

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于社会网络分析的隐性知识推送服务方法研究*
[黄微 , 高俊峰, 王晨, 齐玥]
, 高俊峰, 王晨, 齐玥]
, 高俊峰, 王晨, 齐玥]
|
|


黄微: 提出研究思路, 设计研究方案, 起草论文;
高俊峰: 进行实验以及起草论文;
王晨: 采集、清洗、分析数据;
齐玥: 论文最终版本修订。
知识推送技术应用于数字图书馆领域以来, 凭借其独特的个性化需求获取力度以及高效的知识传播能力成为数字图书馆信息服务的重要组成部分。但随着用户知识需求不断呈现出离散、多样化趋势, 目前主流的知识推送方法也不可避免地暴露出些许弊端, 其中最主要问题是用户隐性知识服务能力不足。
隐性知识能帮助用户突破原有的认知结构对当前认知活动的影响, 具有提升用户对客观知识利用率的重要意义。但是隐性知识需求不同于“看得见”的显性知识需求, 系统能根据用户种子订阅情况或跟踪用户的检索习惯等方式把握用户的显性知识期望, 而面对如何有效获取用户无法感知描述的隐性知识需求, 并且高效地将承载隐性知识载体的数据推送给用户等难题, 本文提出基于社会网络分析的隐性知识推送方法, 采用用户子群划分、用户中心性计算、子群知识共享等策略, 以期为用户提供满意的隐性知识推送服务。
知识推送技术对用户需求的获取方式包括基于内容与基于用户两类[ 1], 前者的核心思想是查找与用户之前喜欢的内容相似的项目集[ 2], 后者主要通过建立用户项目评分矩阵对用户聚类分类建立用户行为模型从而推送信息[ 3]。
目前, 国内外学者对知识推送技术的相关研究取得了丰硕成果:
(1) 在用户群体特征的推荐研究方面, 有学者分析Wiki平台的知识共享与知识交流机制, 提出基于Wiki平台的群体用户双向与多向的知识沟通与推荐模式[ 4]。另有观点指出Web 2.0环境下网络用户群体的划分是基于自相似性与吸引因子两方面, 网络群体的聚合效应对用户的行为具有极强的引导性作用, 可增强相似用户群体内知识的传递[ 5]。国外有学者通过判断用户行为特征的相似程度, 设定阈值K以此获取相似用户集, 提取相似用户群体对某一项目的评价进而推送知识[ 6]。
(2) 基于相似用户群体的知识与行为特征进行知识推荐的实践, 已经深入到利用不同心理与社会影响理论、针对不同应用领域提出相应推送服务。如有文献在知识推送过程中引入了用户兴趣动态变化的概念, 通过设置时间与项目相似性权重, 实时向用户推送知识[ 7]。另有学者提出基于读者特征模型改进协同过滤算法, 通过用户学科信息、专业信息、学历信息的引入降低系统计算候选邻居集的复杂度[ 8]。
(3) 知识推送的技术层面, 经典技术与新兴技术不断融合发酵, 支撑知识推送的发展。如SoNARS 知识推送算法[ 9], 通过融入社会网络分析算法改进协同过滤技术, 进而决定知识推送走向。有学者从语义网格技术层面入手, 构建出具有4层体系架构的智能化数字图书馆知识推送服务系统模型[ 10]。另有学者分析了面向企业业务的智能知识推送服务的可能性, 采用任务管理方法引导企业知识的流向[ 11]。
上述学者从不同的维度出发有针对性地提出了聚焦知识共享、组织与推送的相关方法。然而无论基于知识主体或是基于用户相似度, 知识需求的获取仍然受到用户自身认知能力的限制。用户对知识的感知、加工、编码的多样性导致知识推送服务停留在显性知识相似层面, 在用户知识需求的相互关联与预测(隐性知识相关)层面稍显不足[ 12]。另外依托用户-项目评分矩阵匹配最近邻居集导致推送知识断层现象也制约着知识推送服务的进一步发展[ 13]。
社会网络分析中凝聚子群算法的介入能有效解决隐性知识需求获取的问题, 而通过用户中心性计算能使得最佳隐性知识邻居集的生成有迹可循。
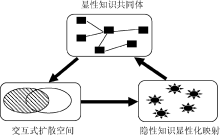
基于社会网络分析的隐性知识推送过程中, 隐性知识显性化的途径可表述为: 显性知识共同体→交互式扩散空间→隐性知识显性化映射, 如图1所示:
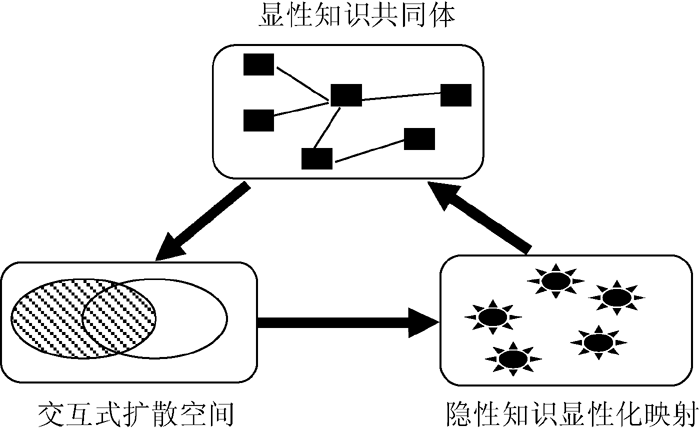 | 图1 显隐性知识演变机制 |
显性知识共同体指相同、相近知识领域工作的人群, 当大量的数据、信息汇聚在共同体时, 知识往往会发生剧烈的碰撞、扩散、交互, 而知识的有机载体会对剧烈的知识运动状态做出相应的反应, 其自身所承载的知识结构得到进一步的发育、成长而重新形成稳定的知识组合体, 并通过知识需求的演变而显性化表述。
隐性知识推送活动中, 显性知识共同体代表具备相似、相关显性知识偏好的用户群, 每一个用户的知识结构像一张布满知识节点的网络, 而具有相似知识背景用户的知识网络必定具有相互重叠的部分, 即关系。假如把用户的知识网络全部节点比为用户可表达的显性知识需求, 那么相似用户知识网络之间不相交的部分即为用户无法准确认识与描述的隐性知识需求, 通过分辨显性知识共同体内知识横向纵向整合轨迹, 进而有序地将隐性的知识单元显性化推送至相应的人群。
因此, 本文提出具有4层结构的隐性知识推送模型, 如图2所示, 通过社会网络分析的方法完成显性知识体构建、知识整合轨迹探寻、隐性知识显性化推送等任务。
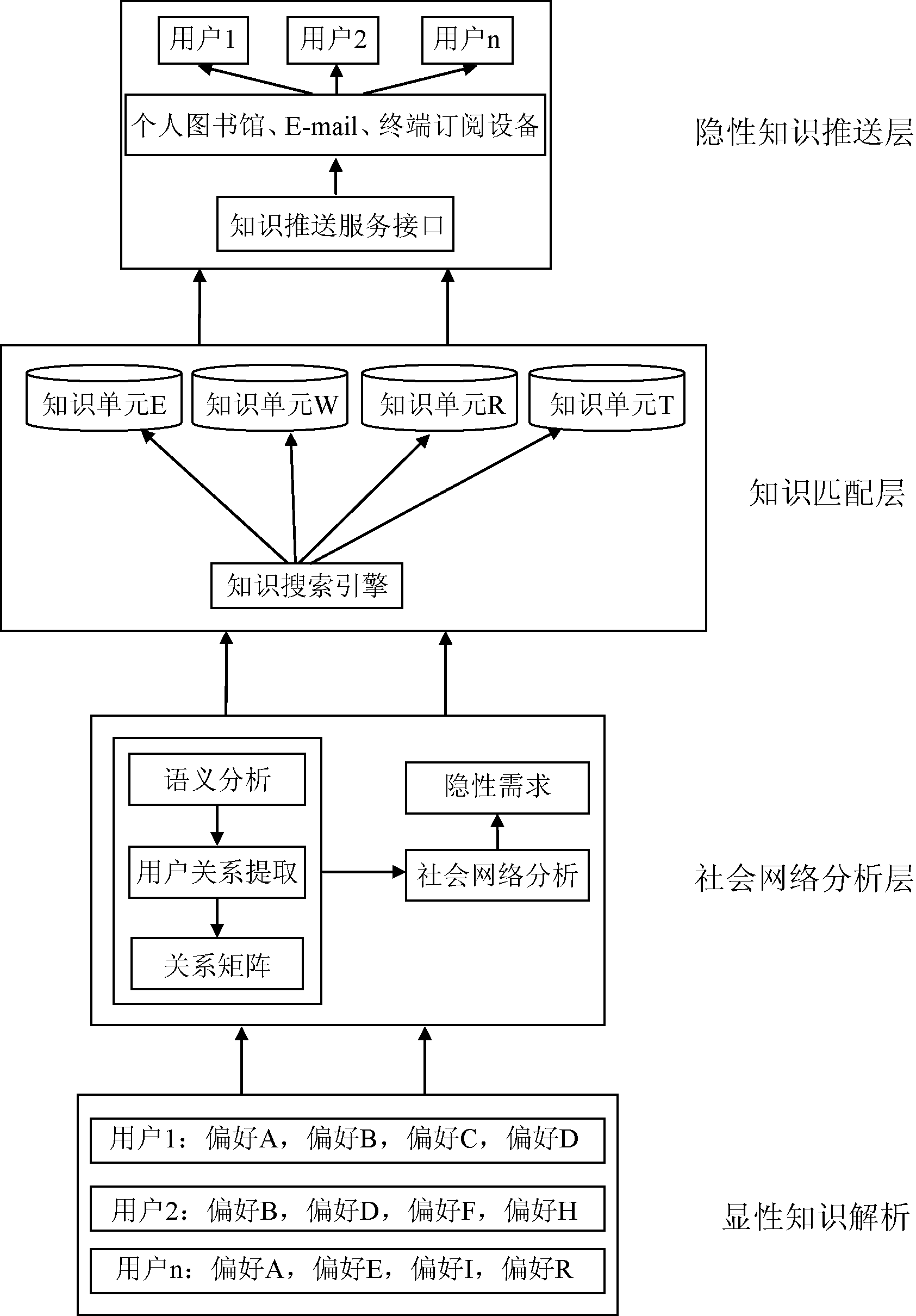 | 图2 基于社会网络分析的隐性知识推 送方法层次结构 |
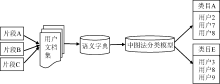
该层提取、清洗、整合用户的显性知识需求并据此划分显性知识共同体。用户显性知识需求是用户发挥主观能动性认识客观世界所展现的独特思维认知, 主要指用户在利用知识服务系统获取知识过程中留下的痕迹, 包括历史检索痕迹、知识订阅痕迹、注册信息痕迹等。笔者所提出的隐性知识推送方法也正是基于具有知识需求一致性的有界群体来完成。显性知识解析步骤如图3所示:
 | 图3 用户偏好处理流程 |
(1) 根据用户的知识检索历史日志和用户预定义的知识种子抽取用户的显性知识需求, 建立用户文档。
(2) 对代表用户知识需求的属性词汇进行初步同义、近义合并, 并形式化表达。例如“本体与Ontology”、“形式概念分析与概念格”, 减少用户间显性知识的关系匹配时间。
(3) 利用《中图法》的一级类目分类模型, 按用户的知识结构与知识需求分类。例如某用户的知识需求包括“Java、单片机、数据结构”三个知识节点, 即将其分入T(工业技术)类。一个用户可根据知识需求的多样性分入不同知识部类。
通过对用户“看得见”的显性知识需求加以解析, 能够准确地定位具有相似知识结构与知识背景的用户群体(如历史知识结构、医学知识结构), 有助于进一步的社会网络分析, 展现出内部行动者知识需求的重合(显性)与分离(隐性)特征。
该层将知识解析层分类出的用户群体进行社会网络分析, 通过分析显性知识需求的语义内涵, 提取用户群中的关系, 计算用户的点度中心性, 获得相似用户子群以及子群中具备触发隐性知识推送动力的核心用户, 算法如下:
设三元组K=(A,T,R), 其中用户集A={a1,a2,…,an}, 显性偏好集T={t1,t2,…,tn}, 集合R为一个二元关系R 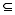
输入: 用户集A, 显性偏好集T
过程:
①对每对ai, aj∈A, 计算偏好相似度:

获取关系集R;
②对每个关系ri∈R,导入关系矩阵matrix(R)中, 生成关系图谱; 对每个包含节点集As的子图, 任意节点ai,aj∈As都有d(i,j) ≤ n, 且任意节点对ay∈As, ax 
③调用点度中心性公式DC(K)= D(K)/N[ 14], 计算用户点度中心性;
输出: 用户子群集N, 用户点度中心性DC(K)
本层主要任务目标是明确隐性知识的发射源与接收端并借助一个智能知识搜索引擎Agent实时搜索知识库中符合需求的知识。
根据社会网络分析的子群理论, 笔者认为, 在一个高凝聚度的子群里, 不直接相邻但距离d满足d ≤ n两个点之间的知识需求具有一致性。基于上述原因, 可以认定子群中某一行动者的隐性知识需求即为同属子群内部其他行动者显性知识偏好的继承, 而子群内中心性节点度高的行动者在知识沟通的过程中扮演关键角色, 是知识共同体内显隐性知识互转化的内推力, 因此以用户中心性为过滤工具, 抽取子群内D(K)值最高的前m个用户知识偏好作为目标用户的最近邻居集(最近邻居集的个数与子群维度n成正比)。
另外由于凝聚子群的知识需求是以一种非线性的动态形式分布, 因此智能Agent需不断将获取的需求逐一提交至知识库中匹配, 并动态监控需求与知识的变化, 合理抽取出待推送知识。
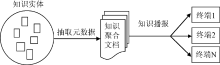
本层将匹配出的知识单元加以编码, 整理出知识的物理链接地址、主题、知识发布者、知识描述文摘等具体元数据, 形成知识聚合文档, 按用户的知识订阅方式(知识推送阅读器、邮件、个人图书馆)逐一播报, 如图4所示:
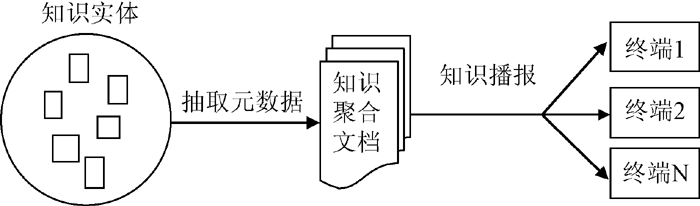 | 图4 隐性知识推送流程 |
笔者选用5个描述标签作为替代知识聚合文档的信息:
笔者通过调研吉林大学图书馆网络数据库的访问日志, 选取24小时内浏览记录中包含的用户知识偏好数据进行实证分析。
基于社会网络分析的隐性知识推送方法与经典的协同过滤推送方法相比, 有三个明显的区别:
(1) 在大数据集环境下, 协同过滤技术按用户对项目兴趣程度产生评分矩阵的推送机制容易忽视知识间的隐性关联, 从而忽略目标用户的隐性知识期望。而以子群为导向的知识推送活动中, 用户显性知识需求形成的子群构成一个知识过载的闭合回路, 通过调整n值而改变用户间关联深度, 进而满足从不同的知识截面推荐项目的需要。
(2) 协同过滤技术关注相似用户集对某一项目的评分选择情况, 基于相似用户群中多数用户共同的知识偏好以此作为少数用户的推荐项目。社会网络分析的隐性知识推送方法更注重群体中显隐性知识间的交叉互补生成推荐项目, 而非通过简单的少数服从多数的办法生成推荐项目。
(3) 用户点度中心性分析的介入在一定程度上缓解了由于信息不完整、推荐种子错误设定等数据稀缺原因而导致最近邻居集生成不准确的现象。按子群内用户中心性高低生成最佳邻居集, 能够准确地辨识目标用户知识需求的动力要素, 进而准确把握用户隐性知识期望。
通过显性知识解析, 笔者发现所截取的用户浏览记录达到1 000余条, 并涉及多领域的知识内涵, 为了更有针对性地说明社会网络分析在隐性知识推送中的意义, 在此选取具有历史知识偏好的21个用户为对象加以分析, 经过偏好的规范化处理得出用户显性知识偏好标签集, 如图5所示:
 | 图5 用户显性知识偏好集 |
经过对21个用户的知识偏好语义归并整合, 最后得出71个知识偏好, 经过社会网络分析, 得出用户知识关系矩阵, 如表1所示:
| 表1 用户知识关系矩阵(部分) |
矩阵中行与列代表相同行动者, 用户间的二元关系由“1, 0”直观体现。由于篇幅原因, 笔者并没有将关系矩阵全部给出, 全部的用户知识关系利用软件Ucinet[ 14]生成图谱展现。
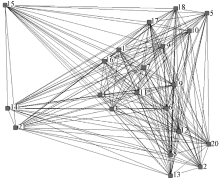
图6为21个用户知识关系的可视化展现, 经过观测不难发现用户的知识偏好虽然同属历史范畴, 但包含多个分支, 因此需要进一步划分出社会网络关系中的n-团子群, 使得获取的隐性知识更具颗粒性。
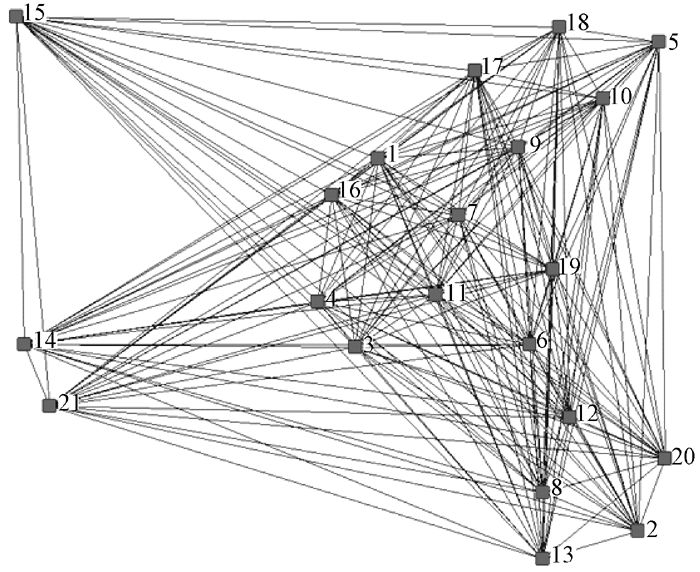 | 图6 历史知识社会网络分析图谱 |
在n-团子群划分中, 将所有节点的邻近值n设置为1时, 意味着子群中所有节点都是相邻的, 但这并不符合本文探索的隐性知识需求通过族群内传递进而共现的思路, 因此将n值设置为2。2是一个有用的临界值, 2-团子群内所有节点不必直接相连, 但相互之间最多通过一个中介节点彼此即可达[ 14]。
经过计算, 历史知识网络共被划分为4个2-团子群(Max Distance (n-)= 2, Minimum Set Size=5):
① {1 7 9 11 16 19};
② {3 4 6 7 11};
③ {2 8 12 13 20};
④ {5 9 10 17 18};
4个子群分别具有的知识属性为“苏联史、中国抗日战争史、欧洲资产阶级革命、明清史”。通过分析三个非子群用户的知识偏好发现用户15的知识偏好T15={商鞅变法}, 知识偏好在知识网络中过于生僻, 无法与其他用户构成关系, 而用户14与用户21虽然互为关系, 然而却不能满足2-团子群划分的最短距离以及最少节点集的约束条件, 因而没有形成知识共现子群。
实验用户在社会网络图谱中的D(K)值如表2所示:
| 表2 用户中心性指标 |
以子群1为例, 子群1所包含的13个知识偏好如下: 8. 19事件、托洛茨基主义、主权有限论、苏波战争、尼古拉二世、布柳姆金惨案、苏芬战争、外贸垄断、喀琅施塔得暴动、古巴危机、尼古拉二世、弗拉索夫、十月革命, 在此笔者选取子群内D(K)值前三的用户(7,11,9)作为用户1的最近邻居集, 获取并推送用户1所不具备的显性知识偏好(布柳姆金惨案、苏芬战争、外贸垄断、喀琅施塔得暴动、尼古拉二世、弗拉索夫、十月革命), 根据社会网络分析的隐性知识推送方法, 推送结果如图7所示:
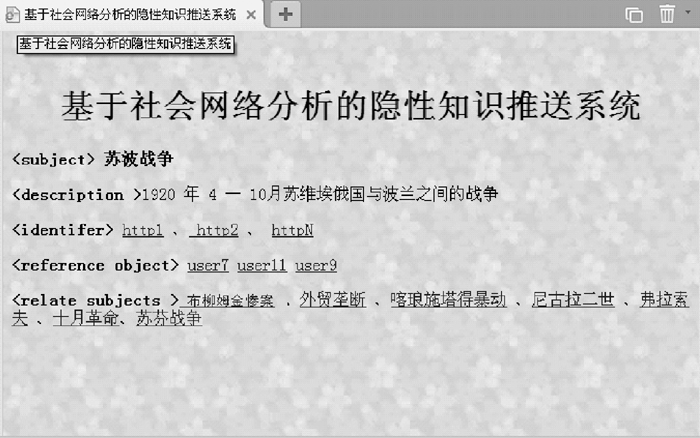 | 图7 隐性知识主题推送 |
分析实际误差可知, 偏好“苏芬战争、外贸垄断、弗拉索夫” 与用户1的显性知识偏好(托洛茨基主义)关联程度不高, 这是由子群维度规模所决定。如果改变n-团子用户群的参数n将会出现不同的知识松散耦合聚合局面, n值越高, 推送隐性知识的广度越大; 相反n值越小, 推送隐性知识的精准率越高。n值过大或过小都会破坏相似用户群体的客观知识结构, 因此子群划分时参数值的选择需要依据实际情况确定。
本文提出的基于社会网络分析的隐性知识推送是建立在对知识群体的关系、群落划分基础上, 其根本是对知识需求之间进行相关性的判断, 子群是基于用户关系的距离划分的。用户关系即代表知识间的互惠, 而具有相关性的知识即是对用户认知上的补充。通过该方法能解决知识推送服务过程中隐性知识服务不足的问题。
实证研究中数据规模较小, 因而推送噪音较低, 但面对海量信息的隐性知识推送服务, 如何自动化地清洗和提取知识偏好数据以及有效评价隐性知识推送服务的效果, 碍于时间、水平有限而没有在文中涉及, 这将成为下一步研究中有待解决的问题。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|