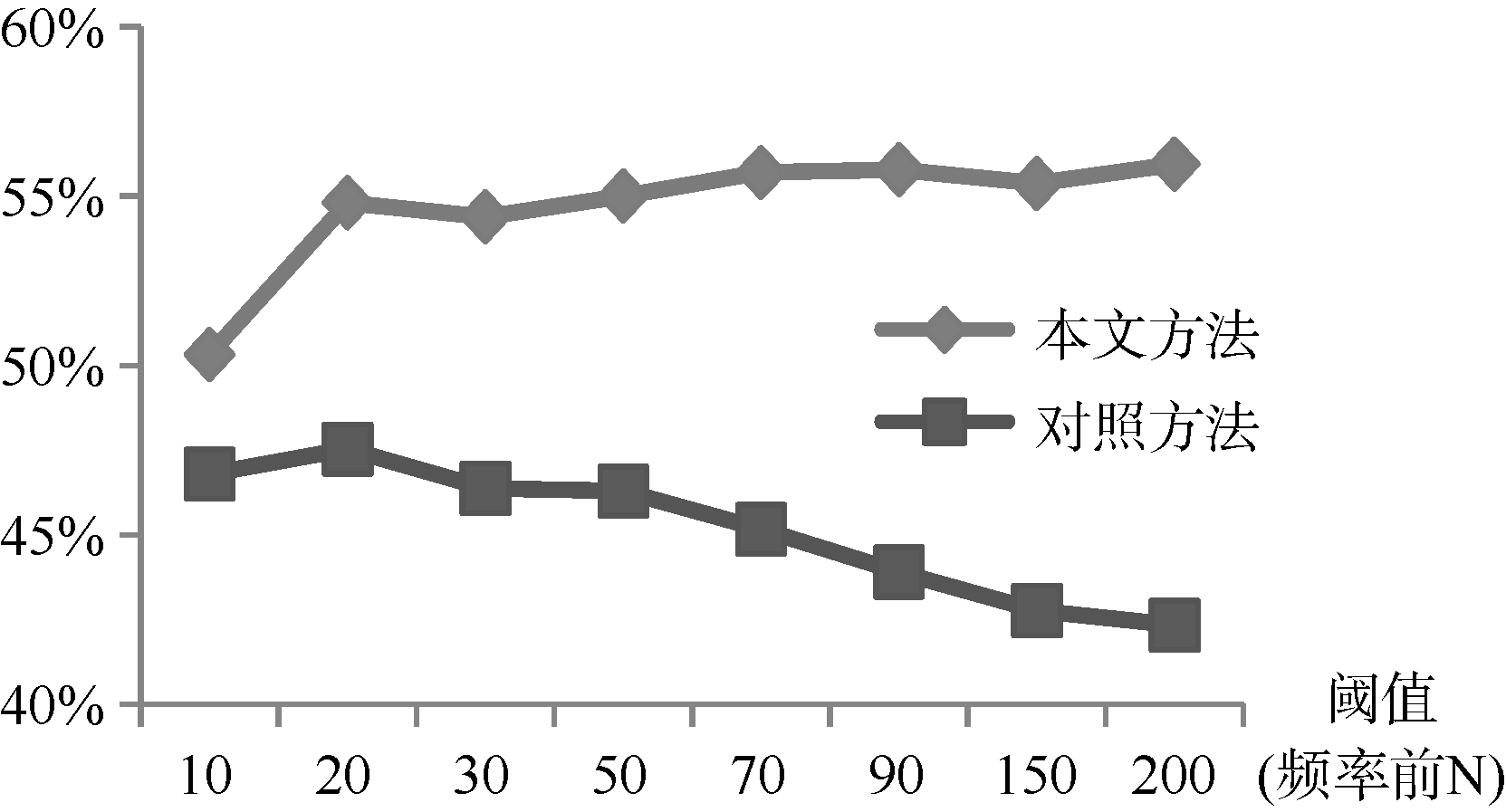 | 图5 实验对照结果 |
图6为系统运行结果实例。可以看出, 对于语义明确, 断句清晰的句子都会有较高的准确率。运行实例显示抽取结果为“屏幕-偏黄; 其他-可以; 系统-好用” 。“系统” 、“偏黄” 、“其他” 、“可以” 等词语通过特征词典和情感词典被辨识, 而利用依存句法分析归纳出的特征词(名词)与评价词(形容词)间的搭配评价关系则形成抽取模板, 与之匹配的特征标签实例被快速识别。而对于诸如“清晰度赛过电脑” 、“后盖无法打开” 等句子, 包含了比较、动词词组固定搭配等复杂句式, 出现频次少, 因未能通过依存句法分析归纳生成抽取模板, 则无法识别。可见, 自动抽取效果对基于自然语言分析技术的句法分析的性能表现依赖也较大。而某些句子由于包含了隐含语义, 会干扰正常的标签抽取, 系统的整体性能受到影响。
 | 图6 系统运行结果实例 |
本文提出一种自动识别并提取特征标签的方法, 引入依存语法关系对评论模板自动提取, 分类、过滤、泛化并形成模板库。在特征标签抽取过程中, 对间接关联型的模板进行窗口限制, 与忽略语义特征模板抽取、泛化、过滤的方法相比, 系统性能有了较大的提升。通过研究句法模板类型, 发现噪声通常出现在第三类间接抽取模板中, 提出在特征标签抽取过程中添加语义特征限制(窗口大小)的有效控制方法, 并且发现单纯“n-COO-n” → “n” 的泛化规则能取得较好的分析结果, 因而本文方法对于错误模板的容忍度较高。对中文领域, 提取性能可达到近60%。当然, 系统表现还会受到分词系统、句法分析结果等多种因素的影响, 系统性能稳定性仍有待进一步探测与分析。本文的算法通过评论模板的阈值过滤, 窗口大小过滤, 在一定程度上缓解了网络评论文本不规范的难题, 但其依然是影响本系统准确度的重要因素。
进一步的研究, 需要考虑评论句子的质量与过滤、特征词库的自动化获取以及在形成模板过程中, 添加更多的句法和语义特征, 提高特征标签的抽取准确度。特征标签抽取结果, 对于诸如评论深度自动总结等挖掘工作有非常重要的意义。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|