

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
LDA模型下书目信息分类系统的研究与实现
[李湘东1 , 廖香鹏1 , 黄莉2  ]
]
]
|
|


作者贡献声明:
李湘东: 负责提出研究思路, 设计研究方案;
黄莉: 采集和分析实验所需真实数据;
廖香鹏: 进行实验; 论文起草、初稿撰写;
李湘东, 黄莉: 论文审阅和最终版本修订。
【目的】改善图书和期刊论文等的书目信息的分类性能。【应用背景】采用传统向量空间模型对图书和期刊论文等书目信息分类的效果不理想, 通过LDA模型挖掘文本隐含语义信息, 能有效提高分类效果。【方法】通过LDA建模, 用隐含主题表示文本并通过分类效果确定最优主题数, 在此基础上采用SVM算法分类。【结果】实验表明, 在复旦和Sogou公开语料库中的Macro_F1分别达到95.5%和93.5%; 在馆藏目录及电子期刊数据库等真实书目数据中的Macro_F1分别达到77.4%和87.6%。【结论】在真实数据上的分类性能比传统向量空间模型分别提高10%和3%, 达到实用水平。
[Objective] To improve the classification effect of bibliographic information of books and journal articles etc.[Context] The classification performance under the traditional vector space model is not satisfied, and LDA model can effectively improve the classification effect by mining the implied semantic information.[Methods] Using LDA model to represent each text with implied topics, the optimal number of topics is determined on the classification result.Then the SVM classification algorithm is used.[Results] Experiments show that the Macro_F1 in Fudan and Sogou corpus reach 95.5% and 93.5% respectively; the Macro_F1 on the real data from catalogue and electronic journal database reach 77.4% and 87.6% respectively.[Conclusions] The classification performance on real data is increased by 10% and 3% respectively compared to the VSM, that reaches the practical level.
文本自动分类是信息检索和数据挖掘领域的研究热点和核心技术, 近年来得到了广泛的研究和高速的发展, 目前关于文本分类的研究主要集中在文本表示和分类方法上。对于分类方法, 主要将各种机器学习方法应用于文本分类, 主要有KNN(K-Nearest Neighbor)、朴素贝叶斯和支持向量机(Support Vector Machine, SVM)等; 对于文本表示, 大多基于传统的向量空间模型(Vector Space Model, VSM), 即以特征词作为特征项, 向量空间模型将文本集表示为一个高维的稀疏矩阵, 计算量大, 对分类的时间复杂度和空间复杂度有很大的影响。另外, 由于向量空间模型将所有特征词看成相互独立的, 因此无法解决一义多词问题。
Deerwester等[ 1]在1988年提出潜在语义分析(Latent Semantic Analysis, LSA)模型, 通过奇异值分解, 将文本从高维的特征词空间映射到低维的主题空间, 一定程度上解决了一义多词问题, 但奇异值分解计算量巨大; Hofmann[ 2]在1999年提出概率潜在语义分析(Probability Latent Semantic Analysis, PLSA)模型, 通过概率的方法获得文本的潜在语义, 但PLSA的参数个数随着文本数的增加而线性增长, 且易出现过度拟合问题; Blei等[ 3]在2003年提出潜在狄利克雷分布(Latent Dirichlet Allocation, LDA)模型, LDA假设文本-主题矩阵服从对称的Dirichlet分布, 使得待估计的模型参数数量不会随着文本集的增加而增多。
LDA模型提出后, 以其可发现隐含主题等优势, 被广泛用于文本分类领域, 并在实际问题中得到了大量应用, 取得了较好的效果。其中, 刁宇峰等[ 4]利用LDA模型识别博客中的垃圾评论; 黄小亮等[ 5]使用LDA模型在主题空间上对软件缺陷进行分派; 廖晓锋等[ 6]通过LDA主题模型构建自动漏洞分类器, 实现信息安全漏洞的自动分类; 孙李斌等[ 7]将LDA主题模型应用于遥感图像的表示和分类中; 张志飞等[ 8]在基于向量空间模型的基础上, 利用LDA模型更改部分特征词权重。
本文以信息管理领域的主要真实数据──图书的书目信息和电子期刊数据库的期刊论文书目信息为对象自建语料库, 通过分析其与复旦、Sogou等公开语料库文本的异同, 在采用LDA模型作为文本表示、进行Gibbs抽样时, 没有采用LDA模型中通常使用的困惑度方法确定主题数, 而是通过不同主题数下的分类效果来确定最优主题数; 将文本集表示为固定数量的隐含主题上的概率分布, 将隐含主题的概率作为分类的输入特征, 以隐含主题作为特征项, 既避免了使用传统向量空间模型表示文本时的高维稀疏等问题, 同时通过将文本(特别是篇名等短文本)中相同或相似含义的特征词分配到同一主题, 有效解决了同义词问题, 从而增强了文本特征项的表述能力。通过实验验证了本文提出的方法在复旦、Sogou等公开语料库中分类的高效性之后, 进一步验证了本方法在自建的图书和学术期刊论文等书目信息语料库中也有较好的分类效果。
LDA是Blei等[ 3]在2003年提出的一种对离散数据集建模的统计主题模型, 将文本表示成一个由文本、主题和特征词组成的三层概率模型。LDA模型假设文本集中每篇文本为隐含主题集上的随机混合, 按照一定概率共享隐含主题集; 而隐含主题则是特征词上的多项式分布, 每个主题由一系列相关特征词组成。LDA模型如图1所示:
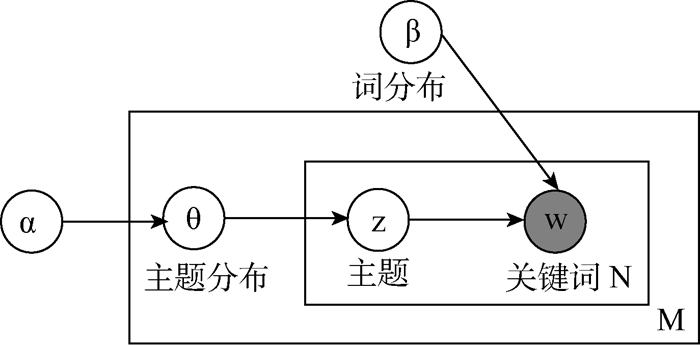 | 图1 LDA模型[ 3] |
其中,θ和z表示隐含变量,w是唯一性特征词, 表示可观察值; 对于给定的文本集D,D是M个文本的集合, 表示为D={d1,d2,...dM},V是文本集中的特征词种类数。设有T个主题, 则文本d中第i个特征词的概率表示为[ 3]:
 | (1) |
其中,zi是潜在变量,zi=j表示特征词wi取自主题j,P(wi|zi=j)表示wi属于主题j的概率,P(zi=j)表示主题j属于文本d的概率。令 

 | (2) |
LDA模型在 
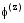
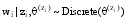
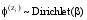

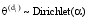
其中,α,β是Dirichlet分布的超参数,α可理解为获得文本集中文本以前,主题被抽样的次数;β可理解为见到文本集中的特征词以前,从主题抽样获得的特征词频数。由于不同主题和不同特征词被利用的方式基本相同,因此可以假定对称的Dirichlet分布,即所有的α,β取相同的值。
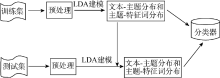
基于LDA模型的文本分类方法利用LDA模型挖掘文本中的隐含主题信息, 通过对文本集建模, 将每个训练集和测试集文本表示为隐含主题空间中的向量, 在训练集文本-主题矩阵中训练SVM, 构造文本分类系统。整个分类框架如图2所示, 主要包括预处理、LDA建模、分类器构造、分类过程和性能评估5个部分。
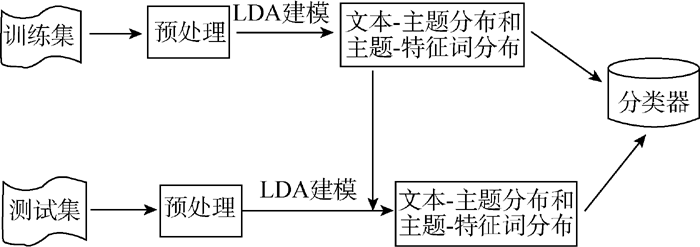 | 图2 基于LDA模型的文本分类框架 |
具体分类步骤如下:
(1) 预处理: 分词、去停用词。
(2) 对不同主题数, 采用LDA对训练集数据进行分析建模, 参数推理采用Gibbs抽样, 迭代足够多次数, 获得训练文本的文本-主题矩阵和主题-特征词矩阵。
(3) 在步骤(2)获得的文本-主题矩阵上训练支持向量机, 构造文本分类器。
(4) 用LDA建模后的训练集数据对测试集数据进行模型推断, 得到测试集数据的文本-主题矩阵, 获取测试集数据的文档特征。
(5) 用SVM分类模型预测待分类文本的类别。
对于一个新的待分类文本d, 同样采用Gibbs抽样的方法来获得其在主题上的分布, 此时因为训练集中的特征词主题分布已经稳定, 因此只需迭代较少次数(如100次), 但是在Gibbs抽样中计算条件概率以更新特征词所属主题状态时, 要同时考虑训练集和待分类文本, 其公式为[ 9]:
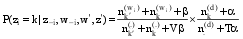 | (3) |
其中,w'和z'分别表示训练集中的特征词及其主题, 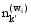
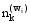
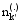
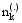
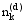
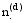
最后, 利用如下公式[ 9]计算待分类文本d在主题空间上的表示:
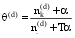 | (4) |
构建LDA模型的关键是隐含变量分布的推断, 即获得目标文本的隐含主题分布θ和主题–特征词分布Φ, 若给定模型参数α,β文本d的随机变量θ、z和w的联合分布为[ 3]:
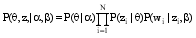 | (5) |
由于公式(5)中同时存在多个隐含变量, 直接计算θ和Φ是不可能的, 因此需要对参数进行估计推断, 常见的参数估计算法有变分贝叶斯推理[ 3]、期望最大化(Expectation Maximization, EM)[ 10]和Gibbs抽样[ 11]。本文采用Gibbs抽样进行参数推断, Griffiths[ 12]指出Gibbs抽样在困惑度(Perplexity)与运行速度等方面均优于变分贝叶斯推理和EM算法。变分贝叶斯推理算法得到的模型与真实情况有所偏差, 而EM算法往往由于似然函数的局部最大化问题导致无法找到最优解, Gibbs抽样能快速有效地从大规模数据集中提取主题信息, 成为当前最流行的LDA模型提取算法。
MCMC是一套从复杂的概率分布中抽取样本值的近似迭代方法, Gibbs抽样作为MCMC的一种简单实现形式, 目的是构造收敛于目标概率分布的Markov链, 并从链中抽取被认为接近该目标概率分布值的样本。在LDA模型中, 只需要对主题变量zi进行抽样, 其后验概率为 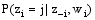
 | (6) |
其中,wi是特征词记号,不仅与特征词本身有关,还与该特征词所在的位置有关,zi=j表示将特征词记号wi分配给主题j,z-i是所有 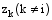

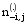
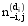
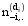
Gibbs抽样算法具体为:
①为每个特征词记号wi随机分配主题。zi是特征词记号的主题, 将zi初始化为1到T之间的一个随机整数,i从1到N,N是文本集中的特征词记号, 此为Markov链的初始状态;
②i从1循环到N, 根据公式(3)为特征词记号wi新分配主题, 获得Markov链的下一状态;
③迭代步骤②足够次数后, 认为Markov链接近目标概率分布, 取zi(i从1循环到N)的当前值作为样本记录下来。
对于每一个样本, 按下列公式估算Φ和θ的值[ 3]:
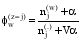 | (7) |

其中, 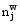
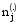
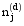
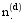
采用LDA模型对文本集进行主题建模时, 主题数T对LDA模型拟合文本集的性能影响很大, 因此需预先设定主题数。确定主题数的方法有多种, 姚全珠等[ 13]采用贝叶斯统计中的标准方法确定主题数, 曹娟等[ 14]通过计算主题之间的平均相似度来确定最优模型, 孙世杰等[ 15]使用困惑度获得最优主题数。其中, 困惑度是衡量一个模型好与坏的评价指标, 困惑度越小, 代表该模型的泛化能力越强, 该方法是语言模型中标准的评判准则, 在LDA模型中被广泛使用。本文通过不同主题数下的分类效果来确定最优主题数, 并与使用困惑度确定模型最佳拟合时的分类效果进行比较, 本方法一方面能获得更直观准确的最优主题数, 另一方面可以找出困惑度确定的最优主题数对应的分类效果与实际结果的差距。困惑度公式为[ 15]:
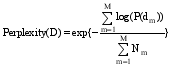 | (8) |
其中,M为文本集中的文本数,Nm为第m篇文本的长度, 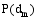
 | (9) |
为验证本文方法应用于图书和期刊论文等书目信息时的可靠性和有效性, 首先对复旦和Sogou公开语料库进行实验。其中, 复旦大学语料库共有军事、体育、旅游、计算机和经济5个类别; Sogou语料库共有计算机、教育、军事、体育和经济5个类别。
在探讨基于LDA模型的文本自动分类对图书和期刊论文等书目信息的适用性时, 以图书的书目信息和电子期刊数据库的期刊论文书目信息等信息管理领域的真实数据为对象自建语料库。图书语料取自某大学图书馆馆藏目录, 包括计算机技术、军事和体育三个大类下部分图书的书目信息; 期刊语料库包括计算机技术、体育和军事三个类别, 分别选自《计算机学报》、《体育科学》和《军事历史研究》三个期刊上2007-2009年的部分数据。两种自建语料库中, 测试集包括题名和摘要, 测试集只包含题名。
本文两种自建语料与复旦、Sogou公开语料有很大差别。首先, 复旦、Sogou语料属于长文本, 其中复旦语料测试集文本平均长度为2 772个字, Sogou语料测试集文本平均长度为685个字; 图书和期刊语料属于短文本, 其中图书语料测试集文本平均长度为7个字左右, 期刊语料测试集文本平均长度约为20个字。其次, 图书和期刊语料因为其本身学术性, 特征词有较强主题指示性, 因此, 即使文本长度较短, 如果能够正确识别出各个主题词的隐含语义, 也能获得较好的分类效果。
为消除不平衡数据对分类结果的影响, 本文所有实验均使用平衡数据, 每个类随机抽取200篇作为训练集, 100篇作为测试集, 训练集和测试集之间无重复。所有语料库分别进行5组实验, 最后取平均值作为实验结果。
性能评估是在整个文本分类完成后, 用各种指标来评价分类器的性能, 本文在常用的查准率P、查全率R和F1值三种指标基础上使用Macro_P、Macro_R和Macro_F1对分类结果进行评估。计算公式如下[ 12]:
 | (10) |
 | (11) |
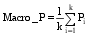 | (12) |
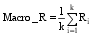 | (13) |
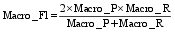 | (14) |
其中,Ti,Ci,Ni分别表示第i类中分类正确的文本个数、分到第i类中的文本个数和第i类中实际包含的文本个数,k是类别数。
为了评估LDA模型的有效性和优越性, 本文进行了如下两个实验:
(1) 通过不同主题数下的分类效果, 确定最优主题数及相应的最佳分类效果, 并与用困惑度确定最优主题数时的分类效果进行比较;
(2) 对本文使用的4种语料, 分别使用LDA模型和向量空间模型作为文本表示, 分类算法采用SVM, 比较分类效果。
语料库使用中国科学院计算技术研究所的分词系统ICTCLAS进行分词, 并去除停用词。
(1) 实验一
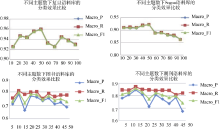
使用Gibbs抽样获取LDA模型参数时, 令α=50/T(T为主题数),β=0.01, Gibbs抽样算法训练集迭代1 000次, 测试集迭代100次, 公开语料库将LDA模型主题数设置为10-100(间隔10), 自建语料库主题数设置为5-50(间隔5), 在不同主题数下分别运行Gibbs算法, 采用SVM对待分类文本, 4种语料库在不同主题数下的分类效果与困惑度如图3和图4所示:
 | 图3 不同主题数下4种语料的分类效果比较 |
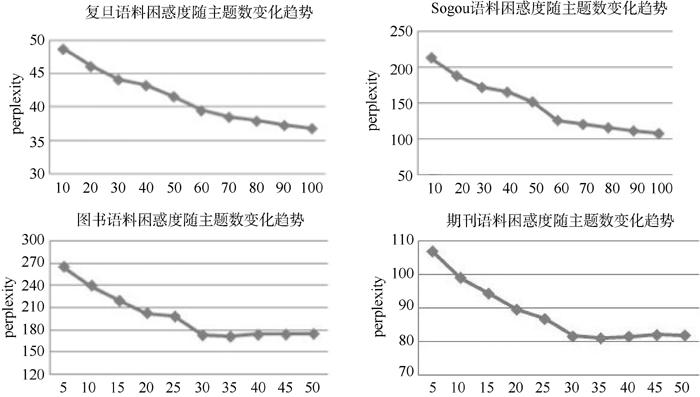 | 图4 4种语料随不同主题数的变化趋势 |
实验表明, 基于LDA模型的文本自动分类系统, 在Sogou、复旦公开语料库中的分类效果最佳分别达到95.5%和93.5%, 达到了同类系统的相同水平甚至略有提高[ 11]; 在图书、学术期刊论文等主要真实数据语料上也有较好的分类效果。
通过比较可以发现, 公开语料库中, 复旦和Sogou语料库分类效果最好时的主题数均为50, 而使用困惑度获得的最优主题数均为100; 自建语料库中, 图书和期刊语料库分类效果最好时的主题数分别为10和15, 而使用困惑度获得的最优主题数则分别为35和30。从分类效果来看, 通过困惑度确定的最优主题数对应的分类效果与真实结果相差甚远, 对复旦语料来说, T=100时的Macro_F1为93%, T=50时的Macro_F1为96%, 相差3%; 对Sogou语料来说, T=100时的Macro_F1为86.4%, T=50时的Macro_F1为92.2%, 相差5.8%; 对图书语料来说, T=10时的Macro_F1为79.6%, T=35时的Macro_F1为76.1%, 相差3.5%; 对期刊语料来说, T=15时的Macro_F1为85.8%, T=30时的Macro_F1为82.1%, 相差3.7%。
综上可知, 通过困惑度确定的最优主题数, 其分类效果并不是最好的, 与困惑度相比, 本文确定最优主题数的方法分类效果更好, 且更直观准确。
(2) 实验二
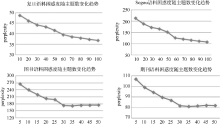
为了消除实验结果的偶然性, 对每种语料库进行了5组实验, 每组实验中每个类别从语料库中随机无重复抽取200篇用作训练集, 100篇用作测试集, 确保训练集和测试集无相同文本。文本表示选择向量空间模型(VSM), 结合SVM分类方法的分类系统作对比实验, 实验结果如图5所示:
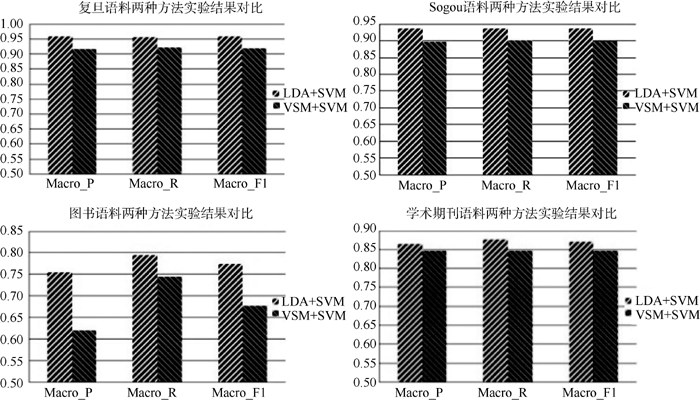 | 图5 4种语料在两种文本表示方法下的实验结果对比 |
实验结果表明, 在复旦和Sogou公开语料库上的分类性能比传统向量空间模型分别提高4%和3.5%左右, 分别达到95.5%和93.5%, 验证了本系统达到的水平及可靠性。在此基础上, 进一步通过实证, 研究了本系统在图书、学术期刊论文等信息管理领域的主要真实数据语料上进行自动分类的可行性, 分类性能比传统向量空间模型分别提高10%和3%左右, 分别是77.4%和87.6%, 达到可以实用的水平。
本文引入LDA模型作为文本表示方法, 将每个文本表示为固定隐含主题集上的概率分布, 分类算法选择支持向量机(SVM), 避免了传统向量空间模型作为文本表示时的高维稀疏特征空间问题, 同时, 通过将近义词分配到同一主题, 有效解决了一义多词问题。基于LDA模型结合SVM分类算法的文本分类系统在复旦和Sogou公共语料库上有良好的表现, 在自建图书和学术期刊语料库上也有较高的分类效果。另外, 本文采用不同主题数下的分类效果来确定最优主题数, 与常用的困惑度方法相比, 分类效果更好且更直观准确。尽管LDA模型降维效果明显, 但其建模速度慢、强制分配主题等缺点也是亟待解决的问题, 本文下一步工作将对LDA相关算法进行改进和优化, 并将其用于短文本分类, 以提高短文本分类效果。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|