



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
应用开源搜索引擎Solr构建标准信息管理与分析平台*
[王峰 , 魏凤, 刘毅, 周洪, 赵德]
, 魏凤, 刘毅, 周洪, 赵德]
, 魏凤, 刘毅, 周洪, 赵德]
|
|


王峰, 魏凤: 提出研究思路, 设计研究方案;
刘毅, 周洪, 赵德: 数据获取、清洗和分析;
王峰: 论文起草;
魏凤: 论文最终版本修订。
标准情报研究作为情报研究的一个新兴重要领域, 工作人员需要对大量零碎的标准信息进行整理、分析与综合, 揭示产业技术更新规律和模式, 预测未来的技术发展趋势和可能产生的影响[ 1, 2]。但是, 国内外主要的标准化组织网站或标准资源网站, 例如国际标准化组织ISO的官方网站[ 3], 国家标准馆的“国家标准文献共享服务平台”[ 4]以及“江苏省标准信息服务平台”[ 5]等地方标准网站, 功能上侧重于某个组织或行业的标准文献的获取与下载, 未提供专业化的标准信息分析功能, 建设过程相对比较繁琐, 需要对数据库进行大规模查询优化。
Solr是一个基于Apache Lucene的全文搜索服务器, 提供了分面搜索、高亮显示等功能, 同时实现了可配置、可扩展, 并对查询性能进行了优化, 已经在众多大型的网站中使用, 较为成熟和稳定。在数字图书馆领域, 姚晓娜等在采用Solr对中国科学院机构知识库CAS-IR的访问统计部分进行了改进[ 6]; 鲜国建等利用Solr构建了一个中文农业期刊文摘检索系统[ 7]; 陈波基于Solr提出了一种快速高效的分面浏览解决方案改进现有的OPAC系统[ 8]。
本文从国家科学图书馆标准情报研究团队的工作需求出发, 基于Solr对海量数据的良好支持和快速查询响应, 设计开发应用效率高、界面丰富、操作便捷、部署灵活的标准信息管理与分析平台, 为国家科学图书馆标准情报研究团队提供一套高度自动化的信息管理分析工具。
在日常工作中, 标准情报研究团队一般通过“国家标准文献共享服务平台”等标准服务网站收集整理各国各行业的标准信息, 利用计量分析法、文献调研法等情报研究方法, 从各国标准的数量、类别、等效程度、应用行业、应用产品、时间、强制性等几个方面进行分析, 从而得出相应的结论。整个过程需要情报分析人员手工整理大量的标准题录信息, 分类录入到Excel或其他分析工具中进行计算, 费时费力, 数据维护成本高、重复使用难度大。因此, 采用覆盖标准数据管理和分析全流程的自动化网络平台辅助工作是提高标准情报研究工作效率和质量的发展方向。
笔者根据标准情报研究团队的工作流程, 确定标准情报管理与分析平台主要由标准信息管理、标准信息检索和标准信息分析三个功能模块组成。标准信息管理模块主要承担标准信息的录入和编辑, 可以从Excel等文本文件中快速导入数据。标准信息检索模块包含快速检索、高级检索和表达式检索三种检索方式。标准信息分析模块对标准信息要素进行多维统计和定量分析, 由标准总体情况分析、标准产业应用布局分析、标准体系发展现状分析、标准发展进程的演算分析、标准体系变化进程计算分析等5部分构成, 提供分析结果的多种图形可视化展示和数据导出等功能。
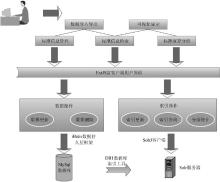
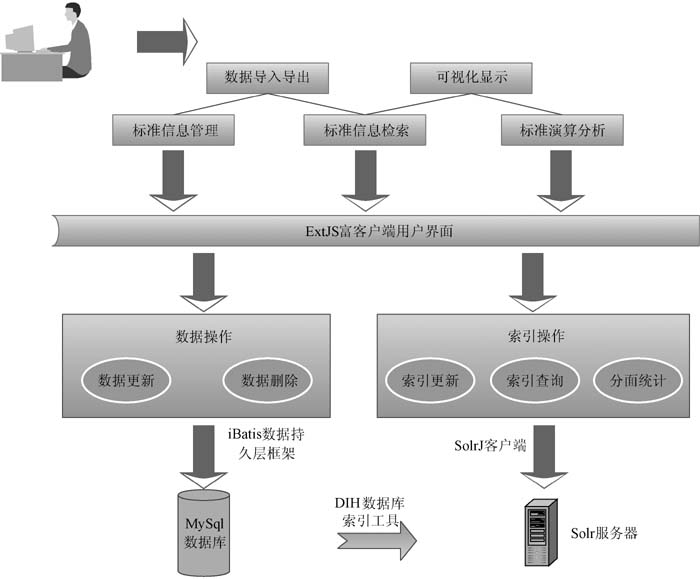
根据平台功能需求, 系统体系结构分为用户服务层、业务逻辑层与数据索引层三层, 采用MVC模式的多层结构设计思想实现业务逻辑和数据显示分离, 各逻辑层之间相对独立, 只提供特定的服务, 功能逻辑发生变化时对其他逻辑层没有影响, 便于系统的更新、复用和扩展。
(1) 数据索引层: 主要负责数据存取和索引服务。系统采用轻量级持久化框架iBatis, 结合Spring框架提供的DAO工厂模式, 进行底层数据库的创建、读取、更新、删除操作和数据库连接的建立与管理; 嵌入部署一个Solr搜索引擎服务器, 利用Solr提供的HTTP客户端SolrJ与Solr服务器通信, 进行索引的建立和更新。
(2) 业务逻辑层: 主要进行程序核心业务逻辑的处理, 向下调用数据索引层接口来进行数据操作, 向上为用户服务层提供服务接口, 对Solr服务器进行管理, 包括查看Solr服务器的状态、返回索引查询结果, 利用Solr的分面搜索功能对预设指标进行计算分析等。
(3) 用户服务层: 通过JSP页面作为载体实例化ExtJS的组件类满足用户的界面外观需求, 完成用户登录、标准检索、标准演算分析、可视化结果显示与输出、数据的导入导出等功能操作。
整体技术框架如图1所示:
索引字段是基于Solr进行信息查询和统计的基础, 笔者首先按照标准信息分析对信息要素的特殊要求, 参考“国家标准文献共享服务平台”以及“江苏省标准信息服务平台”等公开网站的数据格式, 在常见的“标准号”、“标准名称”、“主题词”等基本数据要素基础上, 扩展了“国别代码”、“层级代码”、“应用或行业领域”、“更新年代号”、“性质分类”、“技术领域”等与标准分析相关的数据要素; 然后再根据查询检索和标准分析的不同功能需求, 将这些数据要素设置为不同类型的Solr索引字段, 提高检索响应速度、准确度和数据操作的清晰性和灵活性, 具体设置如表1所示:
| 表1 索引字段 |
数据导入与预处理的目标是: 将标准情报研究团队在工作中积累的以Word、Excel文档或Access数据库等形式保存的标准数据和从国内外一些权威的网站中下载的公开发布的信息存储在统一的数据结构中, 实现异构数据的统一。主要工作包括数据导入、数据预处理和创建索引, 具体过程如图2所示:
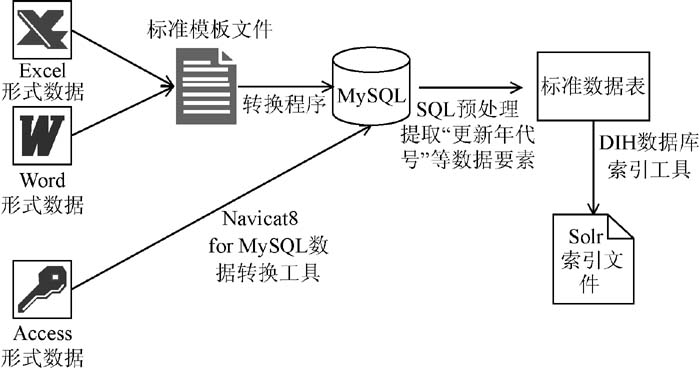 | 图2 数据导入与预处理 |
(1) 数据导入
针对以Word和Excel形式保存的数据, 笔者利用Apache POI设计了专门的转换程序, 遍历文档将数据保存到MySQL数据库中。由于数据来自不同的数据源, 存在异构, 笔者按照4.1节中的标准数据要素设计了一个Excel模板, 将所有的Word和Excel文档中的数据整理成标准格式文件, 然后上传到平台服务器, 再由转换程序统一处理。
对于以Access数据库形式保存的数据, 笔者则使用MySQL客户端工具Navicat8 for MySQL提供的MS Access数据表导入工具直接导入到对应的数据表中。
(2) 数据预处理
由于数据来源不同, 导入的数据中“国别代码”、“层级代码”、“应用或行业领域”、“更新年代号”等关键字段一般为空, 不能满足下一步分析计算的要求, 需要使用一定规则的SQL命令进行统一的预处理。
笔者遵循国际通行的标准号制定规律, 直接在数据库中执行SQL语句从标准号、原年代号等已有字段中提取填充“国别代码”、“层级代码”、“更新年代号”、“原年代号”等信息。例如, 一条中文标题为“釉瓷和搪瓷精饰制件的釉瓷和搪瓷层试验方法的选择”, 标准号为“ISO 4528-2000”的数据, 根据其标准号代码提供的信息, 其层次代码应为“国际标准”, 更新年代号应为“2000”。
(3) 创建索引
Solr提供了DataImportHandler(DIH)数据库索引工具, 支持直接从数据库的查询结果中创建索引, 并提供全量索引和增量索引两种方式。启动Tomcat, 在浏览器中输入http://localhost:8080/solr/dataimport?comm-and=full-import 即可将数据全部导入Solr服务器进行全量索引。278 547条包含14个索引字段的标准数据, 创建索引所需时间为2分42秒。
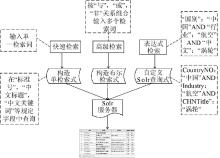
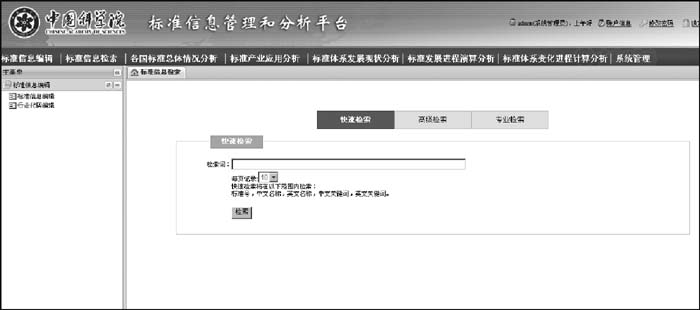
标准信息检索模块提供了快速检索、高级检索和表达式检索等灵活的检索方式。在每种检索方式中, 系统都将用户输入的检索式自动转换为Solr定义的查询语句, 提交到Solr服务器进行检索。
在快速检索中, 用户输入检索词以后, 系统会在“标准号”、“中文标题”、“英文标题”、“中文关键词”、“英文关键词”等索引字段中查询。
在高级检索中, 系统将输入的检索词组合传递到Solr服务器, 每个检索式都包含“与”、“或”、“非”等布尔信息。可供选择的索引字段有“标准号StandardNo”、“中文标题CHNTitle”、“英文标题ENGTitle”、“发布单位DrawupInst”、“中文关键词CHNKeyword”、“英文关键词ENGKeyword”。
在表达式检索中, 笔者根据Solr的查询规则设计了一套检索规则: 含有空格或其他特殊字符的单个检索词用引号(“”)括起来, 多个检索词之间根据逻辑关系使用“AND”或“OR”连接。例如, 要检索有关中国航空涡轮行业的相关标准, 输入的表达式为:“国别”: “中国”AND “行业”: “航空” AND “中文标题”: “涡轮”, 系统转换后对应的Solr查询语句为CountryNO: “中国”AND Industry: “航空”AND CHNTitle: “涡轮”。
检索流程如图3所示:
标准信息的可视化分析是在标准信息数据库的基础上, 根据具体的研究目标, 检索计量标准基本信息要素, 可视化展示分析计算的结果。系统先预设不同的分析指标和分面统计字段, 再利用Solr强大的分面搜索功能, 对分面查询返回的结果多维度演算得出分析结果, 结果数据以可视化图表的方式呈现。具体的分析指标和分面统计字段如表2所示:
| 表2 分析指标和分面统计字段 |
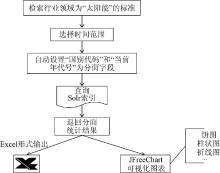
以太阳能技术标准“时间构成分析” 的流程举例说明: 如图4所示, 当用户进行“时间构成”分析的时候, 首先检索行业领域为“太阳能”的标准, 接下来选择时间范围, 系统自动将“国别代码”和“当前年代号”设置为分面搜索字段, 然后查询索引, 获取分面结果, 按年份自动排序, 通过JFreeChart生成可视化图形, 用户可以选择不同图形从多角度查看分析结果, 也可以将分析结果以Excel形式导出。
 | 图4 太阳能技术标准“时间构成”分析流程 |
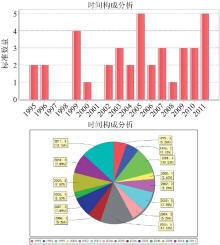
平台已交付国家科学图书馆标准情报研究团队使用, 标准信息数据库存储了约28万条数据, 并且在不断增加中。用户可以根据自己的需求, 在平台的信息分析模块中选择不同的目标国、目标领域和信息要素, 开展标准信息挖掘、标准布局分析、标准化战略分析等研究工作。平台提供了计算分析结果的可视化展示输出功能, 根据业务逻辑层返回的分析结果集, 创建显示图表的数据集, 在ExtJS框架下的用户界面中, 定制饼图、柱状图或者折线图等多种形式图表的对象属性, 将分析结果以JPEG格式在页面输出。如图6-图8所示, 中、美、德等国的太阳能技术标准的时间构成以柱状图、饼图等形式对比呈现。经过综合测试, 检索查询响应时间低于2秒, 可视化分析最慢响应时间不超过7.8秒。
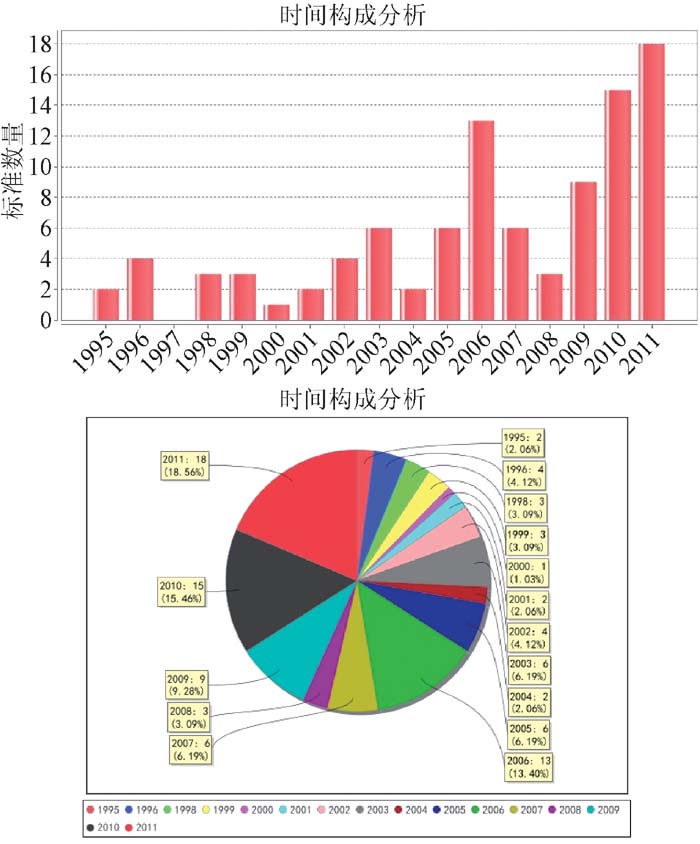 | 图6 中国太阳能技术标准“时间构成分析”的结果 |
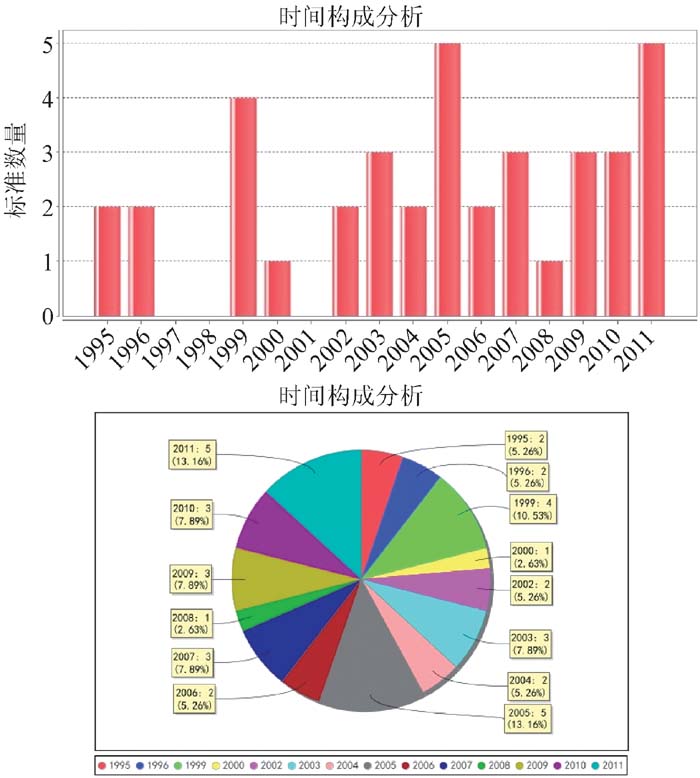 | 图7 美国太阳能技术标准“时间构成分析”的结果 |
 | 图8 德国太阳能技术标准“时间构成分析”的结果 |
标准信息管理与分析平台整合了分面搜索引擎Solr的功能特点, 使用ExtJs富客户端构建用户界面, 数据内容、业务逻辑和用户界面完全独立。平台功能侧重于大量标准信息数据的有效管理、分析和可视化展示, 运行安全、稳定、可靠, 具有良好的功能扩展性。在实际应用中, 基本能够满足标准情报研究团队的信息管理与分析需求, 下一步的工作拟实现更深层次的情报分析功能。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|