
{kind=link}
{kind=link}
{kind=link}
{kind=link}
一种利用协同过滤预测和模糊相似性改进的基于内容的推荐方法*
[姜书浩1  , 薛福亮
, 薛福亮2 ]
, 薛福亮|
|


姜书浩: 提出研究思路, 设计研究方案;
薛福亮, 姜书浩: 进行整个实验过程的设计;
姜书浩, 薛福亮: 数据采集、分析和处理, 其中平均绝对误差、覆盖率以及多样性的计算主要是薛福亮完成; 用户特征、项目特征以及相似性计算主要是姜书浩完成;
姜书浩: 论文起草;
姜书浩, 薛福亮: 论文的修改以及最终版本修订。
互联网的海量数据使得用户获取有价值的信息越来越困难, 这一点在电子商务环境下尤为突出, 为了应对上述挑战, 智能推荐系统已成为为用户提供个性化推荐最重要的工具[ 1], 推荐系统(Recommender System, RS)基于用户的兴趣特征和购买行为, 在复杂的网络环境中向用户提供其可能最感兴趣的项目。现在普遍使用的推荐系统中, 主要包含两种最常用的方法: 协同过滤(Collaborative Filtering, CF)和基于内容的过滤(Content-Based Filtering, CBF)。协同过滤通常是在用户群中找到指定用户的相似用户, 综合这些相似用户对某一信息的评价, 形成系统关于该指定用户对此信息喜好程度的预测, 从而给予适当的推荐; 而基于内容的过滤是通过比较包含在项目中的描述内容与用户感兴趣的内容, 从而提供推荐, 与其他相似的用户并没有任何关系[ 2]。当前, 电子商务推荐系统在实际电子商务环境中已经有了比较好的应用, 但仍然存
在许多问题。如协同过滤的推荐质量受到庞大而稀疏的用户评价数据的影响; 基于内容的推荐则受推荐多样性限制, 而严重影响推荐的效果。
基于内容的推荐系统通过分析项目描述来识别用户感兴趣的项目, 但是项目的特征和用户的行为在本质上是高度主观的[ 3], 因此项目的代表性和用户行为建模是创建基于内容推荐系统的主要问题。一些学者提出了基于模糊集的个性推荐方法, 并介绍了该方法的依据和规则, 同时在该领域也做了很多工作[ 4, 5, 6]。但是, 基于内容的推荐系统在某些领域的应用是有缺陷的。例如: 用户在购买单反相机时首先设定购买价格要低于7 000元、配备SD或SDHC卡、1500万像素以上的全高清视频录制功能的单反相机。基于内容的推荐系统返回首选推荐的是一台包含上述功能的尼康D7000。虽然这是一个不错的推荐, 但如果第二、第三和第四的推荐只是在第一推荐的结果上稍作修改而做出的, 那用户就不会太满意。如果用户决定选择其他
品牌, 比如佳能, 那基于内容的推荐系统就无法做出推荐。因此多样性问题是基于内容的推荐系统公认的缺陷。目前, 解决这个问题的常见方法是在基于内容推荐的基础上结合协同过滤推荐, 以消除基于内容推荐系统的多样性问题。一些学者提出了衡量推荐多样性指标。多样性在推荐系统中包含两个层次: 用户间的多样性, 衡量推荐系统对不同用户推荐不同商品的能力; 用户内的多样性, 衡量推荐系统对一个用户推荐商品的多样性[ 7]。
基于内容的推荐与协同过滤推荐是目前推荐系统中的主流技术, 协同过滤推荐通过对未评分项进行评分预测来实现。基于用户的协同过滤算法基于一个这样的假设: “跟你喜好相似的人所感兴趣的东西, 也很有可能是你所感兴趣的”, 基于用户的协同过滤就是找出某个用户其兴趣度最相似的邻居, 从而根据其最相似邻居的兴趣偏好做出未知项的评分预测。协同过滤推荐相对于基于内容的推荐的最大优势在于推荐的新颖性。基于内容的推荐, 主要是基于项目的特征和用户过去的历史偏好的匹配度实施推荐。基于内容的推荐系统难以区分待推荐项目的品质和风格, 而且不能为用户发现新的感兴趣的项目, 而协同过滤推荐系统存在可扩展性和稀疏性等问题[ 3]。因此, 很多研究人员将协同过滤和基于内容的推荐技术结合起来, 以克服它们各自的缺点。Fab系统通过为每个用户生成一个特征模型[ 8], 并基于该特征模型计算用户的兴趣相似度, 从而将协同过滤和基于内容的推荐进行整合。有些学者采用基于用户模糊聚类的协同过滤技术[ 9], 以及采用基于模糊聚类的协同过滤技术[ 10]都是对协同过滤技术进行的基于用户的模糊聚类的改进, 目的也是解决协同过滤系统的稀疏性问题。
在应用系统中, 即使是准确率比较高的推荐也不能保证用户对其推荐结果满意。原因是用户得到的推荐结果可能是非常流行的商品或用户熟悉的商品, 对于这些信息或者商品, 用户很可能早已从其他渠道得到, 因此对用户来说这些推荐意义不大; 而对其他相对陌生或新颖的产品, 系统可能会因为评价较少等原因很少推荐或不予推荐。对于用户间的多样性, 朱郁筱等提出采用计算汉明距离来作为多样性的指标[ 7]。张富国等分析探讨推荐多样性的度量方法, 提出了基于信任的提高推荐多样性的算法[ 11]。而对于用户内的多样性的研究相对并不多见, 本文研究的多样性正是针对用户内产品多样性的改善。在此基础上, 本文又在以下三方面做了改进:
(1) 基于本地和全局的模糊距离, 并利用特征兴趣度测量设计了一个模糊的协同过滤模型。
(2) 通过引入一种“模糊的项目特征表示方法”和“相似性度量”提出了“模糊的基于内容推荐方案”。
(3) 利用模糊协同过滤推荐的项目多样性预测的优势, 以改进模糊基于内容的推荐。提出了一种模糊的协同过滤与基于内容的混合推荐模型。
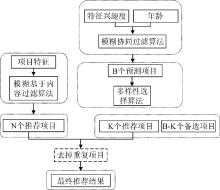
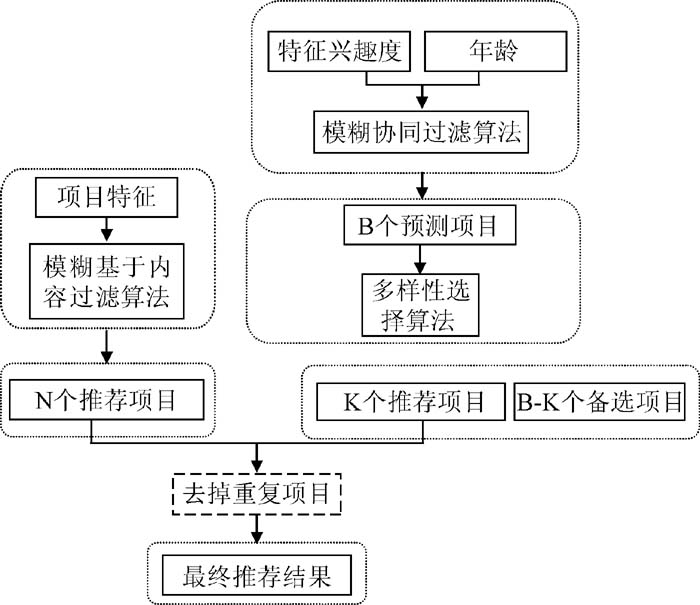
整个推荐框架如图1所示:
本文总共采用了两次模糊算法, 一次是在协同过滤中计算用户相似性时用到, 另一次是在计算项目相似度时。无论是项目还是用户在进行分类时很可能存在某一用户(项目)既属于A类又属于B类, 唯一不同的地方可能是隶属的程度不同, 如果严格按照非A即B的方式, 很可能造成运算结果的偏差, 所以采用模糊的划分方式, 将样本的隶属度值在[0,1]划分到不同类别中。
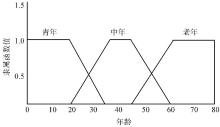
实际应用中, 过于清晰的特征描述并不能反映用户的实际决策需求[ 12], 例如, 18岁和20岁的两个用户的年龄差为2年, 而这两个用户属于同一年龄组, 即青年。因此, 对用户特征进行模糊化的描述具有很大的优势, 反而能检索到最相似的用户群体[ 13]。使用不同模糊集能够用来模糊化各种不同特征的用户。首先, 年龄被模糊化为三个模糊集: 青年、中年和老年, 如图2所示:
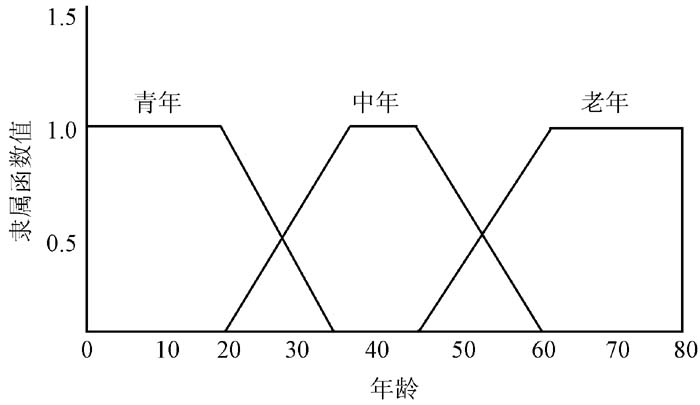 | 图2 年龄隶属函数 |
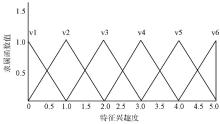
此外, 特征兴趣度模糊化分为6个模糊集合: 很不感兴趣(V1)、不感兴趣(V2)、一般(V3)、感兴趣(V4)、很感兴趣(V5), 以及非常感兴趣(V6)。特征兴趣度在不同的模糊集隶属函数值, 如图3所示:
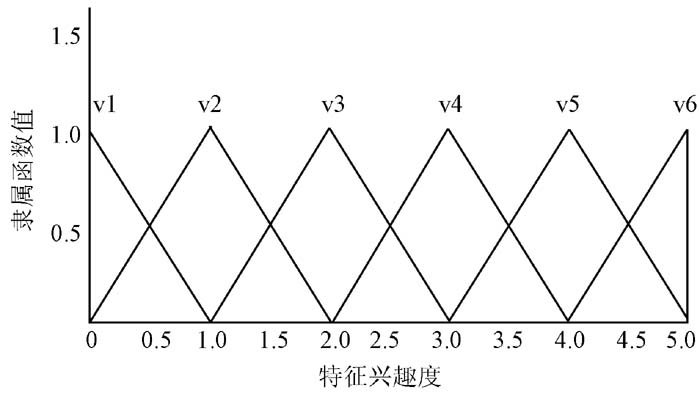 | 图3 特征兴趣度隶属函数 |
用户之间的相似性度量是协同过滤推荐系统获取其最相似用户的关键。用户的特征被模糊化为不同的模糊集, 为了计算两个用户之间的相似度, 对于不同特征之间的局部模糊距离的计算, 笔者提出以下公式:
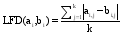 | (1) |
其中, ai,j为用户a的第j个模糊集特征i的隶属度值, 而k是模糊集的数量。为了获得用户之间的全局模糊距离(GFD), 笔者提出通过以下公式得到:
 | (2) |
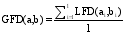
其中, l是a和b的用户特征的数目。对于用户之间的相似度, 笔者使用全局模糊距离来进行计算, 提出公式如下:
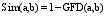 | (3) |
通过用户的相似性计算, 协同过滤系统可为当前用户产生其最相似邻居集合N, 以下公式[ 14]可用来预测该用户在项目S上评分值Pa,s:
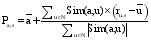 | (4) |
其中, 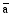
上述算法与大多数推荐算法存在一个相同的问题, 推荐时只考虑了单个项目的准确度, 而忽略了整个推荐项目集对用户满意度的影响。通过以上的模糊协同过滤计算, 可以获得包含B个最优待推荐项目的集合, 但该集合中有些待推荐项目可能存在很高的特征相似性, 这会严重影响到用户对整个项目集的满意度, 所以本文在此基础上提出多样性选择算法以消除上述集合中相似性过高的项目。由于推荐项目集还需进行二次推荐和精简, 所以其中B的取值可以相对较大一些, 这样既增加了推荐集中项目的多样性, 同时在使用多样性算法后去掉相似的项目也不会增加推荐项目集的复杂度。
多样性选择算法将会从B个预测项目中选择K个最不相似的项目, K个项目的选择主要目的是用于提高基于内容推荐的多样性, 其算法思想如下:
输入: 前B个项目与它们的评分值。
输出: K个不同项目的集合R。
步骤:
①从B个项目中选择第一个项目, 作为多样性集合R的当前项目;
②用公式(6)计算当前项目与剩余B-1个项目的相似度;
③将剩余B-1个项目中与当前项目最不相似的项目加入到R, 并把它作为当前项目;
④对R中的每一个当前项目重复步骤①-步骤③, 直到K个不同的项目被找到为止。
多样性选择算法的关键技术是项目间的相似度计算, 推荐项目集在经过多样性选择算法处理后, 会有B-K个项目从推荐集中滤出, 滤出的项目对推荐系统并非毫无意义, 其被滤出的原因是与推荐集中某些项目具有较高的相似性, 可能会给用户造成重复推荐, 后续可根据与K个推荐项的相似性距离进行分组, 在用户需要时作为推荐的备选项。
本节提出一种模糊基于内容推荐的框架, 其中模糊建模将会被用来描述项目特征。
(1) 项目特征描述
从特征的角度来描述项目。在MovieLens电影数据集里, 电影的特征通过其所属风格分类来描述, 如: Movie1(枪战、恐怖、爱情……), 而大部分的项目都不只具有一个分类特征, 很多项目之间都有1-2个分类特征是相同的。假设S={S1,S2,...,SN} 作为项目的集合, 而f为项目的特征, A={F1,F2,...,FN}为项目的特征集合, f可从集合A中取多个值, 项目Sl隶属于特征fj的高斯隶属函数取值可用以下公式[ 14]描述:
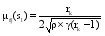 | (5) |
其中, γ为与项目s1与集合A相关联的特征的数目, rk是fj在集合A中的位置等级, ρ 取值大于1。
(2)项目相似度计算
很多学者做过项目的相似度计算的研究, 例如基于项目分类的相似性计算[ 15]。本文的计算方式为项目Sl和Sp可以分别定义为 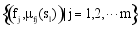
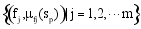
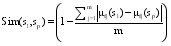 | (6) |
预测当前用户a未评价项目的评分值, 公式[ 14]如下:
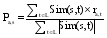 | (7) |
其中, L是用户a喜欢的项目的集合。
本文提出的模糊的协同过滤与基于内容的混合推荐方法的主要步骤如下:
(1) 基于特征兴趣度和年龄的混合特征, 采用模糊协同过滤算法, 获得前B个待推荐项目和它们的预测评分值, 在表2中可以看到采用模糊协同过滤算法(模糊CF)获得的项目预测分值平均绝对误差比未采用模糊预测的简单协同过滤(CF)要低很多, 这也充分说明了模糊方法的意义与优势。
(2) 通过多样性选择算法在预测的B项目中选择前K个最不相似的项目, 实验中选择B的值为20, 对这20个项目选择第一个项目(项目1)与剩余19个项目采用公式(6)进行相似性计算, 选取相似性最低的项目作为当前项目(项目4), 将当前项目与剩余18个项目继续采用公式(6)进行相似性计算, 以此类推。实验数据如表1所示:
| 表1 项目间的相似性 |
从表1中可以看出, 项目1与项目2、项目3、项目5以及项目6相似度是相对较高的, 尤其是与项目3和项目6, 分别高达0.7310和0.8760, 如此高的相似度, 在同一推荐结果中出现显然是严重影响了推荐结果的多样性, 而通过多样性选择算法, 最终选取的项目1与项目4, 其项目相似度仅为0.2344, 可以说这两个项目相似度极低, 依据相似性最后可得项目1、项目4、项目11等5个项目序列为B中最不相似的项目集合, 消除其多样性。
(3) 通过模糊协同过滤可以获得与当前用户具有相似偏好的用户最喜欢的且当前用户未评分的项目集合, 但模糊协同过滤忽略掉了项目之间相似性, 即忽略掉了与当前用户最喜欢的项目具有最大特征相似性的其他项目。因此将模糊协同过滤与模糊基于内容过滤进行融合, 模糊基于内容的过滤可以获取top N个最优推荐项目集合, 本文N取值为5, 去掉模糊协同过滤top K与模糊基于内容top N中的重复项目, 最后剩余的项目集合作为最终推荐项目集合。
为了证明本文提出方法的有效性, 笔者在公开MovieLens(ML)数据集上进行了实验。
MovieLens站点( http://MovieLens.umn.edu/)是一个基于 Web的研究型推荐系统, 用于接收用户对电影的评分并提供相应的电影推荐列表。MovieLens电影数据集包含电影的属性、用户评分和用户人口学特征。该数据集包括943个用户为1 628部电影提供的评分, 评分范围在1-5 之间, 分数值越大说明用户的喜爱程度越高。每个用户至少对20部电影进行了评分。
在实验中, 选择了数据的三个子集, 分别包含50、100和150名用户, 依次称作ML50、ML100和ML150。这样选择的目的是为了证明在不同数量的用户参与下本方案的有效性。选择的每一个子集都被随机分为两部分: 60%的训练数据和40%的测试数据。为了测试方案的性能, 采用平均绝对误差(MAE)和覆盖率作为测试指标来计算实验预测的准确性[ 16], 其中测试集中25%的项目作为多样性选择算法中K的值。
为了说明本设计方案(模糊CF-CBF)具有提供更好的推荐精度的能力, 实验比较了其与模糊基于内容推荐(模糊CBF)、模糊协同过滤(模糊CF)和混合协同过滤的基于内容推荐(CF-CBF)的平均绝对误差和覆盖率, 结果如表2所示:
| 表2 四种方式平均绝对误差和覆盖率的比较 |
其中, 平均绝对误差和覆盖率的计算基于不同的数据集超过20次实验的平均值。推荐性能优越的方案应该有更低平均绝对误差和更高覆盖率。从表2可以清楚地看出, 从预测准确性的角度来看, 本方案的表现要好于其他几种技术方式。在ML100的案例中, 20次不同的实验运行的平均绝对误差如图4所示:
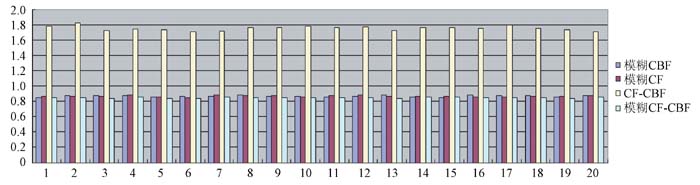 | 图4 100人运行20次的平均绝对误差 |
同时, 由于本方案经过多样性选择算法的二次过滤, 所以在第一次选择中适当增大了选择范围K的数
值, 其目的是通过扩大选择基数来提高项目推荐的多样性。实验分别选择采用多样性选择算法的最终推荐项目(项目1、项目4、项目11、项目15、项目17)和未采用多样性选择算法的top B中前5个推荐结果的项目的相似性比较结果, 如表3和表4所示, 采用多样性选择算法的推荐结果相似性明显低于未采用的, 其中未采用多样性选择算法的top 5推荐结果中项目2、项目3、项目5因具有较高的相似性, 因此被多样性选择算法淘汰。从实验结果看出, 多样性选择算法达到了增加项目多样性的目的, 同时还增强了推荐结果的可信度。
| 表3 采用多样性选择算法的推荐结果 |
| 表4 未采用多样性选择算法的推荐结果 |
本文提出了一种模糊的项目特征描述方法, 以及一种模糊的用户行为偏好建模, 在此基础上着重探讨了基于内容推荐的多样性问题。本文将模糊协同预测与模糊基于内容推荐进行融合, 减轻了基于内容推荐预测多样性的问题, 从而提高了推荐质量。为了验证本文提出的混合模糊协同过滤与基于内容推荐方案的有效性, 设计了一个实验方案与其他三种主流技术(模糊的基于内容推荐、模糊协同过滤和混合协同过滤与基于内容推荐)进行比较, 实验结果表明, 本设计方案优于其他三种方式。
目前的研究内容仅局限于特定的电影推荐系统, 在今后的工作中, 会将该方法拓展到其他特征项目来进一步完善, 以期提高基于内容推荐的精确率。相信随着该方法的成熟, 会很快推广到其他领域, 例如音乐、书籍甚至电子产品等。但是在这些应用领域, 计算项目特征时通常很少能获得用户对项目的评分, 所以在用户评价较少甚至无评价的情况下来生成用户对产品的评价是本算法需要继续探讨的问题[ 16, 17]。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|