{kind=link}
{kind=link}
微博中文本特征质量对检索效果的影响
[唐晓波, 房小可 ]
]
]
|
|


作者贡献声明: 唐晓波: 提出研究思路, 设计研究方案, 以及最终版本的修订;
房小可: 数据采集、清洗和各特征质量指标的计算, 以及论文的撰写。
通过对国内4大微博平台中特征词质量的测度, 探讨其质量指标对检索效果的影响。
【方法】将权重计算指标TF-IDF从特征词角度提升为特征的研究, 并通过描述能力和辨别能力两个质量测度指标对国内4个主流微博平台中各特征的质量进行评估。
【结果】微博中文本特征的描述能力和辨别能力对检索效果产生正向影响; 各平台不同特征的质量对分类有着不同程度的影响, 两种测度指标综合考虑时得到的分类效果最好。
【局限】微博中的对话回复、粉丝数、关注数等特征并没有被考虑在内; 对于语义研究中的特征词一词多义或者同义词的讨论并未涉猎。
【结论】本研究可更好地揭示微博中各种特征影响检索效果好坏的重要程度, 有助于研究者对各平台特征作用的深入理解, 从而从根本上提高社会化媒体平台的检索质量。
To discuss the effect of features quality on the search results through the four major domestic microblogging.
[Methods]The weight calculation indicators TF-IDF is enhanced from the perspective of the whole feature, and the quality of each feature in the microblogging is further assessed by the two measure indicators including descriptive power and discriminative power.
[Results]The descriptive power and discriminative power in microblogging appeare positive effects on the search results; Different quality of features in each platform has different impact to the classified results; And integrating the two indexes has the best effective in the classification.
[Limitations]Some other features in the microblogging, namely dialogue replies, and number of fans, have not been taken into account. And the word semantic ambiguity characteristic like synonyms is not discussed yet.
[Conclusions]This study helps features in the microblogging to be in-depth understood through the discussion that the effect of features quality on the search results. So as to improve the retrieval quality in the social media platforms.
分类号: G203
随着Web2.0技术和移动互联网技术的迅猛发展, 互联网的普及率和覆盖率大幅度提升。截至2012年12月底, 我国网民规模已达到5.64亿, 互联网普及率为42.1%, 较2011年底提升了3.8个百分点, 在互联网的应用上, 即时通信、博客/个人空间、微博、社交网站、视频分享等社会化媒体类应用的用户使用率均位于前列[ 1]。可以说, 以博客、微博、社交网站等为代表的社会化媒体已经在我国互联网中占据主流地位, 逐渐成为人们获取与创造信息的主要载体。如新浪微博在2011年10月20日推出独立的微博搜索(http://s. weibo.com), 以及腾讯的搜搜检索推出微博实时搜索(http://search.t.qq.com/)。本文提到的检索也是针对微博平台的检索。
由文献[1]进一步可知, 作为社会化媒体之一的微博, 其用户规模达到3.09亿, 用户使用率达54.7%。微博中用户产生内容类型多样, 包括文本、图片、视频和音频, 同时每种类型本身有着不同的内容特征。对于非文本特征信息, 其内容特征来自于对象本身, 如纹理等[ 2]。而对于文本信息, 其内容特征来自于用户的创建过程中产生的信息。事实上, Web2.0应用下的信息检索, 包括多媒体领域的信息检索, 仍更多地考虑网页中的文本特征[ 3, 4], 即文本信息内容而并非纹理等对象本身特征。本文正是基于文本信息的特征质量分析, 然而从以往的研究来看, 有关基于文本特征检索的研究更多的是对标签质量的探索[ 5, 6, 7], 对于其他文本特征对检索效果的影响研究尚不多见。此外, 微博中用户发布信息的无监督性和随意性使得信息质量良莠不齐, 严重影响了社会化媒体检索结果的好坏, 这成为社会化媒体检索领域亟待解决的问题之一。
在这种背景下, 以国内4大微博(新浪微博、腾讯微博、网易微博、搜狐微博)为研究平台, 探讨文本特征的质量对检索效果的影响, 以期为社会化媒体检索提供有益的改进借鉴。本文涉及的微博文本特征质量指标包括描述能力和辨别能力, 通过权重计算各文本特征的质量, 进而通过实验证明不同微博平台的每个文本特征对检索效果的影响, 旨在探索4个问题: 每个微博平台有价值的文本特征是如何分布的; 文本特征的描述能力对检索结果产生怎样的影响; 文本特征的辨别能力对检索结果产生怎样的影响; 每种权重组合对检索结果产生怎样的影响。
信息质量的研究起于较早的数据质量的研究[ 8], 早在1997年, Strong等[ 9]提出文本中数据的质量包括本质质量(Intrinsic DQ)、获取质量(Accessibility DQ)、情景质量(Contextual DQ)和表达质量(Representational DQ)。所谓本质质量, 即信息资源内在、独立、固有的属性, 如准确性、客观性等, 本文主要从特征本质质量角度, 对微博文本特征的质量展开研究。
目前, 由于缺乏坚实的信息质量理论的支持和统一应用研究领域, 信息质量评估的研究还处于探索阶段, 还没有一个能被广泛认同的评估体系[ 10]。在问答系统中, 用户检索出的答案是由其他相同主题下的用户提供的, 根据这一特性, Agichtein等[ 11]利用文本特征和社会关系特征来定义和区分答案中的高质量信息, 以此提高检索效果。其中, 文本质量是通过字典和语法规则来测量, 而社会性特征通过用户建立的不同网络关系实现测度。相类似的还有Pike等[ 12]和Camm等[ 13]的研究。
在文本特征质量对检索的影响研究方面, 除了以上提到的关于标签质量的研究, 也有少量针对其他特征质量的研究。Mishne[ 14]对博客中评论特征进行分析, 包括评论的普及率和分布, 表明评论中的信息可以提升检索效果。FitzGerald等[ 15]通过用户之间的交互关系使用线性链方法将博客中的评论进行质量分类。信息质量的研究也是对协同创建内容检索的关键, 因此很多学者关注维基百科中信息的质量。Lih[ 16]通过编辑数量、辨别性等测量指标评估维基百科中的文本质量。Dalip等[ 17]对维基中的结构、类型、长度等特征进行定义, 通过不同的组合探索不同特征的影响程度。Reich等[ 18]通过对学生使用维基的调查评估了维基的文本质量, 得到Web2.0下的内容可以提供研究环境。值得一提的是De Moura等[ 19]提出网页特征内容测量的方法分析网页结构的重要性, 本文借鉴其中的TF和IDF两个测度方法表示文本的描述能力和辨别能力。
在微博搜索平台上, 搜索得到的内容是以对象为整体返回的, 对于一个对象而言, 通常由用户名、发布微博和原始微博组成。本文把这种由用户名、发布微博和原始微博三部分组成的整体称之为一个对象, 用字母“O”表示。用户名是微博用户的代名词或称呼, 不仅可以使用真实姓名或者公司团体名, 还可以以个人的兴趣命名, 如“搜索引擎”这一用户名某种程度上可以表示出用户的兴趣; 发布微博是用户最新创建的微博, 位于用户名下方; 原始微博是用户转发的微博, 由于早于发布微博, 本文称之为原始微博。二者都是用户创建的内容, 包括心情、新闻或者评述等, 是用户重要的表达渠道。因此, 按照对象结构中的三个特征文本进行分析, 探究其对检索效果的影响。
研究样本来自于国内的4大微博中笔者关注的内容。从2013年8月26日到2013年9月4日共10天时间, 每天中午时段抓取10页微博对象内容, 对于每个对象所抓取的特征包括用户名、发布微博和原始微博。根据笔者的关注内容, 每个平台抓取的微博对象的类型和数量如表1所示:
| 表1 各平台微博对象的类型和数量 |
由抓取结果可知, 各平台中每种对象类型的分布比较平均, 其中网易微博的数据总量最多。客观原因之一是网易微博中的原始微博数量比较少, 检索返回的对象更多是仅由用户名和发布微博组成的, 每个对象占用较少版面空间所致; 主观原因之一可能是由于网易微博中的用户行为更多是发布微博而非转发微博, 从而导致客观原因的产生, 导致所抓取的微博对象的数量相对比较多。
对微博文本特征质量评估的前提是了解每个特征在各平台的分布情况, 这也是探索该特征在检索中的重要程度的基础。本文通过对微博平台数据的分词处理和词频统计, 选择词频在100以上的非停用词作为考核的特征词标准。每个特征项在4大微博平台中的比例, 以及含有特征词的特征项在该特征项总量中的比例如表2所示:
| 表2 各平台特征分布 |
从表2中可看出, 新浪微博平台拥有的用户特征和原始微博特征所占比例最高, 这也说明了新浪微博是目前使用最广泛和拥有最大客户群的交互平台, 用户平时在发布消息的同时也习惯在该平台上浏览信息并转发; 腾讯微博较其他三种微博平台拥有更多发布微博和特征原始微博, 这是因为用户使用QQ等聊天工具时较容易登录腾讯微博, 因此存在更多的发布微博; 而在所抓取的对象中搜狐微博和网易微博原始微博数量极少, 网易微博中甚至为零, 从这一现象可以推理出, 用户在使用网易和搜狐微博的时候更多是直接发布自己的观点和态度, 比较少浏览微博中的内容。虽然网易微博平台用户的使用量比较少, 然而其所含有特征词的发布微博所占比例最大, 其原因之一可能是网易微博的长度更长, 表达观点的用户更专业化, 这一点在图1中有所表现。
一个检索系统中检索效果的好坏与特征词权重的准确性密不可分, 因此人们一般用特征词集合表示网页中的内容。而为了计算网页的重要性, 除了使用PageRank[ 20]算法直接以网页为整体计算网页重要性外, 赋予特征词一定的权重同样是区分网页重要性的方法。为了分析每种特征项对检索效果的影响, 本文同样从特征词分析的角度来解决该问题。
一个文本内容是否与查询词相关, 首先要分析该文本的描述能力, 即该文本所描述的内容是否与查询词密切相关; 其次要分析文本的辨别能力, 即人们是否能准确地断定其所属类别, 如提到“摇滚”人们很容易辨别其所属类别为“音乐”。为了对描述能力和辨别能力进行定义, 需要引入应用在空间向量模型中的TF(Term Frequency)和IDF(Inverse Document Frequency)两个测量方法[ 21], 如公式(1)和(2)所示:
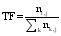
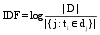
公式(1)中TF指某一个特征词在文本中出现的频率, 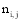
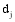
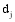
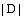
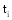
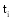
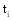
(1) 特征的描述能力
根据需要, 引入TF和IDF思想分析每个特征的描述能力和辨别能力。设O代表一个对象, 包括用户名、发布微博和原始微博三个特征; t表示特征词; T表示特征词集合; i为特征词的数量。则有公式(3)和公式(4):
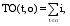
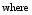
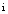
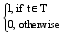
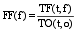
其中, 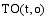
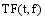
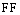
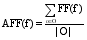
其中, 
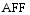
(2) 特征的辨别能力
同样, 运用IDF的变形来表示特征的辨别能力。IFF表示逆特征频率, 则根据公式(2)转化概念得到公式(6):
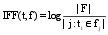
其中, 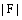
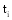
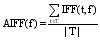
其中, 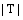
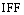
为了深入分析微博中文本特征项对检索性能的影响, 分两部分进行实验。在第一部分实验中, 利用仿真技术, 从粗粒度角度探究描述能力和辨别能力对检索效果的影响; 在第二部分实验中, 从细粒度角度出发对每个特征项的描述能力和辨别能力进行权重组合, 深入分析每个文本特征对检索效果的影响程度, 同时运用检索中的分类这一重要任务作为检验标准, 探究哪种组合为最佳组合。
系统动力学仿真是情报学领域中的一种有效方法[ 22], 为了验证文本特征的描述能力和辨别能力对检索效果的影响程度, 笔者使用系统动力学仿真模拟微博中文本特征对检索效果的影响。
首先, 假设在同一环境下, 忽略其他因素的影响, 只考虑特征的描述能力和辨别能力, 可得到两种指标与检索效率的系统流图; 其次, 根据系统动力学原理确定状态变量、流率变量和辅助变量; 为了实现本实验的目标, 设置状态变量为检索低效率(Lowprecision)和检索高效率(Highprecision), 设置描述能力(Description)和辨别能力(Distinguish)为辅助变量, 以此考察两个因子对状态变量的影响。对状态变量和辅助变量的取值做简单解释:
(1) Lowprecision:低效率变量, 设置其初始值为100;
(2) Highprecision: 高状态变量, 设置其初始值为0;
(3) Description: 两个状态变量的辅助变量, 即描述能力, 分别考察其取值由5到10时, 状态变量的变化情况;
(4) Distinguish: 两个状态变量的辅助变量, 即辨别能力, 分别考察其取值由5到10时, 状态变量的变化情况。
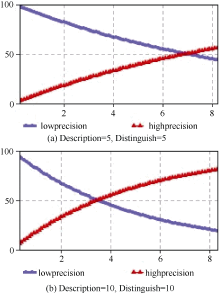
同时设置滑动窗口为8个单位。对两个变量取值, 得到其对检索效果的影响如图1所示:
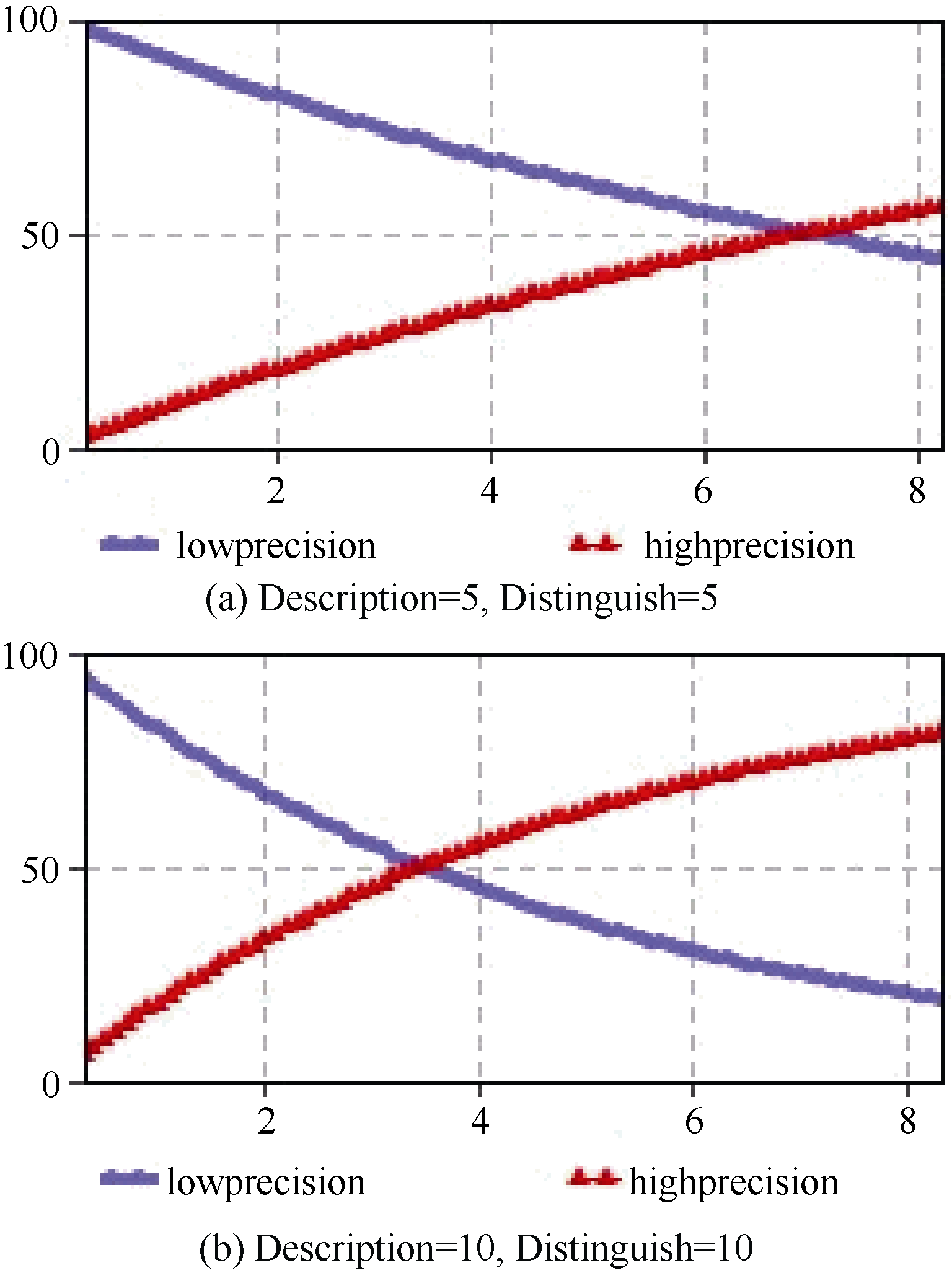 | 图1 描述能力和辨别能力对检索效果的仿真 |
由仿真结果可知, “蓝色”代表的状态为低效率, “红色”代表的状态为高效率。描述能力和辨别能力取值都为10时比二者取值为5时的转换速率快近两个单位长度。由此可推理得知, 微博中文本特征的描述能力和辨别能力对检索效果产生正向影响, 文本特征的描述能力或者其辨别能力的增强都能提高检索性能。
通过6.1节的实验, 初步了解到微博文本特征的描述能力和辨别能力对检索性能有正向影响。笔者进一步分析三种特征的质量, 即两种指标对检索性能的影响程度。由于对检索词的设定标准及相关性本文尚未提及, 因此对于权重的验证方法, 采取作为检索的重要任务“分类”方法进行验证。可得到各个文本特征的描述能力和辨别能力如表3所示:
| 表3 4大平台各特征的描述能力和辨别能力 |
由表3可知, 特征的描述能力和辨别能力被新浪和腾讯两大平台占据。首先, 新浪微博的用户名特征较其他平台, 具有较高的描述能力和辨别能力, 这不仅说明新浪微博平台拥有最多用户群, 同时表明其用户名一部分以关键词命名, 是比较随意的; 其次, 新浪微博中的发布微博和原始微博两个特征具有较高的辨别能力, 而二者在腾讯微博中具有较高的描述能力。即在腾讯微博的发布微博和原始微博中, 特征词的平均出现率更高。
然而, 对微博进行检索的结果是由对象整体组成的, 即对用户呈现的结果是对象列表并非单个文本特征。因此, 需要计算整个对象的权重, 首先探讨每个特征的权重, 对此笔者设置以下三种权重方案:
(1) FF: 对每个文本特征只计算描述能力, 并将其作为最终考核的权重;
(2) IFF-: 对每个文本特征只计算辨别能力, 并将其作为最终考核的权重;
(3) FF*IFF-: 对每个文本特征计算描述能力与辨
别能力之积, 并将其作为最终考核的权重。
其中IFF-表示对象内的特征辨别能力, 分母表示在对象内的特征词频数, 如公式(8)所示:
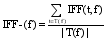
对于检索结果的任何对象而言, 其组成部分至多包括用户名、发布微博和原始微博。因此每个对象可以表示为由三个特征组成的向量空间, 其中每个特征用权重表示, 记作 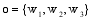
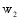
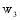
KNN(K-Nearest Neighbor Algorithm)是电子信息分类器算法的一种, 对包容型数据的特征变量筛选尤其有效, 被认为是VSM(Vector Space Model)理论下最好的分类方法[ 23]。因此选取该方法实现对微博对象的分类。根据上文的权重策略, 对于 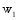
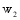
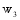
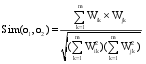
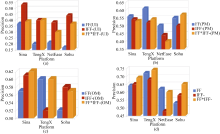
利用KNN分类方法得到各特征的三种权重组合在4大微博平台上的分类准确率如图2所示:
 | 图2 各特征的三种权重组合在4大平台的分类效果 |
可知, 图2(a)表示各平台中用户名特征的质量对分类效果的影响, 特征中描述能力最高的新浪微博分类准确率较其他微博明显要高, 其次是网易、腾讯和搜狐微博平台。同理, 特征中辨别能力最大的新浪微博分类准确率也最高, 其次是搜狐、腾讯和网易。以上结果与表3得出的结果相对应, 同时证明了6.1节中的实验, 即描述能力和辨别能力对检索性能产生正向影响。此外, 可看出各平台的用户名这一特征的辨别能力比描述能力的分类效果更明显。
同理可解释图2(b)和图2(c), 其中发布微博特征中描述能力的分类效果较辨别能力更显著。由于网易微博平台中的数据不存在原始微博, 在图2(c)中未给出, 在该特征中新浪微博和搜狐微博在辨别能力的分类效果优于描述能力, 而腾讯微博与之相反, 其原因可能与平台中的信息特征有关。
图2(d)表示综合考虑三种特征, 即用户名、发布微博和原始微博在各权重组合的情况下, 实现的4大平台的分类效果。从总体趋势来看, 描述能力和分辨能力强的新浪和腾讯微博平台, 其分类准确率要高于网易和搜狐微博平台, 这在一定程度上验证了6.1节中实验的结果; 从单个平台来看, 除了网易微博, 在其余微博平台中, 利用FF*IFF-的权重组合得到的分类效果优于前两种权重策略。
探讨社会化媒体中信息质量对检索效果的影响, 有助于研究者针对平台特征构建检索模型和检索方法, 对于深入研究面向社会化媒体检索意义重大。本文以拥有广大用户群的微博平台为例, 选取国内4大微博平台, 即新浪微博、腾讯微博、网易微博和搜狐微博, 探讨平台中对象内的用户名、发布微博和原始微博三个文本特征, 选择质量因素描述能力和辨别能力作为衡量标准, 从而揭示各平台中文本特征的质量对检索效果的影响。
实验可得到以下结论: 各平台中的描述能力和辨别能力对检索性能产生正向影响。4大平台特征的描述能力和辨别能力的不同导致分类效果的不同。其中, 用户名特征对分类效果的影响最小, 其辨别能力在新浪平台的分类效果较好。发布微博和原始微博的描述能力对分类的影响较大, 而在腾讯微博中原始微博特征的辨别能力分类效果较好。综合各特征的分类效果整体上优于单独考虑各特征的分类效果, 且权重策略FF*IFF-的效果最好, 尤其在腾讯微博中表现的最为明显。
对微博特征质量进行分析的必要性在于: 通过对各平台三类特征质量的分析, 可更好地揭示各种特征对检索效果影响的重要程度, 有助于研究者对各平台特征作用的深入理解。通过每种特征的重要程度, 赋予每种特征合理的权重, 才能从根本上提高社会化媒体平台的检索质量。本文的研究存在以下不足: 微博中的对话回复、粉丝数、关注数等由用户本身产生的社会关系并没有考虑在内, 只是对对象内的文本因素进行了探讨, 同时对于语义研究中的特征一词多义或者同义词因素并未涉猎。这些问题都是今后进一步深入研究的内容。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|