{kind=link}
{kind=link}
搜索日志中中文人名的自动识别
[曾镇 , 吕学强, 李卓]
, 吕学强, 李卓]
, 吕学强, 李卓]
|
|


作者贡献声明:
吕学强: 提出研究命题;
曾镇: 提出研究思路, 采集和标注数据, 完成实验, 起草、撰写论文;
吕学强, 李卓: 最终版本修订。
【目的】人名在搜索日志中大量存在, 搜索日志中人名识别研究有助于提高搜索引擎的检索效果。【方法】提出一种搜索日志中识别中文人名的方法, 首先分析日志中人名的内部组成结构以及外部上下文信息, 提取7个特征, 选用合适的特征模板, 应用条件随机场模型初步识别人名。然后针对CRFs未能识别的人名其所在查询串字间组合共现频次较低的规律, 设计贝叶斯条件概率计算公式筛选更多的人名。【结果】在搜狗日志中进行实验, 开放测试结果准确率达到95%, F值达到91%。【局限】需要人工标注一定规模的训练语料。【结论】实验结果表明, 该方法对于搜索日志中的人名识别是行之有效的。
[Objective] Many names exist in query logs, and the name recognition can improve the performance of the search engine.[Methods] This paper presents a method that identifies the names in query logs. Basing on the internal structure characters of the name and its context information, extract seven features, choose suitable feature template, and apply the conditional random field model to preliminary identify of the person’s name. According to the characteristics of the query string that CRFs cannot mark with the names, design Bayesian conditional probability formula to select more names.[Results] Experiments are done in Sogou Web query logs, the precision of name recognition reaches 95%, and the F-measure of the machine learning method is 91%.[Limitations] A certain amount of manual annotation training corpus is required.[Conclusions] The results validate the effectiveness of this name recognition method, and prove that this method has positive impact on name recognition.
近年来, 搜索引擎产生的大量搜索日志越来越受到人们关注, 搜索日志作为一类富含大众智慧的海量数据资源, 成为数据挖掘领域广泛关注的研究对象[1, 2]。社会的进步使得用户对自己或他人的关注度越来越高, 会借助搜索引擎进行检索, 因此搜索日志中存在着大量的人名。Downey等[3]的研究表明, 每天产生的搜索日志中, 有2%-4%为人名查询串。由于搜索日志中存在大量的人名, 对日志中人名识别的研究在垂直搜索、查询推荐以及Web检索等方面被广泛应用[4]。
前人研究人名识别通常基于1998年人民日报标注语料, 多是基于统计模型以及统计与规则相结合的方法[5, 6]。随着机器学习方法的兴起, 研究者将其应用在人名识别上[7]。与丰富的文本语料相比, 搜索日志略显单薄, 内容短、缺少上下文、结构不规范, 这些特点给日志中人名识别带来了挑战。目前在搜索日志中进行人名识别的研究相对较少[8, 9], Pasca[10]提出一种根据手动给定的种子实体确定其所在查询串的模板, 利用模板相似性算法抽取候选人名的方法。然而该方法只有当种子实体仅属于单个语义类别时才能取得较好的效果。曹雷等[11]提出了一个基于弱指导话题模型的命名实体框架, 通过引入弱指导生成的概率模型, 学习各个类别的查询模块分布, 改善了候选实体的排序效果。张磊等[12]将Pasca的框架移植到中文查询日志中, 借助关联规则对命名实体进行评分排序。上述方法对选取的种子要求较高, 种子性能的好坏将直接影响实验结果。Wen等[13]提出一种基于搜索会话的无监督中文人名识别方法, 通过模拟人与人之间建立联系的过程, 结合候选人名上下文提出了候选人名的筛选方法。该方法虽实现了种子人名的自动发现, 但仅立足于搜索会话范围, 不能实现整个搜索日志内的人名识别。
与前人研究方法不同, 本文将人名识别任务转化成CRFs序列标注任务。分析用户输入查询串中人名的分布特点、用字规律, 设计有效的颗粒特征和复合特征。引入人名知识库, 部分解决机器学习对缺少上下文信息的孤立人名查询串的弱识别难题。对未召回的含人名查询串进行统计, 发现其均存在查询串短(一般为2-3个字)、且多为低频或生僻的人名用字现象, 据此设计了条件概率筛选准则作为优化处理。
与文本领域的句子不同, 查询串自身包含的字面信息较少, 人名所能依赖的信息更少, 构成查询串的关键词顺序前后也比较随意, 并不遵循严格的语法规则, 如表1所示:
| 表1 搜索日志和长文本对比 |
通过表1对比发现, 人民日报语料中的人名有着丰富的上下文、紧密的逻辑关系。而搜狗搜索日志内容贫乏, 上下文信息易缺失, 缺乏严格的语法规范, 给搜索日志中人名识别带来了挑战。但搜索日志数量庞大, 涉及范围较广, 拥有其他语料无可比拟的召回效果。并且日志内容结构单一, 可以有效避免一些人名歧义现象, 例如表1中的第二组对比语料。
本文从人名用字、人名上下文信息、人名关注度以及伪人名4个方面对查询串进行详细的分析。
对搜索日志中的人名统计其姓氏和名字的词频, 发现姓氏用字集中在几个常见大姓, 如王、赵、李等。名字用字情况则较为复杂, 较常用的名字用字相对集中在几十个字上, 如英、明、志、国、月、杰、珍等, 其通常被赋予某种美好含义, 但人名用字涉及的范围较广, 一些生僻字、方言字、古字也有出现, 如蕤、肜、琮、巽、祚等。
由于用户输入查询串较短, 主要以主谓、定中结构为主。因此查询串上下文缺失比较严重, 如表2所示。
| 表2 人名上下文信息特点 |
由表2可得, 虽然查询串的语法结构混乱, 但其上下文结构比较单一, 同一模式下的人名边界词比较集中固定。如上边界词: 主持人、将军、演员; 下边界词: 资料、简历、照片等。本文将人名边界富含的信息特征融入机器学习模型。
关注度是汉语词汇中的一个热词, 意为关注的程度。搜索日志中的人名关注度即指该人名在当下被搜索引擎检索的热度, 反映在数值上则是其出现频次的高低。
关注度较高的人名, 在搜索日志中反复出现, 可利用其充足的信息量通过信息扩散来辅助识别信息量不足的人名。关注度较低的人名由于频次低, 鲜有上下文信息, 且多含生僻字等特点使其成为人名识别中的难点。
伪人名指字面意义上虽近似人名, 但在整个查询串语境中并不符合语义的假人名。日志涉及内容广泛, 不免会有伪人名存在。如实体间的混淆, “陈家坝大桥” , 地名“陈家坝” 近似人名。“名词+名词” 、“动词+名词” 这类词间组合易形成伪人名, 如“方正卓越K100-5460最新价格” 易出现“方正卓” 。此外用户输入不当也会导致伪人名, 如“刘的翔” 。
条件随机场是一种十分成熟的统计学习模型, 本文尝试将其引入查询串中人名的初次识别。使用人名领域相关的知识定义特征函数来提取序列之间的关联特征。采用前向算法评估出给定观察序列条件下各状态序列的概率, 据此识别人名。CRFs对训练数据格式有严格的要求, 每一行又称为一个token, 由多列组成。token的基本单位可以是字或词, 本文采用基于字的序列标注方法, 对人名用4词位标记法, 即B、M、E、S这4个标记分别表示人名首部用字、人名中部用字、人名尾部用字、人名外部用字。测试语料中标记为BME和BE的连续字则为人名。
特征选择是机器学习方法中的关键部分, 人名识别可以利用的特征很多, 包括字符、拼音、词性、边界、引导信息、频次统计等。它们的组合方式更是呈指数级增长, 因此选取合适的特征及其组合对于提高系统性能、节省训练时间非常重要。本文选用两大类特征: 原子特征和复合特征。考虑人名的长度, 选取大小为3的窗口, 即(W-1, W0, W1)。
由于下面每个特征只考虑一种因素, 故称之为原子特征。
(1) 姓氏可信度特征: 姓氏是人名结构中最重要的因素, 除少数笔名或仅有名字的称呼外, 所有姓名都含有姓氏用字, 所以姓氏用字常作为模型识别的首要触发条件。为了表示姓氏用字成为姓名首字的可能性大小, 结合停用词列表和名字列表以及文献[14]提出三级强度的姓氏可信度。详细划分方法如表3所示:
| 表3 姓氏可信度强弱划分和特征取值 |
(2) 边界词特征: 人名构成具有随意性, 在查询串中仅靠对姓氏用字的分析很难取得好的识别效果。查询串中同一个话题模型比较集中固定的边界词能指示人名出现的可能位置。一些低频边界词并不对所有查询串都有人名引导作用, 如查询串“朱德元帅” 中, “元帅” 在“中国十大元帅” 中则不再充当边界词。所以边界词的特征区分度在某一程度上取决于该词频次的高低。边界词筛选依据公式(1)。
fmax分别表示最小、最大词频,
(3) 人名区分词特征: 对2.4节伪人名分析, 如果词语尾字为姓氏, 此词语与后续词语很容易被误识别为人名, 如“基金鸿飞” 中“金鸿飞” 常被误识为人名。考虑到查询串较短, 其包含的词汇有限, 基于此前提, 剔除训练集中标注的搜索日志人名, 对剩余片段分词, 过滤长度为1和含有英文字母的字符, 保留余下的词语集合, 作为人名区分词表。
(4) 人名知识库: 关注度较高的人名往往在查询串中重复率很高, 对训练语料库所包含的已有实体信息建立人名知识库, 查看候选目标是否存在知识库中并给出相应的特征标记。
使用区分词和知识库等词特征时, 对每个标注的查询串使用后向最大匹配算法为组成词的相邻字加上对应的字符特征标记。
单独的原子特征还不足以表示查询串中上下文出现的各种现象, 通过对原子特征的组合来表示字与字之间更为复杂的联系, 组合后的特征称为复合特征, 实验用到的复合特征及其模板如下:
(1) 姓氏用字和名字用字的复合特征: 姓氏用字用
(2) 前后区分词复合特征: 用
(3) 语义约束复合特征: 一些头衔、职位、称呼等词往往暗示着人名的出现, 这里称之为语义词, 用
根据原子特征和复合特征就能构造特征模板, 特征模板的作用是为特征函数的生成提供一个统一的模式, 通过特征模板可以方便地获取所有的特征函数。一套合理的特征模板可以大大提高人名识别的效率。本实验的特征模板如表4所示。
| 表4 模板特征集 |
由于语料规模限制, 条件随机场在学习过程中很难学习到搜索日志的全部特点, 这直接导致条件随机场漏识了部分信息量少的人名, 如表5所示:
| 表5 部分未召回人名所在查询串 |
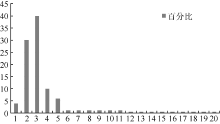
观察上述查询串长度分布特点, 统计其查询串长度所占比例大小, 如图1所示:
 | 图1 未被召回查询串长度分布 |
从图1可以看出, 未被识别的人名所在的查询串, 长度为2-3的查询串占到70%, 大大损失了召回率, 由于不存在上下文, 且只单独出现一到两次, 缺少特征信息, 机器学习方法很难将其辨认。进一步研究这些人名多为少见人名, 即其字之间的组合比较少见, 且其在整个语料中出现频率低。为此定义基于贝叶斯的人名条件概率如下:
其中, P(wordi)表示用字wordi的出现概率, P(wordi+1|wordi)表示在字wordi的前提下出现字wordi+1的概率, P(Name) 为查询串的条件概率值。n=1时人名长度为2, n=2时表示人名长度为3。
表5中名字较为生僻, 名字之间字的组合很少连续, 导致姓与名和名与名之间的条件概率值小于语料中词的条件概率值, 选择1998年1月的人民日报作为基准语料, 计算每个字的概率和以该字为基准的条件概率, 得到一个概率参数表。利用概率参数表计算人名条件概率值, 对长度为2和3的查询串分别设定阈值TVO2 (Threshold Value of 2 Words)和TVO3 (Threshold Value of 3 Words), 按照阈值筛选候选人名, 在保证准确率的前提下, 提高人名召回率。具体步骤如下:
(1) 对未标记人名的查询串计算长度, 保留长度为2和3的查询串;
(2) 如果查询串的首字被姓氏表包含, 且第二个字或第二、三个字均被姓氏名字表包含, 则将该查询串定义为候选人名查询串, 从而得到候选人名查询串集合;
(3) 分别对候选人名查询串按公式(2)计算其人名条件概率, 与给定的阈值比较, 去除概率值大于阈值的候选人名查询串, 其余的认定为人名。对条件概率值为0的人名用字进行均值数据平滑, 避免结果出现零值。
(1) 实验数据1
搜狗实验室官方网站提供的2008年6月、7月的查询日志, 选取6月无重复且包含百家姓姓氏的4万条查询串, 手工标注人名, 前3万条作为训练数据, 后5 666条作为测试数据。5 666条测试查询串里面, 含人名1 123个。
(2) 实验数据2
百度公司2010年开放的108 520 856条日志记录, 选取无重复且包含百家姓姓氏的4 000条查询串作为数据1的对比实验数据。
条件概率筛选阈值, TVO2取5× 10-5, TVO3取 5× 10-7, 阈值TVO2、TVO3选择依据是1998年1月的人民日报语料中分词长度为2和3的所有词语的均值条件概率值。
(3) 评测指标
对系统的识别结果选用准确率(Precision)、召回率(Recall)、F值(F-measure)三个指标进行评测。
(1) 多特征对比实验
为了验证选取特征的有效性, 实验依次加入了3.1节中提到的特征集, 使用条件随机场工具包CRF++0.5进行多组对比实验, 边界词特征中的比例因子
| 表6 多特征对比实验结果 |
结果表明, 添加姓氏可信度特征准确率虽有所下降, 但召回的人名数明显增多, F值也提高了1%, 表明姓氏可信度特征对召回率提高有重要作用。姓氏特征和名字特征组合为复合特征时, 效果更好, 准确率、召回率都有提升。边界词特征对系统效果有一定的提升, 充分说明边界词特征对人名有一定的指示作用。区分词复合特征对系统性能有小幅提升, “陈云子女” , “游戏王巴龙” 等查询串中的伪人名“陈云子” 、“王巴龙” 均被正确标记。部分地名如“陈家坝大桥” 始终被识别为人名“陈家坝” , 一些少见姓氏且没有上下文的查询串也很难被识别, 如“姬鹏飞” 。语义词特征与前面的特征存在冲突, 对系统性能贡献度甚小。
对查询串进行人名条件概率计算, 筛选未被识别的人名, 系统结果在略微损失准确率的情况下, 提升了召回率。实验结果如表7所示:
| 表7 人名条件概念实验结果前后对比 |
实验结果发现人名条件概率计算能正确召回“姬鹏飞” 、“查士标” 、“战卫华” 等机器学习漏识的名字查询串, 还可排除“江苏” 、“韩国” 、“金瓶梅” 等噪音信息。结果表明该方法对生僻人名或少见人名有很好的识别效果。
(2) 与Baseline对比实验
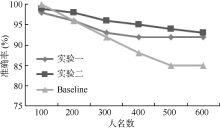
由于对查询日志中单单针对人名识别的相关研究并不多, 故选取文献[11]中实体类别中名字类实验结果作为对比实验。对比实验中没有考虑召回率因素, 对此统一以准确率为评价标准。为了验证训练语料规模的大小对测试结果的影响, 对训练集增加1万条查询日志, 分别做训练语料为3万条和4万条的实验1和实验2, 测试集不变, 为上述5 666条查询日志。实验结果如图2所示:
 | 图2 不同规模训练集对比实验 |
从图2可以看出, 本文方法训练语料越大, 准确率略微下降, 这是召回率大幅度增长所带来的一定损失。与Baseline相比, 本文方法在查询日志规模较大的情况下优势明显。日志规模的扩大带来的是更复杂的语言环境, 对比实验中结合特征的规则筛选方法在新的语言环境下很难达到满意的效果。
(3) 不同测试集对比实验
为了验证该方法在其他语料中的效果, 选取搜狗日志2008年7月的4 000条查询日志与百度公司2010年开放查询日志中的4 000条查询日志做对比实验, 结果如表8所示:
| 表8 不同测试语料结果对比 |
由实验结果可知, 尽管训练语料搜狗2008年7月查询日志和百度2010年搜索日志语境有较大差别, 但在人名知识库和前面4个有效特征的辅助下, 系统性能还是有一定的保证。本实验词表词汇量有限, 如果扩大实验的人名知识库和边界词表将可进一步提升效果。
本文分析了人名在搜狗查询日志的分布特点和上下文特征, 选用有效的特征集和特征模板构建机器学习模型识别查询日志里面的人名, 针对学习模型未标注出人名的查询串的数据特点, 提出一种依据条件概率计算值排名的筛选方法。实验结果表明, 该方法取得了较好的效果。
在商业应用方面, 在查询日志中快速识别人名对用户行为分析、用户跟踪定位等有重大的应用价值。本实验中的CRFs特征选取还可以进一步深究, 以获得更好的效果。机器学习中训练语料均为手工标注, 如何最大限度减少人力成本, 实现语料的半自动标引是未来的研究方向。本实验的召回率与基于规则和统计的方法相比仍偏低, 这是由于许多查询串长度很短, 缺少训练的上下文。总之, 查询日志中的人名识别是一个重要且有待发展的研究方向, 还有很多后续工作可以展开。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|