


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
面向知识关联的标签云优化机理研究*
[毕强1  , 周姗姗
, 周姗姗1 , 马志强2 , 滕广青2 ]
, 周姗姗|
|


作者贡献声明:
周珊珊: 采集、清洗数据, 进行实验;
毕强: 提出研究思路;
马志强: 设计研究方案;
滕广青: 论文起草及修订。
【目的】通过揭示与呈现Folksonomy标签云中的关联关系, 对标签云优化机理进行探讨。【应用背景】 传统Folksonomy知识组织模式中的标签云由于无法体现主题知识之间的关联, 制约了标签云的感知有用性。【方法】 通过对用户标签网络的属性分析以及模块化处理, 将标签云中的标签划分成若干个知识群落。借助连线、颜色、字号的相互配合, 从主题知识关联的视角优化标签云。【结果】 发现社群中隐含的知识群落具有稳健性, 能够呈现出知识间的关联关系。【结论】面向知识关联的标签云优化能够在多个粒度上提高标签云的感知有用性, 促进更科学实用的标签云体系研发。
[Objective] This article explores the optimization mechanism of tag cloud by the revealing and presenting of relationship of tag cloud in folksonomy.[Context] The traditional mode of knowledge organization of tag cloud in folksonomy is unable to reflect the knowledge relevance between the themes, which restricts the perceived usefulness of tag cloud.[Methods] Through the analysis of attribute on network of user tags and modular processing, tags in cloud are divided into a number of knowledge communities. With the cooperation among the links, the color, font size, tag cloud is optimized from the perspective of knowledge relevance between the themes.[Results] The latent knowledge community is robust, and it is able to show the relationship between knowledge.[Conclusions] Optimization of tag cloud based on knowledge relevance can improve perceived usefulness on multiple granularities, and promote the researching and developing of more scientific and practical tag cloud system.
Folksonomy[ 1]知识组织模式凭借其标签云的感知易用性, 为用户知识检索与导航提供了传统知识组织模式所不具备的便利。用户可以通过标签云了解社群中的热门主题, 并能够根据标签的字号大小判断主题的热门程度。然而, 在标签云的感知易用性为用户带来便利的同时, 标签云的感知有用性却未能尽如人意。标签云中的标签虽然基于统计上浮原理产生, 但其分布却松散自由, 不同标签所反映的主题知识之间无法体现关联, 从而给用户呈现的热门主题只是星罗棋布的知识碎片。
本文借助关联标签原理[ 2]与复杂网络分析技术[ 3], 基于Folksonomy中用户标签间的关联关系构建用户标签网络。通过对用户标签网络中的节点进行模块化处理, 将标签云中的标签依据网络属性划分成多个标签子群。通过标签间连线、标签颜色、标签字号的相互配合, 尝试构建一种能够体现标签主题知识关联的标签云优化机制。
Folksonomy知识组织模式中, 用户标签完全由用户个体自主标注。从这个意义上讲, 用户标签的产生是一个独立的认知过程。同时, 众多的用户标签仅仅基于统计上浮原理产生标签云。因此, 标签云在实际应用中也自然没有提供标签间的关联关系。然而, 在标签云看似自由松散的表象下, 知识的关联却无所不在。
近年来, 一些学者对用户标签间关联关系的揭示进行了有益的尝试和探索。
德国卡塞尔大学(University of Kassel)知识与数据工程小组(Knowledge & Data Engineering Group)的学者Schmitz等[ 4]与Folksonomy研究领域的著名学者Stumme合作, 对Folksonomy知识组织模式中散乱的用户标签实施关联规则的挖掘。其研究结果显示, 基于独立认知过程产生的用户标签背后存在着潜在的知识关联, 以这些关联关系组织用户标签, 能够丰富标签间的语义关联, 优化标签体系的组织结构。与此同时, 以色列学者Begelman等[ 5]采用聚类分析技术对离散的用户标签进行组合。其研究表明, 标签聚类有助于改善用户体验。在此基础上, 意大利复杂网络拉格朗日实验室(Complex Networks Lagrange Laboratory)的学者卡Cattuto[ 6]与Stumme等人合作, 通过相似性计算将用户自主标注的标签以相似程度聚类, 并与WordNet中的同义词集建立映射关系, 借助语义距离验证了用户标签在语义层面上的关联关系。此后, 国际学术界对于Folksonomy知识组织模式中用户标签的关联关系进行了更深入的研究, 包括通过标签概念空间向量分析扩展用户标签间语义关联[ 7], 采用无监督机器学习的方法挖掘用户标签间的关联关系[ 8], 以及基于多用户协作行为分析呈现用户标签间的关联关系[ 9]等。与此同时, 随着一些国际学术界在用户标签关联关系揭示方面优秀成果的引入[ 10], 国内学者对用户标签间关联关系的研究也取得了相应的进展。北京大学的周鑫等[ 11]通过对用户标签概念外延的界定, 挖掘用户标签间的关联关系。北京邮电大学的刘海旭等[ 12]通过潜在狄利克雷分配模型(Latent Dirichlet Alloca-tion, LDA)和向量空间模型(Vector Space Model, VSM)求得知识资源间的相关度, 并将知识资源间相关度与“标签-资源”的依附关系相结合, 提炼出标签间的关联关系。
随着复杂网络分析技术的兴起, 研究者们纷纷尝试从网络分析的视角探寻Folksonomy知识组织模式中用户标签的关联关系。波兰科学院(Polish Academy of Sciences)的Chojnacki等[ 13]利用迭代图反映Folksonomy用户标签超图的动态性和聚类系数的高位性。Mas[ 14]则利用“社群驱动(Folksodriven) ”展示Folksonomy中用户标签的概念结构。国内的研究中, 吴江[ 15]基于凝聚子群的标签网状分类结构对用户标签间的关联关系进行揭示。滕广青等[ 16]对Folksonomy的用户标签网络的结构中心性进行了探讨。这些研究成果为基于复杂网络分析技术解决Folksonomy知识组织模式中的用户标签背后的知识关联问题做出了有益的尝试和铺垫。
综上所述, 尽管学术界在Folksonomy的用户标签关联关系方面已经积累了较为丰富的研究成果, 但其中绝大多数成果主要围绕Folksonomy知识组织模式中一般意义上的用户标签, 而对基于统计上浮原理生成的标签云在呈现知识关联方面的感知有用性及其优化问题则鲜有问津。另外, 复杂网络分析的视角与技术为Folksonomy用户标签关联关系的揭示提供了新的理论支撑。因此, 引入复杂网络分析为探索面向知识关联的Folksonomy中标签云优化问题提供了契机。
目前, Folksonomy知识组织模式已被广泛应用于各类资源型网站, 包括: BibSonomy、Connotea、LibraryThing等。本文选择BibSonomy.org网站中的标签云作为研究数据。该网站标签云中的用户标签遵照Folksonomy知识组织模式的一般原理, 采用统计上浮原理生成。在标签云中出现的用户标签是用户自主标注行为中被频繁使用的标签。某一标签被使用的越频繁, 则标签字号越大, 标签颜色越深, 同时也反映出该用户标签在网站中处于热门的地位, 被用户群体高度关注。其具体呈现方式如图1所示:
 | 图1 BibSonomy.org网站中的标签云(数据来源: http://www.bibsonomy.org/tags, 2012-10-15) |
在实际应用中, 用户可以通过点击标签云中的某一个标签直接检索到该标签所标注的知识资源。同时还可以发现, 图1标签云中的各用户标签在布局形式上呈现出自由化的松散造型, 即标签云中并没有反映出各用户标签之间的任何关联关系。因此, 在用户点击标签云的中某一具体的标签之后, 所得到仅仅是被该标签标注的知识资源。尽管这些知识资源同时也会隶属于其他标签(被其他标签标注), 但从标签云的呈现方式上看, 这种知识间的关联关系却没有被表现出来, 制约了标签云的感知有用性。
在数据采集过程中, 选取图1中的全部标签作为本研究的原始基础数据, 共计98个标签。在BibSo-nomy.org网站的标签云中点击某一标签后, 网站在给出该标签下知识资源的同时, 也会给出与该标签处于同一标签集的其他标签, 即该标签的“关联标签(Related Tag) ”[ 1]。进一步基于关联标签建立用户标签间的关联关系。针对标签云中98个热门标签, 采用人工筛查的方法建立初始标签的关联关系, 如表1所示:
| 表1 初始标签关联关系(节选) |
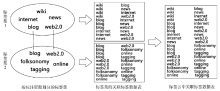
进一步, 根据表1中的初始标签关联关系, 将其转换为相应的关联标签数据表。生成过程如图2所示:
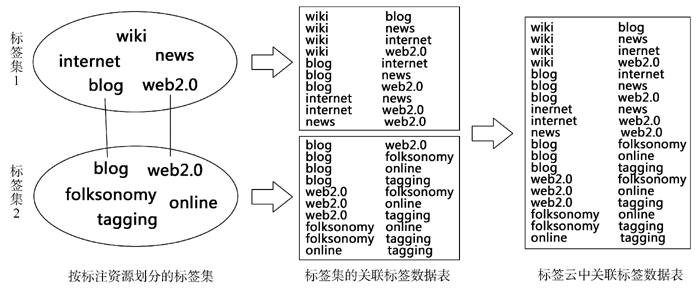 | 图2 关联标签数据表的生成过程 |
图2中, 两个椭圆分别代表两个知识资源, 资源1被“wiki”、“internet”、“news”、“blog”、“web2.0”标签标注, 则这5个标签组成标签集1, 互为关联标签。同理“blog”、“web2.0”、“folksonomy”、“online”、“tagging” 5个标签共同被用于标注资源2, 形成标签集2, 也互为关联标签。将标签集转换成标签集的关联标签数据表时, 前后两列标签与顺序无关, 处于同一行的两个标签互为关联标签。其中, “blog”与“web2.0”同时出现在两个标签集中(同时标注两个资源), 建立了两个标签集之间的联系, 在整个标签云范围考查关联标签时则合并重复的关联关系, 如“blog-web2.0”关联关系保留一个即可。
既然标签间的关联关系反映的是其背后的资源间的关联关系, 或者更深层次地说反映的是知识间的关联关系, 那么可以借助复杂网络分析技术[ 3]构建用户标签网络。通过网络结构属性揭示标签云中用户标签之间的内在关联, 从而使标签云能够呈现知识关联, 提高标签云的感知有用性。
本文将图1所示的标签云按照图2所示的方法建立标签云关联标签数据表, 将数据表导入网络分析软件Gephi[ 17], 初步获得用户标签网络如图3所示:
 | 图3 用户标签网络 |
图3中, 每一个网络节点代表标签云中的一个标签, 两个互为关联标签的节点之间由一条“边”连接。也就是说, 如果用户在标签云中选择“rdf”标签, 则可以通过网络节点的直接连接所反映出的关联关系, 一方面向用户提供“rdf”标签所标注的知识资源, 另一方面还向用户推荐与“rdf”节点存在“边”的“ontology”、“xml”、“semantic”、“semanticweb”、“database”标签所代表的知识资源, 即“rdf”标签所代表的知识主题的强关联知识。
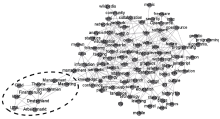
然而, 当采用Force Atlas2算法[ 18]重新计算网络节点间引力并对标签网络重新布局后发现, 标签网络中的节点在图3所示的随机分布的基础上, 由于节点间的引力差异, 形成了一些局部范围内的小子群, 如图4所示:
 | 图4 标签网络的Force Atlas2布局 |
图4显示, 基于知识资源关联生成的标签网络中, 各个节点间并非具有相同的引力。以图4中左下角虚线中的10个标签为例, 这组标签节点形成了一个相对独立的子群, 说明一些紧密关联的节点之间的引力远大于与非紧密关联节点之间的引力, 在布局上表现出一种群聚性。这种群聚性说明, 即便是标签网络背后所反映出的知识关联, 也具有远近亲疏之分, 借助这种关系能够进一步对标签云进行优化。
鉴于标签网络初步表现出的群聚性, 本文进一步对标签网络进行模块化处理, 以便更深入地探究网络中基于节点关联关系形成的标签子群及其背后的知识群落。研究中采用Blondel等提出的快速展开模块化算法, 识别社群知识群落。对节点i(知识点)是否归属于模块C(知识群落)的具体判识算法如下:
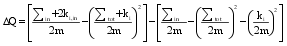 | (1) |
其中, ΔQ是节点i划入模块C后的收益, 如果ΔQ>0, 则该节点i被归入模块C; ∑in是模块C内部连接的权重之和; ∑tot是模块C内节点发生的全部连接的权重之和; ki是节点i发生的全部连接的权重之和; ki,in是节点i与模块C内各节点连接的权重之和; m是网络中所有连接的权重之和。
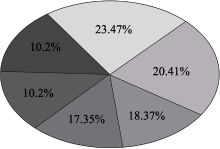
依据公式(1)将标签网络中的节点共划分为6个模块, 每个模块包含的节点比例如图5所示。图5中, 标签网络中的所有节点(即标签云中的所有标签)被分成6模块, 形成6个知识群落。从图3中可以看出, 宏观上看所有的标签都存在一定程度的关联, 其中互为关联标签的标签节点间具有强关联关系, 直接以“边”相连, 而较弱的关联关系则需要在多个节点间“跳”来连接。而图5的结果则说明, 即便是非直接相连的标签节点也同样可能存在一种较为紧密的关联关系, 这种关联关系为从中观层面上探求稍大规模的知识群落提供了条件。
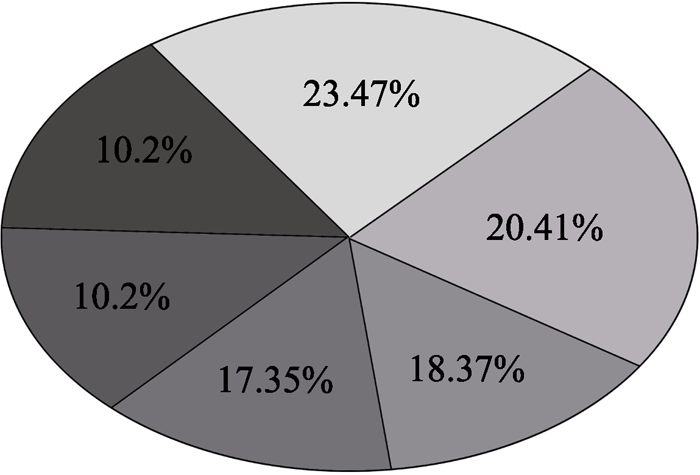 | 图5 模块化后节点分布比例 |
根据模块化处理结果分别为处于6组不同群落的标签节点赋予不同的颜色, 每个群落内部颜色统一。至此, 相同颜色的标签构成了基于知识关联和连接频度的一种知识群落, 这种知识群落未必以某一特定标签为核心, 但是往往映射出实践中某一具体的学科或研究方向中的共现知识。同时, 各个标签之间的关联关系仍然以连线表示, 连线两端的两个标签互为关联标签, 关联较弱的标签通过多节连线可达。此外, 继续保持标签字号的统计特性, 即用户使用越频繁的标签, 其字号越大。则图1中的标签云经过优化后形成的新标签云如图6所示:
 | 图6 优化后的标签云 |
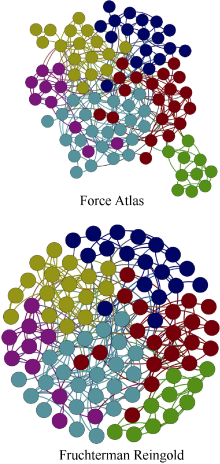
关于公式(1)对网络模块划分的有效性, 在文献[19]中有详细的实验数据支持。此处只对基于公式(1)提取的社群知识群落的鲁棒性进行测试。将研究数据在Force Atlas[ 18]和Fruchterman Reingold[ 20]两个不同的布局算法下进行测试, 结果如图7所示:
 | 图7 Force Atlas与Fruchterman Reingold算法下的知识群落 |
图7中的结果显示, 即使在不同的布局算法下, 通过模块化得到的节点子群仍然具有稳健性。在两种不同算法的布局视图中, 尽管总体布局存在一定的差异: Force Atlas算法在吸引性和排斥性方面比经典的Fruchterman Reingold算法有更好的表现, 但每个子群成分并没有不同, 子群中的节点都是相互靠拢, 且呈现出一种群聚性。这种以知识关联关系为基础的节点子群, 反映了标签网络背后的知识群落, 并且这种知识群落与网络布局算法无关, 其结构是稳定的。
将图6中优化后的标签云与图1中的原始标签云进行对比, 可以发现, 二者在标签数量上是一致的, 都含有98个用户标签。而且, 都能够以标签字号大小反映标签主题的热门程度, 使用越频繁的标签其字号越大, 其热门程度越高。然而, 在体现知识关联关系方面, 原始标签云没有提供任何线索, 标签云中的标签只是帮助用户找到被其标注的知识资源。而优化后的标签云则可以在微观、中观、宏观三个方面实现对知识关联的呈现。
(1) 在微观知识关联呈现方面, 优化后的标签云通过标签间的连线直接在标签云中呈现了关联标签之间的关系。根据关联标签的生成原理, 与目标标签直连的标签都曾经在一定程度上标注过同一知识资源。因此, 其所代表的关联知识也往往是与目标标签关系最为紧密的知识, 扩展了用户检索中的知识关联视野。从网络分析的角度来看, 这种直接关联的知识之间往往产生重要的相互影响。
(2) 在中观知识关联呈现方面, 优化后的标签云通过标签颜色将依据连接频度而处于不同模块中的标签标识出来。同一颜色的标签在标签云中构成一个特定的知识群落, 群落中的知识未必是直接相关的, 但是往往是现实研究中共现程度较高的关联知识, 进一步丰富了Folksonomy知识组织模式中的知识关联维度。从网络分析的角度来看, 这部分关联知识之间往往具有较高的互惠性。
(3) 在宏观知识关联呈现方面, 优化后的标签云能够支持沿着标签间连线将知识关联的视野延伸到距离更远的标签。对于那些希望把握全局状态的用户, 以及希望寻找更广泛的知识交叉点的用户而言, 提供了更开阔的知识导航路径。从网络分析的角度来看, 此类知识关联属于弱连接, 有助于发现新的知识增长点。
至此, 可以得出如下结论: 现有的Folksonomy中的标签云可以通过网络分析技术提高其知识关联方面的感知有用性。以标签间连线反映关联标签关系、以颜色标识区分标签知识群落、以标签间的多“跳”支持知识延展, 从微观、中观、宏观三个层面改善了传统标签云在知识关联方面的感知有用性。
通过对Folksonomy知识组织模式中标签云的分析可以看出, 尽管传统的标签云在知识关联的感知有用性方面尚不能尽如人意, 但是可以借助网络分析技术对其进行优化改进。优化后的标签云能够从多个层面实现对知识关联的支持, 改善了对知识关联关系的呈现, 极大地提高了标签云的感知有用性。下一步的研究中, 将在本文提出的优化机理基础上, 进一步探索新标签云的系统设计与开发, 以期为更科学完善的标签云应用于实践做出探索。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|