{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
一种基于自组织映射与径向基函数预测补值的协同过滤推荐方法*
[薛福亮1  , 张慧颖
, 张慧颖2 ]
, 张慧颖|
|


作者贡献声明:
薛福亮: 提出研究思路, 设计研究方案;
薛福亮, 张慧颖: 进行整个实验过程的设计; 负责数据采集、分析和处理, 其中SOM与RBFN神经网络的预测补值主要由薛福亮完成, 平均绝对误差、F-Measure指标的计算主要由张慧颖完成;
薛福亮: 论文起草, 初稿的完成;
薛福亮, 张慧颖: 论文修改及最终版本修订。
【目的】基于自组织映射与径向基函数神经网络对协同过滤推荐方法进行改进, 提高推荐质量。【应用背景】针对协同过滤推荐方法存在的稀疏性问题, 利用神经网络对缺失评价数据进行预测补值, 在此基础上提出一种新的提高推荐精度的解决思路。【方法】基于稀疏用户评分矩阵, 应用自组织映射神经网络对相似用户进行预聚类, 利用同一聚类簇内用户的相似性进一步应用径向基函数对稀疏的用户评分矩阵进行补值处理, 得到消除稀疏性后的完全评价矩阵, 最后基于完全评价矩阵应用协同过滤技术实施推荐。【结果】通过平均绝对误差与F-Measure两个指标进行实验评价, 结果表明该方法与其他主流推荐方法相比, 无论在推荐精度还是推荐相关性上都更为有效。【局限】本文提出的方法仅在MovieLens公开数据集上进行实验测试, 还需在其他数据集上进一步检验。【结论】在一定程度上解决了协同过滤推荐存在的稀疏性问题, 同时对冷启动与可扩展性问题的解决具有较好的指导意义。
[Objective] To improve recommendation quality of collaborative filtering recommender method based on Self Organizing Map(SOM) and Radial Basis Function Neural Network (RBFN). [Context] Aiming at sparsity problems in collaborative filtering method, this paper proposes to predict missing evaluation values with artificial neural networks, and puts forward a new solutions to improve recommendation accuracy. [Methods] This paper puts forward pre-clustering similar users based on user rating matrix with SOM neural network. Based on the similarity of users in the same cluster, RBFN is used to fill missing values in sparse rating matrix. After that, collaborative filtering is used to generate recommendation based on complete rating matrix. [Results] Compared with traditional mainstream filtering method, MAE and F-Measure experimental results show that the proposed method is more effective both in the accuracy and relevance of recommendations. [Limitations] The proposed method is only tested on the public data set from MovieLens, and it need further examination in other data sets. [Conclusions] The recommender method proposed in this paper solves the sparsity problem in collaborative filtering recommendation to a certain extent, and it is also a guidance to solve the cold start and scalability problems.
协同过滤推荐为顾客发现具有最相似购物偏好的顾客, 并依据顾客之间购物的相似性进行交叉推荐, 该方法被提出以来在很多电子商务网站取得了成功的应用, 是目前最为成熟的一种推荐方法。协同过滤在实际应用中最大的问题在于因为顾客不愿意留下评价信息或者新产品没有足够的评价数据, 导致相似顾客的聚类效果不佳, 从而产生稀疏性以及冷启动等问题[ 1]。评价数据的稀疏会造成相似用户的聚类不够准确, 在不准确的同一聚类用户之间进行交叉推荐会严重影响协同过滤推荐系统的推荐质量, 甚至会产生错误的推荐。同时如果用户没有足够的评价数据会导致无法确定用户所属聚类, 进而无法得到该用户的推荐, 产生冷启动问题。解决此问题通常有两种方法: 进行缺失评价数据的补值或缺失数据的预测。很多学者从不同的角度提出了自己的观点, 并取得了较好的效果。在此基础上, 笔者利用自组织映射(Self-Organization Mapping, SOM)与径向基函数(Radial Basis Function, RBF) 神经网络, 提出了一种新的缺失评价数据的预测和补值方法, 并通过实验验证了该方法的可行性。这是一种新的数据稀疏性的解决思路。
在数据补值方面, Schafer等[ 2]认为顾客历史交易记录、注册信息、顾客评论等可以作为顾客对产品评分的有益补充, 进而提出了对顾客偏好进行补值处理的思想以消除评价数据的稀疏性。Pazzani[ 3]认为顾客个人社会属性信息能够反映出顾客的购物兴趣, 提出使用顾客个人社会属性信息对顾客偏好进行补值处理, 但采用个人社会属性信息可能会涉及到用户的隐私。除此之外, 顾客隐式浏览行为、产品关联规则、Web日志等信息蕴涵着丰富的顾客偏好信息[ 4], 可以通过Web数据挖掘技术获得隐性偏好。在此基础上, 李晓昀等[ 5]提出了一种隐性评价数据的分析处理方法, 并提出了一种基于隐性偏好的电子商务推荐系统, 如何利用隐性评价数据对用户显性评价补值是该方法的最大挑战。在数据预测方面, RFM(最近购买时间, 购买频率, 购买金额)指标[ 6]被提出用来度量客户终身价值(Customer Lifetime Value, CLV), 从而可以让商家发现更有价值的客户, 基于客户终身价值的推荐方法就是在此基础上产生的。同时基于产品的相似性来预测顾客对其未评价产品的偏好[ 7]也在数据预测方面取得了较好的成绩。这两种方法适用于产品的个数远远小于用户的数量, 而且产品的个数和相似度相对比较稳定的场景中。陈逸等[ 8]进一步提出了顾客相同评分矩阵的概念, 通过顾客相同评分矩阵中体现的相似性关系对未评价产品进行偏好预测。张慧颖等[ 9]也提出了可以基于用户之间的相似性进行缺失数据的预测处理, 从而尽可能消除稀疏性、冷启动问题。另外, Xue等[ 10]采用用户所属聚类评价均值对缺失值进行预测的方法取得了较好的效果。但这几种方法在大量评价数据下的数据训练阶段, 以及相似用户聚类阶段有较大的计算复杂度, 未考虑推荐算法扩展性问题。为解决此问题, 肖强等[ 11]提出了利用SOM神经网络进行Web用户聚类的尝试, 在计算复杂度方面取得了较好的效果。
以上研究一定程度地消除了稀疏性问题对协同过滤推荐的困扰, 但仍有很多值得研究的方向。目前协同过滤聚类算法多采用K均值聚类方法, 这种聚类方法对初值的依赖性过强。另外, 该算法具有较高的计算复杂度, 会降低推荐效率。在数据补值方面, 现有研究多采用同一聚类簇用户评分均值对缺失评分进行补值。神经网络在聚类与缺失值预测方面已经在其他领域有了非常成熟的应用, 在此背景下笔者尝试使用SOM基于用户评分对相似用户进行聚类, 基于聚类结果应用经典的RBFN对缺失评分值进行训练补值, 并依据补值后的评分数据进行推荐。使用公开的测试数据集(MovieLens)实验发现, 其最终推荐质量比现有的聚类与补值算法效果更好。另外, SOM聚类能够和RBFN无缝结合, 其聚类结果可以直接作为RBFN的期望输出。经过训练成熟后的网络可以直接处理新产生的用户评分数据, 并进行聚类输出与补值。相对于K均值聚类算法的新数据的增量聚类与补值, 其计算复杂度有一定优势。本文利用SOM与RBFN神经网络对协同过滤推荐算法进行改进, 是解决协同过滤稀疏性问题的有意义尝试。
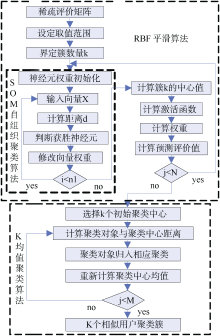
本文推荐框架共分为三部分, 如图1中三个虚线矩阵所示:
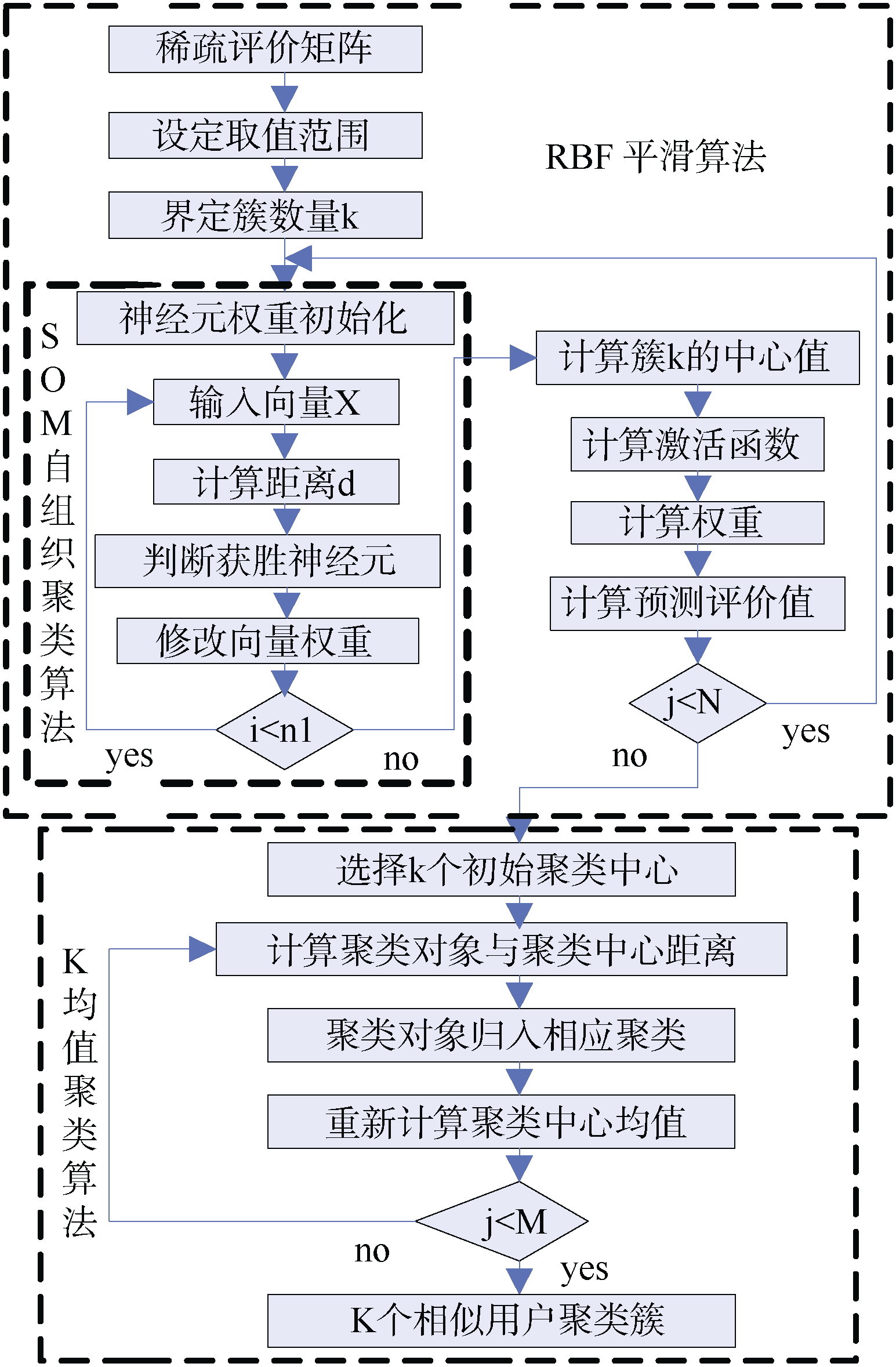 | 图1 本文推荐框架 |
协同过滤推荐方法从一个高稀疏评价矩阵中发现相似用户比较困难, 本文采用RBFN及SOM对稀疏的用户-项目评价矩阵进行补值处理, 从而得到去除稀疏性后的完全矩阵, 为后面的用户聚类提供完整的评分数据。
(1) SOM自组织聚类算法: 主要基于稀疏的原始用户评分矩阵进行相似用户预聚类, 其输出为k个用户聚类簇, 同一聚类内具有最大的用户偏好相似性。
(2) RBFN补值算法: 以SOM自组织聚类得到的k个聚类簇为基础, 基于同一聚类内的用户评分相似性对用户未评分项目的缺失数据进行补值处理, 得到尽可能消除稀疏性的完全评价矩阵。
(3) 协同过滤推荐算法: 基于消除稀疏性的完全评价矩阵利用经典的K均值聚类算法, 进行相似用户二次聚类, 利用同一聚类内用户偏好相似性实施交叉推荐。
下面首先对一些基本概念进行界定:
M个用户的用户集 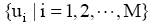
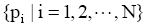
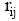
自组织映射神经网络是一个典型的非监督学习神经网络, 它根据输入样本数据自学习, 并进一步调整神经元权值进而聚类。本文利用自组织特征映射网络对相似客户进行聚类。利用同一聚类中客户兴趣特征的相似性, 进行客户未评分项目的评价值预测, 与客户评价均值[ 10]相比提高了预测值的准确度, 这是由于神经网络预测方法过滤掉了与当前用户兴趣偏好偏差较大的评价值。SOM聚类过程如下:
输入: 某项目的评分向量 
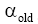
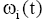
输出: 经过划分后的k个向量。
方法步骤:
(1) 对于每一个输出神经元j, 将其初始权重赋值为一个很小的随机数 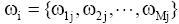
(2) 将某向量x输入网络;
(3) 计算距离 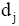
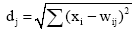 | (1) |
(4) 某个神经元k距离x最近, 则认为该神经元为获胜神经元;
(5) 在近邻范围内修改所有向量的权重:
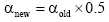 | (2) |
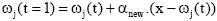 | (3) |
(6) 循环执行步骤(2)至步骤(5)共n1次。
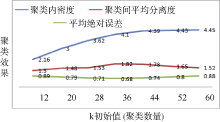
初始聚类簇k的数量初值的设定非常重要, k值过大会导致同一聚类内非相似用户过多, k值过小可能会导致大量用户无法聚类, 进而会对推荐质量有较大的影响。聚类效果通常用聚类内密度和聚类间平均分离度[ 11, 12]两个指标来衡量。聚类内密度是所有聚类集中数据点和中心的相似度, 值越高说明聚类效果越好, 其公式如下[ 11]:
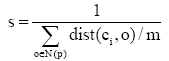 | (4) |
其中, 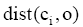
聚类间平均分离度是指不同聚类中心之间的差异程度的平均值, 平均值越大说明聚类的效果越好, 其公式如下[ 11]:
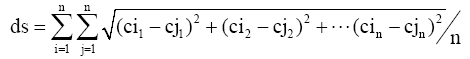 | (5) |
其中, 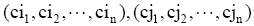
传统协同过滤推荐用户聚类k值一般设定在20-40之间, 笔者分别设定k(聚类数量)初始值为12、20、28、36、44、52、60进行SOM聚类, 并通过实验确定最优初始值, 实验发现在不同聚类数量下, 聚类内密度和聚类间平均分离度效果如图2所示。同时在MovieLens数据集中抽取固定稀疏度水平的测试数据, 分别设定k初始值为12、20、28、36、44、52、60进行SOM聚类, 进而进行RBFN预测, 并通过预测值与真实评分值平均绝对误差比较不同聚类数量设定对推荐结果的影响, 实验结果如图2所示。实验发现在该数据集下平均绝对误差与聚类间平均分离度在k=36时效果最优, 聚类内密度在k=36时趋向于稳定。
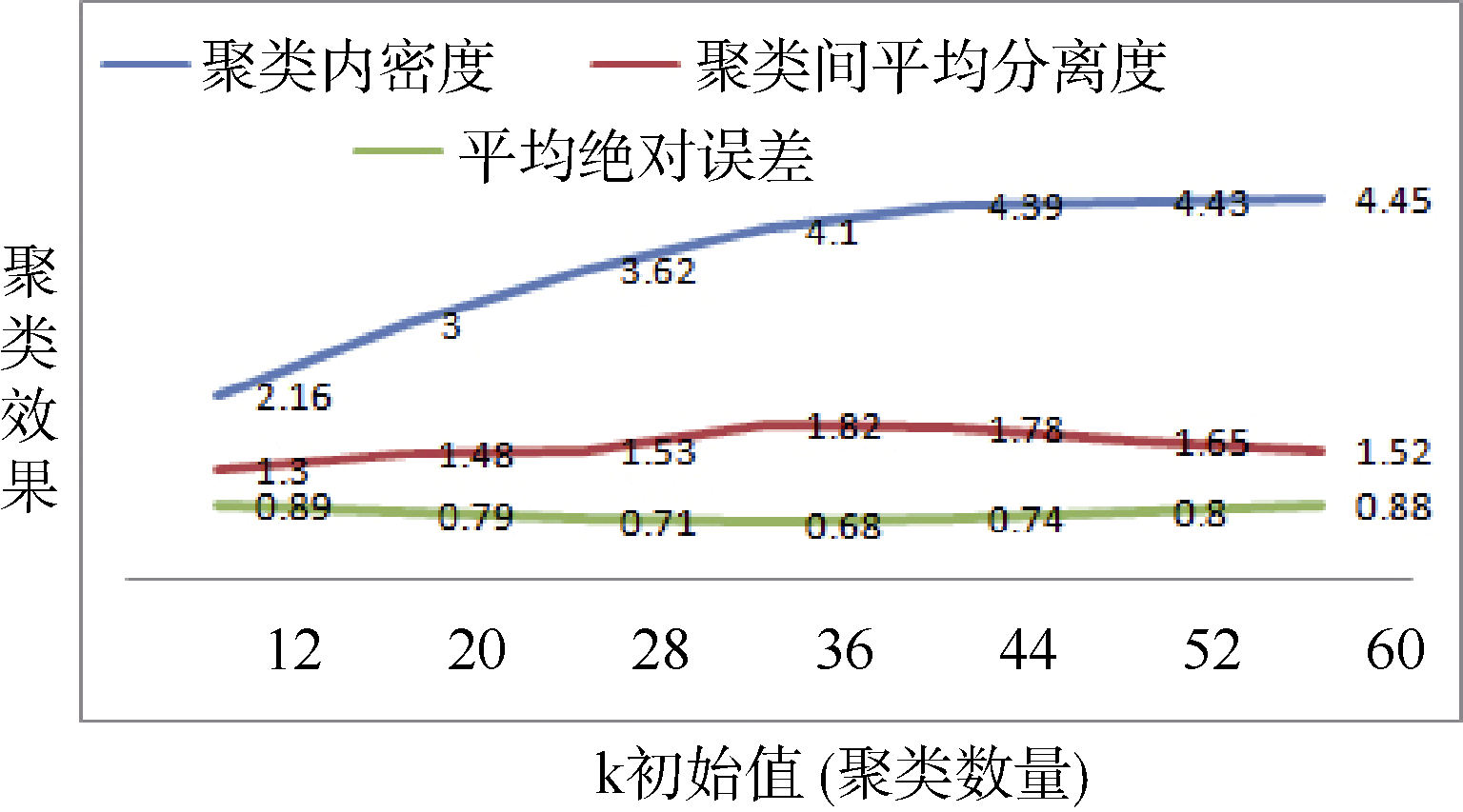 | 图2 k初始值对聚类效果及推荐结果影响 |
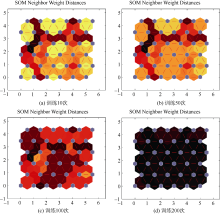
通过实验数据观测训练次数为10次时, 临近神经元距离情况如图3(a)所示, 直线连接的菱形代表具体神经元, 连线代表神经元间的连接, 神经元与神经元之间深浅不同的颜色表示神经元间距离的远近, 颜色越浅表示神经元间距离越近, 颜色越深表示神经元间距离越远, 观测训练次数为50次、100次、200次时, 临近神经元距离情况如图3(b)至图3(d)所示 :
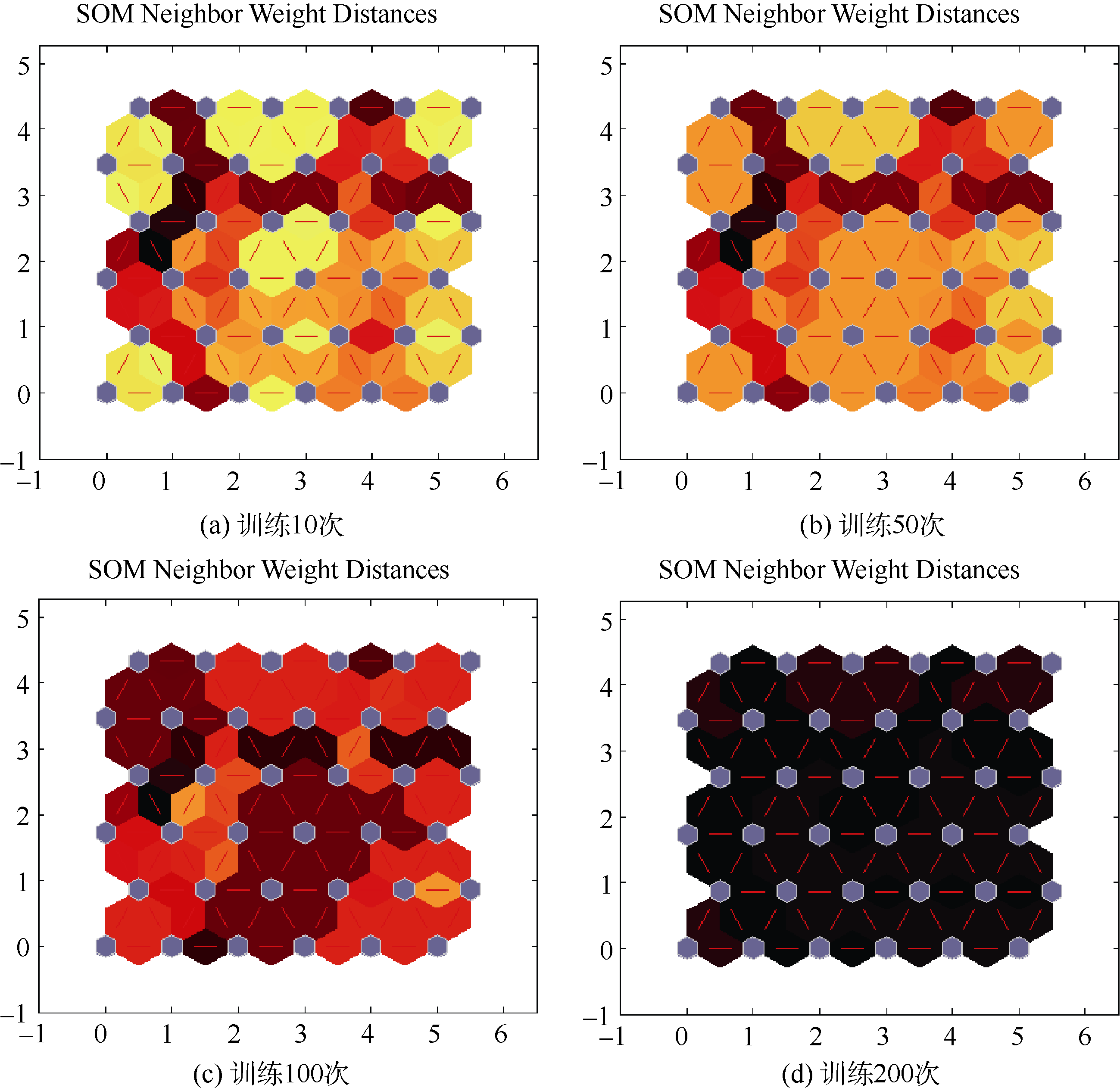 | 图3 临近神经元距离情况 |
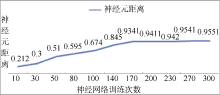
经过临近神经元距离情况发现, 训练次数为200时聚类细化, 并趋向于稳定, 其输出为36个神经元间平均距离达到最大, 不同训练次数神经元间距离如图4所示:
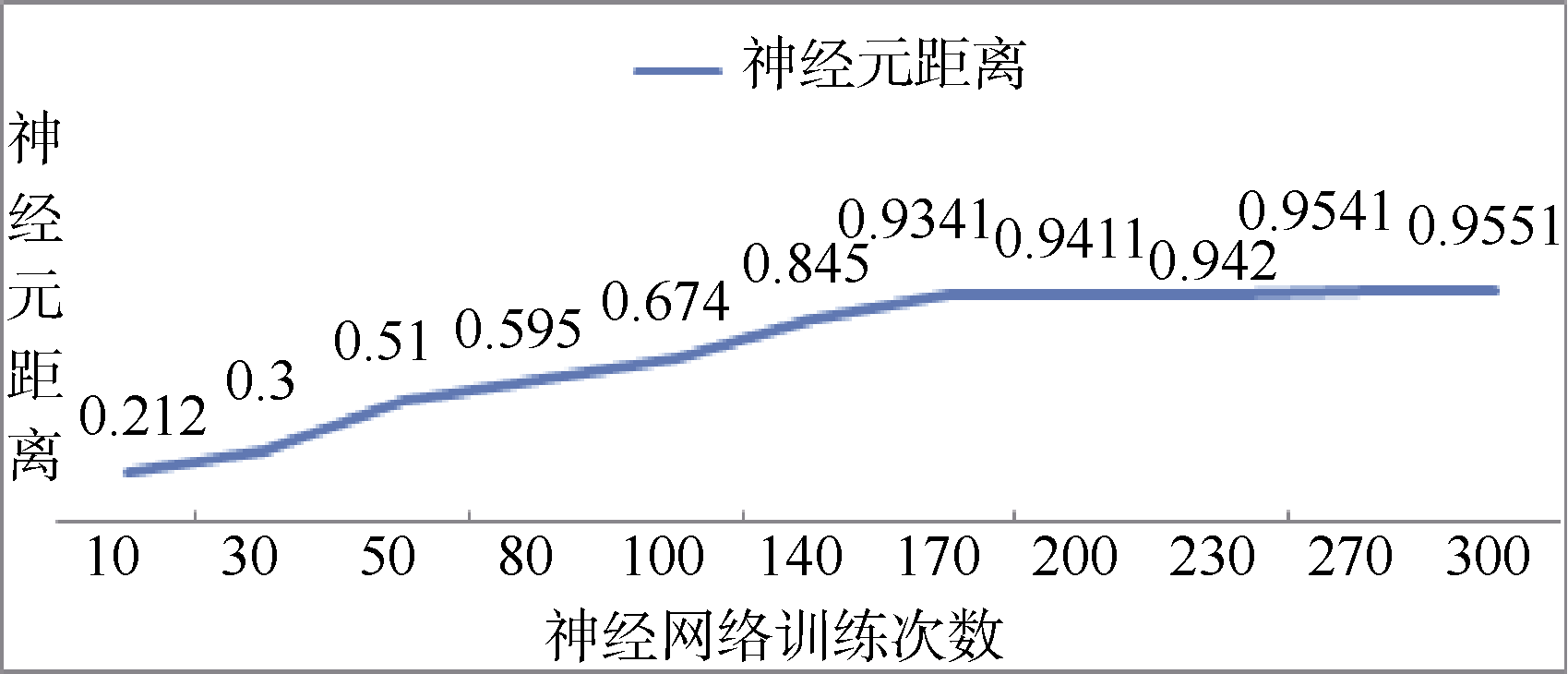 | 图4 训练次数与神经元平均距离变化曲线 |
RBFN神经网络是一个有导师网络, 本文仍然将用户对项目的稀疏评分矩阵输入网络, 某用户对于未评价项目的期望输出用该用户所属聚类簇内最近邻的中心值表示。
径向基函数的核心是要构建一个合适的输出函数[ 12]:
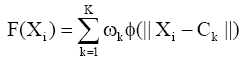 | (6) |
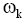
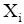
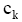
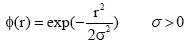 | (7) |
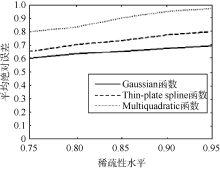
虽然高斯函数不是唯一的径向基函数, 但与其他函数相比有平滑性好、平滑不会失真、旋转对称性好等重要性质, 对评分数据的预测相比其他函数具有优势(见4.2节实验)。
RBFN神经网络补值处理过程如下:
输入: 稀疏评价矩阵 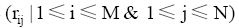
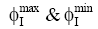
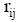
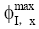
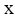
输出: 补值后的用户评价矩阵 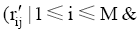
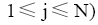
补值步骤:
(1) 设定取值范围 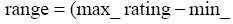
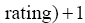
(2) 界定簇的数量k, 以使 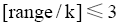
(3) for j=1 to N
①利用自组织特征映射网络, 可将某用户归入簇k。定义 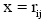
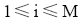
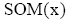
②计算簇k的中心值, 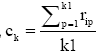
③当 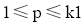
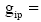
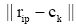
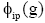
④利用伪随机权重函数如公式(8),计算权重 
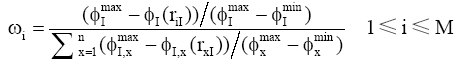 | (8) |
⑤利用公式(6)计算 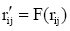
通过以上补值算法, 原始稀疏矩阵采用RBFN被处理为完全矩阵。
输入: 补值后的用户项目评分距阵, 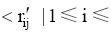
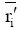
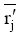
输出: k个聚类簇 
方法步骤:
(1) for i=1 to M; /*计算M个用户之间的相似性*/
(2) sim_count(i)=0;
(3) for j=1 to N 计算用户i和j的Pearson相关系数 if simi,j=1 then sim_count(i)=sim_count(i)+1;
(4) 鉴定Top k个相似用户作为k个聚类簇的初始用户;
(5) 将用户归入相应聚类簇中;
(6) 对M个用户循环计算步骤(3)至步骤(5)。
输入: 活动用户对项目评分, T表示待评分的项目, 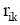
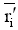
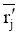
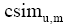
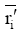
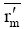
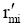
输出: 该用户的推荐
推荐步骤:
(1) 如果用户没有任何历史评分记录(冷启动问题), 用户所在聚类簇的Top T项目将会向该用户推荐。
(2) 如果用户已有历史评分记录, 将通过利用Pearson相关系数鉴定该用户积极和消极邻居簇[ 7]。
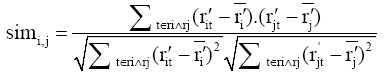 | (9) |
(3) 用余弦相关系数[ 8]鉴定聚类簇中的最积极邻居(最相似)和最消极邻居(最不相似)。
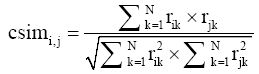 | (10) |
(4) 最积极邻居推荐集合赋值到集合X, 最消极邻居推荐集合赋值到集合Y。
(5) 计算 
本文实验采用MovieLens公开数据集作为该系统的实验数据集, 该数据集共有303 448客户注册, 有效评价记录1 548 678条, 不同种类电影293 455部。同时选择不同时间阶段的数据分别作为训练集和测试集。
对于稀疏性水平为0.75、0.80、0.85、0.90、0.95(步长值为0.05)不等的评价矩阵, 利用不同激活函数处理。实验结果表明Gaussian激活函数其平均绝对误差优于其他激活函数。不同激活函数其平均绝对误差如图5所示:
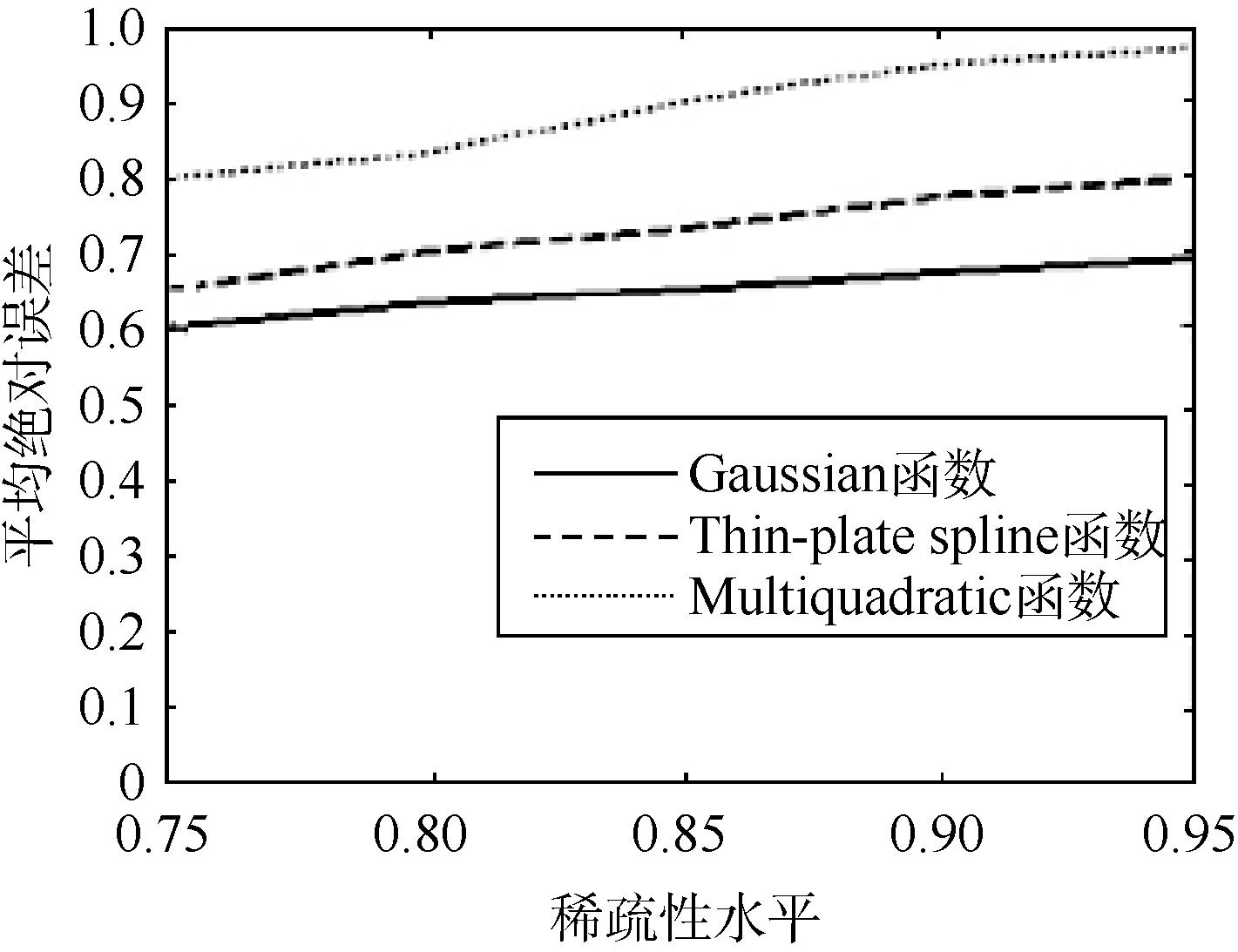 | 图5 平均绝对误差与稀疏性水平 |
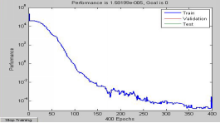
图6中横轴表示为神经元数量, 纵轴数据为神经网络实际输出与期望输出之间的差值。可以看到当神经元的数量超过250个时, 神经网络的输出与期望输出已经接近于0, 说明神经网络已经非常逼近期望输出。
 | 图6 网络输出与期望输出随神经元数量增加的差值变化 |
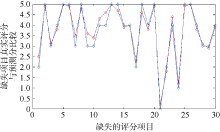
经过训练后的网络基本能反映该聚类簇内用户评分与期望评分的非线性关系, 利用训练好的神经网络对稀疏评价矩阵进行仿真预测, 从而获得未评价值的期望评分值。实验过程中, 笔者从原始评价矩阵中随机去除一些真实评分, 并将去除后的评分置为0作为缺失评分。经过神经网络预测补值后可以将预测的评分数据与原始真实评分进行比较。本文从经过神经网络补值的用户项目评价矩阵中抽取30个预测补值评分, 并与原始用户- 项目的评价矩阵中的实际评分值进行比较, 比较结果如图7所示。图中蓝线为原始真实评分数据, 红线为预测补值的数据。从比较结果可以看出, 预测分值与实际分值的误差基本控制在0.5分之内。可以看到神经网络的预测值具有比较好的准确性。
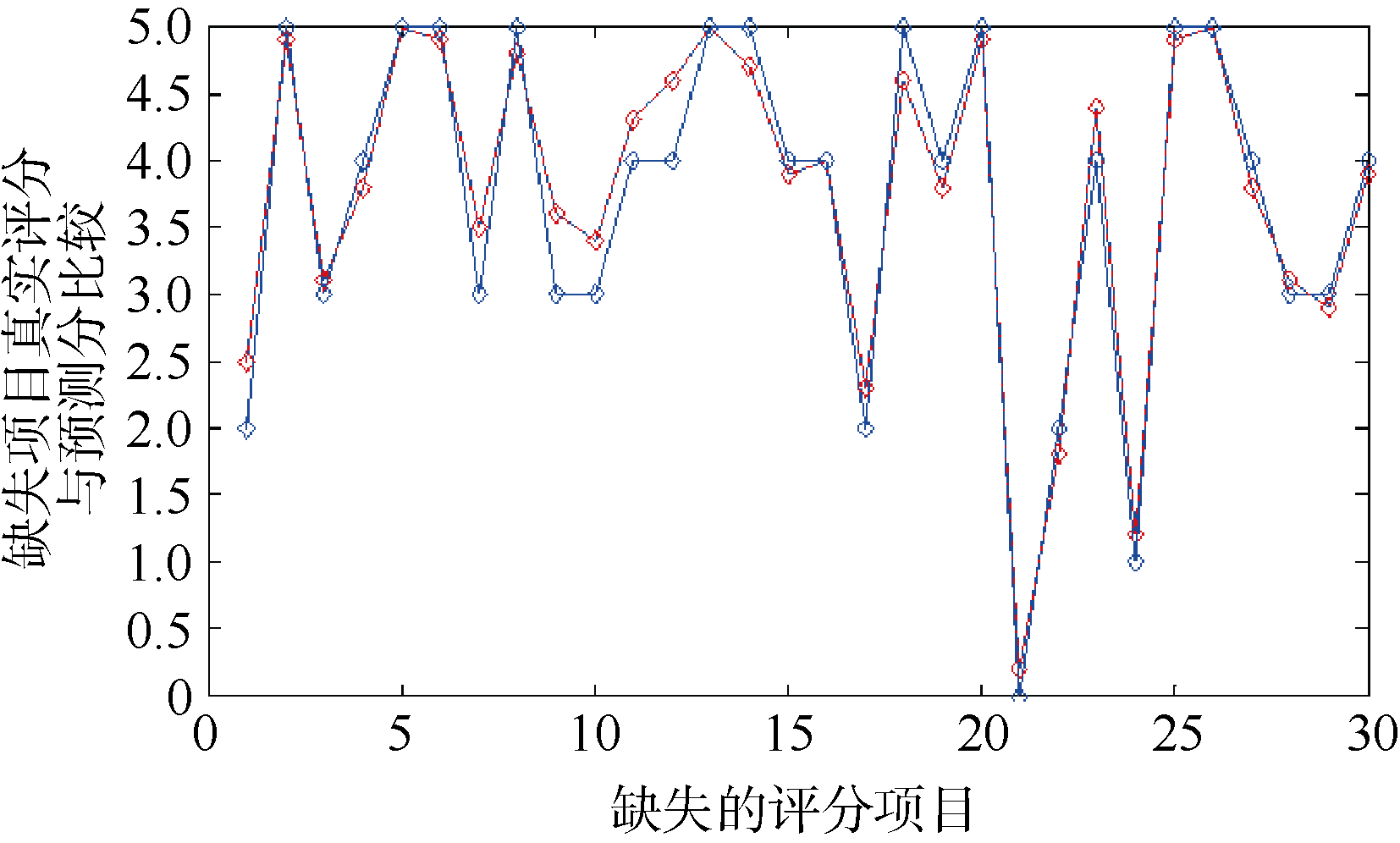 | 图7 预测评价值与实际评价值的比较 |
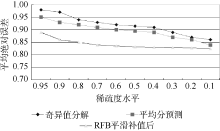
可用平均绝对误差(MAE)来评价预测与最终结果的接近度, 如下所示[ 9]:
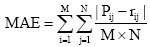
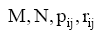
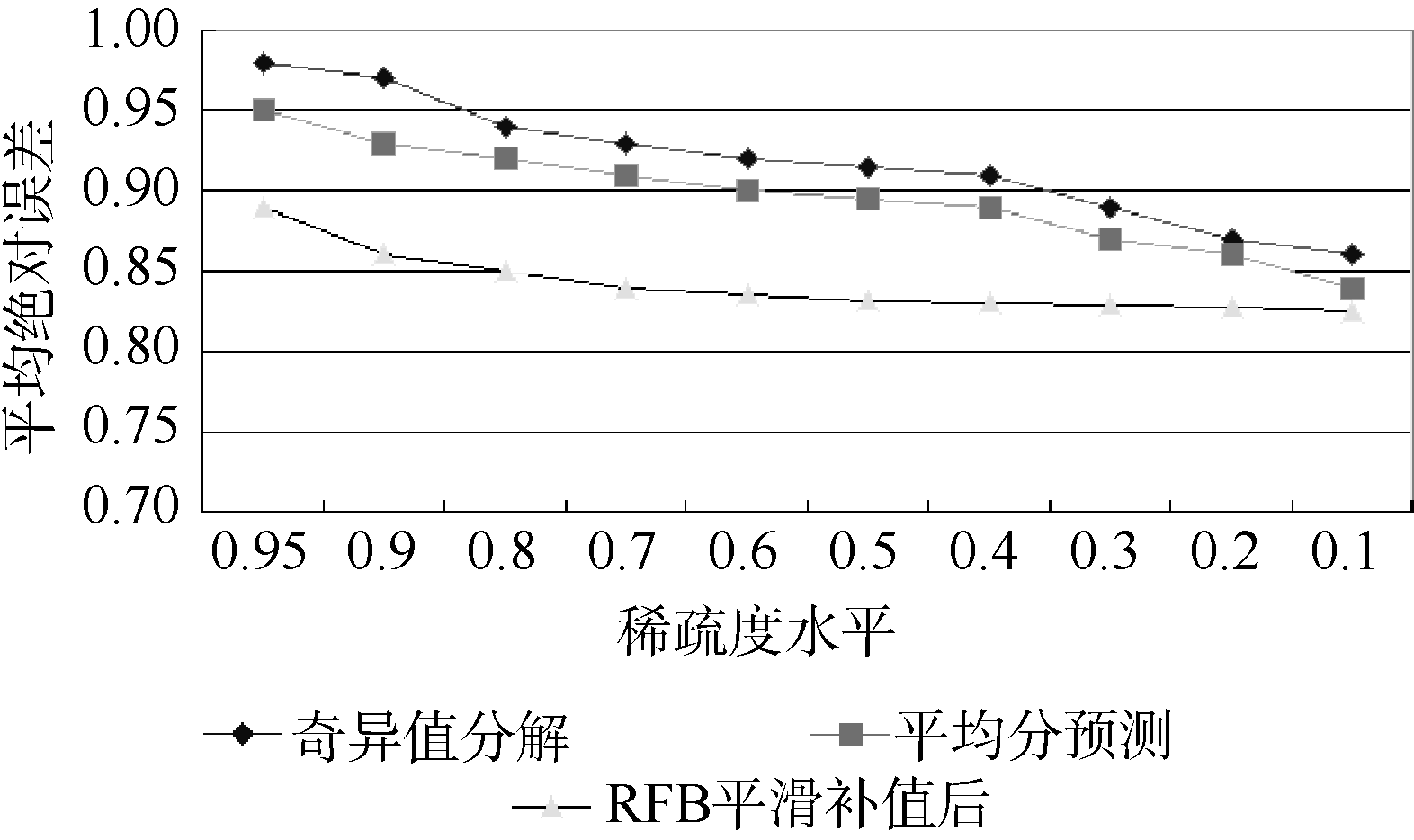 | 图8 不同推荐模型平均绝对误差比较 |
本文提出的方案要优于简单协同过滤, 因为在补值后的聚类的数量要远远小于补值前的聚类数量。在奇异值分解协同过滤中, 只有低纬度的数据被用来预测活动用户的值, 所以其准确性要远远小于本方案, 同时神经网络的训练因过滤掉了评价偏差较大的评分值所以准确性要优于平均分预测协同过滤。
为解决稀疏性问题, 本文通过SOM与RBFN在训练阶段将稀疏矩阵转化为完全矩阵。通过预测补值处理, 用户之间相关性得到增强, 同时保留了有价值的评分数据。在补值处理前, 利用SOM对相似客户进行预聚类, 进行未评分项目的评价值预测, 与客户评价均值预测相比提高了预测值的准确度, 能够适应不同的场景。实验证明补值后的推荐模型能够给出更高质量的推荐。SOM与RBFN补值处理采用离线计算, 减少了历史数据的重复计算量, 保证了在线推荐的实时性, 使系统具有一定的可扩展性。如果用户没有历史评分, 将推荐每个聚类簇的Top T项目作为新用户推荐, 对冷启动问题有较好的效果。
综上所述, SOM与RBFN补值后协同过滤模型将会为用户提供更高质量的推荐。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|