
{kind=link}
机构知识库的发展趋势与挑战
[张晓林 ]
]
]
|
|


机构知识库(Institutional Repository, IR)是机构管理科研成果、传播学术知识、支持全社会创新的重要机制, 日益成为其知识基础设施的重要部分, 成为支持数字科研和数字教育的重要工具。据不完全统计, 截至2013年11月, 已有3 500多个机构知识库提供开放服务[ 1], 已有5 200万篇学术文献可以从开放机构知识库中获得[ 2]。
机构知识库的发展得到了公共科研资助机构的大力支持, 例如美国白宫科技政策办公室在2013年2月发出指令, 要求所有研发资助经费超过1亿美元的联邦机构都应要求资助项目所发表论文在发表后存储到机构或领域知识库、在不超过发表后12个月内实行开放获取[ 3]。诸如哈佛大学、普林斯顿大学、麻省理工学院、加州大学等都要求教师把已发表论文存缴到本校机构知识库开放获取[ 4]。世界科技界正联合推进机构知识库发展, 例如开放机构知识库联盟(COAR)[ 5]以及我国的机构知识库推进工作组[ 6], 积极促进机构知识库间的有效互操作[ 7]。
机构知识库并不是独立存在的, 而是与科研教育环境的各个方面密切交互; 而且, 这些环境本身也在动态变化。随着数字科研的迅速发展、数字知识内容和科研成果的形态日益丰富、知识内容的应用形态和应用方式日益活跃, 科研机构各个层级对机构知识库提出了更多的要求, 为其发展开辟了更为广阔的空间。可以像图1那样, 从知识内容形态到知识应用形态的变迁谱系, 从个人到机构在整个变迁谱系的可能需求角度, 来分析机构知识库的未来发展。这里, 将专门针对支持非文本信息、支持教育科研活动、支持机构战略性知识管理三个具体方面进行分析。
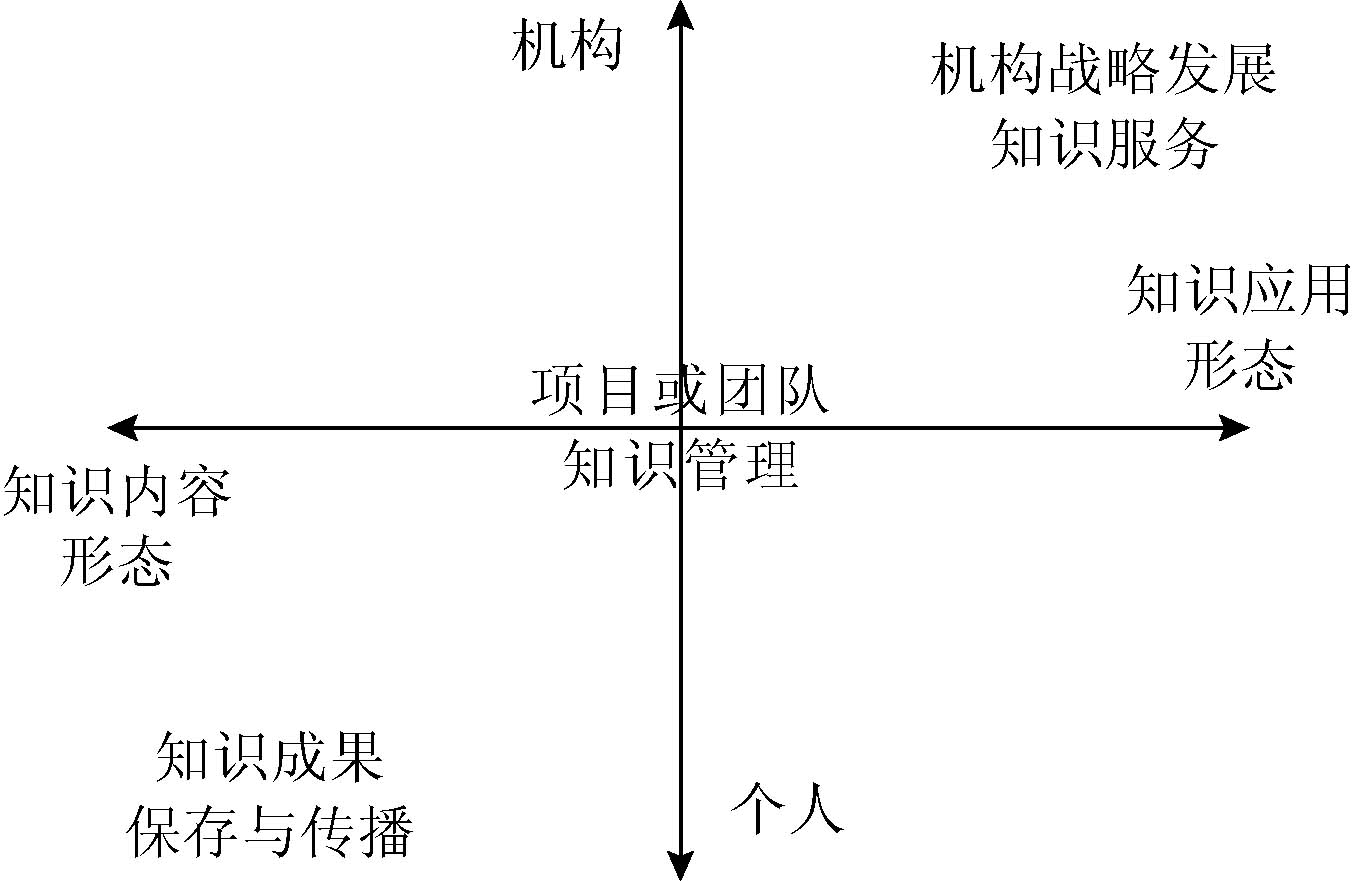 | 图1 知识环境动态变化中的机构 知识库作用领域 |
截至目前, 多数机构知识库的目标、功能和服务仍集中在文本(例如期刊、图书、报告)和准文本(例如PPT文档等)的知识内容上。但要在新的数字科研中维系相关性和贡献力, 必须支持非文本信息(Non-Textual Materials, NTM)。
NTM一直就是科研信息的内在部分, 例如观测数据、图像、音视频、计算机模拟或设计数据、可视化数据等。在包括人文社科在内的多数学科, NTM往往是基础的和主要的研究信息。只是, 在尚未数字化网络化的“史前期”, NTM的传播、共享、处理和管理都较困难, 往往需要将其转化、提炼和重组为文本信息后才能广泛传播和利用, 因此造成以文本为主来传播、处理和保存科研信息的历史现实。可以说, 依赖文本的学术信息传播体系只是历史的无奈和误区。
随着数字化网络化的发展, 采集、组织和呈现NTM的数字化技术已经非常普遍, 例如遥感信息、环境或活动感知信息、疾病检测信息、调查数据、图像和音视频等, 多数从一开始就是以数字化方式存在。而且, 表征、转换、处理NTM的各种标准、方法和工具日益成熟和普及, 人们已经进入数字化为主的科研信息时代[ 8], 这催生了新的科学研究范式——数据密集型的知识发现模式[ 9]。现有的以文本为主的科研知识采集、组织、传播和保存机制已远不能适应需要, 必须基于研究信息全谱段来设计和组织知识的传播、利用和保存机制。因此, 已有人提出, 要超越文本信息来组织科技信息的传播与供应[ 10], 要从整个数字化学术研究的角度、覆盖文本和NTM信息来组织新的数字图书馆服务[ 11]。作为机构科研知识基础设施, 机构知识库必须提供对NTM的支持。仅能处理文本的机构知识库将很快失去在数字科研环境下的核心生命力。
其实, 能否处理NTM已不是简单技术问题。《经济学家》 2013年指出[ 12], “必须重新确立一个基本原则: 作为一篇论文的支撑证据的数据, 必须与论文同时发布。不这样做则构成科学不端行为”。英国《卫报》也早在2012年指出, 科学不端行为正在泛滥[ 13], 其中典型做法包括: 不发布支持所发表论断的证据; 选择性采集和发布数据; 只发表部分的或带偏见的数据(如临床试验中的正面证据); 不发表否定性验证结果。因此, 为了杜绝科学不端、保证科学成果的可信度以及可检验, 把支持科学结论的科学数据(包括音频视频和其他形态的NTM) 公开发表或存储在可公共检索获取的数据库里, 就成了科学的基本要求。这也就要求科研机构的知识库需要有效支持各类非文本的科学数据。
机构知识库支持NTM, 首先要支持各类非文本内容的存缴、描述和长期保存。这涉及一系列的技术问题, 例如数据格式、内容元数据、数据集标识与引用、数据格式或元数据转换、数据保存包组织等; 还涉及一系列保存与使用管理问题, 例如数据溯源描述、数据权益描述、数据转移管理、使用许可管理、使用细粒度控制机制等。将各种千差万别的科研项目所产生的数据存储到一个公共的体系中并能支持公共传播与利用, 显然需要解决许多新的问题。
机构知识库支持NTM, 不能仅停留在数据生命周期末端的存储上, 要将有关服务前置, 避免因为数据共享的许多复杂问题[ 14]导致最后存缴时已经找不到众多宝贵的内容和信息。例如, 有些机构知识库或数据知识库(Data Repository)将协助科研人员制定数据管理计划, 例如美国普渡大学PURR系统[ 15], 提供了科研资助机构数据管理规划要求、范例、以及数据管理规划咨询评估工具。同时, 机构知识库还可把数据管理规划转化为机构知识库内嵌的基于科研过程的数据管理流程模块, 支持项目组对各阶段各类数据进行上传、共享、转移、存储、修改等, 并可支持数据的采集、清理、审核、转换、提取、融汇、关联、可视化等, 成为项目组的科研管理平台, 例如上述PURR系统已经提供的部分功能。
机构知识库支持NTM, 还可扩展针对数据的新服务, 例如, 可嵌接开放科研或社交网络工具, 支持对数据的采集、分析、判读、标注、关联的众包及相关公民科研活动。而且, 机构知识库可以嵌接各类NTM内容识别、分析、挖掘等方面的工具与服务[ 16], 支持对NTM的细粒度的语义化的检索、分析和利用, 支持音视频的对象识别、场景划分、内容与故事构建等, 支持对数据进行位置相关检索、可视化检索以及荟萃分析(Meta-analysis)。有些图书馆(例如德国TIB)已经在这方面做了大量工作[ 17]。
从一定意义上讲, 科研工作流就是科研信息流。在数字科研时代, 科研活动不仅是信息密集型过程, 而且往往是信息驱动的创造过程和管理过程。将传统上被认为仅仅负责科学成果传播的、被动置于后端的机构知识库, 转变为参与知识创造、传播和应用全谱段活动的主动、交互的知识工具, 已是现实的需要。Cramer 认为, 传统意义上的独立的机构知识库已经濒于死亡(IR is dead)[ 18]。 Horstman 提出, 让IR消失在科研流程中(Invisible IR)[ 19]。 这些都提出了重新设计和发展机构知识库来直接支持科研与教育活动的任务。
机构知识库对科研管理的支持, 至少包括以下方面:
(1) 将机构知识库与科研管理信息系统有机链接, 支持科研项目(尤其跨机构、长时间项目)对项目科研成果进行管理和评价。Day曾专门分析了将机构知识库与科研信息系统集成的几种模式[ 20], 例如荷兰的国家研究与合作信息系统(NARCIS)将荷兰科研项目、人员信息与荷兰机构知识库国家网络DARE.Net有机结合, 可通过项目、人员与研究成果进行双向查询[ 21]。为支持科研管理信息系统与机构知识库间互操作, 英国RIOXX项目提出的元数据指南[ 22]在Dublin Core元数据上增加了rioxxterms.projectid和rioxxterms.funder两个元素, 前者使用资助机构资助项目号, 后者从RIOXX资助机构名称表中选用规范机构名称, 支持资助机构开放地发现和调用受资助项目的开放获取论文。
(2) 将科研项目管理机制嵌入机构知识库, 可支持围绕项目工作流、信息内容驱动的项目管理和项目资料与成果管理。例如, 德国马普学会eSciDoc知识库对科研各阶段及其产出对象进行语义标记和管理, 以对象(Item)、对象集合(Container)及环境(Context)的综合管理为科研人员构建知识空间[ 23], 形成机构知识库内容对象及其管理与科研过程的对象、工具、管理的互操作, 协同支持科研工作流。前面提到的普渡大学研究知识库也支持内嵌的基于科研过程的数据管理模块, 支持围绕科研流程来规划、汇交、审核、共享、处理项目成果。
(3) 将机构知识库的内容对象能力扩展到复合数字对象, 支持对科研项目复杂内容的有机组织。许多科研项目都涉及在多个时间、多个地点、用多种方法获得的多种类型的数据对象, 这些对象间存在复杂的关系, 例如不同地点测得的数据、在同一地点但不同时间测得的数据、或者从一个数据集中抽取或与别的数据集融汇产生的新数据集等。而且, 目前许多重要期刊都要求学术论文要关联发布支持其论点和结论的各种非文本数据。从科研活动角度, 这些内容对象是相互关联的, 需要采取新的技术方法来组织、发现和利用这些数据。为此, 人们提出了诸如OAI-ORE[ 24]标准, 通过一个集成对象和若干Resource Maps, 对所集成的资源及其关系进行定义, 支持复杂对象体系的组织和跨知识库的对象组织。再有, 业界正积极推动在机构知识库采用规范的作者标识和内容对象标识, 例如ORCID[ 25]作者唯一标识符, 支持各类内容之间的有机关联。
机构知识库可以发挥科研数据管理基础设施的作用, 支持科研成果验证、支持科研可重复性。科学研究的可重复性, 不仅需要将研究数据可靠存储, 而且需要建立严谨细致的研究数据溯源管理[ 26], 这不仅需要描述科研数据的元数据, 而且需要描述科研过程中谁、为什么目标、根据什么规程、用什么工具或方法、按照什么参数或设置、在什么时间和地点、对什么对象、进行什么处理、生成什么结果等, 并把相应的原始数据、中间数据、最终数据及其过程描述信息规范地记载和保存[ 27]。只有这样, 人们才能准确理解和客观评价支持科研结论的相关数据。要支持这样的能力, 一方面要建立详细描述数据溯源的要求及其知识本体[ 28], 另一方面要围绕科研活动生命周期, 建立基于数据溯源知识本体的数据描述、管理和集成服务。许多科研流程管理系统都在一定程度上支持了上述服务[ 29], 但考虑到本文第2节提到的围绕项目生命周期来支持非文本数据的管理规划、汇交、共享和长期保存, 其实机构知识库将是实现数据溯源管理的最佳锚地之一。目前, 已有重要项目在这方面开展积极的试验[ 30]。
机构知识库可以支持开放数据应用和开放创新, 把知识内容从图书馆和数据库中解放出来, 成为社会公众的有利创新武器[ 31]。英国皇家学会指出, 要支持开放创新, 科学数据应该可获取、可理解、可评价和可应用[ 32]。机构知识库可以通过元数据和溯源管理来支持“可理解”和“可评价”, 还可以把元数据、内容组织数据、甚至内容数据本身以不同的程度(见表1)开放出来供公共获取和计算机化应用。这一方面需要让数据以规范的计算机可读形式被获取, 提供开放的数据调用接口、调用协议以及计算处理工具[ 33], 从而支持第三方发现、调用、处理数据来生成新的数据、工具和服务。另一方面, 还需要通过开放使用许可来定义和支持用户的使用, 例如创作共用许可Creative Commons[ 34]和开放数据共用许可Open Data Commons[ 35]。数据拥有者或提供者还可对数据的使用进行更为精细的管理。一方面要对数据进行评价和必要的清理, 防止暴露隐私或影响竞争; 另一方面可以对数据使用进行监测, 或者要求使用者事先登记, 或者限制使用频次或数量, 或者要求事先签署使用协议以禁止某些使用(例如商业应用或镜像公开)。具体的要求往往取决于数据的性质、数据拥有或提供者本身的服务内容、以及第三方使用的性质等。
| 表1 数据的5个开放应用层级[ 33] |
研究和教育是知识密集型活动, 研究和教育机构是知识驱动的机构。因此, 机构所产生的科研成果作为机构知识资产, 不仅是个人化检索、利用和创造的工具, 也是机构进行战略管理的工具。利用这些资产, 机构可客观系统地审计自己的知识能力、知识影响力、知识竞争力和知识生产效率, 可基于知识资产进行知识产品的再创造和扩展利用; 还可利用知识资产支持战略规划。这样, 机构知识库将为机构层面对知识资产的战略性利用、机构知识创造的规划与决策、机构知识资产的深度挖掘开发等做出战略性贡献。
机构知识库提供了基于证据的科研成果管理与评价能力。为了可靠支持机构的知识管理, 首先要评价和核实机构的知识产出在多大程度上已经收集进机构知识库, 为此可以与综合文摘索引系统进行比对分析, 或者与论文引证系统进行对比分析, 或者与科研管理/学位管理系统申报数据进行比对分析。当然, 这需要解决不同系统之间的数据接口和元数据映射。
在此基础上, 可以建立科研成果影响力计算和评价的途径, 例如通过机构知识库内的论文数据查询引文数据、进而查询引文网络数据, 揭示出被引多少次、被谁引用、通过共著或共词或同被引或引文耦合等关系关联起来的其他论文是什么等, 并将这些数据及其关联进行可视化和时序化展示和分析。
论文的利用及其影响一定程度上还反映在论文下载数据上, 因此可对机构知识库论文下载数量及谁在下载等进行分析[ 36], 并利用其他Altmetrics指标[ 37]来揭示在科学传媒、社交媒体、科学社群等中对论文的利用。除了利用上述数据分析基于产出和基于利用的知识能力和影响力外, 还可把人员、经费、时间、项目等级等因素考虑进来, 分析知识生产率。
机构知识库中往往包含分布在较长时间范围、发表在众多媒介(期刊、会议等)、涉及众多主题、具有不同学术深度的学术成果。这是新知识作品创作和扩展的知识宝库。例如, 可以利用机构知识库创作衍生作品, 包括以问题为中心的跨主题跨类别的横向的“文集”汇编, 形成所谓Overlay Journals[ 38]。当然, 也可以围绕学科或主题领域或问题来纵向地组织论文, 形成“研究演进专著”。这些都需要界定“问题相关相似判断”的标准, 设计横向的问题结构或纵向的研究演进框架, 建立计算分析工具, 支持自动的或计算机辅助的衍生作品生产流程。
机构知识库还可利用所存储内容及其关联, 支持对知识转移转化的管理。一方面, 机构知识库可以支持预印本存缴、登记和发布服务, 提供科研成果首发优先权的证明证据; 可以支持科研论文与专利在创作者、引用、主题关系等方面的关联分析, 通过与专利相关的论文研究宽度与厚度来分析专利转移的基础知识支持和后续研发支持能力, 从而支持成果转移转化。另一方面, 机构知识库还可支持基于存储内容的科学教育或科学普及资料包的组织(可看成专门“文集汇编”), 支持科学教材与支撑或延伸论文、数据的关联组织, 支持从存储内容中直接提取文摘、目次等生成“研究概要”, 支持从存储内容及其图表、图像、附属音频视频文件等直接生成可演示文档等。这些服务可能需要专门的内容提取、可视化、结构化、PPT化等工具。
研究机构可利用机构知识库存储内容自动生成研究人员学术履历、研究组室学术目录、内部及与外部的学术合作网等。在此基础上可生成本机构的知识图谱, 可视化地说明本机构谁在做什么、特色方向在哪里、有无重复、与谁合作等, 并利用本机构图谱与全领域知识图谱、与竞争对手知识图谱等的比较分析, 鉴别自己的竞争优势和空白偏差, 发现潜在的竞争对手, 选择可能的合作机会。进一步地, 可利用机构知识库存储内容进行研发布局规划, 分析究竟谁有能力做什么、谁的知识生产率高、谁的合作基础强、哪些团队可以组配起来进行哪些方面的攻关, 等等。可视化、交互式分析将是这些服务的必要体现形式。
这里仅仅是对机构知识库在新环境下的可能作用的初步分析。仍需挖掘和伸展自己对未来科研环境和科研需求的洞察力, 大胆跳出机构知识库作为“存储库”的传统束缚, 充分利用机构知识库丰富内容及其与整个信息环境的丰富链接, 积极探索和创造新的服务, 将机构知识库转变为科研过程中的主动的直接的和不可或缺的知识服务平台。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|