


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
一种面向用户偏好定向挖掘的协同过滤个性化推荐算法
[王伟军, 宋梅青 ]
]
]
|
|


作者贡献声明:王伟军: 确定研究方向及研究方法, 提出论文的修订意见;
宋梅青: 进行算法设计及实验分析, 负责论文的撰写与修订。
解决协同过滤推荐的可扩展性问题和数据稀疏性问题。
【方法】提出一种面向用户偏好定向挖掘的协同过滤算法。该算法以时间为约束, 第一阶段先寻找基于项目的弱相似用户; 第二阶段基于用户关联性和属性相似性进行定向挖掘, 形成推荐集合。
【结果】实验结果表明, 新算法的时间复杂度降低一个数量级, 并且数据越稀疏, 推荐精度的领先优势越大。
【局限】该算法基于用户已表现出的偏好进行深度推荐, 对未表现出的其他偏好暂未涉及。
【结论】该算法在提升可扩展性的同时, 对数据稀疏性也有很强的适应能力。
To solve the scalability problem and data sparsity problem of the collaborative filtering.
[Methods]This paper proposes an algorithm of collaborative filtering personalized recommendation through directionally mining users’ preferences. Introducing time as a variable, the algorithm excavates in two stages. The first stage is to find the project-based weak similar users, the second stage is to use users’ relevance and attribute similarity so as to do directional excavation and form a collection of recommendation.
[Results]Experimental results show that the time complexity of the new algorithm reduces a magnitude. Furthermore, the more sparser the data is, the greater leading advantage the recommendation accuracy has.
[Limitations]The algorithm recommends deeply by analyzing the users’ existed preferences, and it doesn’t involve the users’ preferences which haven’t appeared.
[Conclusions]This algorithm has a strong ability to adapt to data sparsity and enhances its scalability at the same time.
协同过滤是个性化推荐系统的主流技术之一, 最早用于邮件过滤和新闻推荐, 后广泛应用于电子商务领域。目前, 亚马逊、eBay、淘宝、京东等都在使用协同过滤技术进行商品的个性化推荐。不仅如此, 众多视频网站, 如: Hulu、YouTube、Netflix等也利用协同过滤推荐来提升服务质量[ 1]。社交网站Facebook还运用协同过滤技术实现了广告的个性化展示。商业应用的巨大成功, 引起了国内外众多学者对协同过滤展开研究, 试图通过对其算法的改进, 不断提高协同过滤推荐的质量。
协同过滤算法通过对用户-项目评分矩阵中评分数据的统计, 来判断用户或项目的相似性, 作 为产生推荐集合的基础。但随着用户数和项目数的不断增加, 用户-项目评分矩阵逐渐成为高维矩阵, 使得用户或项目的相似性计算的复杂度急剧增加, 进而导致系统的性能下降, 推荐的实时性和准确性降低, 即: 协同过滤的扩展性问题。此外, 高维的用户-项目评分矩阵中, 用户真正给予评分的商品项很少, 通常在1% 以下[ 2], 使得评分矩阵的数据逐渐稀疏, 从而导致推荐质量下降, 即: 协同过滤的数据稀疏性问题。本文针对这两大算法瓶颈, 提出一种面向用户偏好定向挖掘的协同过滤个性化推荐算法, 命名为: 定向协同过滤推荐算法, 该算法引入时间维度, 通过递进式的定向挖掘, 可以同时解决可扩展性问题和数据稀疏性问题, 提升系统的推荐效率。
在解决可扩展性问题方面, 目前主要有两大类的改进思路。
第一类改进思路是通过聚类来解决可扩展性问题。比较有代表性的有: Sarwar等[ 3]提出对评分进行Bisecting K-means聚类, 在聚类中寻找邻近用户集合。Rashid等[ 4]在此基础上, 为每个聚类设置一个代表用户, 通过计算和代表用户的相似性来选择邻近用户集合。王卫平等[ 5]提出了融合蚁群算法的AntStream用户聚类法, 能改善推荐实时性。邓爱林等[ 6]提出先对项目聚类, 再计算目标项目和聚类中心的相似度, 在相似度高的聚类中去寻找最近邻集合。卞艺杰等[ 7]使用LSH/MinHash算法对用户进行归类, 实现类似聚类的效果, 再计算同一个聚类中对象的相似度, 从而降低了计算的复杂性。
第二类改进思路是通过对用户-项目评分矩阵降维来解决可扩展性问题。顾晔等[ 8]提出一种改进增量奇异值分解法来降维, 每次分解都找出当前最显著的特征向量, 从而减少计算量。杨兴耀等[ 9]对项目评分统计获得评分奇异性, 采用多渠道扩散相似性模型实施推荐, 可有效改善可扩展性。Rennie等[ 10]提出利用最大边际矩阵分解法来降维, 取得了一定的效果。Goldberg等[ 11]和Kim等[ 12]提出可利用统计学中的主成分分析技术来实现评分矩阵降维。郁雪等[ 13]在此基础上, 综合使用语义分类和主成分分析, 实现局部降维, 加快系统响应。罗辛等[ 14]使用相似度支持度, 来评估项目间评分相似度的可信度, 以此来改进K近邻模型, 提高可扩展性。
在解决数据稀疏性问题方面, 对评分矩阵进行缺省值补充是常见的改进方向, 比较有代表性的有: 平均值补充[ 15], 即将已经打分项目的评分平均值补充到评分矩阵中; 众数法补充[ 16], 即将用户已评分中频次最高的分数补充到评分矩阵中。邓爱林等[ 17]依据项目的相似性预测评分, 实现数据填充。李华等[ 18]先按情境对用户群分类, 得到评分子矩阵, 再用Slope One算法对评分子矩阵进行补充。邓晓懿等[ 19]先根据情境将用户分类, 再引入社会网络理论分析用户间关系, 建立用户评级模型, 预测评分再补充。
除缺省值补充以外, 为应对数据稀疏性问题, 学者们还从信任度、模糊聚类等不同角度进行了算法改进。比较有代表性的有: 俞琰等[ 20]利用目标用户所在社会网络中用户之间的信任度来提高推荐精度。林耀进等[ 21]通过综合考虑用户之间和用户所处群体之间的相似性, 来寻找最邻近相似用户集合, 提升了推荐质量。张海燕等[ 22]利用项目属性特征对项目进行模糊聚类, 结合基于项目的协同过滤技术共同改善数据稀疏性。韦素云等[ 23]先对项目聚类, 再计算用户的局部相似性, 综合局部相似性得到全局相似性, 以此缓解数据稀疏性。
现有的改进算法在设计时, 要么专注于提高可扩展性, 要么专注于缓解数据稀疏性, 缺少能够同时解决这两大瓶颈的改进算法。而可扩展性问题和数据稀疏性问题往往是并发的。如果只改善了算法的可扩展性, 虽然能提升推荐的实时性, 但推荐精度难以保证。如果只缓解算法的数据稀疏性, 而不提升可扩展性, 即使改进后的算法推荐精度很高, 也只是理论上推荐精度。在实际应用中, 由于无法保证推荐的实时性, 使得实际的推荐精度降为零。现有算法无法同时克服这两大瓶颈的原因, 就在于改进思路上将提升可扩展性和缓解数据稀疏性对立起来, 具体如下:
(1) 基于聚类的改进算法是希望通过缩小相似用户或相似项目的搜索空间, 来降低相似性计算的复杂度, 从而提高可扩展性。但无论是对用户聚类还是对项目聚类, 均以牺牲相似性计算的精度来换取相应速度的提升。因此, 在解决可扩展性问题时很难同时改善数据稀疏性。
(2) 对评分矩阵降维固然能缩小相似性的计算总量, 在一定程度上提升可扩展性, 但这样会使得原本稀疏的数据进一步减少, 加剧了数据稀疏性。Aggarwal[ 24]和Papagelis等[ 25]指出矩阵降维会导致信息丢失, 高维矩阵的降维效果更是无法得到保证。
(3) 通过缺省值补充来缓解数据稀疏性。这类算法有两方面缺陷:首先, 用户打过分的项目毕竟只占极少数, 对海量的未打分的项目进行评分预测本身就增加了计算的复杂度, 加剧了扩展性问题。现有研究中大多通过离线方式进行评分预测, 但这只有在用户和项目处于相对静态的情况下才能实现, 而实际应用中消费及评分情况是随时变化的, 项目也在不断更新, 必须进行实时的评分预测, 但这无疑将大大延迟系统的响应。此外, 由于这些缺省值的补充由系统完成, 并不能代表用户的真实偏好, 容易造成较大的误差。
(4) 利用用户情境、信任度、用户社会关系等解决数据稀疏性。这类算法最大的应用障碍在于情境信息、信任程度数据及关系信息等本身是缺乏的, 只依据少部分此类信息就对用户进行归类, 其准确性难以保证。
本文在总结现有研究的基础上, 提出了定向协同过滤推荐算法。该算法在衡量相似性时, 摆脱了对评分矩阵和相似度计算的过度依赖, 提出一种时间约束下的新的相似兴趣判定方法, 从根本上规避了可扩展性问题的产生。再结合项目属性进行递进式挖掘, 逐步提升相似关系, 克服数据稀疏性。
定向协同过滤推荐算法的思路为: 如果两个用户在同一时间段内, 消费了同一个项目, 则认为这两个用户在该项目上有潜在的相似兴趣。根据算法判定规则, 判断这两个用户在该项目上的兴趣是否具有一致性。若有, 则称这两个用户为基于该项目的弱相似用户。由于该项目将两个不同用户的兴趣关联起来, 则称该项目为关联项目。这样, 目标用户消费记录中任意一个项目都可以找到K个弱相似用户, 将这K个弱相似用户喜欢的项目推荐给目标用户。但不是所有的都推荐, 而是那些与关联项目类似的, 并且弱相似用户兴趣度最高的才入选, 形成一个基于该关联项目的待推荐集合。找到所有关联项目的待推荐集合, 筛选后形成最终的推荐项目列表。
算法通过两个阶段的递进式挖掘, 将弱相似变为强相似。第一阶段先寻找基于项目的弱相似用户, 如图1所示。第二阶段基于用户关联性和属性相似性, 通过定向的偏好挖掘, 形成推荐集合, 如图2所示。
 | 图1 第一阶段流程图 |
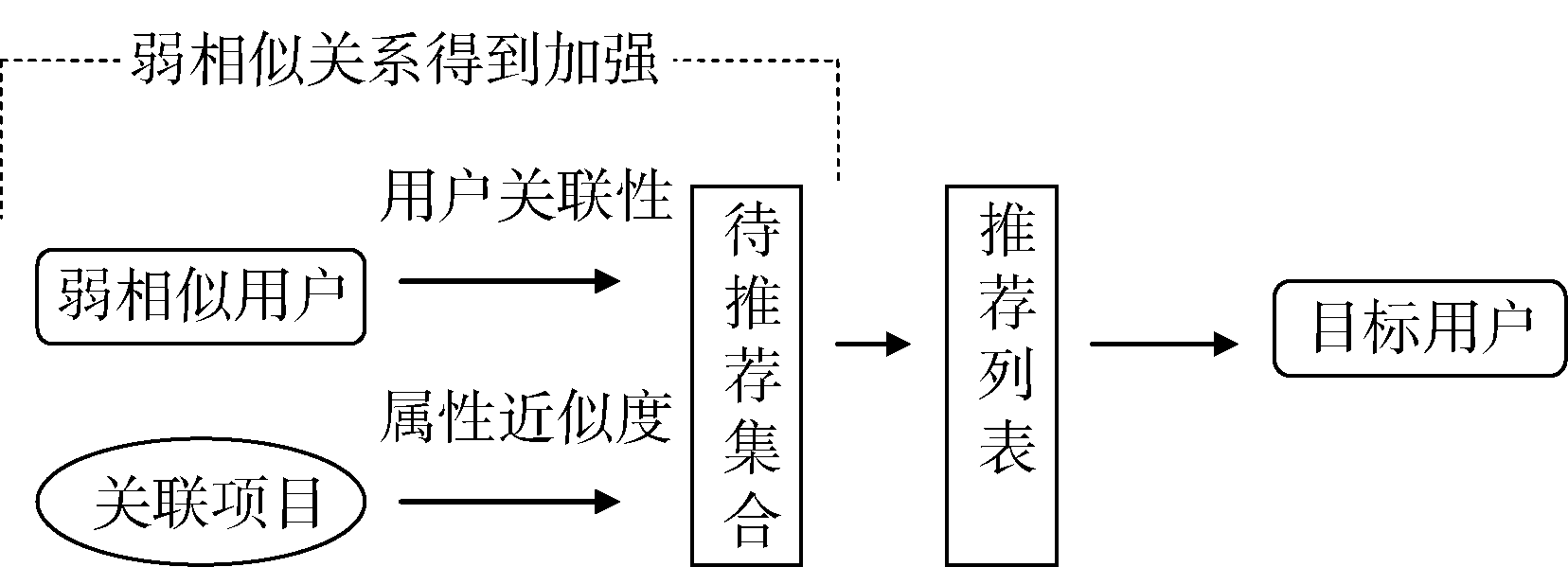 | 图2 第二阶段流程图 |
3.3 算法的实现
设U为非空集合, 是所有用户构成的集合。设R为非空集合, 是所有项目组成的集合。设(i=1,2,
,m)为U中的任意一个用户, 设
为任意用户
的消费记录。
定义1: 弱相似用户。X,YU,bR, 如果用户X和用户Y在同一时间段内, 消费了同一个项目b, 则根据弱相似用户判定规则P, 判断X和Y在项目b上的兴趣是否具有一致性。若有, 则称X和Y为基于项目b的弱相似用户。其中, 同一时间段的长度可根据需求调解。
定义2: 关联项目。X,YU,bR, 若X和Y为基于项目b的弱相似用户, 则称项目b为关联项目。关联项目连接着弱相似用户之间的相似兴趣。
弱相似用户判定规则P: 当两个用户中至少一方表现出明显的负面评价时, 判定兴趣不一致。否则, 判定这两个用户对于该项目的兴趣具有一致性。即使双方均未对该项目打分, 或者评分不完全一样, 也同样判定兴趣具有一致性。因为消费行为本身已经代表了双方具有类似的需求和潜在兴趣。
设目标用户为 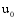
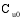
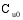
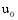
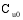
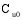
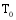
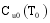
算法的具体实现步骤如下:
(1) 寻找目标用户的弱相似用户集合。
若目标用户 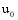
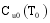
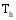
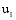

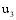

其中, 时刻t一定是包含在 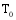
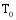

(2) 根据找到的弱相似用户及其关联项目, 计算基于该关联项目的待推荐集合。
{ 
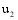
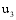
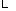
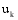
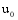

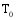
系统根据每个项目的内容, 预先将其分配在一定类别当中, 这些类别以标签的形式存在, 例如: 某电影视频网站, 将其电影按地区(如美国、中国、欧洲等)和类型(如喜剧、爱情、动作、科幻等)进行分类。通过计算潜在推荐项目与关联项目的类别标签重合度来确定两者所在类别远近。
定义3: 关联项目近似度。设ABR, 项目A为关联项目, 项目B为潜在推荐项目, 称B相对于A的类别近似度为B的关联项目近似度。
本文提出一种关联项目近似度的计算公式, 如下:
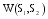
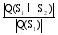
其中, 


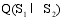

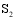

通过以上方法, 可以计算出所有潜在推荐项目的关联项目近似度, 再结合弱相似用户对其本身消费项目的评分, 才能得到项目的推荐分数。以弱相似用户 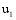
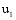
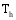
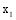
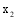
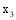
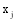
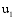
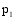

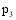
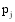
本文提出一种潜在推荐项目的推荐分数计算公式, 如下:
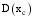
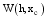
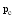
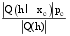
其中, 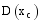
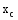
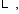
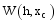
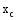
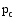
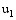
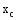
找出 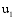
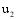
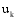
(3) 计算出所有关联项目的待推荐集合, 综合处理后得到最终的推荐列表。
目标用户的最新消费记录 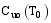
实验数据来自美国Minnesota大学的GroupLens研究项目组提供的数据集ML-100K。数据集有23个文档数据, 共包含943位用户对1 682部电影的10万条打分记录、用户基本信息、电影基本信息等。每个用户至少对20部电影进行了评分, 打分标准采用5分制, 分数越高表示对电影的满意度越高。评分矩阵数据稀疏度为1-100000/(943×1682)≈0.936 9。
本文的定向协同过滤推荐算法采用Top-N推荐, 其测评采用业内通用的召回率和准确率, 召回率描述有多少比例的用户-项目评分记录包含在最终的推荐列表中, 而准确率描述最终的推荐列表中有多少比例是发生过的用户-项目评分记录[ 1]。
召回率公式[ 1]:
Recall= 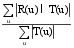
准确率公式[ 1]:
Precision= 
其中, 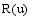
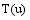
(1) 在训练集上将目标用户已消费项目中评分最高的项目抽取出来, 按时间先后顺序依次排列, 作为候选的关联项目。本实验入选标准为4分, 即用户消费后评价较满意的项目。
(2) 将前5个、前10个、前15个、前20个、前25个候选关联项目, 依次存贮在集合G1、G2、G3、G4、G5中, 作为5个正式的关联项目集合, 这5个关联项目集合对应的消费时间段依次为T5、T10、T15、T20、T25。
(3)以T5到T25这5个不同长度的时间段来截取训练集数据, 时间片段越短, 对应数据源越稀疏。实验以不同稀疏程度的数据来测试算法在数据稀疏性方面的表现。将传统的召回率和准确率中的 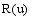
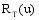
需要注意的是, 由于每个用户起始消费时间、消费周期和消费频率都不一样, 所以针对每一个目标用户都将根据其消费时间的区间, 设定个性化的时间搜索范围。若目标用户的消费不足以划分为5个时间片段, 则以实际消费为准, 对备选关联项目数除以5后取整。
实验选取传统的基于用户的协同过滤算法(UBCF)和基于项目的协同过滤算法(IBCF)作为对比。以定向协同过滤推荐算法测试中相同的时间片段来截取训练集数据, 作为查找的数据源来计算准确率和召回率。最后将每个时间段下的测评数据取平均值。为突出不同时间段约束, 将上述两种对比算法重新标记为UBCF-TC和IBCF-TC。实验使用的软件平台为Matlab7.0, 最终的测试结果如表1和表2所示:
| 表1 召回率测试结果 |
| 表2 准确率测试结果 |
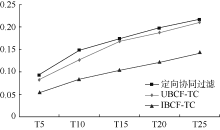
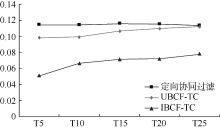
将测试结果中召回率和准确率的对比绘制出来, 如图3和图4所示:
 | 图3 召回率对比 |
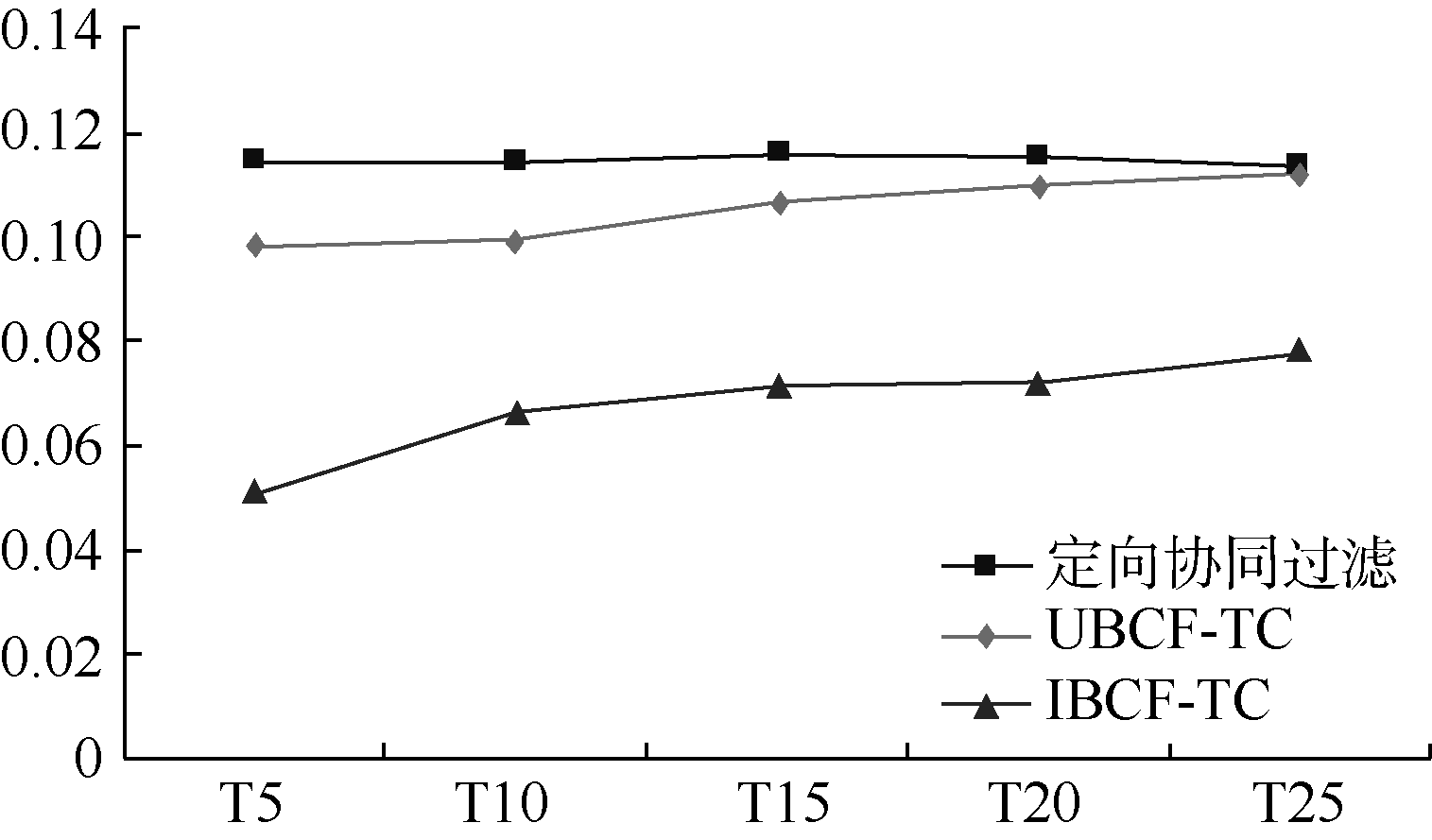 | 图4 准确率对比 |
在T5到T25整个阶段, 定向协同过滤的召回率和准确率都居于领先位置。在算法的时间复杂度方面, 定向协同过滤推荐算法为, 而传统的协同过滤算法中, UBCF-TC和IBCF-TC在相似度计算阶段的时间复杂度就达到
。总体上看, 定向协同过滤推荐算法的时间复杂度降低了一个数量级。因此, 在保证较高推荐精度的同时, 提升了系统响应, 成功解决了可扩展性问题。能够改进的原因就在于, 定向协同过滤在算法流程设计上, 不需要对全局用户或项目进行相似性比较。而是针对自身消费, 在时间约束下进行定向挖掘, 逐步提升相似性。因此, 不会随着用户和项目的大幅增长, 出现计算复杂度急剧上升的情况。
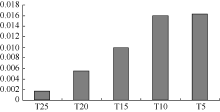
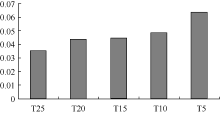
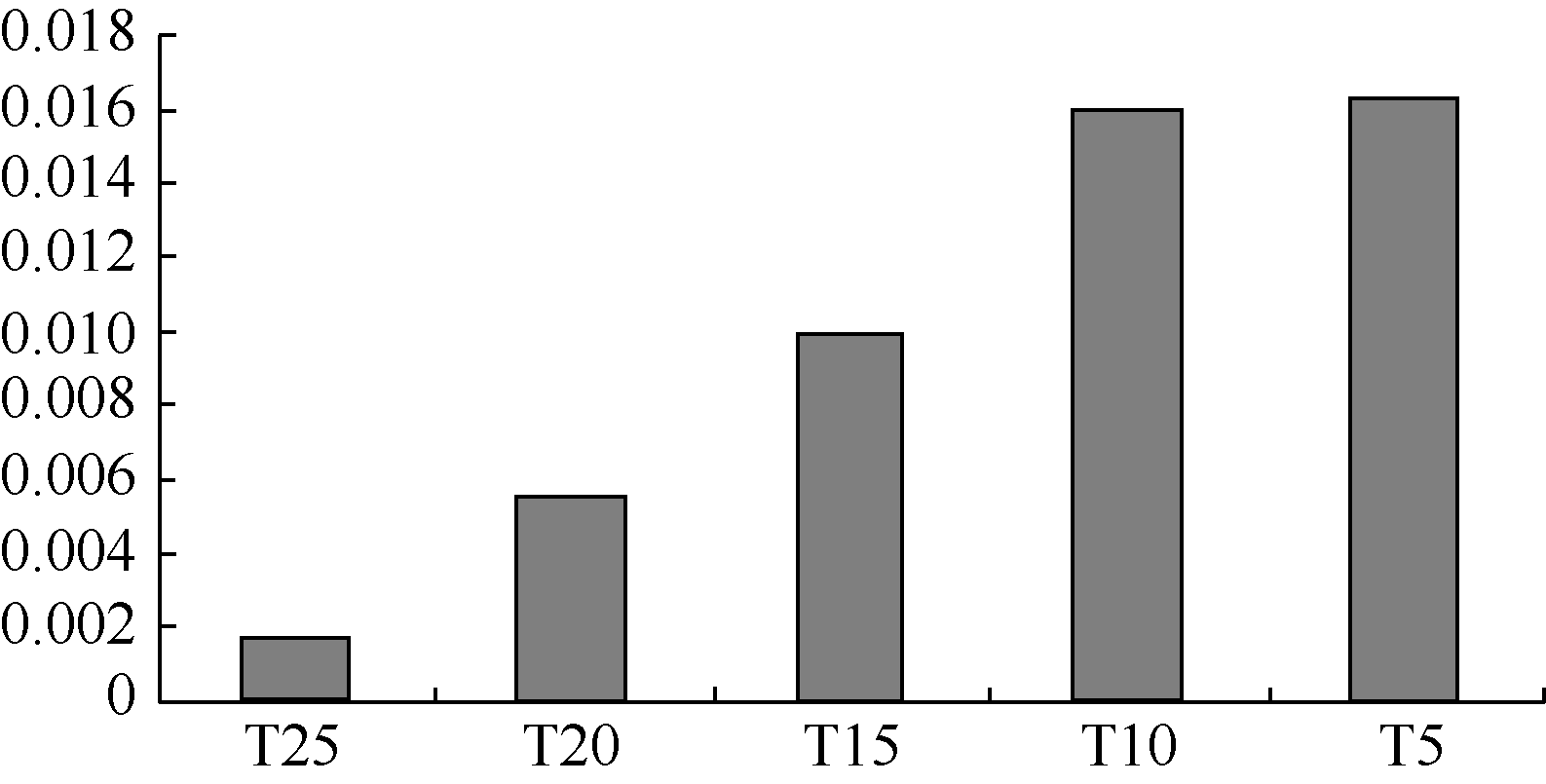
设定向协同过滤推荐算法与UBCF-TC算法、IBCF-TC算法的准确率的差值分别为C1、C2, 将不同时间片段下的C1和C2的值, 分别绘制成图5和图6:
T25对应的时间片段最长, T5对应的时间片段最短。从T25到T5, 随着时间片段逐渐缩短, 相应的数据也进一步稀疏, 而此时定向协同过滤推荐算法在准确率上的领先优势却逐渐扩大, 说明算法对于数据稀疏性的处理能力更强。
定向协同过滤推荐算法能够克服数据稀疏性的原因来自两个方面:
(1) 由客观行为部分代替了主观评分。在算法第一阶段, 当两个用户在同一时间段内消费了同一项目, 即被认定在该项目上有一定程度的相似偏好, 即使二者都没有打分或只有一个打了分, 也不影响两个用户有弱相似偏好的判定。因为这种消费行为本身已经反映出他们对该类项目有相似的需求。当两者中至少一方表现出明显的负面评价时, 才放弃弱相似偏好的判定。
(2) 由全局数据补充个人数据。目标用户通过关联项目找到弱相似用户以后, 将弱相似用户的个人评分数据应用到对目标用户的推荐上来, 即: 将弱相似用户评分最高的项目推荐给目标用户。在筛选待推荐项的过程中, 通过关联项目近似度计算, 将这种评分数据应用的误差约束在可控的范围内, 有效地缓解了数据稀疏性。
定向协同过滤推荐算法以消费时间为约束条件, 定义了关联项目和弱相似用户等新变量, 通过定向挖掘寻找合适的推荐项目, 提出了一种全新的算法思路。该算法的优势在于提升可扩展性的同时缓解数据稀疏性。下一步的改进方向, 应该是进一步提升推荐精度。笔者将继续对算法进行优化, 以期形成更加完善的个性化推荐方案。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|