



{kind=link}
{kind=link}
{kind=link}
{kind=link}
Web导航模型综述*——信息觅食理论视角
[柯青 , 王秀峰]
, 王秀峰]
, 王秀峰]
|
|


互联网迅猛发展以及网络信息资源爆炸式增长使得人们获取信息的难度不断加剧。网络信息资源的超文本组织结构具有灵活、交互性强、自由度大等优点, 但是也造成了用户Web迷航现象。网络信息资源的内容、形式以及组织的纷繁复杂远远超出用户的认知能力, 使得用户与Web导航的交互活动是一个涉及多因素、多行为的复杂过程。用模型表示用户与Web导航交互过程是学界深入研究用户Web导航行为的常用方法。模型能将一个复杂而抽象的过程具体化, 以一些构件、要素来描述环境与用户之间的交互细节以及分析关键因素对行为的影响。Miller等[ 1]认为一个好的模型必须综合考虑用户心理预期、决策制定和实际控制, 能成功预测用户的行为, 与用户的认知和生理局限性相符。为此, 学界试图借鉴各种行为分析理论来构建Web导航模型, 信息觅食理论(Information Foraging Theory, IFT)即为其中代表。
觅食是动物最常见的本能行为, 生态学家在模拟和解释动物觅食行为时观察出动物觅食的过程表现出一些规律[ 2]: 例如一个动物在取食前必须首先决定到哪儿去取食, 取食什么类型的食物, 什么时候转移取食地点。在觅食的过程中, 动物需要不断评估食物所含的能量和捕食所消耗的能量并做出决策, 通过评估不同的环境和不同的食物之间的最优化收益, 从而决定是继续留在该地区捕食还是转向另一个捕食地区。用户的导航过程也呈现出类似的特征。早在20世纪末, 在“电子世界的导航”工作组会议中(Navigation in Electronic Worlds: A CHI 97 Workshop), Darken等用一个框架解释了Web导航活动的过程[ 3]。导航活动起始于用户决定要寻找的目标是什么, 是要找一个特别的主题还是要找一组主题, 相关空间的信息有哪些; 其次, 必须制定完成寻找任务的策略或计划, 思考诸如是否需要借助于搜索引擎还是跟随像Yahoo这样的分类目录, 是否要使用路标等问题, 这个过程可能需要地图或者其他的外部资源; 最后执行实际的寻找任务。用户扫描语境中的相关信息, 评价是否为其所期望的结果, 以及完成寻找任务的过程是否充分。与此同时, 用户以认知地图等思维模型感知相关语境信息, 根据评估结果决定采取的行动是沿着一个超链接还是转向新的Web导航交互, 该过程是认知活动之一, 是决定放弃寻找任务还是开始新的尝试, 是放弃当前策略还是重新制定策略。
行为的产生源于动机和需求所导致的一系列行动, 对比动物的觅食过程和Web导航过程, 可以看出两种行为都经历需求动机的产生、制定策略、执行策略、改变策略以及终止行为这5个阶段。在每个阶段, 两者之间的相似性表现如表1所示:
| 表1 动物觅食行为与用户Web导航行为相似性 |
信息搜寻成本呈正比例递增趋势, 总成本呈U型趋势, 当执行成本和信息搜寻成本相等时, 位于曲线的最低点, 这个最低点即为最优绩效点。图1也表明, 最优绩效点的信息搜寻行为次数居于中间某个值, 太多的信息搜寻行为和太少的信息搜寻行为都不是最优绩效。
基于表1中二者相似性, 信息觅食理论的提出者Pirolli等发现用户的导航行为也可以用IFT来解释和预测, 因而提出基于线索的导航和ACT认知架构中的信息觅食一系列Web导航模型(Scent-based Navigation and Information Foraging in the ACT Cognitive Architecture, SNIF-ACT)[ 4, 5]。这些模型提出的基础是有限理性假设和次最优决策, 而从本质上看, 该系列模型是基于IFT的思想来描述用户如何在Web信息空间评价信息线索、选择链接以及终止导航行为。
古典决策理论中在研究人类决策行为时曾提出了完全理性假设, 认为行为人的选择或决策是在资源约束的条件下实现效用最大化。不过, 这种完全理性假设和现实情况有冲突, 在指导人们实际决策活动时存在局限性, 古典决策理论的代表人物西蒙[ 6]在其所著的《管理行为》一书中提出用“管理人”取代“经济人”, 并提出了有限理性假设, 认为由于人的知识、时间和精力是有限的, 因而总是基于一定的权衡来做出相适应的选择和决策。在西蒙之后, 其他的学者如Anderson[ 7]、Oaksford等[ 8]提出动物和人类是根据与周围世界和环境的交互中获得的经验而做出有限理性决策。用户的信息行为也受这一法则支配, 信息搜寻者评估各种不同的方案直到有一个方案能够让其满意。有限理性意味着搜寻者不需要完全信息和无限制的认知资源, 也不需要穷尽所有的可得方案, 而是根据有限的知识来做出适应性调整。
根据有限理性假设, Fu等研究了用户是如何权衡信息搜寻成本和信息效用来决定是否继续执行信息搜寻行为的过程[ 9]。用户信息需求的产生是为了执行任务, 因而总成本可以分为两部分: 执行任务成本(Execution Costs)和信息搜寻成本(Information-Seeking Costs)。随着信息搜寻行为的发生, 根据信息的效用, 会带来执行任务成本的降低, 信息搜寻成本在不断增加。如果定义信息搜寻的执行次数为n, 单次信息搜寻的成本为C, 那么信息搜寻成本为n×C。由于每次信息搜寻行为的发生, 都会带来一定的信息效用, 所以执行任务成本实际上是信息搜寻次数的函数, 用f(n)表示, 总成本为f(n)+n×C, 三者之间的关系如图1所示:
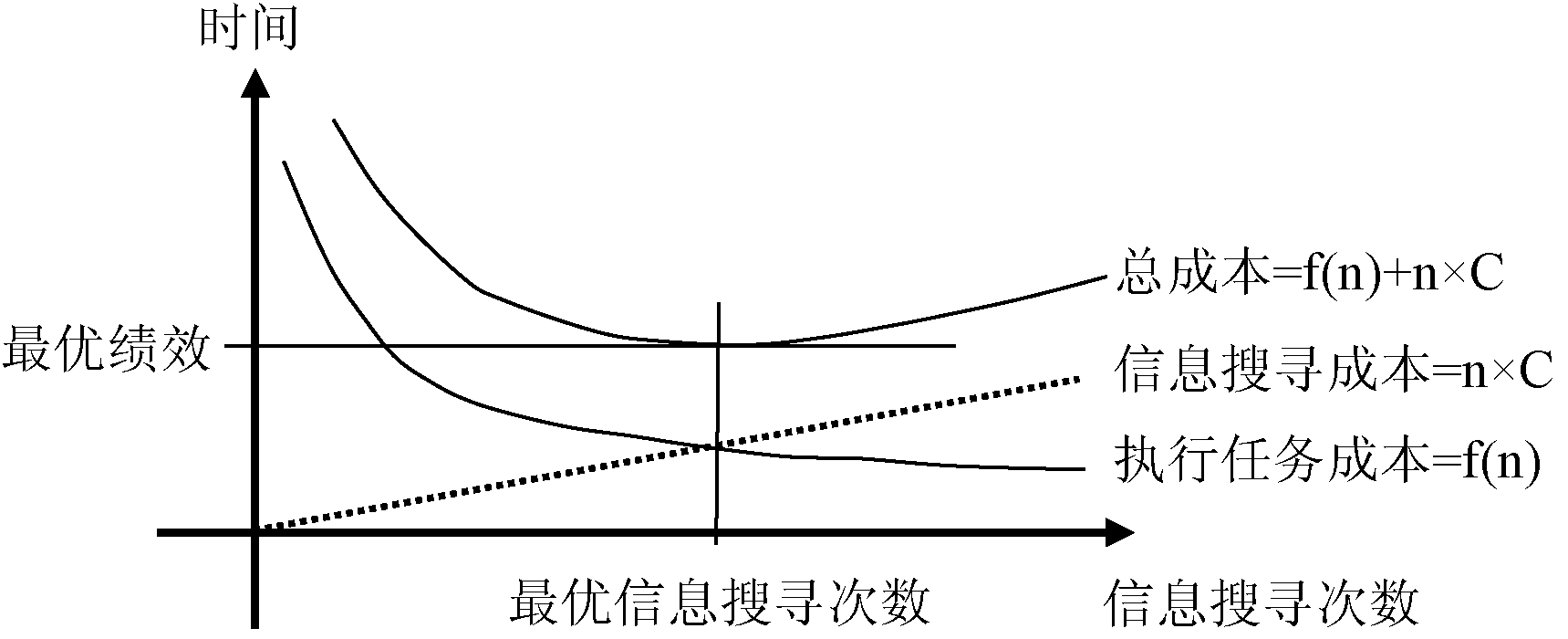 | 图1 信息搜寻成本与信息效用关系[ 9] |
信息搜寻成本呈正比例递增趋势, 总成本呈U型趋势, 当执行成本和信息搜寻成本相等时, 位于曲线的最低点, 这个最低点即为最优绩效点。图1也表明, 最优绩效点的信息搜寻行为次数居于中间某个值, 太多的信息搜寻行为和太少的信息搜寻行为都不是最优绩效。
通过对信息搜寻成本和信息效用之间关系的分析, 可以发现虽然存在一个理论上的最优绩效点, 但是由于有限理性原则使得用户很难从实践中发现这个最优的决策点。用户的认知局限、信息的不完全性都影响了用户的信息搜寻行为, 因此需要从次最优决策的层次上来探讨用户的行为。
1995年, Pirolli最早提出信息觅食理论, 1997年全球知识大会上前联合国秘书长Kofi Annan指出“信息鸿沟已经成为了区分有无的新的分界线, 那些觅食到新的路径者持续发展, 而其余者不断落后”[ 10]。McCart等[ 8]总结了IFT应用于为图形用户界面设计提供导航线索、选择优化的浏览路径、解释程序设计中源代码导航、理解延迟(Delay)、熟悉性(Familiarity)和广阔性(Breadth)等因素对用户的绩效、态度和意图的影响, 以及网站搜索中分析线索对浏览菜单决策时的作用等领域。IFT假定人们信息搜寻策略的形成是所需信息的有用性收益和交互成本的最优化结果。它和Anderson[ 7]提出的理性分析方法的观点有相似性。Pirolli[ 4]认为用户的Web导航行为呈现两个特点: 最具成本效益和有用性的浏览行为的选择是根据导航线索与用户信息需求之间的关系而做出的; 是否继续在网站上浏览还是离开网站是根据对网站的潜在的有用性和成本的持续评估来决定的。Pirolli将理性选择模型以及动物行为学中的最优觅食理论和微观经济学中的观点和方法应用于预测用户的Web导航行为。2003年Pirolli首次提出了SNIF-ACT模型[ 4], 2007年Pirolli与Fu合作, 完善了SNIF-ACT模型, 形成1. 0版本和2. 0版本[ 5], 同年, Pirolli将其多年对IFT的研究成果出版专著[ 11]。
SNIF-ACT系列模型在其发展中借鉴了许多经典的模型, 如贝叶斯满意模型(Bayesian Satisficing Model, BSM)[ 9]、推理思维的自适应控制架构(Adaptive Control of Thought-Rational, ACT-R)[ 12]。并在此基础上, 根据不同的计算信息效用算法, 形成不同的版本。
(1) BSM
基于有限理性假设, 在构建Web导航模型时需要说明两个过程: 如何评估执行成本函数f(n)以及决定何时能够停止信息搜寻行为。前一过程要求理解用户如何根据经验知识来评估信息线索的效用, 后一过程要求理解信息搜寻行为对成本和信息效用的敏感性。BSM即是根据这两个过程建立的预测用户行为的模型, 如图2所示:
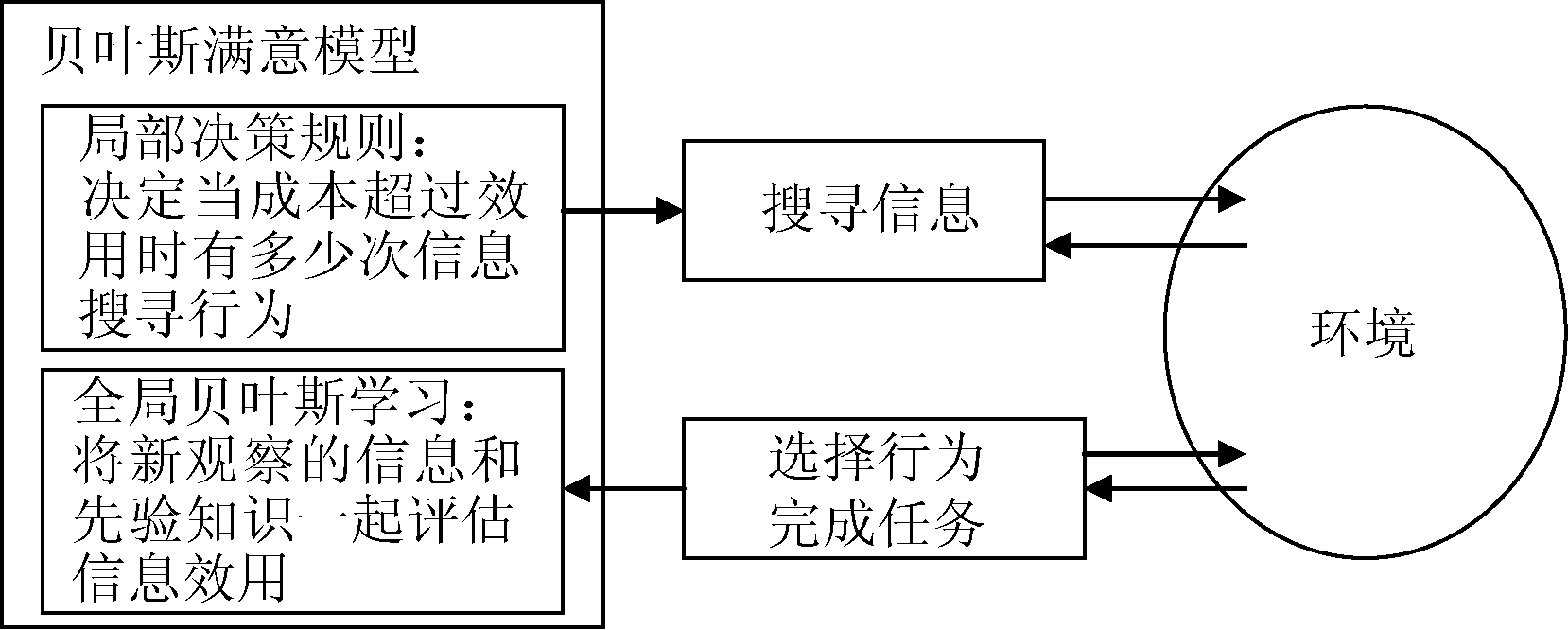 | 图2 贝叶斯满意模型[ 9] |
BSM提出4个假设:
①贝叶斯学习过程是包含新旧信息、与环境不断交互循环的过程;
②模型根据环境现有的知识使用局部决策规则以决定是否停止信息搜寻;
③模型假定信息越多, 完成任务的时间越少, 意味着执行成本越低;
④即使没有信息搜寻行为, 任务也能够根据某些规则完成, 然而当信息搜寻行为的次数不同时, 完成任务的时间即信息效用会变化。
这些假设有助于关注人们如何在不同的环境中, 面对不同的成本和信息效用采取不同的行为。
贝叶斯学习过程允许模型不断地适应环境, 并且从环境中得到更多的信息, 因此提供了一个关于人们如何根据对环境的有限知识来适应性搜寻信息的框架。BSM能够从以下方面预测用户的行为[ 9]:
①根据先前经验, 用户能够在成本和信息效用之间做出权衡, 然后在一个通用的收益递减环境下得出一个具有理性的高绩效。
②用户对成本的反应比对信息有用性的反应更为敏感。
③在一个局部最小化环境(指在信息搜寻行为发生频率较低和较高时, 边际信息效用较高, 而在信息搜寻行为发生频率的中间阶段, 边际信息效用趋于零), 根据局部决策规则, 高成本将带来次最优权衡和对问题空间的更少探索, 因而导致低绩效。
这三个结论正是BSM中所描述的用户行为决策机制。
(2) ACT-R
BSM虽然能够描述用户的信息行为发生机制和终止机制, 但是模型所得出的是一个最优决策点, 实际上由于人类记忆系统、注意系统等认知局限, 不能精确地从数量上描述用户的行为绩效, 因而BSM需要引入合适的心理机制和变量来提高模型的预测准确性。ACT-R模型即是此类模型, 它包括多个集成模块能在更广的范围内预测用户行为。同BSM模型一样, ACT-R也是根据Anderson的理性分析假设, Anderson等[ 12]提出的ACT-R架构包含35个变量和参数, 但是只有部分被引入到SNIF-ACT中。ACT-R模型任务执行的整个过程如图3所示:
 | 图3 ACT-R模型[ 9] |
ACT-R是一个符号认知架构, 包含陈述性知识和程序性知识。陈述性知识在模型中被表示为“块”, 每一个块都有一个激活值决定块的可获得性。程序性知识被表示为状态-行为配对, 或者产生式。ACT-R的核心是噪音冲突解决机制、程序化学习机制和信用分配机制。
①噪音冲突解决机制
当不止一个产生式状态匹配时, 就需要冲突解决机制来决定到底激活哪个产生式。在模型中冲突解决是根据策略效用函数, 计算每一个待匹配产生式的预期效用, 计算结果最高的产生式被选中执行。
②程序式学习机制
ACT-R 的学习过程和BSM的贝叶斯学习机制类似。不同的是, ACT-R中的学习机制不能直接决定信息搜寻次数, 但是产生式预期效用的改变可能影响到该产生式被选中的概率。BSM的学习机制没有区分近期的经验对用户行为影响多于远期经验的这个事实。ACT-R提供了一个时间衰减机制以表明随着时间的推移, 过去的经验对当前行为的影响越来越弱的事实。产生式的成功和失败均随着时间推移, 过去经验的影响越来越小。
③信用分配机制
影响模型学习速度的重要指标是成功和失败的信号。该信号设定越晚, 对早期产生式的影响越大。ACT-R中的信用分配机制因此受到信号设置时机的影响, 设置信号的时间点能控制产生式的成本和收益。
(3) ACT-R和BSM之间的关系
两者的共性包括: 理论基础是理性分析假设; 信息搜寻成本C值的计算依据了贝叶斯过程中用户与任务间的交互与学习。两者的不同之处在于: BSM应用局部决策规则和贝叶斯学习机制以决定信息搜寻行为。在ACT-R中, 利用产生式预期效用的冲突解决机制以实现局部决策, 即用收益与成本的差值(PG-C)来计算预期效用,因而考虑了到达终端目标的可能性以及成本。
ACT-R较BSM的改进有: 采用信用分配机制将一系列行为的实际成本引入产生式中以复杂化激发行为, 即经验成本能够影响将来相同行动被激发的机会。ACT-R中的冲突解决、程序学习和信用分配机制能够模型化BSM中的局部决策规则和贝叶斯学习过程, 该模型另一个优点是能够直接从实验数据中获得计算指标, 支持模型验证。
原始的SNIF-ACT如图4所示:
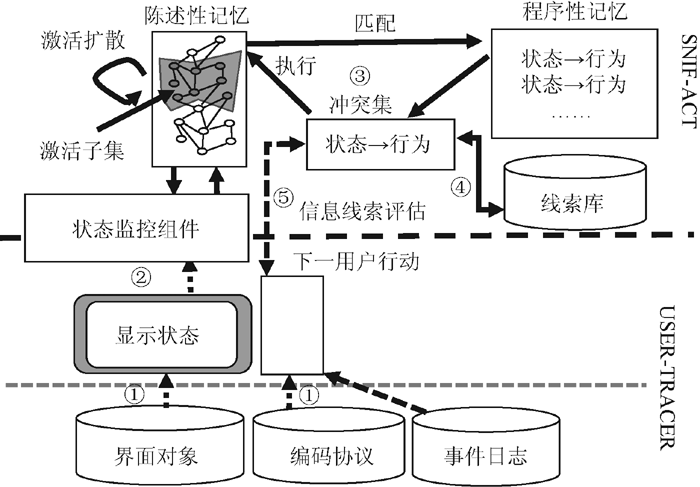 | 图4 SNIF-ACT[ 4] |
SNIF-ACT从ACT-R中继承了两个记忆组件, 即陈述性记忆组件和程序性记忆组件[ 5]。在导航行为中, 陈述性知识被预定义在模型中并保持不变, 包括Web链接内容、导航按钮的功能、用户的当前目标(如评价链接、选择链接等), 该模型假设用户具有使用浏览器的必备知识以及知晓最流行的搜索引擎网址等知识。程序性知识包括一系列产生式集合。SNIF-ACT模拟用户行为和用户踪迹数据匹配过程为:
(1) 解析界面对象, 编码协议及事件日志来决定下一个显示状态和用户行为;
(2) 如果显示状态改变, 则将该信息传递给SNIF-ACT系统, 其中的产生式规则能主动感知显示状态并以块(Chunks)的形式将其更新到陈述性记忆组件中;
(3) 运行SNIF-ACT, 激活扩散陈述性记忆中的活动部分, 匹配程序性记忆组件中的产生式规则来形成产生式冲突集;
(4) SNIF-ACT根据信息线索评估冲突集中的产生式, 从中选择一个将要执行的产生式;
(5) 将选中的产生式和下一用户行动比较, 无论产生式和行动是否匹配都记录相关数据。如果匹配, 执行该行动, 否则继续选择和执行产生式;
(6) 继续重复步骤(1)-步骤(5), 直到没有用户行动为止。
在模拟用户导航过程的各种信息行为模型中, 一个最明显的区分是不同模型描述用户的行为策略选择机制不同。SNIF-ACT是利用激活扩散机制(Spreading Activation Mechanism)来计算Web页面上的链接文字所包含的线索量, 这些信息线索的价值被用来评价行动策略的效用, 如进入一个新的链接、选择链接、回到前一个页面以及离开一个网站等导航策略的效用。激活扩散理论是1981年Rumelhart & McClelland提出的一个认知心理学理论[ 13]。导航中, 用户的认知任务是预测链接标签所指向的页面可能的内容是否有需要的信息, 将用户的认知结构分为表示信息线索的块j和表示信息需求的块i。用户需要对信息线索与信息目标之间的关联强度Sji进行计算, 当关联越强时, 从一个块到另一个块的激活值就越多, 计算某一个链接L相对信息目标G的信息线索效用公式为[ 4]:
 | (1) |
其中, Ai表示信息目标块i的激活值; Bi表示块i的基本激活值, SNIF-ACT中将Bi设置为0; Wj表示对信息线索块j赋予注意力的权重; Sji表示块j和块i之间的关联强度。
在提出SNIF-ACT之后, Pirolli发现作为模型的核心是采用何种机制来选择导航策略, 原始模型利用激活扩散机制, 在随后的1.0版本中, 借鉴了经济学中的随机效用模型和最优觅食理论中的随机搜索模型。2.0版本中还加入了西蒙的满意理论, 吸收BSM机制, 将对信息线索的测量和链接的位置融入模型中。
(1) SNIF-ACT1.0
SNIF-ACT1.0模型主要预测了两种Web导航行为[ 5]: 用户链接选择行为和网站离开行为。两种行为在所有发生的行为中比例达到72%(分别为48%和24%), 其他的行为包括输入URL地址到达一个特定网站、访问书签中的一个收藏网站等, 这些行为因为发生比例较低, 且多受用户的先前知识影响而不是受屏幕上显示的信息的影响, 故不属于1.0模型的研究范畴。
1.0模型继续采用激活扩散理论计算信息线索的效用, 并继承了原模型中的冲突解决机制。1.0模型假设页面上的所有链接都可能被用户依次处理, 改进了原模型中链接产生式选择的计算方式。该模型采用随机效用模型来计算某一个选择链接产生式规则被选中和执行的概率Pr(n|C), 其计算公式为[ 5]:
 | (2) |
其中, C是冲突集; n是第n个链接, 其信息线索IS(n,G)由公式(1)计算, 因为实验环境中G相同, 故简写成IS(n);τ为随机噪音参数。
公式(2)有如下特点: 对某个特定链接的选择考虑了其他链接的效用, 具有同样信息线索的链接之间通过竞争的方式来决定选中概率; 冲突集的规模影响了对某个链接的选择; 随着τ的降低, 模型更有可能选择具有高效用的信息线索链接, 一般τ=1.0, 这是所有基于ACT架构模型的通用值。
(2) SNIF-ACT2.0
除了信息线索的效用影响用户的链接选择行为外, 学者们还发现链接的选择和链接的位置有关, 如Joachims等[ 14]根据搜索引擎的分析得出的结论为人们总是倾向于从头到尾的扫描一个页面, 并且倾向于选择搜索结果中靠上端位置的链接。这个结论也适用于一般的网页。通过信息线索模型和位置模型都很好地拟合了用户的链接选择行为, 也就意味着信息线索量和位置都能预测链接选择, 但是前者的预测力度更强[ 5]。
SNIF-ACT2.0版本正是基于综合考虑信息线索效用和链接位置的影响而提出的一个改进模型。该版本假设用户在选择链接的过程中, 其当前和以前的经验及其在不同的网站交互时的经验都会影响到最终的选择。2.0版本的主要改进是使用一个适应性机制从用户过去的交互经验中学习, 这种适应性机制是假定一个链接被选择的概率是通过贝叶斯学习框架, 用户在一系列从左到右、从上到下的评价中收集数据而对Web页面选择做出理性分析。在决定用户是否追随一个链接以及何时返回到上一页面这两个典型的导航行为中, 主要有三个产生式: 处理链接(Attend to Link)、点击链接(Click Link)、返回页面(Backup a Page), 每个产生式的效用计算公式为[ 5]:
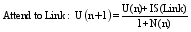

Backup a Page: U(n+1)=MIS(PreviousPages)-MIS(Links 1 to n)-GoBackCost (5)
其中, U(n)表示第n次循环时产生式的效用, U(n+1)表示第n+1次循环时产生式的效用, IS(Link)表示当前链接的信息线索量, N(n)指在n次循环时页面上链接的数目, IS(BestLink)是页面上信息线索量最高的链接, k 是个规模参数, MIS(PreviousPage)和MIS(Links 1 to n)是之前访问页面的平均信息线索量和前n个链接的平均信息线索量。相应的, GoBackCost是回到前一个页面的成本。
2.0版本利用一个随机的、适应性评价和选择机制来评价和选择页面链接。公式(3)和公式(4)是根据BSM和有限理性理论, 公式(5)是根据SNIF-ACT1. 0。
与1.0版本选择的是页面上最优链接不同, 2.0版本只选择了一些足够好的链接, 而无需穷尽所有的页面链接。1.0模型假定用户评估页面上所有链接的可用性, 选择一个信息线索量最高的链接。2.0模型的链接选择方法是根据有限理性理论, 更具有逻辑上的合理性, 但不能保证最好的链接被选择出来。在Pirolli后来出版的著作中指出1. 0模型适应个体用户的行为轨迹, 2.0模型适用于通过蒙特卡罗(Monte Carlo)仿真方法来模拟群体用户的行为[ 11]。Fu和Pirolli通过实验发现SNIF 2.0模型的预测能力要优于1. 0和单纯的位置模型。总之, 尽管IFT是根据理性框架和优化觅食理论, 2.0模型的实施的确包括合理的心理条件, 这是任何一个认知模型, 为了能提供人机交互环境中用户行为描述的一个关键部分。
除了SNIF-ACT系列模型外, 其他基于IFT构建的Web导航模型中较有影响的还有Chi等[ 15]提出WUFIS 模型(Web User Flow by Information Scent), CoLiDes(Comprehension-based Linked Model of Delib-erate Search)以及ColiDes+[ 16]。归纳这类基于信息觅食的Web导航模型的主要特征为:
(1) 该类模型是对用户Web导航过程中的用户认知特征的描述。在用户导航行为中, 用户通过对链接背后的网页内容的预测和自己头脑中的目标信息以及经验、背景知识进行匹配后来判断选择哪个链接。因而, 链接的选择机制主要是在认知层面上进行。正如文献[17]提到“IFT从认知的角度看待用户的信息觅食过程, 并结合信息检索及信息获取等相关理论, 通过设定特定任务目标, 在解释用户的行为方面取得了较好的效果”。Kitajima等[ 18]指出基于信息觅食构建的Web导航模型描述了用户扫描、阅读页面内容、使用搜索引擎、评估、选择链接以及使用各种背景机制(历史列表、后退按钮)等多种行为的混合,是一种认知模型。
(2) 该类模型描述的是用户的有限理性假设和次最优决策行为。Miller等[ 1]曾提出构建Web导航模型时要遵循三个原则: 理性原则、有限能力原则和简单原则。SNIF-ACT系列模型在此基础上用信息搜寻成本和信息效用之间的关系来表示用户导航链接的选择依据, 符合理性原则, 同时引入了BSM和ACT-R模型中对用户有限能力的考虑。BSM的局部决策规则和贝叶斯学习机制来决定信息搜寻行为次数, ACT-R根据产生式的预期效用解决冲突机制, 因而SNIF-ACT系列模型描述的是一种局部环境下的次最优决策行为。
(3) 基于IFT的Web导航模型的优点是使用计算方法来模拟各种认知过程以及自动评估信息结构, 克服了许多其他Web导航模型不能量化处理用户导航策略选择的缺陷, 因而有助于实现用户使用Web导航分析的自动化。SNIF-ACT系列模型根据有限理性假设和次最优觅食理论定义了用户在决定是否继续信息搜寻来寻找更好的导航链接时信息搜寻成本与信息效用的关系公式, 并且借鉴IFT中信息线索计算公式以及贝叶斯学习过程和扩散激活理论, 考虑用户过去的经验对当前的影响, 从而能较有效预测用户的实际导航行为。
Pirolli[ 11]归纳SNIF-ACT系列模型对个体用户和群体用户的导航行为呈现出优秀的适应性。这类模型的核心是一系列简单的产生式规则和一个激活扩散网络, 以及基于理性分析和优化觅食理论的规则结构和效用计算。SNIF-ACT模型为进一步的研究打开了大门, 这是因为ACT-R架构本身拥有许多还没有被充分吸收借鉴的成果。例如, ACT-R包含了感知监控模块(Perceptual-motor Modules), 能被用于提供眼动规律和信息可视化效果。无论是推动理论研究还是商业价值都具有非常广阔的前景。
SNIF-ACT系列Web导航模型继承了IFT的价值, 能用于改进网站导航的设计。在改良Web导航效果方面, 学界主要有两条研究路线: 一条是从面向导航的使用者研究出发, 如研究用户利用导航的规律, 包括心理行为和生理行为; 一条是从导航的设计出发, 例如各种对Web导航系统的可用性评估方法, 旨在为导航找到最好的设计规范和实践。可用性专家Nielson探讨了导航页面上内容所占的比重, 信息线索在导航设计中的应用, 如何减轻用户的认知负荷, 书写风格和图形设计的一些原则[ 19]。但是, 这些成果仅从理论角度提出改进方向, 没有经过严格的科学测试, 只能在一些特殊的设计场合发挥作用。现有的一些模糊的“认知原则”也仅从粗粒度上描述了用户的导航行为, 缺少深层次的应用。SNIF-ACT系列模型则使用了计算模式来模拟认知过程以及量化分析认知是如何影响行为, 其预测能力是其他的一些粗浅的“认知原则”难以超越的。一个很典型的应用SNIF-ACT模型的例子即为Bloodhound系统[ 20], 这是一个网站自动评估的系统, 通过一个爬虫程序采集链接拓扑结构, 然后根据采集的数据来计算每一个链接的信息线索量, 从而预测用户在网站中的导航行为。而文献[ 21]在评价网站的导航性时也借鉴了SNIF-ACT中信息线索的计算方式。
然而, SNIF-ACT系列模型也存在有待改进的问题。首先, 模型假设用户处理Web页面上的链接是线性过程, 这个假设有一定的合理性, 例如通过搜索引擎返回的一个链接列表, 用户依次判断每个链接的信息线索量, 然后做出导航选择。但是, Fu等[ 5]也承认这不能代表所有的Web页面情形。例如, Blackmon等[ 22]研究了按照不同的标题和子类来组织的Web页面结构, 发现用户通常先扫描标题来确定与其信息需求目标最接近的子类, 当标题的信息线索量很大时, 用户的注意力就集中在该标题下的子类中而忽视了该页面上的其他标题。因此, Budiu等[ 23]建议增加一个记忆阶段(Attentional Stage), 并将此想法在一个称为DOI-ACT的模型中实施。Blackmon[ 24]也用实验证实了增加记忆机制的可行性。
其次, SNIF-ACT系列模型是根据普通用户的信息行为提出的, 而非专业级用户, 因而不需要用户具有特别的领域知识而只是一般性的信息需求。但是, 对专业领域的信息用户, 例如医生、工程领域专家等用户群体他们的信息目标较为复杂, 因而简单的SNIF-ACT模型中计算链接相对于信息目标的信息线索量计算公式不适用。因而如何让模型更好地适应不同用户的背景知识也是未来应用面临的挑战。
通过对SNIF-ACT系列模型的分析, 笔者提出基于信息觅食的Web导航模型的可能发展趋势为:
(1) 增加模型对不同页面布局的敏感性, 特别是更多关注用户对页面的视觉注意, 通过实验手段来观察用户的视觉运动与链接选择之间的关系, 综合考虑信息线索的效用与注意对导航行为的影响;
(2) 对模型进一步细化, 按照专业用户和普通用户分别修正信息线索效用计算公式, 分别形成不同背景知识的用户群体的Web导航模型。
笔者相信, 如果在这两方面取得突破, 基于信息觅食构建的Web模型在对用户Web导航行为的模拟和预测方面有更高的应用价值。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|