面向知识组织系统整合的英文同义关系自动发现算法研究*
[李晓瑛, 李丹亚 , 钱庆, 孙海霞, 李军莲, 胡铁军]
, 钱庆, 孙海霞, 李军莲, 胡铁军]
, 钱庆, 孙海霞, 李军莲, 胡铁军]
|
|


作者贡献声明:
李丹亚: 提出研究思路, 设计研究方案;
李晓瑛: 进行实验;
李晓瑛, 孙海霞: 采集、清洗和分析数据;
李晓瑛, 李丹亚: 论文起草;
钱庆, 李军莲, 胡铁军: 最终版本修订。
【目的】进行基于术语同义关系发现的知识组织系统整合研究。【方法】提出一种英文同义关系自动发现算法, 涉及基于词形还原的词形归并以及基于同义关系传递和来源词表颗粒度控制的语义归并等综合方法。【结果】通过对多来源领域术语的大规模实验评估, 并与已有整合知识组织系统进行多指标比较, 获得较为满意的归并正确率, 体现出良好的可行性及实用价值。【结论】本算法可应用于大规模领域知识组织系统的整合研究中, 并对中文知识组织系统整合有一定借鉴意义。
[Objective] In order to find synonymous relations for knowledge organization system integration.[Methods] This paper presents an automatic algorithm, which consists of lemmatization and semantic merging, as well as various methods to control the effects induced by vocabulary granularity.[Results] Its efficiency and effectiveness is well demonstrated from large scale data testing using many source vocabularies, compared with well-known integrated knowledge organization system.[Conclusions] The proposed algorithm can be used in large scale knowledge organization system integration, and is helpful for Chinese knowledge organization system integration.
叙词表、分类表、本体等知识组织系统是某领域权威概念名称(术语)的集合, 一个独立的知识组织系统难以涵盖特定领域所有重要的概念名称, 整合知识组织系统是实现领域术语集成, 进而实现交互式资源集成检索与交叉浏览的重要方法。其中术语同义关系发现(亦称同义归并)是实现整合的关键, 也是不同知识组织系统之间互操作的基础。
在自然语言处理中, 研究者提出多种同义关系发现方法, 用于扩展查询以提高文本检索的效率[ 1], 这些方法大体可分为三类:
(1) 基于词共现的统计方法。基本原理是依据两个词同时在同一文献、段落或特定上下文片段中的出现次数, 对词之间的共现关系进行量化, 如常见的互信息、Jaccard系数、Dice系数等算法, 但这种算法的实质是计算词的相关关系, 并非真正意义的同义关系。
(2) 基于字面相似度的算法。通过词的构成单元(字母)来比较两个词汇的相似度, 这种方法对同义关系的识别有一定的辅助作用, 但噪音较大, 因为相互之间没有任何语义关系的单词却可能有很高的相似度, 如“Constrict(约束) ”与“Construct(构建) ”。
(3) 基于词典的方法。通过借助某些语义词典(如WordNet)来揭示词之间的同义关系, 但这种方法受词典规模及内容建设程度的影响。
目前, 上述各类同义关系自动发现方法已被应用到知识组织系统整合研究中[ 2, 3, 4, 5, 6]。例如华盛顿大学Glue系统开发小组提出基于联合概率分布和Jaccard系数的相似度计算方法, 并通过机器学习, 对本体进行概念相似度比较, 以实现本体之间的相互匹配[ 2]。希腊雅典国立科技大学的Stoilos等通过计算两个词中相同与不同的子串长度来计算这两个词之间的相似度, 开展本体对齐研究[ 3]。此外, 亦有很多学者利用WordNet所提供的同义词集合, 对UMLS整合多来源词表的结果进行改进[ 5]或优化[ 6]。
区别于上述各种方法, 本文所提出的面向知识组织系统整合的同义关系自动发现算法, 注重对知识组织系统源有同义关系的继承与发展。一方面, 同义、等级和相关关系作为三种最基本的语义关系类型, 是知识组织系统编制者根据系统的应用目标与用户的使用习惯, 同时结合编制标准和自身经验, 为概念或术语所添加的语义信息, 且同义关系本身又具有传递性质, 所以十分具有借鉴价值, 这属于继承部分; 另一方面, 由于不同知识组织系统的概念组织方式和颗粒度不同, 导致术语所表征的概念含义有所差异; 因此在整合时, 必须考虑颗粒度的影响, 对源有较细概念进行合并, 而对某些较粗的概念应做相应拆分, 此部分是对源有同义关系的发展。
对计算机程序而言, 在继承不同知识组织系统的同义关系时, 第一步操作便是进行词串匹配以查找可传递同义关系的中间术语。但不同知识组织系统中表示相同含义的术语, 往往词形不同。例如《医学主题词表》 (Medical Subject Headings, MeSH)[ 7]将“肾病”表示为“Kidney Diseases”、“Disease, Kidney”, 而在《国际系统医学术语集-临床术语》 (Systematized Nomenclature of Medicine - Clinical Terms, SNOMED CT)[ 8]中却是“Kidney disease”、“Renal disease”、“Renal disorder”; 如若直接进行忽略大小写的字符串匹配, 由于“Kidney Diseases”与“Kidney disease”存在单复数差异, 上述5个术语将被视为完全不同的词形, 且因失去中间术语而无法进行同义关系的传递。可见, 在继承不同知识组织系统的同义关系之前, 需进行词形归并处理, 以忽略单复数等词形差异。因此, 本文所探讨的面向知识组织系统整合的同义关系自动发现算法, 涉及基于已有词形还原技术的词形归并以及本文首次提出的基于同义关系传递和来源词表颗粒度控制的语义归并。
词形归并是将术语的不同表达形式统一为一个形式化标准名称, 实现方法包括词干提取[ 9]和词形还原[ 10, 11, 12]两种方式。比较而言, 词形还原方法的准确性较高[ 11]。通过对MorphAdorner[ 13]、Stanford Core NLP[ 14]、NLM NLP Norm[ 15]等多种词形还原工具的比较[ 12], 本研究选择基于NLM SPECIALIST LEXI-CON[ 16] (专家词典)的Norm工具。2013年版的专家词典含有469 992 条英语通用词汇及生物医学常用词汇条目, 涉及857 502条词汇变化形式[ 17]; 在还原词形时, Norm首先在专家词典中查找术语的原形, 对于未收录的词汇, Norm基于词汇变化规则进行相应处理。
Norm适用于处理单词及词组, 包括11项词形规范化处理操作: 去除所有格、去除带括号的复数形式(如es)、去除停用词(如of)、用空格替代标点符号、去除发音符号、去除音标符号、转变为小写形式、生成每个词的原形、处理拼写变化形式 (如Colour 转成 Color)、按字顺排序, 最后提取标准名称。Norm词形规范化操作的部分处理过程如表1所示:
| 表1 Norm词形还原处理操作示例 |
表2为Norm词形还原示例, 不同来源词表术语经Norm词形还原处理后, 最终生成一个统一的形式化标准名称“health woman”, 从词形角度起到对术语进行归并的目的, 从而为同义关系自动发现过程中鉴别上述一系列词形变体的同义词奠定了基础; 但Norm处理结果可能不具有可读性。
| 表2 基于Norm原形化的术语词形归并结果示例 |
异形同义术语如肝细胞“liver cell”和“hepatocyte”无法通过上述词形处理技术而归并到一起, 但可借助知识组织系统内在的语义关系进行归并。
(1) 同义关系传递的基本方法。整合知识组织系统的同义关系传递是指在多来源词表中表达相同概念的不同术语间的同义关系的推导传递。
(2) 同义术语匹配传递规则。多来源词表同义术语进行匹配归并时, 需遵循一定规则, 以尽可能地避免同义关系传递错误。本研究采用以下规则:
①核心词表术语优于非核心词表术语;
②优选术语优于非优选术语;
③精确匹配术语优于原形匹配术语;
④长字符串术语优于短字符串术语;
⑤多义术语要进行匹配传递控制;
⑥不可靠连接术语要进行控制或阻断。
(3) 多义术语传递控制。多义是指因歧义术语、缩略语、简称等导致的同一术语具有两种以上的含义, 易导致同义关系的传递错乱。多义术语很大程度上由缩略语和简称造成。通过对医学领域105部知识组织系统中的缩略语进行分析, 发现单纯字母型缩略语比字母数字型缩略语、短语型缩略语具有更大的歧义性; 且字母型缩略语长度为2时歧义性最高, 长度大于4时歧义性明显降低[ 18]。本研究在进行同义关系传递时按照长度对缩略语进行传递控制, 从而在一定程度上规避了多义术语传递导致的错误。
对于缩略语之外的其他多义术语, 本研究采取如下的同义关系传递控制措施: 依据源词表对概念的界定, 自动识别多义术语, 并构建多义术语词典; 依据多义术语所属范畴类别等信息, 进一步判断是否为整合词表所认定的多义术语; 对所确认的多义术语采取同义关系传递阻断等综合措施。
整合知识组织系统的多来源词表由于编制目的、类型及应用领域不同, 概念间隔尺度或词表颗粒度存在很大差异, 进而对同义关系发现产生影响。如《MedlinePlus健康主题》(MedlinePlus Health Topics, MedlinePlus)[ 19]词表颗粒度较粗, 将“Cirrhosis(硬化) ”、“Hepatic Cirrhosis(肝硬化) ”和“Liver Fibrosis(肝纤维化) ”组织为一个概念; 而MeSH中这三个术语分别表示不同的概念, 如果基于MedlinePlus词表传递同义关系, MeSH词表的三个概念通过同义关系传递会被归并为一个概念。又如《华盛顿大学数字解剖学图谱术语表》(University of Washington Digital Anatomist, UWDA)[ 20]颗粒度较细, 将“Transverse cervival veins”和“Transverse cervival vein”分为两个概念; 而SNOMED CT将它们组织为一个概念, 如果基于UWDA进行同义关系传递, SNOMED CT同一概念的两个术语会被拆分成两个概念。
针对来源词表颗粒度差异对同义关系发现带来的影响, 本研究尝试从以下两个角度进行控制:
(1) 词表颗粒度的识别和修正。首先确定拟建设的整合知识组织系统的概念间隔尺度; 基于这一标准对来源词表的颗粒度进行鉴别, 并将词表颗粒度大致分为较细、适中和较粗三类。对于颗粒度较细的词表要进行适当的预归并处理, 如将上述UWDA例子中单复数术语合并为同一个概念; 而对于较粗的词表应依据颗粒度适中的词表进行适当的概念拆分, 如MedlinePlus。
(2) 词表颗粒度差异性控制。本研究初步尝试三种控制措施:
①评分法。对每个词表颗粒度进行评分, 按分值高的词表所认定的术语关系进行概念归并和拆分。但该方法的结果是针对整个词表的, 其分值可能对绝大多数概念是合理的, 但对少数概念并不合适, 而且对每个词表进行合理打分也比较困难。
②最细颗粒度法。该方法按所有待整合词表认定的最细颗粒度的同义关系进行概念归并和拆分, 如上例中, MedlinePlus 认定术语“Cirrhosis”、“Hepatic Cirrhosis”和“Liver Fibrosis”互为同义词, 但MeSH中它们分别表示不同的概念, 其颗粒度也最细, 成为归并和拆分的依据。但该方法不适用于颗粒度过细的词表。
③统计法。该方法计算支持术语为同义或非同义关系的词表个数, 按多数词表认定的术语关系进行概念归并和拆分。但这种方法要求有足够多的来源词表支持。
通过对上述三种方法进行测试, 本研究最终提出一种基于角色归并的综合方法, 基本原理为:
(1) 根据来源词表的类型、建设目的、应用范围、权威性以及术语在期刊文献中的使用频次等, 对所有待整合词表的颗粒度进行等级评分(分值不重复), 并逐一指定各自的领域权重及归并角色: 核心词表(即主干词表)、一般词表、粗颗粒度词表以及入口词扩充表; 各个角色在术语同义关系发现中的任务如下所述:
①核心词表在归并中等级最高, 其概念颗粒度是同义关系成立的主要标杆;
②一般词表的等级低于核心词表, 术语是否需要归并优先取决于核心词表的归并结果;
③粗颗粒度等级低于核心词表和一般词表, 术语是否需要归并优先取决于核心词表和一般词表的归并结果;
④入口词扩充表用于补充词形相同的入口词, 在实际应用中多用于补充定义; 且词表中术语仅能以入口词身份归入到已有的概念中, 而不会独立形成概念。
(2) 归并时首先依据词表归并角色的等级高低, 按评分法进行颗粒度控制。
(3) 同为核心词表时, 依据颗粒度等级评分值, 按评分法进行颗粒度控制。
(4) 对于来自一般词表或粗颗粒度表且在核心表中未收录的术语, 颗粒度控制采用统计法对其进行归并或拆分。
本研究采用基于大规模实验数据的定量与定性相结合的对比分析法, 进行算法有效性和实用性验证。
(1) 测试数据集。应用本算法对18个医学领域权威性高、语义结构丰富、类型不同的英文知识组织系统进行测试, 术语总量为210余万条, 并将算法运行结果作为测试数据集, 表3为测试数据的基本情况。由于其他领域没有现成标准数据做实验对照, 结果评估有一定困难, 故选用医学领域词表进行实验。
| 表3 测试数据集基本情况 |
(2) 标准数据集。本研究所选取的术语集同时也被UMLS超级叙词表[ 21]收录(该系统目前已被广泛应用于医学信息资源的组织及管理), 可作为标准对照数据集。从术语同义关系发现的角度而言, UMLS整合过程与本文算法的不同之处主要为: UMLS通过计算机及人工辅助方法实现, 而本算法尝试基于计算机自动处理实现同义发现和归并; 从目前文献调研情况来看, UMLS采用一部词表为主干、其他词表中的术语基于主干词表汇聚、拓展的逐一归并方式, 且并未通过大规模计算机自动方法来解决词表颗粒度差异所带来的影响[ 22], 而本算法尝试基于词表领域权重、颗粒度的鉴别自动实现多部词表的同时整合。
(1) 测试方法。本研究将对术语同义关系自动发现结果的一致性及算法运行时间进行评估。一致性表示测试数据与标准数据集中某概念的术语数和内容完全一致。考虑到术语归并前后, 数据集中实际发生变化数据的比例大小会对评估结果产生影响, 本研究采用全局一致性、局部一致性的综合统计法以及对测试数据集与标准数据集不一致的数据进行抽样分析的测试方法。其中, 全局一致性将对术语同义关系自动发现前后的全部数据进行对比分析, 包括发生变化和未发生变化的数据, 而局部一致性仅对概念发生变化的数据进行统计研究。
(2) 评价指标。本研究采用的定量评价指标包括归准率P、归全率R和F值。归准率用于评价术语同义关系自动发现算法的准确度, 归全率用于评价本算法运行结果与UMLS归并结果的吻合度, 而F值则是对前两者的综合, 用于反映算法的整体情况。三者的计算公式如下:
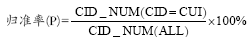 | (1) |
其中, CID_NUM(CID=CUI) 表示“测试数据集与标准数据集中概念完全相同”的测试数据集中的概念数; CID_NUM (ALL) 表示测试数据集中的概念总数。
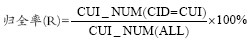 | (2) |
其中, CUI_NUM(CID=CUI)表示“测试数据集与标准数据集中概念完全相同”的标准数据集中的概念数; CUI_NUM(ALL) 表示标准数据集中的概念总数。
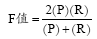 | (3) |
(1) 测试数据集与标准数据集全局一致性统计分析。经统计, 测试集术语自动归并聚集后生成773 563个概念, 比标准集概念数779 096少5 533个概念, 仅占测试集概念总数的0.7%。其中测试集与标准集完全一致的概念数为720 388, 归准率为93.1%, 归全率92.5%, 如表4所示。由于该方法对全部参与归并的术语进行计算, 而大量术语实际上在归并前后概念并未发生变化, 因而这种方法只能粗略地反映术语同义关系自动发现的大体情况, 无法确切地反映术语同义归并的准确性和有效性。因此, 本研究还需结合其他两种方法进行评估。
| 表4 全部数据一致性比较结果统计 |
(2) 测试数据集与标准数据集局部一致性统计分析。本实验所用两个数据集的局部一致性统计分析结果如表5所示。测试集产生变化的概念数为101 404个, 标准集为86 373个; 测试集与标准集完全一致的概念数为60 531个, 归准率为59.7%, 归全率70.1%。由于局部一致性仅对发生变化的术语进行计算, 因而能较准确反映术语归并的准确性。
| 表5 局部数据一致性比较分析 |
此外, 通过对测试集及标准集实际发生变化的概念数占概念总数的百分比进行统计, 如表6所示, 发现两个集合中实际发生变化的概念数很少, 表明本研究采用局部一致性对只发生变化的术语采用归准率和归全率等多种指标进行评估是十分必要的。
| 表6 同义关系发现后发生变化的概念数统计结果 |
(3) 对测试集与标准集结果不一致的数据进行抽样分析。本研究随机抽取100个归并后概念不一致的数据进行详尽分析, 发现主要原因有以下两点:
①标准数据集与测试数据集自身差异性所致。UMLS标准数据集整合了160部来源词表, 而测试数据集仅为18部词表的术语同义关系自动发现结果。如果不同来源词表术语含义相同, 但不具备实现术语自动匹配以传递同义关系的条件, 也不能被归并在一起。如表7所示, 标准数据集的一个概念C0005757, 在测试数据集被归并成两个概念C368518和C370923, 原因在于测试集的两个概念因缺少《用户健康词表》(Consumer Health Vocabulary, CHV)[ 23]中的术语“eyeblink”、“blinking”作同义关系传递, 而没有被归并在一起, 但标准集UMLS的归并结果由于来源词表较多而被关联到一起。这种情况或类似情况占抽样分析数据的51%, 如表8所示, 非本算法所致。
| 表7 测试集概念与标准集结果不一致示例 (数据集本身差异所致) |
| 表8 对局部数据不一致性的产生原因统计结果 |
②多义术语所致。来源词表中存在大量歧义术语, 在2.2节已提出一些控制多义术语传递的措施, 但由于来源词表情况复杂, 导致结果中仍存在一些因多义术语导致的归并问题。这种情况占抽样分析数据的45%。
(4) 算法运行时间。实验中, 本算法运行时间为1小时39分钟, 运行效率较为满意。测试环境为: 硬件: Intel(R) Xeon(R) CPU E7420 @2.13GHz, 16内核, 内存32GB, 存贮2TB; 软件: 操作系统 Windows Server 2003 (64位企业版), 数据库Oracle 11g (64位企业版)。
综上所述, 本算法表现出较好的归并准确率和效率。尽管归准率和归全率受到标准集与测试集自身差异的影响, 但不会对该算法的整体评估效果产生过大影响。导致实验所用的两个数据集结果不一致的原因, 除了数据集自身差异之外, 主要来自多义术语, 研究中虽然已采取相应的控制措施, 但仍需细化。
术语同义关系自动发现是整合知识组织系统的建设基础和关键环节。本文提出的面向知识组织系统整合的英文同义关系自动发现算法, 采用综合解决方案, 从词形归并、语义归并、多义术语传递控制及来源词表颗粒度控制等方面, 对整合知识组织系统英文术语同义关系自动发现的完整过程进行了探讨与实践。通过大规模领域术语测试, 及与UMLS标准数据集进行比较评估, 获得较高的归准率和归全率, 实验结果能够满足工程化实施的要求。此外, 本算法所提出的多种来源词表颗粒度控制方法以及对多义术语的歧义处理方法, 对中文术语同义关系发现及中文知识组织系统整合有一定的借鉴意义。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|