{kind=link}
{kind=link}
中图法与DDC类目自动映射研究*
[张爱民1 , 贾君枝2  , 郝倩倩
, 郝倩倩3 ]
, 郝倩倩|
|


作者贡献声明:
张爱民:设计研究方案,进行算法实验;
贾君枝:提出研究思路, 修改、修定论文;
郝倩倩:起草论文。
【目的】研究中图法与DDC类目自动映射的问题,通过实现两者的互操作以达到集成检索、浏览和下载跨语言、跨地区的信息资源的目的。【方法】基于人工匹配映射的数据,研究基于特征集、类目匹配规则、类目关系、书目记录的语义匹配算法。【结果】实验证明,将近80%的类目与人工映射结果的数据相同,一定程度上提高了自动映射的准确性。【局限】仅基于人工映射经验提出基于特征词集的类目相似度计算,尚未实现语义层面的精确计算。实验数据局限在理学类目领域,未对其他领域的类目特征详细研究。【结论】综合考虑类目的含义受类名、类目注释、主题词、上下位关系等多种因素影响而提出的自动映射算法,相比当前主要考虑单一方面的要素而言,具有客观性和全面性。
[Objective] Study the problems of automatic mapping aiming to realize integrated retrieval, browsing, downloading information cross regions and language through classification interoperation. [Methods] Discuss semantic similarity algorithm considering characteristic sets, category matching rules and semantic relation based on artificial mapping data. [Results] Prove that 80% categories are the same as the results of artificial mapping in the experiment. [Limitations] The similarity of categories based on characteristic sets, is short of matching of semantic operation. Also is only in the field of science, it is necessary to apply in other fields in the future. [Conclusions] The algorithm is considering comprehensively category names, notations, subject vocabularies, and semantic relations which define connotation and denotation of concepts, comparing to the existing limitation of relying solely on the category names matching method.
分类法的类名、主题词、注释、语义关系都是类目的组成部分,其共同规定了类目的具体内涵和外延,而且每个因素所发挥的作用大小有很大的差别。由于类名直接解释类目内涵,因此最具有话语权。匹配类目时应首先参考类目名称的语义相似度。类目的内容注释也是类表本身的组成部分,起到解释类目的作用。主题词揭示了类目所对应的主题词集合,一定程度上限制了类目的外延,类目间的语义关系明确了类目所在的语境信息,这些信息都将是实现匹配时考虑的重要因素。
目前单纯依靠某一方面信息,尤其是类名信息进行计算机匹配映射是当前研究者研究类目映射的关注点。如UMLS[ 1]作为超级叙词表,集成140多种生物医学受控词表、术语表、分类表、专家系统中的词汇、词典及工具性词表,将同一概念的各种名称(同义词)和形式(单复数、形容词等)建立联系。欧盟Renardus项目[ 2]将DDC作为一个全局检索语言,各个本地网关的分类法作为局部检索语言,实现各个局部到全局的映射。OCLC实现的LSCH和DDC的映射是采用的同现映射类目匹配方法。戴剑波等[ 3]利用计算类目概念的语义相关度,以实现类目自动匹配。此外,除了针对DDC和中图法的映射研究外,周林志等[ 4]以实验为基础,提出基于词汇相似度实现《国际专利分类法》(IPC)和中图法的映射等。这些研究明显具有一定的局限性,正如笔者所研究的理学类目人工映射数据表明,依据类名、主题词、注释信息实现匹配的分别占总类目的31%、13%、8%[ 5]。将近有50%左右的类目需要借助于语义关系、书目记录等其他信息完成匹配。如果单一地依据某一种信息来实现两部分类法的准确匹配,其准确率很明显受到影响。
基于此,本文旨在提高映射结果的准确性,认为分类自动映射系统应依据多重信息,结合多种算法,考虑多种因素的综合作用。DDC是国际上应用最广的分类法,是实现国内分类法与世界接轨的最优选择。随着国际化趋势的推进,英语成为使用最广泛的语言。解决多语言检索首先应考虑中英文一站式检索。在此背景下,本文研究DDC与中图法(简称CLC)的映射问题,通过实现两者的互操作以达到集成检索、浏览和下载跨语言、跨地区的信息资源的目的。研究旨在基于已完成的人工匹配映射的数据,充分考虑类名、主题词、注释、语义关系等多种信息的贡献度,研究自动映射算法,以改进已有的自动映射算法,最终提高两部分类法映射的准确性。
DDC和中图法都是体系分类法,类目按照学科进行组织,虽然依据的学科划分原则不同,但是从总体上看,理学类目二级类目下各学科能够较清晰地体现出一致性。同时人工匹配数据显示,理学类目中跨学科分布的仅占6.95%。因此,为提高匹配的效率,有必要先在学科之间匹配,再计算学科内特征词相似度。尤其考虑到DDC和中图法中都存在一些通用性类目名称,名称相同但含义差别明显,如540.1 和530.01 类名都是Philosophy and theory(哲学和理论),在对应学科内匹配无疑会减少进一步辨别的难度。
DDC和中图法中每一条类目信息都是一个独立的对象,每个对象由类名(Terms_ClassName)、注释(Terms_Note)、主题词(Terms_Thesarurus)、上下位语义关系(Terms_Depth)表示,其分别由若干个特征词所组成的特征词集表示。
因此,首先需分别对类名、注释、主题词中的特征词进行相似度匹配,每一次匹配过程满足指定条件时,明确其匹配类型。匹配类型包括等价关系(exactMatch)、包含关系(broadMatch)、包含于关系(narrowMatch)、相关关系(relatedMatch)。在此基础上考虑基于类目规则、类目关系的匹配,最后依据书目记录结果,对依据类名、注释、主题词以及类目关系匹配无法找到匹配类目的,找到其可匹配的类目,并对已经实现匹配的类目进行校验,实现如图1所示。基于书目记录库,以DDC类号为检索词,一个类号对应多条书目记录,筛选这些记录中包含CLC no.的匹配数据,统计出一个DDC no.对应的CLC no.。如果50%对应同一个CLC no.,则检验匹配数据库中两类号是否已建立匹配,若匹配则校验通过,否则做校验未通过标记,并添加匹配CLC no.。存在较多的是一个DDC no.对应多个CLC no.,这时需要统计对应数据所占的比例,对与DDC no. 匹配大于20%的CLC no.类号检验是否已经匹配,若未匹配,添加匹配记录,反之做校验通过处理。
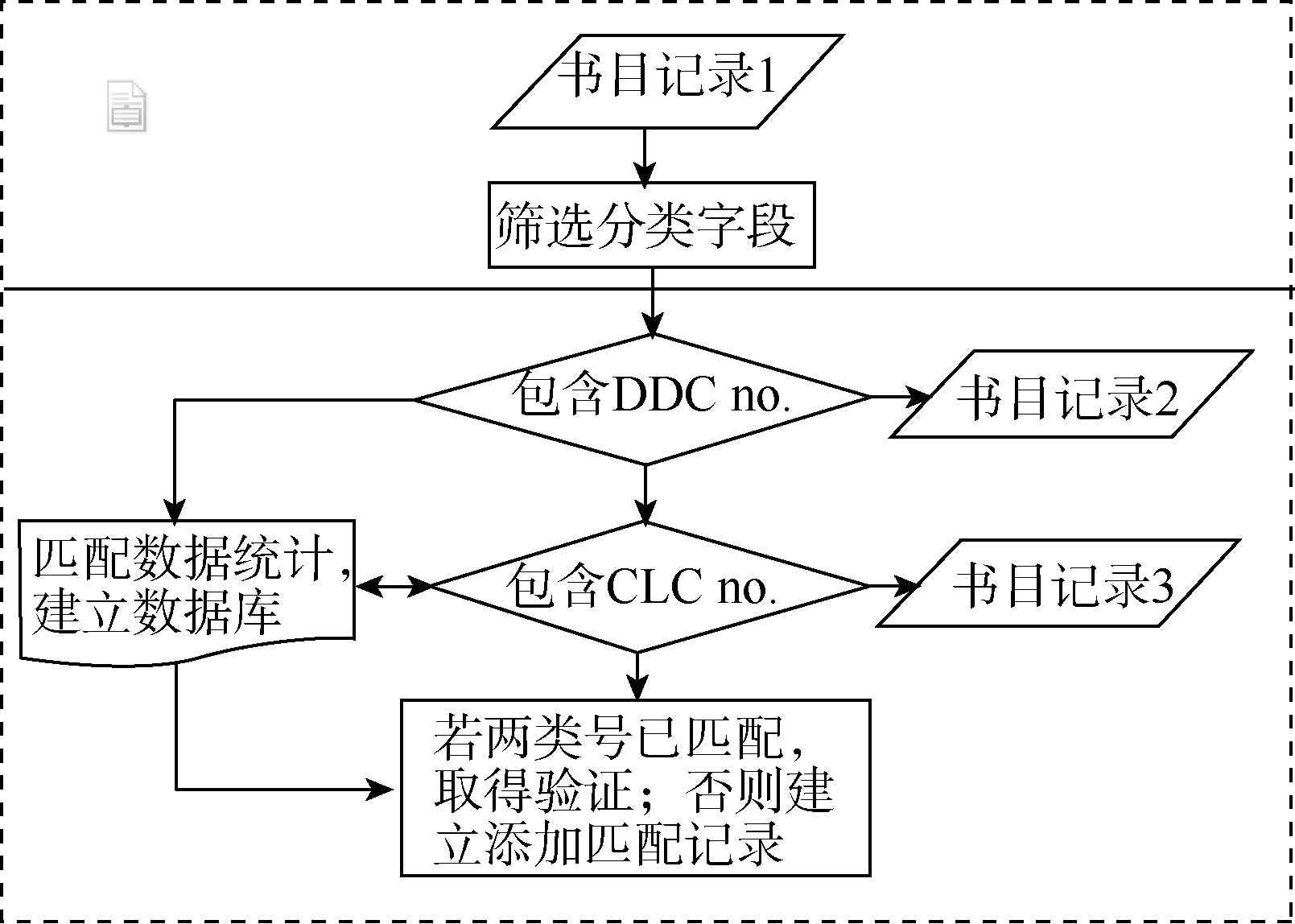 | 图1 书目记录自动匹配流程图 |
停用词是指在分类表匹配时不影响类目特征的词,在注释中表现为没有实际意义的虚词和类别色彩不强的中性词。TF是一种简单的评估函数,其值为训练集中此单词发生的频率,认为一个词在训练集中大量出现时,通常认为是噪声词[ 6]。基于TF评估函数,本文选取前11个高频词作为停用词,如表1所示,并依据哈尔滨工业大学中文停用词表确定了25个停用词,(合计36个停用词汇),如表2所示。
| 表1 基于TF评估函数值的停用词 |
| 表2 中文停用词表中类目注释停用词 |
类目、主题词本身经过规范化处理,参照特定的类名规范标准确定,其特征词抽取本着“长度最大”原则。类名的主要表现形式一般有单词、词组或具有偏正关系的短语。中图法和DDC的类目采用大量的组合类目形式来表达一些复杂概念,这些概念由两个或两个以上的语词组成,并通过不同的连接符或连接词进行组合,以表达复合概念的类目,DDC和中图法分别采用连接符等符号表示其含义。中图法和DDC中组合类目的比例各自为总类目的16.33%和30.20%[ 7],可见在两部分类法中组合类目都占据很大的比重,因此抽取特征词时应考虑这些关系的表达,尤其是并列关系、属分关系、主题交叉关系。
类名选词多为学术名词,标准化、规范化、简短化是DDC和CLC类目名称的共同特征。分词工具在分词时仍然粒度较小,不适合类目名称的处理。因此,在类目名称处理时不用分词工具进行分词,需将停用词去除后,单一名称的类名直接作为特征词,组合类名去掉组合符号,涉及到组合类目的限定关系词,一些组合类目如“岩石的属性,成分”,其中“成分”单独作为并列类目没有意义,因此将此并列类目处理成“岩石的属性、岩石的成分”形式。
两部分类法中,注释的形式基本相同,均包含形如“计算尺、电子运算器等的使用入此。”、“包括一般环论、理想子环、结合环、非结合环、局部环、模论等。”的内容注释, “参见B815、O211。”的参见注释, “<3版类名:半序集合和格论>”的类名修改注释,“依世界地区表分。”的复分注释,其格式固定,种类有限,便于特征词的抽取。匹配时所依据的注释主要指内容注释和类名修改注释,其他类型的注释在特征词抽取时不作考虑,本文所处理的主要形式是“……入此”或“包括……”。特征词抽取之前首先应对注释进行处理,去掉其他形式的注释,只留下内容注释。应去除的注释类型有“…入+类号”、“参见…”、“…见+类号”、“…入有关各类”、“<…>”。最后,使用分词工具分词[ 8],去除停用词表的停用词汇,得到每个类目注释的特征词。
本文将每一个类目都视为一个独立的概念,由三类特征词集和两个因子解释其内涵和外延。因此,可将类目表示为:
Item_C = {<Terms_ClassName> <Terms_Note> <Terms_Thesaurus> , <Depth_C> , <Relation> }
Terms_ClassName、Terms_Note、Terms_Thesaurus分别表示类名、注释、主题词的特征词集;Depth_C表示类目在分类表中的层次;Relation表示类目上下位关系。匹配过程中,不仅需要考虑特征词集的相似度,类目层次Depth_C也起到关键性的作用。类目层次的深浅决定类目的内涵和外延的大小。因此,将映射匹配计算分成类目层次对语义相似度的影响和特征词集相似度对映射的影响两部分。
C1和C2的相似度是通过计算其各个元素之间的相似度得到的,即Terms_ClassName1和Terms_Class-Name2,Terms_Note1和 Terms_Note2,Terms_Thesauru1和 Terms_Thesaurus2的相似度SIM。SIM由组成这些项目的特征词决定,可以通过计算词形和语义方法度量。当两个特征词的词形相似度大于阈值N时,此时无需计算语义相似度。特征词集的语义相似度计算效率和精确度直接决定着两类表匹配的实现程度。语义相似度计算时应坚持以下原则:要量化,需基于人工映射的数据,经统计分析和推理论证给出较准确的阈值;计算相似度的方法应该简单、方便;应充分利用和体现类表的结构及组成特征;特征词集相似度是对称的,相同的两个类目不会因为先后顺序不同影响相似度,即Sim (C1,C2) = Sim (C2,C1)。
(1) 特征词相似度计算算法
考虑到综上所述因素及计算原则,本文将采用通过词汇之间的词形相似度SimTerms(T1,T2),从而给出精确的特征词集的相似度计算公式如下:
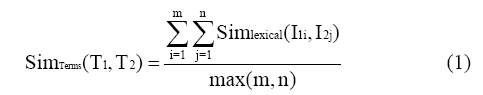 |
其中, 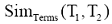
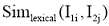
(2) 类名特征词相似度计算算法改进
在对各领域类目处理时发现,通过控制m、n大小,可以基本确定依据类名匹配的匹配类型。因此,将特征词相似度计算公式进一步规范,如下所示:
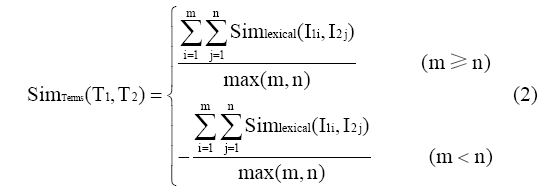 |
正负号确定的是m和n的大小,当m>n时,类名1的特征词T1包含的概念多于类名2包含的特征词T2,概念范围类目1大于类目2。因此,建立类目1到类目2的broadMatch,反之建立narrowMatch。
体系分类法具有等级体系结构,每一级类目由其上类逐级细分而来,形成树形结构层次。每一个类目所处的深度称之为类目层次,记作Depth(C)。中图法的基本大类类目层次记作1,即Depth(O 数理科学和化学)=1,其他依次类推。分类法中每个类目之间的语义相似度计算不涉及类目距离,即类目结点之间的距离,而受类目层次的影响。两个类目分别在不同的分类法中的不同位置,即类目层次和类目关系都可能不同,其所处深度的不同直接影响类目的映射关系。
类目C1、类目C2分别来源于CLC和DDC,其类目层次分别为Depth(C1)、Depth(C2),定义类目层次差异度公式如下:
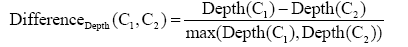 | (3) |
其中, 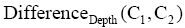
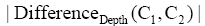

可以看出,类目匹配时,类目层次差异度的正负值对于类目匹配的类型具有重要的作用。
DDC中存在一些特殊的类目,不同学科中类目名称结构一致,含义相似。人工映射中,需建立统一的映射规则以确保映射的一致性。本文将对标准细分、专类复分类目、DDC中人物类目三种情况按照映射规则进行计算机处理,即遇到此类型的类目则直接获取其上位类的映射结果,建立broadMatch匹配类型。
替代类目和停用(迁移)类目的处理。DDC、中图法中替代类目、停用(迁移)类目都有明显的标识。如[P24]测绘仪器是替代类目,526[.0221] Map drawing属于停用(迁移)类目,在确定类目的类型后,将替代前后或停用前后的类目建立等同关系的匹配。若其中一个类目已建立了匹配,则另一类目自动建立相同的匹配关系。
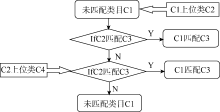
依据人工数据统计发现,类名、注释、主题词、类目规则4个属性可完成约60%的类目匹配,大约有40%的类目需借助于语义关系进行处理。对于未匹配的类目作如图2所示的处理,找到未匹配类目的上位类;如果其上位类已找到映射关系,则直接与其上位类的映射类目建立匹配;如果上位类也未匹配,则查找其上位类的父类,依次类推。
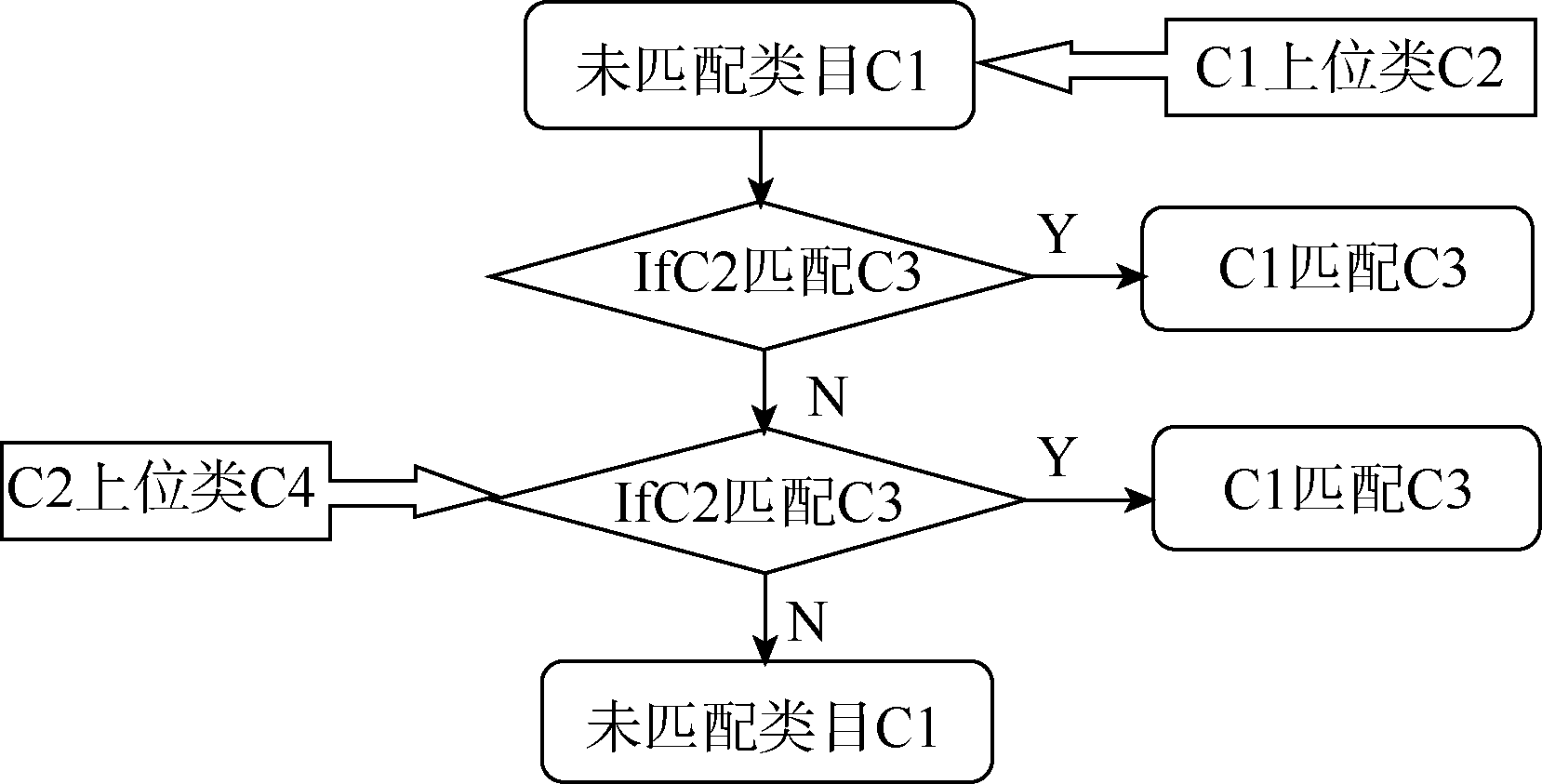 | 图2 类目关系的匹配原理 |
本文选用数学领域的类目进行实验,类目共有357个。由于存在一对多的映射,因此共实现匹配数目为492个。
遍历两类表类名特征词,计算类目特征词相似度,理论上特征词相似度不为零的两类目均具有可匹配性。当特征词相似度 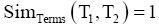
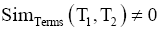
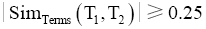

| 表3 数学领域内部分类目类名语义相似度计算结果 |
注释参与类目匹配时,特征词相似度计算不仅局限于两个分类表的注释特征词的比较,同时注释特征词也要和另一分类表的类名特征词匹配计算。实验通过对数学领域类目匹配结果进行分析,其中通过注释实现匹配的类目中13.21%的类目是通过DDC注释和CLC类名特征词之间计算实现的,77.35%是通过DDC类名和CLC注释计算实现的,另外仅仅9.44%是两个分类表注释特征词之间计算实现的。三种情况特征词相似度的平均值为0.4938,最小值为0.2。因此,DDC类名特征词和CLC注释特征词、DDC注释特征词和CLC类名特征词相似度高于0.2的类目匹配类型分别暂定为broadMatch、narrowMatch,DDC注释和CLC注释特征词相似度计算结果大于0.2的类目匹配类型暂时标注为relatedMatch,最后依据类目层次差异度DifferenceDepth(C1,C2)和书目记录进行验证。
中图法的主题词来源于汉语主题词表,对应词汇非常全面。DDC的主题词来源于LCSH,主题词较少,因此实现匹配所占的比重不大。主题词匹配的实现和注释词类似,但匹配处理不尽相同。
(1) 主题词和类名的匹配。计算机匹配时将一个分类表的类名特征词与另一分类表的主题词的特征词进行遍历,计算其相似度。在对数学类目进行分析时,此种情况占主题词匹配的59.7%。
(2) 遍历两个分类表的主题词特征词,计算其相似度,若二者交叉相同,则建立relatedMatch,等待进一步确认,相关映射占数学学科主题词匹配的40.3%。匹配中主题词特征词相似度值多分布于较小的数字区域。因此,在匹配中不设置临界值,相关类目即可建立匹配关系,待下层类目关系及书目记录匹配。
依据类目规则的匹配,从DDC类目中识别出14个类目,占总类目的2.81%。75个类目通过类目关系与上位类建立broadMatch类型。书目记录主要起到验证类目匹配和补充类目匹配的作用。实验采用中国国家图书馆OPAC书目数据库和OCLC提供的书目数据库作为数据来源。通过书目数据库解决了跨学科领域匹配的问题,例如,“510.92 Mathematicians数学家”在原来匹配的基础上增加了“K826.41数学家”匹配类目,弥补了按学科进行相似度计算的不足。
匹配过程中,基于类名、注释、主题词的匹配在计算时已基本确定匹配类型。数学类目74.90%已确定匹配类型,exactMatch、broadMatch、narrowMatch 分别占32.26%、55.65%、12.09%。其余25.1%的类目通过类目规则、类目关系匹配。这些匹配中匹配类型再次通过类目层次差异度DifferenceDepth确定。数学类目中未确定匹配关系的匹配中经过DifferenceDepth(C1,C2)确定了匹配类型,78.20%类目和人工匹配的数据一致。对于匹配类型确定的类目,需用DifferenceDepth(C1,C2)进行检验。数学类目中broad Match的匹配中,当 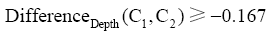
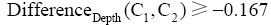
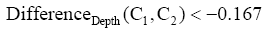
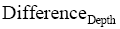
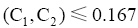
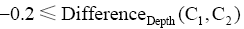

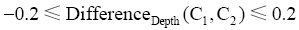
考虑到分类法中的类名、主题词、注释、语义关系及其书目记录信息都或多或少地限制着类目的含义。本文以DDC和CLC映射为研究对象,提出了综合考虑以上信息的自动映射匹配算法。实现结果表明,90%的类目可以找到映射,优于文献[9]设计的基于书目记录的自动映射系统,其有大约60%的类目匹配,80%左右的类目与人工映射结果的数据相同,一定程度上证明该自动映射算法能够提高匹配映射的准确性。本文基于人工映射经验数据,提出基于特征词集的类目相似度计算方法,尚未实现语义层面的计算,同时没有考虑各种类型特征词对相似度的贡献差异度。书目记录的验证中,本文没有就出现的各种不同情况进行详细分析,如书目记录中不同时出现DDC、CLC类号时会给自动映射的实现带来困难等,此类问题将在今后的研究中进一步深入。分析实验数据局限在理学类目领域,未对其他领域的类目特征详细研究,因此在实现的过程中仍需结合各学科类目结构和特点进行分析。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|