{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Primo对MELINETSⅡ元数据收割接口的设计和实现
[唐小新 ]
]
]
|
|


Primo是Ex Libris公司推出的新一代资源发现与传递系统,可实现资源的一站式发现与获取[ 1, 2], 随着各图书馆对新一代资源发现与传递系统Primo的引入, 如何全面地在Primo系统中统一揭示图书馆文献信息资源, 是一项承上启下的工作, 通过使用Primo系统, 图书馆不仅可以平衡对实体和电子信息资源的访问能力, 而且能对检索结果进行规范化和加强, 从而为读者提供适应不同需求的丰富的相关信息[ 2]。而且通过它能够进一步实现对ILS (Integrated Library System)服务功能的外延, 深层次扩展读者服务, 以提高传统纸质图书的利用率。
实现Primo系统对ILS的数据收割, 是Primo全面揭示图书馆馆藏文献的有效途径, 而如何揭开双方系统的神秘面纱, 高效及时地实现Primo向ILS的数据收割, 是每个引入Primo系统的图书馆技术人员必须思考的问题。
数据收割是Primo的基础工作, 图书馆希望将所有资源提供给用户[ 3], 传统的图书馆集成系统ILS以管理馆藏的纸本书刊为主, 各个图书馆的ILS系统都积累了大量纸本书刊的编目数据。如何自动获取ILS 的文献增删改记录, 使得Primo的书目和馆藏数据与ILS 的数据保持同步仍是一项十分艰巨且需要投入技术和人力的工作[ 4]。
MELINETSⅡ作为传统的图书馆集成系统之一[ 5], 在高校图书馆投入使用历史较长, 早期并没有数据收割能力, 在引入Primo系统时, 会面临很多新的问题。例如, 尽管Primo在建设大型集中索引时, 提供内置管道收割元数据的方式, 但仅适用于与其签订元数据收割协议的众多大型的数据库供应商和ILS开发商[ 6]。由于MELINETSⅡ为非签订元数据收割协议的ILS, 就需要构建新的技术方案。
签订协议的ILS用户构建Primo元数据数据库极为简便, 通过Primo内置的数据收割管道进行简单的配置即可实现, 而对于非协议的ILS用户来说, 实现Primo元数据数据库的转换过程极为繁琐复杂, 难度较大, 需要进行元数据分析、元数据转换、元数据映射等多个实现环节的开发, 而且在数据转换过程中因涉及到双方的系统, 数据的操作安全性犹为突出, 从检索的相关文献和对Primo厂商了解的情况来看, Primo对非协议ILS数据收割依赖于从非协议ILS的业务功能模块的数据导出接口通过手工来实现。
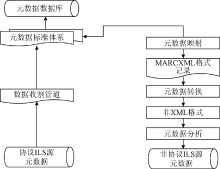
非协议的ILS与协议ILS两种方案的对比如图1所示:
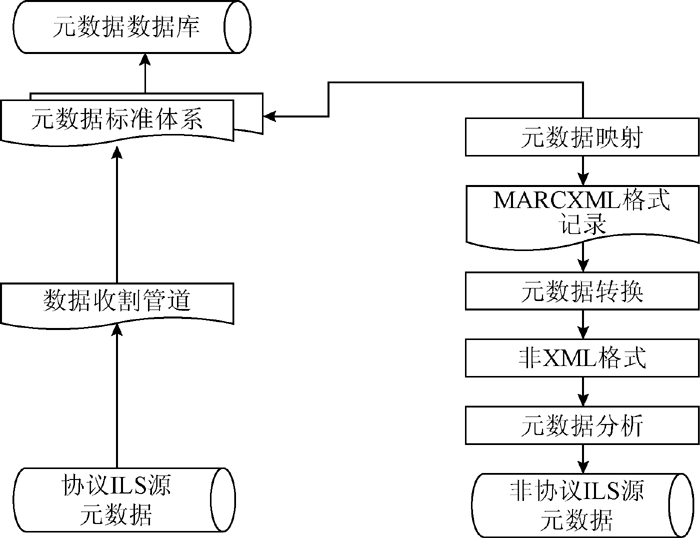 | 图1 资源发现系统结构 |
目前Primo对MELINETSⅡ数据收割普遍采取以下方式:
(1) 通过使用客户端编目子系统, 利用它的目录产品模块, 按条件查询MELINETSⅡ中的馆藏数据, 为保证MELINETSⅡ中的馆藏数据导入到Primo系统中不出现乱码, 查询到的结果集需要以Unicode格式进行输出, 点击MARC输出。
(2) 登录Primo服务器, 将传统纸质图书馆藏数据手动上传至Primo服务器。
显然, 这样的数据收割方式存在一个重大问题: 人工操作环节过多, 导致数据更新的及时性、准确性极大地依赖于操作人员的责任心。如何科学合理地进行馆藏数据收割接口设计, 解决如MELINETSⅡ非签订元数据收割协议的ILS的数据收割时人工操作环节多、数据更新不及时不准确的问题, 以实现无人值守的自动更新, 减轻工作人员劳动强度和劳动负担, 这是每一个图书馆技术人员需要思考解决的问题。
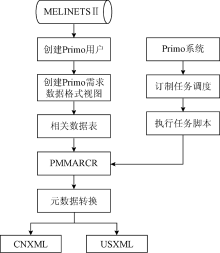
作为非签订元数据收割协议的ILS —— MELINETSⅡ早期用户在面对资源发现系统工作原理中的元数据分析、元数据转换、元数据映射这三项重要工作时, 需要在不改动双方各自系统的前提下, 实现自动收割。为此, 笔者采用中介者设计模式, 在MELINETSⅡ增加一个数据接口来做中介, 该接口导出的源元数据可以满足Primo的数据要求, 然后通过订制任务调度, 定时从MELINETSⅡ的数据接口读取数据并进行元数据转换, 再使用Primo管道进行元数据映射, 如图2所示:
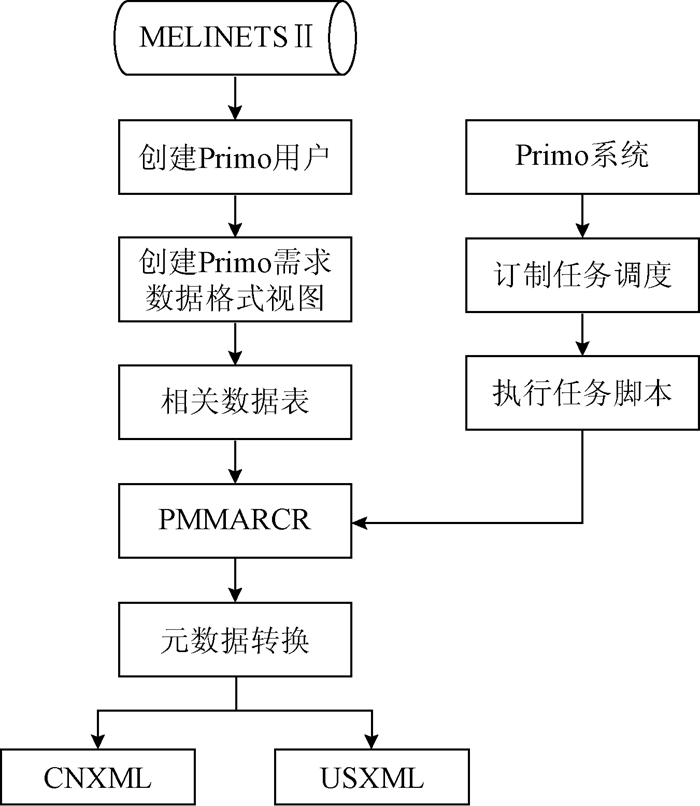 | 图2 Primo数据自动收割设计思路 |
在MELINETSⅡ下创建Primo用户, 通过分析Primo所需的数据格式, 分别从MELINETSⅡ数据库中的相关数据表中提取相应的数据字段, 创建Primo需求数据格式PMMARCR视图, 生成Primo数据接口, 提供给Primo读取。
在Primo中订制任务调度, 定时触发任务调度去执行编写的任务脚本, 来实现系统自动读取MELINETSⅡ中元数据分析后的PMMARCR视图数据接口, 分别转换成Primo所需的中文图书和外文图书XML格式的数据元数据, 保存到CNXML和USXML文件中, 供Primo内置的管道进行元数据的收割, 进而实现元数据映射。
Primo数据自动收割接口实现的关键是在MELINETSⅡ中创建一个可供Primo访问的数据接口, 由Primo去访问使用它, 定期读取所需数据, 这样既能保障在不改变双方系统现状下进行系统间的数据交换, 又能确保数据的安全可靠。为实现该目标, 需要构建元数据接口视图、编写元数据转换脚本、创建运行用户、设置调度时间和配置索引, 其具体实现方式如下。
通过对Primo数据格式的需求分析发现, 为了全面揭示图书馆馆藏文献, Primo需要馆藏文献的MARC数据, 同时在数据中又需要区分数据的文献类型, 还需要提供MELINETSⅡ中数据关联的唯一ID号, 也就是记录控制号。另外通过数次试验, 发现数据的更新以时间为界限较好, 通过对时间的限定, 提取当天的馆藏更新情况, 有利于减少数据文件的传输量及藏馆文献的记录数, 提高系统的更新效率。综上所述, 得出Primo实现自动收割馆藏文献的基本数据格式需求, 如表1所示:
| 表1 Primo馆藏文献数据格式需求 |
由于上述字段分别位于MELINETSⅡ中的table_type、table_A、table_marc三个表, 在创建PMMARCR视图数据接口时, 需要分别从这三个表中提取字段。为了减少Primo对MELINETSⅡ数据影响, 在Primo方案下创建一个视图, 为Primo提供数据接口。
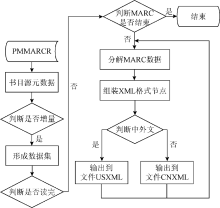
Primo为实现将MELINETSⅡ数据接口提供的数据转换为自身所用的数据, 需要通过编写元数据转换脚本文件来解决。转换脚本主要实现的功能有三点: 连接MELINETSⅡ中PMMARCR数据接口视图; 从PMMARCR读取增量的书目源元数据, 用于Primo中馆藏文献索引的更新; 循环书目源元数据集, 逐条分解MARC数据, 提取MARC中的字段, 组装成Primo所需的XML格式的节点, 形成以MARC-XML格式转换数据记录集文件CNMARC或USMARC。
其元数据转换程序流程如图3所示:
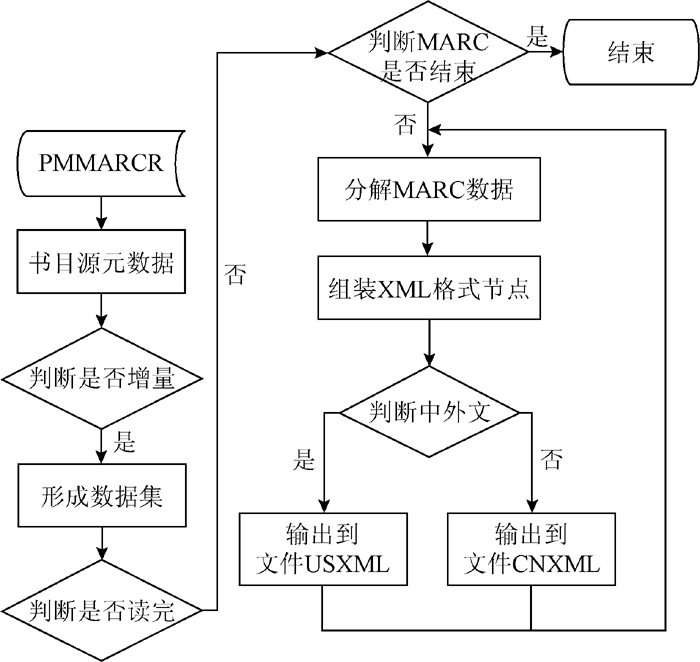 | 图3 元数据转换程序流程 |
元数据转换程序语句, 因篇幅所限, 不再一一列举说明。
对于协议ILS用户来说, Primo提供了内置的数据收割管道, 仅需要做简单的配置即可实现对ILS的元数据进行收割, 而对于非协议ILS用户来说, Primo无法直接访问到ILS元数据, 数据收割在什么时间, 按什么条件进行收割, 都需要进行订制开发, 由于数据收割时需要频繁地访问数据库并进行读操作, 因此, 通过在数据库中直接创建用户供第三方程序进行数据收割效率更高, 安全性更强。
用户是定义在MELINETSⅡ后台数据库中的一个名称, 它是数据库的基本访问控制机制[ 7]。出于对MELINETSⅡ数据安全的考虑, Primo访问MELINETSⅡ中的PMMARCR视图或是读取视图的数据时, 需要为Primo的访问创建一个适合的用户, 并赋予一定的角色及权限。
在MELINETSⅡ中为Primo创建的GXUPRIMO用户, 赋予了CONNECT角色, 仅能访问PRIMO. PMMARCR视图, 而且只能做SELECT操作, 确保MELINETSⅡ数据的安全。
订制任务调度, 按时调度任务脚本, 是执行数据收割的重要环节, 通过它实现数据的定时收割。crontab命令常见于Unix和类Unix的操作系统之中, 用于设置周期性被执行的指令[ 8]。为实现定时调度任务脚本, 在crontab命令中把upd_export.pl脚本的执行加入系统cron jobs中。它的代码如下:
30 23 * * * /bin/tcsh -c "source /exlibris/primo/ p4_1/upd_export.pl"/*每晚23: 30执行任务脚本upd_export.pl */
由于非协议ILS的MELINETSⅡ馆藏文献的元数据是MARC格式, 不是XML格式的数据, 这就需要通过元数据转换接口程序, 把非XML格式的MARC数据, 转换为Primo对应的MARC-XML格式记录, 但是MARC-XML格式的记录依然只能保存在文件中, 无法实现数据库的检索, 因此Primo还需要通过对CNXML和USXML目录中已经生成MARC-XML格式的数据进行收集整理和重建索引, 才能完成元数据标准体系统元数据库建设。该过程通过Primo提供的收割管道和重建索引工具完成, 进行简单的配置即可。
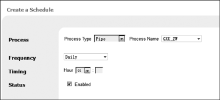
登录Primo Back Office管理界面, 在“Schedule Tasks”的“Create a new Schedule”进行配置, 如图4所示:
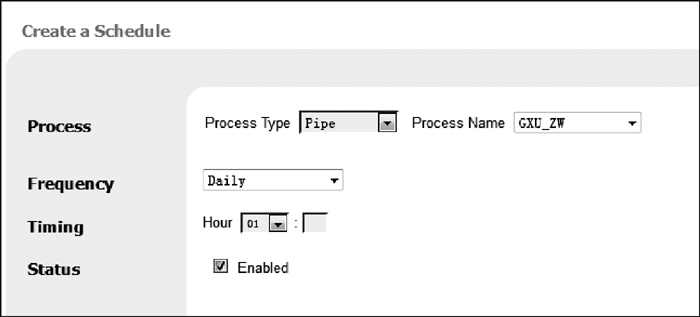 | 图4 Schedule管道和重建索引配置 |
在Process下属Process Type 选项中, 选择“Pipe”或“Processes”来进行数据管道或重建索引, 而对应的Process Name中选择“GXU_ZW”(CNARC数据的收割)、“GXU_XW”(USMARC数据的收割)或者“Indexing_and_Hotswapping”; Frequency定义收割频率, 如果是日更新, 则选择“Daily”; Timing 定义具体收割的时间, 本例中时间为01: 00, 该时间的选择必须要在馆藏书目导出任务脚本执行之后; Status勾选Enabled, 确认数据管道Schedule生效。
当Pipe和Processes的定期任务都定义好之后, 就实现了数据的定期更新, Primo就会自动按照规定的时间和频率装载数据和重建索引。
广西大学图书馆的MELINETSⅡ系统已经上线13年了, 为解决上述数据收割问题, 该馆引入了Primo, 并进行了本文所述的改造和实际应用。在确保双方系统数据安全的前提下, 着重解决发现系统中元数据分析、元数据转换、元数据映射三个难点, 实现了Primo对非签订元数据收割协议MELINETSⅡ数据自动化收割。
(1) 访问控制权限严格, 双方系统数据及运行安全。
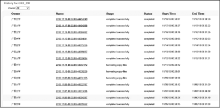
(2) 在Primo对MELINETSⅡ源元数据收割时, 采用底层数据访问, 不需要通过OPAC进行关联, 减少了第三方软件的影响, 稳定可靠。同时数据收割无人值守, 定时执行, 减少了人工操作环节, 确保了馆藏文献数据更新的及时性, 提高了工作效率。数据收割运行日志情况如图5所示:
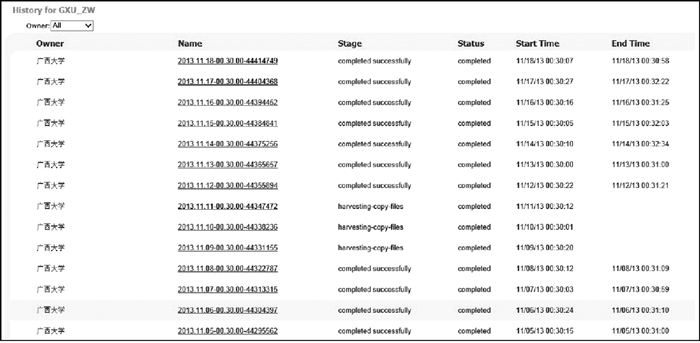 | 图5 数据收割运行日志情况 |
从数据接口运行近一年的日志文件来看, 每天00: 30定时执行收割, 从无间断, 运行稳定可靠, 无需人工干预。
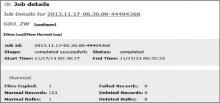
(3) 数据收割采用日增量方式更新, 相对于全库导出的数据更新方式, 更新数据量少, 生成的XML文件小, 更新快, 执行和传输效率高, 如图6所示:
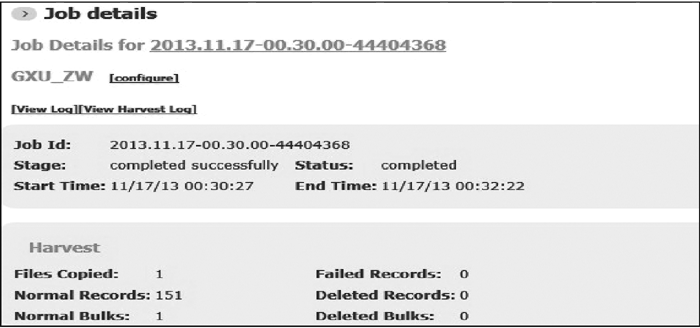 | 图6 数据收割情况 |
在该例中, Primo安装在Linux操作系统下, MELINETSⅡ运行在Oracle数据库环境下, 从大量日志记录的Normal Records中可以看到, 更新日均约为150条记录, 收割时间为2ms, 整个任务完成花费时间为1分多钟, 相对于40万条记录的全库, 人工手动操作需要一天时间, 显然日增量更新数据量少, 效率更高。
由于MELINETSⅡ为Primo的非签订元数据收割协议的ILS, 无法使用协议ILS用户现有的集成管道, 用传统的方式解决数据收割, 将是一项十分艰巨且需要投入大量技术和人力的工作, 自动化的数据收割方式需要额外进行开发。本文的解决方法建立在反复与双方开发人员讨论沟通的基础上, 明确双方的开发边界, 尽可能减少人工操作环节和系统的互访, 实现了无人值守, 以减少图书馆人力的投入, 达到数据的更新更及时、更新效率更高的目标, 对非签订元数据收割协议的ILS和类似电子图书的数据收割自动化具有一定的借鉴意义。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|