

{kind=link}
{kind=link}
{kind=link}
面向中文专利权利要求书的分词方法研究
[张杰 , 张海超, 翟东升]
, 张海超, 翟东升]
, 张海超, 翟东升]
|
|


作者贡献声明:
张杰, 张海超, 翟东升: 提出研究思路, 设计研究方案, 实施研究过程; 张杰, 张海超: 数据的采集、清洗与分析; 张杰, 张海超, 翟东升: 论文起草及最终版本修订。
【目的】解决中文专利权利要求书分词问题, 满足专利相似研究需求。【方法】总结中文专利权利要求书分割特征词、分割子串规则和术语抽取规则, 构建领域词典, 提出一种基于领域词典和规则相组合的分词方法。【结果】实验结果表明: 分词的准确率为90%, 召回率为95%, F值为92%。【局限】由于领域词典的庞大, 使得大规模分词的效率降低。【结论】该方法能够进一步提高中文专利权利要求书的分词效果和效率。
[Objective] To segment Chinese patent claims and fulfill the research needs of patent similarity.[Methods] This paper not only summarizes the segmentation words, the rules of substring segmentation and the rules of domain terms extraction, but also constructs the domain dictionary. The method based on domain dictionaries and rules to segment Chinese patent claims is presented.[Results] The experimental results show that the precision is 90%, the recall-rate is 95%, and F-score is 92%.[Limitations] However, the huge field of dictionaries reduces the efficiency of large-scale segmentation.[Conclusions] This proposed method further improves the effectiveness and efficiency of Chinese patent claims segmentation.
目前, 海量专利信息的处理面临着巨大的挑战, 信息的快速检索和充分利用成为必然, 专利文本分词是研究专利相似的基础和重要部分。词是能够独立使用的最小语言单元, 但中文文本和西语存在很大不同: 汉语中词与词之间没有明显的类似于空格的显式边界。因此, 中文分词成为计算机处理的重要工作, 中文分词的难点是切分歧义的消除和未登录词的识别[ 1]。
虽然中文分词研究取得了丰硕成果, 但针对中文专利文献分词的研究并不多, 本文结合中文专利权利要求书的分割子串规则和术语抽取规则, 构建特定领域词典, 在初分词的基础上, 提出一种基于规则和领域词典的组合分词方法。
中文分词算法很多, 大致可归纳为: 词典分词方法、统计分词方法、理解分词方法和组合分词算法[ 2]。
基于词典的分词方法也称作基于字符串的机械分词方法[ 3], 其主要思想是: 按照一定的匹配规则将文本中的字符串和事先构建好的词典中的词语进行逐一
匹配, 若匹配成功则切分出来。常用的几种词典分词方法有正向最大匹配法、逆向最大匹配法、双向最大匹配法和最少切分等[ 2]。莫建文等[ 4]提出改进的基于词典中文分词方法, 该方法结合双字哈希结构, 并利用改进的正向最大匹配分词算法进行中文分词。李玲[ 5]构造了标准词典、临时词典和临时高频词表组成的双词典机制作为分词基础, 应用正向最大匹配法和逆向最大匹配法进行分词, 提出基于双词典机制的歧义处理方法。何国斌等[ 6]采用哈希法和二分法进行分词匹配, 并针对机械分词算法的特点, 提出一种基于最大匹配的分词概率算法。梁桢等[ 7]设计能够记录词长的 Hash 结构尾字词典, 提出一种逆向回溯最大匹配算法, 该改进算法采用的回溯机制能够有效消除分词中可能存在的一些歧义问题。
目前来看, 词典分词方法的研究主要围绕词典结构、设计Hash表提高分词性能。词典分词方法的缺陷在于切分准确率依赖于词典规模, 需要权衡时间开销和空间开销。
基于统计的中文分词方法, 其思想是: 词是稳定的汉字的组合, 利用已有的文本语料库作为切分资源, 文本中相邻字之间共现的概率能够很好地反映字之间成词的可信度, 再通过训练语料的迭代, 最后形成统计模型进行分词。常用的是互信息方法、隐马尔科夫模型(HMM)、N元语言模型和最大熵模型等[ 2]。田思虑等[ 8]提出一种改进的基于二元统计的HMM分词算法, 计算出二元统计粗分模型有向边的权值, 运用最短路径法求出分词结果。冯永等[ 9]提出一种基于自适应中文分词和近似SVM的文本分类算法, 利用近似支持向量机进行文本分类。赵秦怡等[ 10]在互信息原理的基础上提出一种基于统计的中文文本分词方法, 该方法对经过预处理后每一个串中的任意可能长度串均判断其成词的可能性。刘丹等[ 11]提出基于贝叶斯网络的中文分词模型, 使用性能更好的平滑算法, 提高了分词效率。
但是, 基于统计的方法往往依赖于大规模的标注训练语料, 不同专业领域的语料存在很大的差异, 分词的准确率与其密切相关。若训练语料过大, 也可能出现数据稀疏的问题。
基于理解的中文分词方法, 基本思想是: 分词同时进行句法、语义分析, 利用句法信息和语义信息处理歧义现象, 理解分词方法需要使用大量语言知识和信息, 常用的人工智能技术包括专家系统、神经网络和生成-测试法三种[ 2]。王彩荣[ 12]设计了分词专家系统的框架, 用知识推理与语法分析替代传统的“词典匹配分词+歧义校正”的过程。尹锋[ 13]利用 BP 神经网络设计了一个分词系统, 进行大量仿真实验, 取得不错的分词效果。来斯惟等[ 14]提出一种基于表示学习的中文分词方法从大规模语料中无监督地学习中文字的语义向量, 将字的语义向量应用于基于神经网络的有监督中文分词。王靖等[ 15]通过对条件随机场机器学习模型的改进, 增加模型导出功能和使其支持预定Tag, 降低了机器学习的代价。
组合的分词方法, 在实际分词过程中往往需要组合几种分词方法利用各自优势, 以更好地解决分词难题。佟晓筠等[ 16]设计了N-最短路径自动分词和词性自动标注一体化处理的模型。蒋建洪等[ 17]提出一种将词典与统计方法结合的中文分词模型, 分析特定领域的文本数据的特点, 设计并实现了一个快速、准确度高的分词模型。张梅山等[ 18]提出一种将统计与词典相结合的领域自适应中文分词方法, 通过将词典信息以特征的方式融入到统计分词模型中实现领域自适应性。
在中文分词研究中, 针对专利文献的讨论并不多。张桂平等[ 19]提出一种基于统计和规则相结合的多策略分词方法, 结合文献的上下文信息进行最大概率分词。岳金媛等[ 20]采用基于领域词典与统计相结合的方法探讨专利文献的中文分词, 使用条件随机场模型提高专业术语的识别率。宋立峰[ 21]对比分析基于词类的错误驱动学习方法、条件随机场方法和期望最大值方法在中文分词方面的应用, 结果显示基于词类的错误驱动学习方法具有较高的适应性, 有更好的分词效果。
目前, 成熟的中文分词系统是中国科学院计算技术研究所开发的ICTCLAS中文分词系统[ 22]。该系统采用多层隐马尔科夫模型, 扩展原有的隐马尔科夫模型, 分词精度和速度都有很大提高。
专利文献中存在大量未登录专业术语, 关系到分词准确性。而ICTCLAS系统是针对普通文本设计的, 对专利文献的分词效果并不理想。因此, 本文根据中文专利权利要求书的结构特点, 提出一种基于规则和领域词典的组合分词方法, 在ICTCLAS系统初分词的基础上, 构建分词规则和领域词典进行再分词, 以期解决要求书分词的问题, 提高要求书分词效果, 同时也为专利文献相似研究提供基础。
我国专利法规定专利权利要求书应当以说明书为依据, 一项发明或者实用新型应当只有一项独立权利要求书, 并且写在同一发明或者实用新型的从属要求书之前, 并且专利权利要求书与一般的文本不同, 专利权利要求书具有一定的格式要求[ 23]。
一项权利要求一般用一句话表示, 以期强调句子意思的完整性和独立性, 但可以用顿号、逗号和分号等来分割。权利要求书开头不用写明专利名称, 可以直接撰写第一项权利要求项, 即独立要求项。从属要求项紧接着独立要求, 若有两项以上独立要求, 各自的从属权利要求对应写在独立权利要求之后。
独立权利要求一般分为两部分撰写: 前序部分和特征部分。独立权利要求的前序部分和特征部分应当包含发明的全部必要技术特征, 共同构成一个完整的技术解决方案, 同时限定发明或实用新型的保护范围。前序部分: 写明发明或实用新型的要求保护的主题名称, 与该项发明或者实用新型最接近的现有技术共有的必要技术特征。特征部分: 写明发明或实用新型区别于现有技术的技术特征, 这是权利要求的核心内容。该部分紧接前序部分, 并且用“其特征是…”、“其特征在于…”等类似短语与前序部分相连。
从属权利要求也应分两部分撰写: 引用部分和限定部分。引用部分: 写明被引用的权利要求书的编号及发明或实用新型主题名称。限定部分: 写明发明或者实用新型附加的技术特征, 是对独立要求的补充和对引用部分的技术特征的进一步限定。同样, 也以“其特征是…”、“其特征在于…”等类似短语与引用部分相连。
综上所述, 中文专利权利要求书存在明显的结构特点, 属于半结构化文本。因此可以根据这些结构信息提高要求书分词效果。
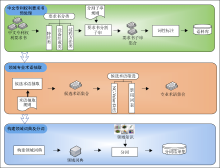
根据中文专利权利要求书的特点和撰写规范, 其分词方法与普通文本的分词方法有所不同, 本文提出的分词方法流程如图1所示:
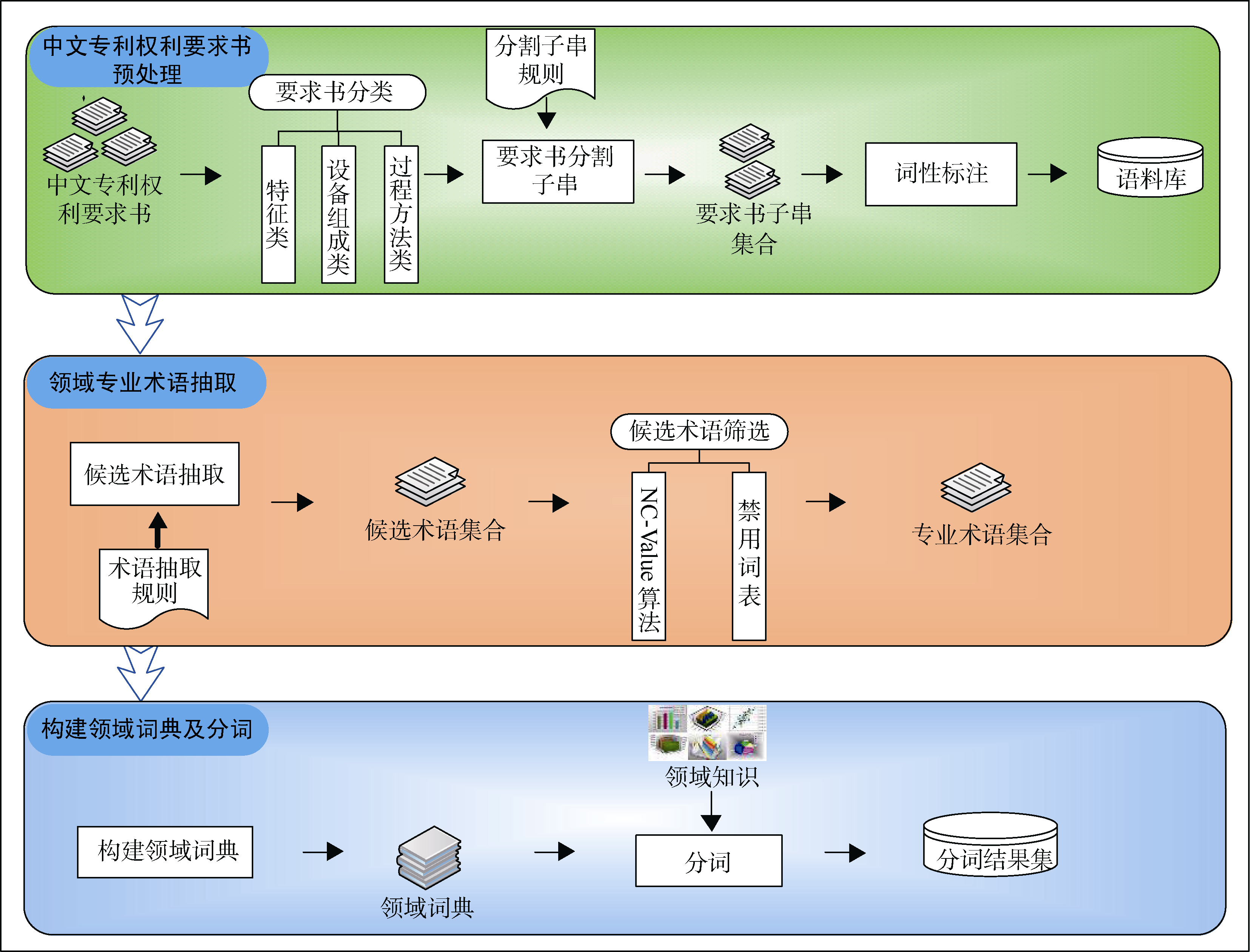 | 图1 中文专利权利要求书分词流程 |
该分词方法的大致步骤如下:
(1) 中文专利权利要求书预处理: 对要求书分类, 根据分割子串规则初步分割要求书, 并对其进行词性标注, 形成要求书语料库;
(2) 领域专业术语抽取: 利用术语抽取规则对已经预处理的要求书语料进行候选术语抽取, 候选术语筛选方法识别出最终的专业术语;
(3) 构建领域词典及分词: 利用识别出的专业术语集合构建领域词典, 并结合专利领域知识进行分词。
要求书预处理主要包括: 要求书分类、要求书分割子串和词性标注。
(1) 要求书分类
翟东升等[ 24]经过对大量的中文专利权利要求书分析, 归纳了部分分类特征词。本文在综合上述文献的基础上, 将中文专利权利要求书分为: 特征类、设备组成类和过程方法类, 并总结出分类特征词表如表1所示:
| 表1 中文专利权利要求书分类特征词表 |
(2) 要求书分割子串
根据分割子串规则, 将中文专利权利要求书分割成子串, 从大量要求书中总结出分割子串规则。根据表1建立分割特征词表规则, 根据要求书潜在的分割子串符号标志, 建立符号分割规则, 如表2所示:
| 表2 常用标点符号分割标记(部分) |
正则表达式(Regular Expression)由一些普通字符和一些元字符组成[ 25]。一个正则表达式通常可以称为一个模式, 用来匹配一系列符合某个句法规则的字符串。本文利用正则表达式来表达上述的分割特征词表规则、符号分割规则和术语抽取规则, 并且构建了XML 调用规则表达式模板, 该模板与本文设计的C#中文分词系统的程序代码相分离, 容易存储、调用及根据需要进行修改。在实验时, 若遇到规则不一致的情况, 则进行人工干预, 进一步完善规则表达式。对表1分割特征词表规则构造相应的正则表达式, 如下所示:
(其?特[征点性](?:[是为]|在于)?)|((?:(?:以下|其|各)?(?:复合)?[成组][份成分][是为]?)|(?:(?:主要|是)由)|(?:包[有括含])|(?:其?[含具]有)|(?:(?:如下)?[处配]方[是为]?))|((?:如下)?(?:过程|(?:制备)?工艺(?:步骤)?|(?:工艺)?步骤|(?:生产)?方法)[为是]?)。
经过上述两步后, 要求书分割子串后的样式如下所示:
“一种移动通信网络适配器/ , / 其特征在于/ : / 具有无线端口/ 。/”
因此, “一种移动通信网络适配器, 其特征在于: 具有无线端口。”一句完整表述被分割成: “一种移动通信网络适配器”和“具有无线端口”两个子串。
(3) 词性标注
词性标注的目的是为了便于4.3节术语抽取规则的运用。词性标注利用ICTCLAS系统的一级词性标记集对子串进行词性标注, 例如“一种移动通信网络适配器”子串进行词性标注后, 结果为“一/m 种/q 移动/vn 通信/vn 网络/n 适配器/n”。
该阶段, 利用术语抽取规则对预处理后的要求书文档语料库进行术语抽取, 形成候选术语集合; 候选术语是否是真正意义上的专业术语, 还要对其进行筛选; 最后形成专业术语集合。
(1) 候选术语抽取
专利文献的术语一般用词严谨、遵循语法规则, 大多由动词、名词和形容词组成, 包含一些缩略词和停用词。要求书中存在明显的标点符号、提示词、连接词、数字和其他切分标记, 因此根据要求书专业术语的构词特点和词性标注信息归纳出术语提取的一些规则, 总结出术语抽取的规则, 如表3所示:
| 表3 中文专利权利要求书术语抽取规则(部分) |
其中, n表示名词, a表示形容词, v表示动词, q表示量词, m表示数词, *表示出现任意次, +表示出现一次或者一次以上。
运用术语抽取规则对语料库中子串进行术语抽取时, 利用了4.2节中的词性标注, 若语料符合抽取模式, 则抽取候选术语, 形成候选术语集合。例如“网络/n 适配器/n”符合“n+n”模式, 则被抽取成“网络适配器”候选术语, “一/m 种/q”符合“m+q+”模式, 则被抽取成“一种”候选术语。
(2) 候选术语筛选
候选术语是否是真正意义上的专业术语, 还要对其进行筛选, 用到的方法有C-value算法和禁用词表。C-value是由Frantzi提出的领域独立的多词术语的统计抽取方法, 该方法是对词频计算方法的改进, 更有效地抽取文本中的嵌套多词术语、反映术语的上下文信息, 本文利用改进的C-value方法评价抽取的候选术语是否是有实际意义的专业术语, 公式如下[ 26]:
| (1) |
| (2) |
其中, s表示候选字符串, |s|为字符串s的长度, f(s)为字符串s的词频。Ts表示包含字符串s的术语, p(Ts)表示包含字符串s的术语总数, w为Ts中任意的包含字符串s的术语, fs(w)为w在字符串s的上下文中出现的次数。α和β为可调权重系数,
通过粗切分后, 语料中可能会出现词性标注错误, 术语的识别也因此会出现术语切分范围过界和术语前后粘连等问题。利用禁用词可以很好地校正该错误。常用的禁用词是一些介词、方位词和数词等, 例如:“为了、除了、下”等。最后, 在对候选术语筛选评价后选择具有实际意义的术语作为专业术语。
中文专利实验数据来源于日立专利信息检索系统Digi-patent/s[ 27]。根据IPC分类号, 选取部分要求书数据作为语料库, 如表4所示。共选取450篇中文专利的权利要求书, 其中350篇要求书作为分词实验的训练数据, 用于构建领域词典的训练语料; 100篇要求书作分词实验的测试数据, 用于实验测试语料。表4中各领域的要求书在训练数据集和测试数据集中都占有相应比例。同时按照专利术语标注标准[ 28]对实验数据手工标注, 作为标准结果集与实验结果对比。
| 表4 实验数据组成 |
将抽取的最终专业术语按照格式导入本文设计的分词系统中, 实验时将本文方法得到的结果与标准分词结果进行对比。经过实验测试, 本文提出的组合分词方法的分词准确率(P)为90%, 召回率(R)为95%, F-score为92%。结果表明, 该方法改善了要求书这一特定文本的分词效果, 提高了分词性能。
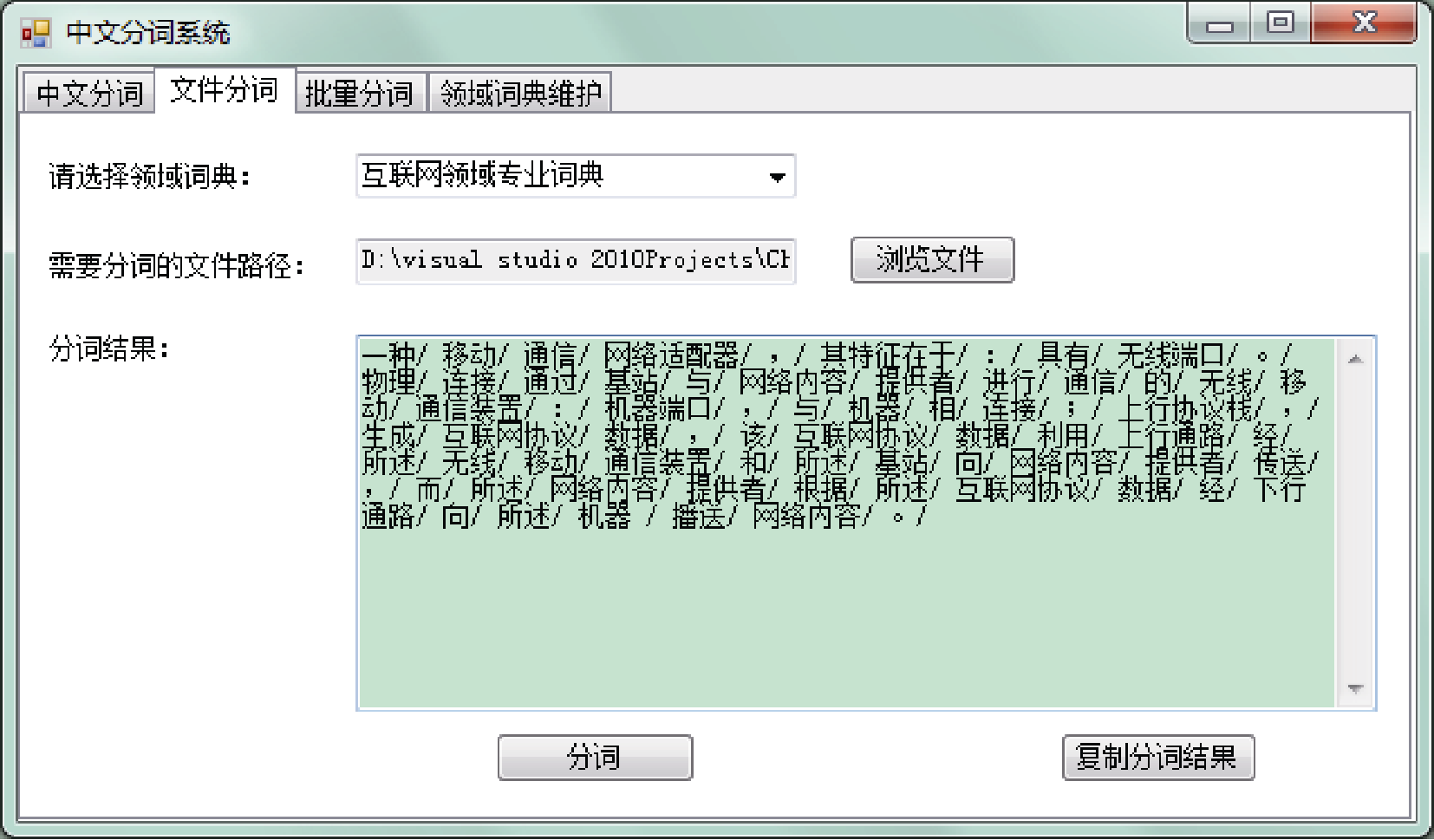
下面是利用本文方法进行分词后的实例, 申请号为“CN01800934.4”的独立权利要求书:
“一种/ 移动/ 通信/ 网络适配器/ , / 其特征在于/ : / 具有/ 无线端口/ 。/ 物理/ 连接/ 通过/ 基站/ 与/ 网络内容/ 提供者/ 进行/ 通信/ 的/ 无线/ 移动/ 通信装置/ : / 机器端口/ , / 与/ 机器/ 相/ 连接/ ; / 上行协议栈/ , / 生成/ 互联网协议/ 数据/ , / 该/ 互联网协议/ 数据/ 利用/ 上行通路/ 经/ 所述/ 无线/ 移动/ 通信装置/ 和/ 所述/ 基站/ 向/ 网络内容/ 提供者/ 传送/ , / 而/ 所述/ 网络内容/ 提供者/ 根据/ 所述/ 互联网协议/ 数据/ 经/ 下行通路/ 向/ 所述/ 机器 / 播送/ 网络内容/ 。/”
中文分词的研究取得了丰硕成果, 但目前针对中文专利文献分词的研究并不多, 本文根据中文专利权利要求书的结构特点, 提出一种基于规则和领域词典的组合分词方法, 在ICTCLAS系统初分词的基础上, 构建分词规则和领域词典进行再分词。实验结果表明, 要求书分词的准确率、召回率和F值都有较大的提高。
本文提出的方法对中文专利权利要求书的分词效果有很好的改善, 但由于领域词典的庞大, 也使得大规模分词的效率降低。因此, 下一步通过对基于理解的分词方法研究, 进行语义分析, 构造新的分词模型, 进一步提高中文专利权利要求书的分词性能。
EBSCO宣布支持NISO开放发现倡议
EBSCO信息服务公司(EBSCO)宣布将完全支持NISO开放发现倡议(Open Discovery Initiative, ODI)工作组所制定的最终版推荐准则, 这一准则给出了发现服务的最佳实践。EBSCO是ODI委员会的一员, 因此, EBSCO有关元数据共享和供应商合作的开放政策与工作组制定的推荐准则是一致的。
ODI列出的多个目标涵盖了很多方面, 包括: 元数据共享、链向出版商内容、使用数据提供等。其中, 元数据共享方面, ODI呼吁内容提供商为发现服务提供商提供更多的元数据, 包括相应的全文或是原始内容, 供发现服务商进行索引。
ODI认为, 下一步将会在这个领域进行更加深入的研究, 以确定具体需要关注的问题, 并研究内容提供商和发现服务提供商会如何解决这些问题。EBSCO在其元数据共享政策第三部分已经明确指出将会支持对该问题的进一步研究。
NISO执行董事Todd Carpenter认为EBSCO支持ODI推荐准则有着重要的意义: “EBSCO一直以来都非常支持NISO的标准制定和标准实施工作, 我们非常感激EBSCO员工的积极奉献, 感谢他们在NISO各项倡议, 包括此次的ODI倡议中发挥的先锋作用。EBSCO最近发布的元数据共享政策与ODI的目标是一致的, 这一举动标示着双方将进行更深入的合作, 为所有图书馆读者谋福利。”
EBSCO计划继续与潜在的合作伙伴进行讨论, 以确保EBSCO内容在第三方发现服务解决方案中的可用性, 并寻求就OPAC功能无缝整合到发现服务中进行合作的可能性。
EBSCO高级副总裁兼ODI委员Scott Bernier认为ODI委员会所做的工作将会令整个图书馆界受益良多: “我们很高兴能够看到这些进步, 也期待能够与业界进行更多的合作, 共同协作执行ODI推荐准则, 为图书馆界谋福利。我们会不定期地分享ODI推荐准则的最新进展。”
(编译自: http://www.ebscohost.com/newsroom/stories/ebsco-announces-support-for-open-discovery-initiative-recommendations)
(本刊讯)
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|