{kind=link}
{kind=link}
{kind=link}
P2P环境下基于社会化标签的个性化推荐模型研究
[赵艳 , 王亚民]
, 王亚民]
, 王亚民]
|
|


作者贡献声明:
赵艳: 提出研究问题、研究思路, 实验实施并撰写论文初稿;
王亚民: 论文版本修订。
【目的】利用用户使用标签的频率和时间因素计算用户的标签偏好向量, 讨论用户兴趣的动态变化性对个性化推荐准确性的影响。【方法】构建P2P环境下基于社会化标签的个性化推荐模型, 详细说明用户偏好的计算过程及推荐流程, 并以西安某高校的P2P电影分享系统为对象进行实验验证。【结果】在随机选择的10名目标用户中, 对其中8名用户的推荐命中率均高于传统基于用户评分的协同过滤推荐, 说明综合用户标签使用频率和时间因素的推荐效果的优越性。【局限】由于本文主要研究用户兴趣的动态性对个性化推荐的影响, 因此只在实验时人工删除无意义标签、合并相似标签, 并没有引入有效的控制标签模糊性机制。【结论】在个性化推荐中, 考虑用户兴趣的动态变化性, 有助于提高推荐结果的准确性。
[Objective] Utilizing tags frequency and time used by the user, discussing the impact of dynamic changes of user interest for personalized recmmendation accuracy.[Methods] Constructing model for personalized recom-mendation based on social tagging in P2P environment, illustrating the calculation of user preferences and recommended process in detail. Making an experiment to verify the validity of the model using P2P movie sharing system.[Results] In 10 randomly selected target users, the hit rate of recommendation for eight users is higher than traditonal collabrative filtering which is based on scores, proving the advantages of making full use of tag frequency and time factor to recommend.[Limitations] Due to the main task of this paper is to reseach the impact of dynamic changes of user interst for personalized recommendation, so only delete meaningless tags and merge similar tags by hands, do not have an effective mechanism to control the ambiguity of tags.[Conclusions] Considering the dynamic changes of user interest can help to improve the accuracy of personalized recommendation.
Web2.0时代, 用户既是内容的浏览者, 也是内容的创造者, 使得Web信息呈现爆炸式增长, 传统的搜索引擎已经无法满足用户的信息需求。因此, 有必要提出更加个性化、更加准确的推荐系统。
Intel P2P(Peer-to-Peer)工作组提出, P2P是指“通过在系统之间直接交换信息来共享计算机资源和服务”的系统[ 1], 它避免了集中式环境下把大量的用户个人信息存储在中央服务器上所带来的信任性问题, 同时避免因为中央服务器的瘫痪导致其余的计算机资源闲置浪费, 且能够满足个性化推荐系统的可扩展性和实时性要求。
社会化标签是社会化标注的结果, 它允许任意用户对感兴趣的网络资源进行基于自身理解的无约束标注。反映用户真实理解和观点的标注[ 2], 有助于发现用户兴趣的“长尾”, 能发现未知和意外的资源, 使用户能找到新的平时不易检索到的资源[ 3]。一方面, 用户在标注资源时所使用的标签既反映了用户自身的兴趣, 又反映了资源的特点; 另一方面, 社会化标签具有与生俱来的维护成本较低、自身带有语义性、容易形成社区等特点[ 4], 这使得很适合利用它来进行P2P环境下的个性化推荐。
鉴于推荐系统的必要性, P2P系统的可扩展性和实时性以及社会化标签在推荐方面的优越性, 本文提出一种P2P环境下基于社会化标签的个性化推荐模型。
目前, 国外研究主要有: Görlitz等[ 5]为标签系统提出了一种P2P结构, 为表征用户和标签环境资源, 在分布式哈希表上设计了一种保持特征向量的方案, 使用特征向量来计算用户之间的相似度; Fokker等[ 6]引入P2P维基百科的概念, 针对电影、音乐、软件等多媒体资源, 提出了一种基于社会化标签协商的个性化推荐系统; Dattolo等[ 7]将用户、标签和信息资源划分到不同的领域, 然后针对特定的用户需求领域准确过滤和筛选信息; Chen等[ 8]根据资源被标注的标签来对资源进行分类, 从而提高推荐的准确度; Shiratsuchi等[ 9]提出从二分图的角度, 对用户网络进行社区划分, 最终利用同一社区中其他用户的标注实现对目标用户的推荐。
国内现有研究中基于社会标注的个性化推荐有以下三个研究视角: 基于矩阵的方法、基于聚类的方法和基于复杂网络的方法。易明等[ 10]分析了各类方法的优势与各自面临的问题, 认为这些方法都存在自身无法克服的劣势, 结合组合推荐策略中的变换策略和混合策略, 构建了同时运用社会化网络的内容推荐和知识互动型社会化网络的协同过滤推荐的组合策略个性化知识推荐框架。刘健等[ 11]提出了一种基于非结构化P2P网络的协同过滤推荐机制, 采用基于词汇链的方法构建资源对象描述向量, 建立由偏好资源对象集合构成的用户模型,并且根据用户的兴趣变化, 通过动态邻居重组的方法获得实时的个性化推荐。
研究发现: 目前将社会化标签推荐引入P2P环境下的研究较少且相关研究在进行检索或推荐时假设用户兴趣是不变的, 但实际中用户兴趣是随时间环境的不同而动态变化的, 因此, 在总结前人研究基础上, 本文提出一种P2P环境下基于社会化标签的个性化推荐模型, 该模型综合用户使用标签的频率和时间因素来计算用户的兴趣偏好, 进而寻找相似用户, 获取与用户当前兴趣相似度较高的资源, 实现个性化推荐。
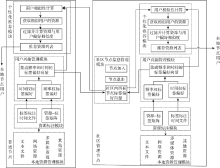
本文所构建的推荐模型如图1所示, 该模型应用于混合结构的P2P环境下, 是在非结构化P2P系统中加入社区管理节点而形成的一种层次结构。包括两类节点: 即普通节点和社区管理节点。普通节点由本地资源管理模块、资源标注模块、用户兴趣管理模块和个性化推荐模块组成。除此之外, 社区管理节点还具有社区节点信息管理模块。
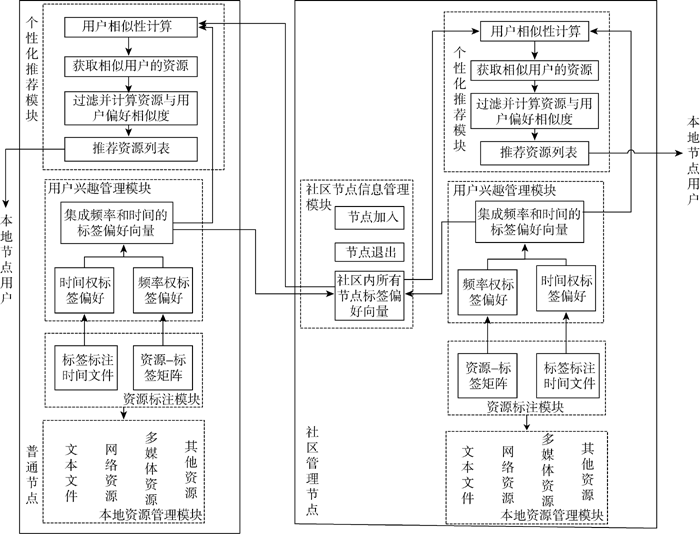 | 图1 P2P环境下基于社会化标签的个性化推荐模型 |
该模块主要用于管理本地节点用户的所有资源, 包括文本文件、多媒体资源、网络资源等, 负责用户对本地资源的添加、删除、修改等操作。标签表达了信息资源的主要特征[ 12], 拥有相同标签的资源具有某些相同的特征和属性, 并且用户使用标签的动机之一就是便于资源的定位和检索[ 13], 因此该模块利用用户标注资源时所使用的标签, 对资源进行分类管理, 便于用户查找。
该模块主要负责用户对资源的标注, 记录、更新和管理用户使用标签的时间信息和用户的资源-标签矩阵, 在该模块中, 用户可以根据自己的理解和认知, 对任意资源添加任意标签。
标签反映了用户对内容的看法及其兴趣所在, 为更加精确和具体的用户模型构建提供了丰富的信息[ 14, 15]。一方面, 用户使用某一标签的频率越高, 也就说明了用户对此相关资源的偏好程度越强; 另一方面, 用户的兴趣具有时间性的特点, 即用户兴趣是随着时间而变化的, 用户最近使用的标签更能反映用户近期的兴趣, 因此, 该模型综合考虑用户使用标签的频率和时间两方面的因素, 提出频率权标签偏好和时间权标签偏好, 并将二者综合得出最终的用户标签偏好向量。无论是普通节点还是社区管理节点, 该模块都只负责计算本地节点用户自己的标签偏好向量, 不同的是, 普通节点将计算的本地节点用户的标签偏好向量提交给社区管理节点, 由社区管理节点进行保存, 当在个性化推荐模块中计算用户的相似性时, 则从社区管理节点中获取保存在其上的其他用户的标签偏好向量。每个节点只计算本地节点用户自己的标签偏好向量, 而不是由社区管理节点计算社区内每一个节点的标签偏好向量, 这样大大减轻了社区管理节点的计算量, 提高系统的运行速度, 能够满足个性化推荐系统的可扩展性和实时性要求。
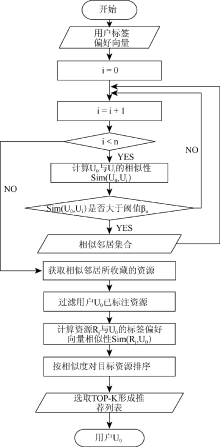
在该模块中, 首先根据社区管理节点所提供的社区内其他节点的用户标签偏好向量, 采用相似性计算方法, 当二者的相似性大于阈值时, 则形成邻居用户, 进而获取邻居用户所收藏的资源并过滤本地用户已标注的资源, 然后计算这些资源与本地节点用户的兴趣相似性, 并按相似性排序, 最终选取TOP-K形成推荐资源列表, 推荐给本地节点用户。
该模块只存在社区管理节点中, 主要负责社区内普通节点的加入和退出, 保存并维护用于个性化推荐的社区内所有节点的标签偏好向量等。当有节点加入时, 社区管理节点就会在本地存储该节点的信息, 并接收该节点提交的标签偏好向量。当有节点退出时, 则删除有关该节点的信息, 并通知与该节点有联系的所有节点。当有节点的信息发生变化时, 则提交给社区管理节点, 由该模块负责更新。
本文综合考虑了用户使用标签的频率以及用户使用标签的时间因素来表示用户的标签偏好, 即频率权标签偏好和时间权标签偏好的综合。
(1) 频率权标签偏好
用户使用某一标签的频率越高, 也就说明用户对与此相关的资源的偏好程度越强, 因此, 利用用户使用某一标签的频率来表示用户对该标签的偏好权重, 如公式(1)所示[ 16]:
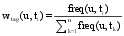 | (1) |
其中, freq(u,ti)表示用户u使用标签ti的频数, 分母表示用户u使用的各个标签的次数总和。wtag(u,ti)表示用户u使用标签ti的频率, 即频率权标签偏好权重。Tagu表示用户u的频率权标签偏好向量, 如公式(2)所示:
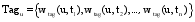 | (2) |
(2) 时间权标签偏好
Cheng等[ 17]为了考虑用户兴趣随时间的变化提出一种自适应指数衰减函数来处理标签中的时间信息, 本文通过改进, 将其应用于根据用户使用标签的时间来挖掘用户对标签的偏好, 计算随着时间的变化用户对标签ti的偏好权重, 如公式(3)所示[ 18]:
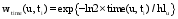 | (3) |
其中, wtime(u, ti)表示根据用户使用标签的时间计算出的用户u对标签的ti偏好权重, 也即时间权标签偏好权重。time(u,ti)≥0且time(u,ti)∈N。当用户使用某个标签时, 将该标签对应的time(u,ti)记为0, 其他标签的time(u,ti)加1, 这样, 当time(u,ti)=0时表示标签ti是用户最后一次标注时所使用的标签, 当time(u,ti)=1时表示标签ti是用户倒数第二次标注时使用的标签, 以此类推。hlu表示用户的半衰期, 其值随用户生活周期的不同而有所不同。用户生活周期等于对用户使用各个标签的时间长度取平均值, 该值越小, 说明用户生活周期越短, 其兴趣度下降越快。其中用户使用各个标签的时间长度等于其最后一次使用该标签与第一次使用该标签的时间差。最后将所有用户的生活周期从大到小排序, 并依次将用户的hlu对应为1到n, 即生活周期最短的用户所对应的hlu为1, 依次类推, 最长的为n。显然, wtime(u, ti)是一个单调减函数, 通过上述对time(u,ti)的赋值方法, 其结果是最近使用的标签的获得权重较大, 早期使用的标签获得的权重相对较小, 由此来表示用户对标签的时间权偏好。Timeu则代表了用户u的时间权标签偏好向量, 如公式(4)所示:
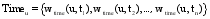 | (4) |
(3) 综合频率和时间的标签偏好
笔者综合频率权偏好和时间权偏好来表示用户的标签偏好向量, 以此来表示用户的兴趣, 如公式(5)和公式(6)所示:
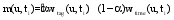 | (5) |
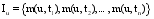 | (6) |
其中, m(u,ti)是综合了频率和时间因素后, 用户u对标签ti的偏好权重, α为调和因子, 用于调整频率权偏好和时间权偏好的权重。Iu为最终的用户标签偏好向量。
假设相似用户有相似的兴趣, 通过用户相似性计算, 寻找相似邻居, 获取相似邻居所收藏的资源。目前, 用户相似性计算方法主要有余弦相似性、皮尔森相似性以及Jaccard系数法。本文采用余弦相似性计算用户之间的相似性程度, 如公式(7)所示[ 18]:
 | (7) |
其中, X(α, β)表示用户α和β共同使用过的标签集合, mα, x和mβ, x分别表示用户α和β对于x标签的偏好权重。通过设置合适的阈值, 选取相似性大于阈值的用户作为邻居用户。
在此, 笔者提出利用邻居用户标注待推荐资源时所使用的标签和用户的标签偏好权重计算资源与用户兴趣之间的相似程度, 具体计算如公式(8)所示:
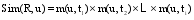 | (8) |
其中, ti表示邻居用户标注资源R时所使用的标签, 并且ti也出现在用户的标签偏好向量中, m(u, ti)为4.1节中计算出的用户u对标签ti的偏好权重。最终将所有资源按其与用户兴趣的相似度大小排序, 选排名靠前的K个资源推荐给用户, 即TOP-K。
本模型中由本地节点计算和更新自己的用户标签偏好向量, 并将其提交给社区节点供社区内所有节点共享, 通过用户标签偏好向量寻找本地用户的相似邻居, 获取相似邻居收藏的资源, 经过滤本地用户已标注的资源, 计算剩余资源与用户偏好的相似度, 并按相似度排序, 选取前K个形成推荐列表推荐给本地用户, 具体推荐流程如图2所示:
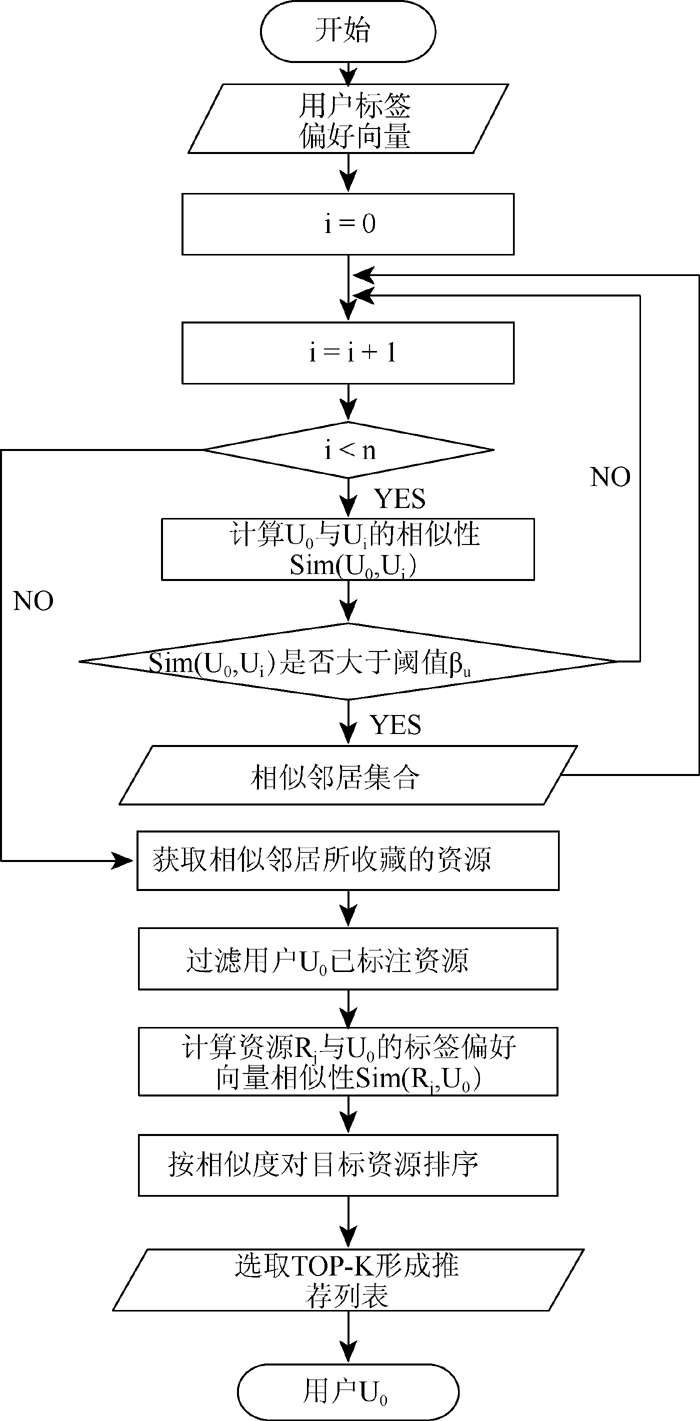 | 图2 P2P环境下基于社会化标签的个性化推荐流程 |
本文以西安某高校的P2P电影分享系统为研究对象, 该系统既允许用户对资源进行显示评分, 又允许用户使用标签进行个性化标注, 同时, 传统基于用户评分的协同过滤推荐算法是目前主流且常用的推荐方法, 因此将本文模型与基于用户评分的协同过滤推荐算法的推荐结果进行比较, 该方法根据用户对资源的评分计算相似用户, 然后根据相似用户对资源的打分来预测目标用户对指定资源的评分, 最后选择评分较高的前若干个资源作为推荐结果。
选取最近较活跃的前120名用户, 搜集每个用户收藏的资源、对资源的评分以及使用标签标注情况。通过删除无意义标签、合并相似标签后, 删除标签数目小于20的用户, 最终剩余92名合格用户作为本次实验的用户。同时, 过滤只有评分而没有被标注或者只有标注而没有被评分的资源。
以推荐准确率(P)作为推荐结果的评价参数, 表示对特定目标用户而言, 正确推荐数与推荐总数的比值, Hits表示正确推荐数, N表示推荐总数。P值越大, 说明推荐准确性越高, 效果越好, 如公式(9)所示:
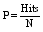 | (9) |
在本次实验的92名用户中, 随机选取10名用户作为目标用户, 分析对这10名目标用户的推荐命中率。同时, 为了验证推荐的命中率, 将目标用户所收藏的资源按时间顺序排序, 将前80%作为训练集, 剩余20%作为测试集。
将选中的10名目标用户从1到10分别编号, 其他82名用户从11到92编号, 收集每个用户使用的标签及其标注的资源, 其中部分结果如表1所示,标签用标签名(a, b)表示, a代表用户使用此标签的频次, b是根据用户使用标签的时间计算出的公式(3)中的time值, 标注资源用资源名称(d)表示, d是用户对该资源的评分。通过分析用户标签使用情况发现, 大多数用户使用频数较多的标签为10个左右, 因此选取每个用户使用频次较高的10个标签的并集作为本次实验的标签集合空间, 共76个不同标签, 因此用户的标签偏好可以表示为76维的向量。
| 表1 用户使用标签及标注资源统计(部分) |
根据表1统计的用户使用标签信息以及计算得到用户的标签偏好向量, 部分结果如表2所示。将调和因子α依次设置为0.1-1.0之间, 步长0.1, 以平均推荐命中率(Av)作为评价指标,寻找较为合适的α取值, 结果发现当α取值为0.6时, 平均推荐命中率(Av)最高, 因此在进行对比实验时, 将频率权和时间权标签偏好调和因子α设为0.6。
| 表2 用户标签偏好向量(部分) |
根据表2得到的综合频率和时间的标签偏好向量计算用户之间的余弦相似性, 寻找邻居用户集合, 设阈值为0.5, 如用户相似性大于0.5, 则认为是邻居用户。计算出邻居用户后, 按照公式(8)计算目标用户对资源的兴趣度, 将得分较高的前10个资源作为目标推荐资源推荐给目标用户。部分用户的推荐结果如表3所示:
| 表3 目标用户推荐资源(部分) |
由于本次实验数据来自于用户已访问过的记录, 并不是真正推荐的结果, 且推荐结果依赖于用户邻居已标注资源, 因此在计算命中率时, 并不要求推荐资源与测试集中的资源完全相同, 只要与测试集中的资源内容相似度较高, 就说明该资源也是用户感兴趣的内容, 即可认为是正确推荐。而相似度的计算则先由人工去除明显不相关的资源, 剩余采用文本分析的方法, 计算两个资源的内容相似度, 如果相似度大于阈值, 即可认为相似度较高, 本次实验参考文献[ 16], 将阈值设为0.6。
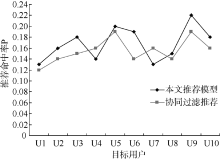
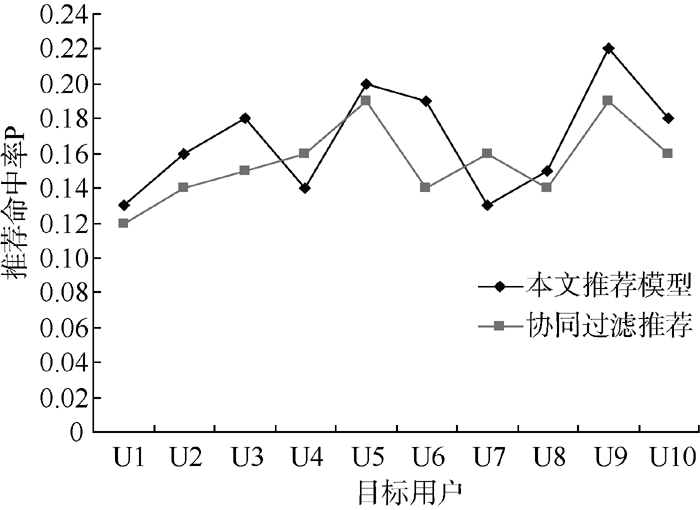
计算本文方法的推荐命中率, 并将其与传统基于用户评分的协同过滤推荐方法进行对比, 实验结果如图3所示:
 | 图3 实验结果对比 |
实验结果显示, 在10名目标用户中, 仅有2名用户的协同过滤推荐效果优于本文提出的推荐模型, 说明了综合用户使用标签的频率和时间因素来表达用户的偏好, 然后根据用户偏好寻找邻居用户集合, 获取邻居用户所收藏资源并经过过滤排序进行资源推荐算法的可行性和优越性。
利用社会化标签进行个性化推荐是目前一个研究热点, 但很少有学者在P2P环境下研究基于社会化标签的个性化推荐。鉴于P2P环境能满足个性化推荐系统的可扩展和实时性要求, 本文提出一种在P2P环境下根据用户使用标签的频率和时间因素来表示用户兴趣的个性化推荐模型, 详细分析了各模块的功能和其中的关键技术, 并通过实验验证了该模型的可行性及优越性。但在模型中, 并没有有效控制社会化标签的模糊性和同义性, 因此未来的目标是引入适当的标签处理方法, 以控制标签的模糊性和同义性, 提高推荐的准确性。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|