


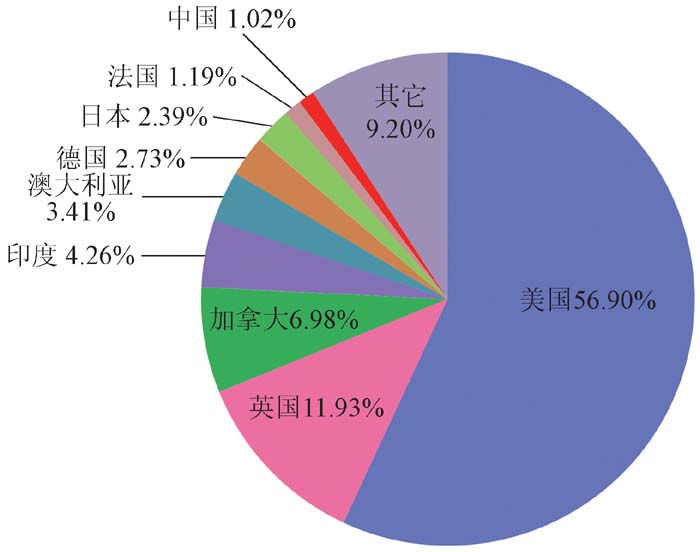
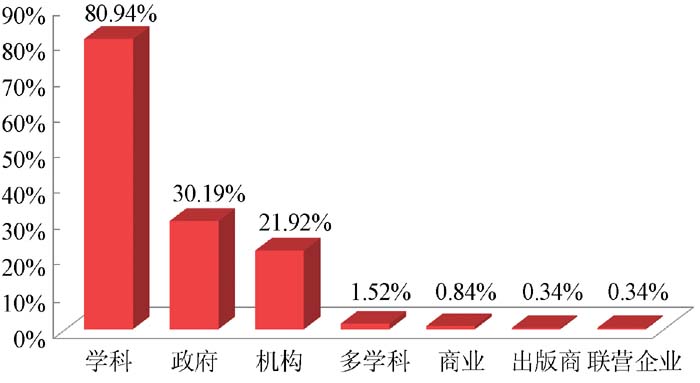
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
科研数据知识库研究述评
[刘峰1, 2, 3  , 张晓林
, 张晓林1 , 孔丽华1, 2, 3 ]
, 张晓林|
|


张晓林: 提出研究思路与研究框架, 参与论文修订;
刘峰: 设计研究方案, 负责研究数据收集、整理、统计与分析,负责论文起草和论文修订;
孔丽华: 参与研究数据的收集与整理, 参与论文修订。
近年来, 随着数据密集型科研活动的蓬勃发展, 数据管理成为科研活动的重要组成部分, 继而对科学数据管理和科学数据知识库(Data Repositories, DR)提出了新的要求。本文通过DR现状分析来揭示现有DR的能力和局限, 为DR的发展提出建议。
DR往往被翻译为数据知识库、数据仓储、数据资源库、数据存储库等。在科研领域和科学数据管理领域, DR的重点往往在于支持科研活动、深化基于数据的知识再利用和再创造, 因此本文中将使用数据知识库。需要指出, 数据知识库本身将随着科技模式、科技环境、以及技术本身的发展而发展, 而且需要通过不同领域、不同应用、不同数据形态等多角度个性化地发展, 因此本文比较开放地定义数据知识库为以存储和管理“科研数据”、支持科研活动及其知识创造的数字知识库, 其中科研数据是指通过采集、实验、观察、整理而形成, 用于科研分析并最终形成科研成果的数字数据[ 1]。
数据知识库承担不断发展更多的数据管理、数据应用的责任, 包括:
(1) 支持对科学数据集的存缴、格式处理、内容描述、长期保存等;
(2) 提供查询、调用、显示等基本服务;
(3) 往往提供对数据进行转换、融汇、可视化等服务或工具;
(4) 可能提供支持数据管理、协同处理、应用控制等服务;
(5) 可由某个机构、领域或者公共第三方建立。
目前, 数据知识库主要分为机构数据知识库、学科数据知识库、多学科数据知识库以及特定项目数据知识库4类[ 2], 如表1所示:
| 表1 数据知识库分类说明 |
其中, 就数据服务的开放性而言, 学科数据知识库和多学科数据知识库由于面向广泛的科研群体, 开放性最强, 而机构数据知识库和项目数据知识库往往局限于相应机构或项目; 就服务学科领域的深度而言, 学科数据知识库面向特定学科领域、且往往是长期服务, 表现出更强的系统化与专业化服务能力; 就服务学科领域的广度而言, 多学科数据知识库和机构数据知识库明显更有优势。
面对越来越多的各类数据知识库, 发现和利用合适的知识库成为一种挑战, 科研数据知识库注册与目录系统应运而生。当前比较知名的这类系统包括OAD[ 3]、re3data.org[ 4]、Databib[ 5]等, 如表2所示:
| 表2 典型数据知识库注册目录系统比较 |
另一方面, 科技发达国家以及一些国际组织结合政府数据和科研数据开放利用的要求, 积极建设自己的数据门户, 帮助人们发现和利用政府数据和政府资助科研项目数据, 如表3所示。由于政府本身往往是各类数据的主要生产者, 也是科技研究的主要资助者, 这些数据门户已经成为所在国最重要的数据目录。
| 表3 主要科技大国及世界组织数据门户列表 |
为了全面了解国际科研数据知识库的发展现状, 笔者对Databib注册的595个数据知识库(截至2013年9月27日[ 6])进行了多角度统计分析。
Databib作为专门的数据知识库注册系统, 力图收集和描述全球有重要价值的数据知识库, 其内容具有一定的代表性。当然, 由于数据知识库本身在迅速发展中, 而且Databib 采取自愿注册, 不同国家的参与度也不一样, 因此它的广泛性、准确性存在一定局限, 基于它的分析主要提供大致的场景而非绝对的数据。
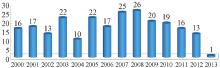
对标有建设年份的433个数据知识库记录统计发现, 建于2000年前的数据知识库占45.27%, 2000年以后的占54.73%, 可见21世纪以来, 各国数据知识库发展建设迅速。笔者进一步分析了2000年以后的各年度数据, 如图2所示, 可见2000年以来数据知识库建设的发展速度总体相对平稳。
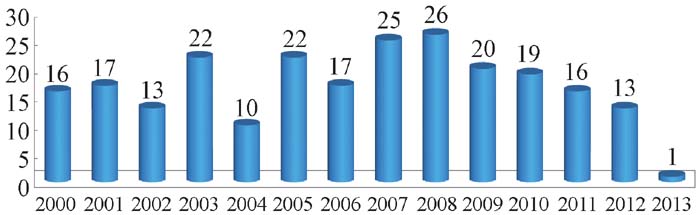 | 图2 2000年以来数据知识库建设情况统计 |
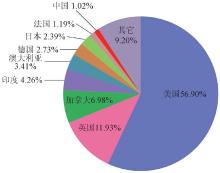
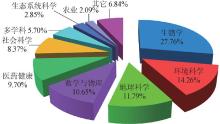
数据知识库按学科领域分布统计如图3所示, 生物、环境、地球科学等的数据知识库分布较为广泛, 农业等领域分布相对较少。应积极鼓励各个领域加强数据知识库研究建设。
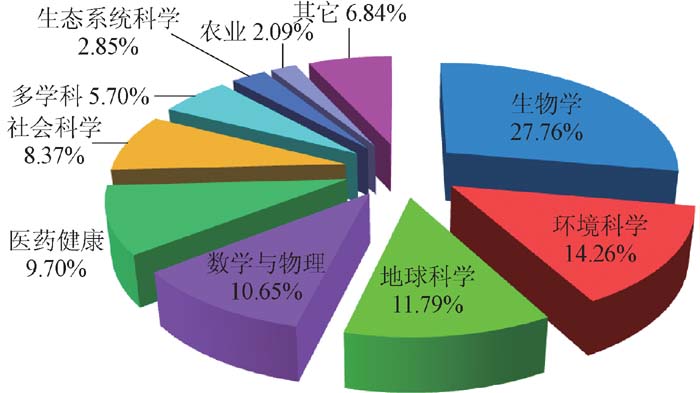 | 图3 数据知识库按学科领域分布统计 |
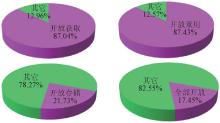
根据数据知识库对内容的开放获取、开放重用、开放存储许可, 统计如图5所示。在Databib登记的多数数据知识库允许开放获取和开放重用, 但只有部分允许开放存储。当然, 这些结果与Databib更关注开放数据库有密切关系。
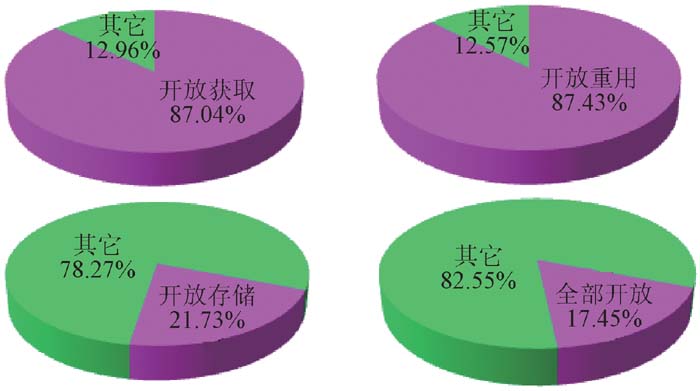 | 图5 数据知识库开放程度统计 |
笔者分析了1983年以来建设的数据知识库的开放获取及开放重用许可情况, 分析了2000年以来建设的数据知识库的开放存储状况(因为开放存储本身的开展较晚), 去除上下限极值后的结果如图6所示, 可见数据知识库的开放获取和开放重用有较为明显的上升, 开放存储稳中略有上升。
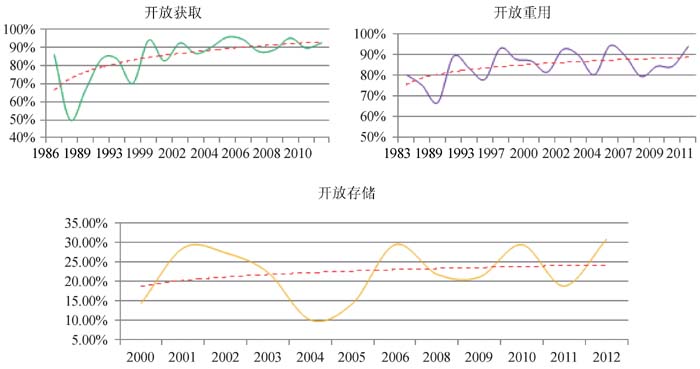 | 图6 数据知识库开放趋势统计 |
为了深入理解科研数据知识库的服务模式与特色, 笔者选取了国际范围内应用广泛的三个数据知识库GenBank[ 7]、Dryad[ 8]和Figshare[ 9]做进一步分析。
(1) 简介
GenBank是美国国家生物技术信息中心(NCBI[ 10])建立的基因序列数据库, 致力于收集所有公开可用的DNA序列数据, 为科研人员提供大规模基因组测序数据。作为国际核苷酸序列数据库协作组织的重要成员之一, 为保证数据的覆盖面, GenBank与该组织的其他两个成员日本DNA数据银行(DDBJ[ 11])和欧洲分子生物实验室(EMBL[ 12])建立了相互交换数据的合作关系。
(2) 服务特点
①采用序列标识符及标注元数据信息检索GenBank序列数据;
②采用基于Web的提交工具BankIt、基于FTP的客户端工具Sequin;
③采用NCBI程序组件接口检索、连接、下载序列数据, 提供专门的检索工具Nucleotide;
④采用BLAST(基础的本地比对检索工具)比对查询GenBank序列数据;
⑤对提交的序列数据类型及内容组成有专门的格式要求;
⑥提交者随时可更新修正序列数据;
⑦提交者可指定序列数据的发布共享的时间;
⑧提交者可因版权、专利等提出保护要求, 可不提供公共访问。
(1) 简介
Dryad 国际数据知识库接受与出版的同行评议论文密切相关的科研数据集。 它对数据格式没有专门要求, 对提交的数据文件都给予DOI标识。Dryad与TreeBASE[ 13]、GenBank[ 7]、DataONE[ 14]结成合作伙伴, 相互之间可以进行数据交换。
(2) 服务特点
①支持灵活多样的数据格式、简单的提交模式和多层次的安全访问控制;
②支持与期刊论文和特定数据知识库(如GenBank)的数据关联;
③为数据对象分配DOI标识, 便于数据引用;
④提供人机两种数据索引及检索接口, 提升数据的可见性;
⑤数据内容可以自由下载和重用;
⑥全程监护数据文件与元数据, 保证数据的有效性;
⑦提交者可以自由更新数据文件;
⑧与CLOCKSS合作进行数据长期保存, 可迁移数据格式到最新版本, 保证数据可无限期访问。
(1) 简介
Figshare为科研人员提供发布各类研究产出的平台, 以便研究成果可以更好地被引用、共享和发现。Figshare接受图表、媒体(包括音频)、海报(Poster)、论文(包括预印本)和多文件(文件集)、数据集等, 为所有内容对象分配DOI, 采用CreativeCommons许可协议共享数据, 并且采用Amazon基于云的数据管理系统来保证数据存储的安全和可靠性。
(2) 服务特点
①支持研究者以可引用、可检索、可共享的模式发布数据;
②提供无限的公共存储空间和1GB的私有自由存储空间;
③提供简洁的数据上传模式, 支持多种数据格式的快速上传;
④所有Figshare上的对象被自动分配DOI标识, 便于数据引用;
⑤所有图片和论文采用CC-BY许可, 所有数据集采用CC0许可;
⑥基于云数据管理服务模式, 支持桌面客户端上传工具;
⑦与CLOCKSS合作进行数据的长期保存;
⑧提交者可以在提交数据后自由更新数据文件;
⑨提供数据内容及功能的开放API接口。
三个数据知识库的综合对比分析如表4所示。这三个数据知识库都支持开放获取、开放重用、开放存储, 支持数据集唯一标识、API接口、自由更新, 支持便捷的提交与检索入口。
| 表4 典型数据知识库实例对比分析 |
当前, 数据知识库的数量不断增加, 许多数据知识库已经能够提供丰富的服务。但是, 由于数据、数据管理实践、数据应用等的复杂性, 要有效发现、有效利用、集成融汇科学数据, 还面临一系列挑战, 例如元数据、数据格式、检索协议等的互操作性。因此, 《自然》杂志提出了Data Descriptor架构[ 15], 以数据描述符为核心, 通过一系列标准及框架映射实现多种数据知识库的有效整合, 并为科学数据及期刊文献的整合出版提供基础支撑服务平台, 如图7所示:
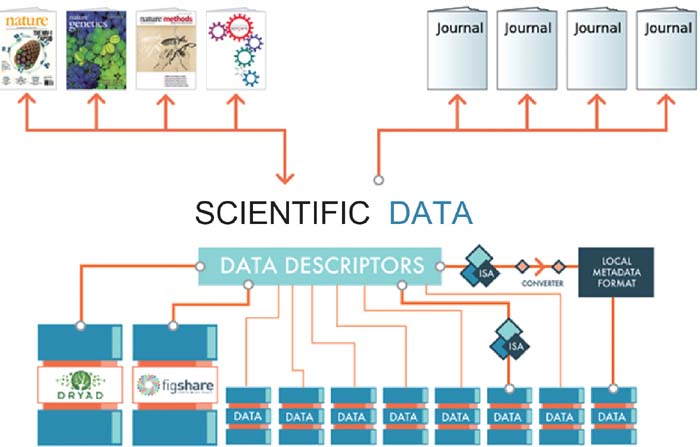 | 图7 数据知识库整合与出版框架[ 15] |
另一方面, 笔者也注意到美国普渡大学的研究知识库PURR[ 16], 已经在数据知识库中嵌入科学数据管理规划功能和数据生命周期管理功能。前者根据美国国家科学基金会(NSF)的项目数据共享与管理计划要求, 提供数据管理计划规范文件、数据管理计划模板以及检查核对模块, 把数据管理关口前移, 支持科研人员从项目申请时就围绕项目目标和过程, 设计数据管理要求和流程, 并形成规范的甚至是计算机可读的数据管理计划。后者更是把数据知识库作为项目的数据管理平台, 支持项目组在项目进行过程中的数据存缴、转换、共享和发布管理等, 一方面支持项目组系统规范地管理数据和研究过程, 另一方面自然地把项目组层面的数据管理与机构层面的数据知识库管理有机结合, 有效解决了原来严重存在的这两个环节彼此割裂的问题。
国内的数据知识库建设也有了长足的发展, 当前重点集中在基础服务体系建设方面。以笔者所在的中国科学院计算机网络信息中心科学数据中心为例, 目前在数据资源集成、管理与服务方面已形成较为完整的软件服务架构, 例如科学数据自助管理方面的VisualDB[ 17]工具, 在数据整合与汇聚方面的数据资源与服务注册系统RSR[ 18], 在数据集成检索方面的科学数据搜索引擎Voovle[ 19], 在数据集管理方面的资源量统计系统Resstat[ 20]和数据服务监控与统计系统MSIS[ 21], 在科学数据参考咨询方面的DRS[ 22]系统, 同时正在云数据管理及基于社交网络的数据交换共享平台研发上进行积极探索。
考虑到科学数据管理本身的复杂性和科学数据发现与应用的复杂性, 数据知识库还需要进一步发展。一方面, 应向普渡大学PURR学习, 将科研活动、数据管理、数据知识库三者密切结合, 梳理和健全围绕科研活动生命周期的科学数据管理的需求与规范框架, 分析科研数据生产、审核、处理、管理、应用整个谱段的利益相关者的复杂需求, 建立科研数据的权益管理框架及科研生命周期驱动的科学数据管理范式, 建立汇聚科研活动、数据管理、数据知识库的新型管理与服务模式。另一方面, 积极适应开放科研环境和开放数据应用要求, 适应科学数据和科学文献的整合出版趋势, 以数据的开放存储、集成发现、互操作、开放利用等为目标, 支持以下“技术”方面的研究与应用实践: 数据集描述与引用; 数据出版; 数据关联发现; 数据溯源管理; 数据格式和元数据互操作; 数据开放检索协议; 数据权益保护和利用许可机制; 开放数据应用管理机制; 数据长期保存; 数据集和数据知识库登记; 海量数据资源集成整合, 等等。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|