{kind=link}
{kind=link}
{kind=link}
机构知识库OAI互操作数据同步策略研究
[姚晓娜 , 祝忠明, 卢利农, 刘巍, 张旺强]
, 祝忠明, 卢利农, 刘巍, 张旺强]
, 祝忠明, 卢利农, 刘巍, 张旺强]
|
|


姚晓娜, 祝忠明: 提出研究思路, 设计研究方案;
姚晓娜: 进行系统开发;
刘巍: 系统功能测试;
张旺强: 论文起草;
卢利农: 论文最终版本修订。
解决在中国科学院联合机构知识库系统建设过程中出现的服务提供方与数据提供方的数据同步问题。
【应用背景】中国科学院联合机构知识库系统基于OAI元数据互操作接口构建而成, 服务提供方只有保持与数据提供方的数据一致, 才能向用户提供准确有效的数据。
【方法】对现有的OAI接口进行扩展, 实现资源集合更新、映射关系更新以及无效数据检测等功能, 并自定义新的元数据模式和操作方式。
【结果】扩展后的OAI接口可有效实现机构知识库资源集合及条目的数据同步, 支持复杂元数据格式的数据交换和共享。
To solve the data synchronization problem between service provider and data provider existed in the construction process of the Federated Institutional Repository of CAS.
[Context]The Federated Institutional Repository of CAS is built on the OAI metadata interoperability interface and provides accurate and effective data to user only if the service provider keeps pace with the data provider.
[Methods]This paper extends the OAI interface and implements functions such as resource sets updating, map relation updating, invalid data detection and customizes a new metadata format and operation.
[Results]The extended OAI interface can effectively realize the data synchronization of resource collections and items between institutional repositories and support data exchange and sharing of the complicated metadata format.
[Conclusions]This method effectively solved the practical problem, and can be referenced by similar systems.
中国科学院联合机构知识库依托于分布在中国科学院各个研究所的机构知识库, 基于OAI接口实现元数据开放获取功能, 通过定期统一收割数据并再组织的方式, 建立起一个全院范围内的数字资产的汇集和共享平台[ 1, 2]。截至2013年7月, 已有83家来源机构知识库, 数据总量达到44.1万。本文的工作正是基于中国科学院联合机构知识库, 在系统开发过程中, 针对OAI元数据互操作接口在数据同步方面的局限性, 对原有接口进行扩展, 有效地解决了实际问题。
开放元数据获取协议(Open Archives Initiative Protocol for Metadata Harvesting, OAI-PMH)[ 3]是一个在分布式网络环境中获取元数据信息的标准化协议, 它将OAI的思想扩展到数字图书馆领域, 通过提供一个元数据互操作框架, 整合网络上不同结构的数字资源, 并以统一的格式为用户提供增值服务[ 4]。OAI-PMH互操作协议以其简单、低门槛、跨平台等特性, 在数字图书馆领域得到广泛的应用。如国外的美国国家数字图书馆项目, 基于OAI-PMH协议对分布在各州的数字图书馆进行有效的数据整合, 给用户提供了一个统一检索的平台[ 5]; 国内的CALIS高等学校学位论文数据库项目在国内高校图书馆的范围内, 采用“各成员单位在本地建立自己的学位论文全文数据库、通过OAI-PMH协议集中元数据”的分布建库方式, 构建了全国性的高校学位论文检索平台[ 6]。
OAI-PMH协议定义了两种逻辑角色:数据提供方(OAI Data Provider)和服务提供方(OAI Service Provider)。数据提供方支持OAI接口, 将本地的资源对象元数据发布出去。服务提供方通过OAI接口从数据提供方获取数据。服务提供方只有保持与数据提供方的数据一致, 才能向用户提供准确有效的数据。因此, 维护服务提供方和数据提供方的数据同步, 成为基于OAI的集成服务平台需要解决的一个关键问题。
由于OAI接口提供的信息较为简单, 使得服务提供方无法对资源对象进行有效的组织和更新。本文在建设联合机构知识库的过程中遇到的相关问题如下:
(1) OAI接口提供的ListSets命令只能获取资源集合的简单列表, 无法获取资源集合之间的层次关系, 如在机构知识库中, 某个专题属于某个部门、某个子部门属于某个部门等关系。根据ListSets命令也无法实现更新资源集合的功能, 需要花费大量时间, 手动更新资源集合。
(2) OAI接口提供的是一种增量查询机制, 只能获取数据提供方在指定时间段内新增或修改的数据, 不能获取被删除的数据, 从而导致服务提供方和数据提供方的数据不一致。而且, 在机构知识库当中可以将一条数据映射到多个资源集合当中, 而OAI接口是按照资源集合进行收割的, 如果某个资源集合下的某条数据已收割, 则不再收割。这样就导致了服务提供方和数据提供方的数据映射关系不一致。
(3) OAI-PMH协议采用都柏林核心元数据(Dublin Core, DC)作为元数据交换的标准集合, 但是由于DC的核心元素只有15个, 无法完成机构知识库中复杂元数据格式的数据收割。
综上所述, 根据现有的OAI接口, 无法解决服务提供方和数据提供方的数据同步问题, 因此, 在实际应用中, 许多研究人员对OAI接口进行了扩展和改进。如在CALIS高等学校学位论文数据库项目中, 针对OAI接口没有提供关于删除数据的处理问题, 提出了一种采用“表单记录”的方式处理删除数据, 数据提供方需要存储最新的删除信息, 服务提供方获取删除信息后, 删除本地的相应数据, 并清除删除信息[ 3]。这样做的优点是只需要获取删除信息, 就可以完成数据同步, 缺点是需要单独开辟空间用于存储删除信息, 而且资源集合和数据映射关系没有更新。Haslhofer等提出将通过OAI-PMH接口获取的元数据转换为关联数据, 并提供SPARQL查询接口, 解决了OAI接口只能从资源集合层次检索资源对象的问题, 并突破了只能通过OAI接口获取数据的限制[ 7]。其中, 数据同步的问题通过关联数据中的关联关系解决, 优点是解决了删除数据和数据映射的问题, 缺点是没有考虑到资源集合对象的同步问题。
在实际工作中, 本文结合项目本身的应用需求, 对OAI接口进行扩展, 增加了如下几个命令, 其中ListTopComms、ListSubComms以及ListSubColls是对原有接口ListSets的扩展, 用于获取部门和专题之间的层次关系, GetOwningColls是一个新的接口, 用于获取条目和专题之间的映射关系, 解决删除条目和条目映射的问题。
(1) ListTopComms: 获取所有的顶层部门, 返回的结果当中包含部门的名称和标识符。
(2) ListSubComms: 获取指定部门下的子部门列表, 需要指定参数commSpec(指定部门的标识符), 返回的结果当中包含子部门的名称和标识符。
(3) ListSubColls: 获取指定部门下的专题列表, 需要指定参数commSpec, 返回的结果当中包含专题名称、专题标识符、专题下的条目数。
(4) GetOwningColls: 获取指定条目所属的专题列表, 需要指定参数itemSpec(指定条目的标识符)。
本文基于上述命令, 分别实现了资源集合更新、映射关系更新以及无效数据检测等功能, 下面对这些功能的实现方案进行说明。
首先, 需要在服务提供方的本地数据库中, 增加用于存储资源集合在数据提供方中的唯一标识符的字段、以及存储专题集合的条目数量的字段。
在对某个数据提供方进行收割时, 先调用ListTopComms获取所有的顶层部门, 将返回结果与服务提供方资源集合进行对比(通过唯一标识符), 如果是数据提供方中存在而服务提供方不存在的部门, 则建立相应的部门并记录唯一标识符; 如果是数据提供方中不存在而服务提供方存在的部门, 则给予删除; 如果是两个集合当中都存在的唯一标识符, 则对比部门名称, 如果部门名称有所修改, 则更新部门名称。然后遍历顶层部门列表, 先调用ListSubColls, 通过指定commSpec, 获取某个顶层部门下的专题列表, 将返回结果与服务提供方相应的资源集合进行对比, 处理逻辑与顶层部门的处理逻辑基本相同, 不同的是ListSubColls的返回结果当中还包含了专题的条目数量, 需要对相应的数据记录进行更新; 然后再调用ListSubComms, 通过指定commSpec, 获取某个顶层部门下的子部门列表, 将返回结果与服务提供方相应的资源集合进行对比, 并做相应处理。处理之后还要对子部门列表进行遍历, 更新各子部门下的子部门和专题列表。资源集合更新的处理逻辑如图1所示:
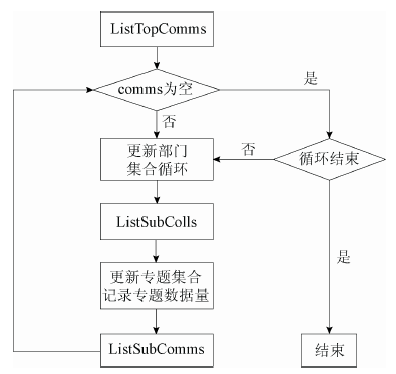 | 图1 资源集合更新的处理逻辑 |
在实际应用中, 经常存在这样的情况, 某个数据提供方导入了某一批数据, 在一段时间之后, 由于各种原因, 将这批数据删除, 而此时服务提供方已经将该条目收割到本地数据库当中。为了保持和数据提供方的一致, 需要对本地数据库进行检测, 删除无效数据。但是联合机构知识库目前已有几十万条数据, 如果对每条数据都进行检测, 将会花费很多时间。所以本文采用检查专题数据量的方法, 对比数据提供方中的专题数据量和本地专题的数据量(从数据库中查询), 如果服务提供方专题的条目数量大于数据提供方中的专题条目数量, 则对该专题下的所有条目进行检测。本文采用GetOwningColls接口进行检测, 如果返回的结果为空, 表示该条目不在数据提供方当中, 对该条目进行删除。
在收割过程中, 映射关系更新和无效数据检测实际上属于同一个步骤, 如果GetOwningColls的返回结果为空, 则视为无效数据, 否则进行映射关系更新。处理逻辑如图2所示:
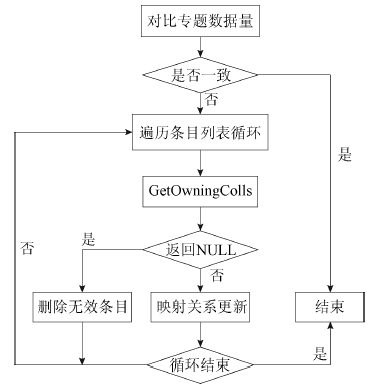 | 图2 映射关系更新和无效数据检测的处理逻辑 |
在对数据提供方收割元数据的过程中, 先调用ListTopComms、ListSubComms以及ListSubColls接口对资源集合进行更新, 然后对各个专题调用ListRecords接口获取上次收割以来更新的条目元数据。所有的专题收割完成后, 再对于条目数量与数据提供方不一致的专题, 进行映射关系更新和无效数据检测。这样就保证了服务提供方和数据提供方的数据一致性, 改进后的收割流程如图3所示:
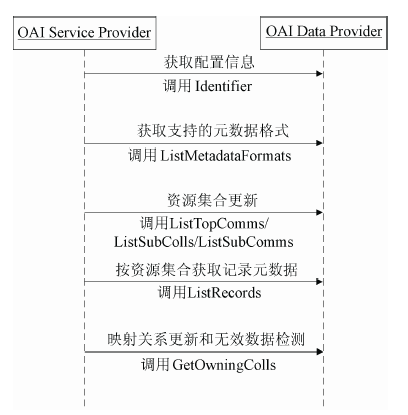 | 图3 改进后的收割流程 |
对于机构知识库来说, 需要对多种不同类型的资源对象进行描述管理, 而面临着在一个开放的信息和知识环境中与多种不同的应用进行交换和互操作的问题, 很难使用一种统一的元数据标准来满足这种多样化的应用需求。因此, 本文在机构知识库的建设过程中, 根据实际应用需求, 本着融合和协调利用多种元数据标准的原则, 以QDC元数据标准为基础, 建立了一种自定义的元数据格式CASDC, 用于描述中国科学院机构知识库中的资源对象。CASDC主要增加了以下几个方面的元数据元素。
(1) 责任者部分:contributor.inventor(专利发明人)、contributor.patentee(专利权人)、contributor. agent(专利代理者)。
(2) 主题和描述部分:discipline(学科主题分类)、subject.major(学位论文专业)、description.version(版本)、description.projectname(项目名称)、description. projectintro(项目简介)、description.cooperation(合作情况)。
(3) 类型部分:type.patent(专利类型)、type. country(专利国别)、type.award(获奖类别)。
(4) 引用相关部分:citation.volume(卷)、citation.issue(期)、citation.pages(页码/数)、citation. conferencename(会议名称)、citation. conference- place(会议地点)、citation.conferencedate(会议日期)、citation.indexed(检索工具收录情况)。
(5) 日期部分:date.application(专利申请日期)、date.copyrighted(版权日期)。
(6) 标识部分:indentifier.citation(引用格式)、identifier.applicationnumber(专利申请号)、identifier. patentnumber(专利号)、identifier.certificatenumber(专利证书号)、identifier.doi(对象DOI标识符)。
(7) 其他:degree.level(学位论文类别)、degree. grantor(学位授予单位)、degree.place(学位授予地点)、publisher(出版者)、publisher.place(出版地)。
在收割过程中, 本文将自定义元数据格式CASDC加入到OAI接口中, 使得服务提供方可以最大限度地获取数据提供方的信息, 解决了机构知识库中复杂元数据的互操作问题。
在建设中国科学院联合机构知识库过程中, 本文对服务提供方使用的元数据收割器OAIHarvester2.0[ 8]和数据提供方的OAI接口OAICat分别进行扩展, 增加上述接口和自定义元数据格式CASDC的相关配置, 并对原有的收割流程进行修改, 实践表明, 改进后的收割流程能够自动完成资源集合的更新, 有效地进行映射关系的更新和无效数据的检测, 明显地解决服务提供方和数据提供方的数据同步问题。目前, 联合机构知识库的收割周期为每周一次, 下面列出2013年5个月的第一周收割后的数据同步情况, 如表1所示:
| 表1 5个月的第一周数据同步情况 |
本文针对联合机构知识库建设过程中的数据同步问题, 从实际应用需求出发, 对OAI接口进行了扩展, 通过增加若干命令的方式, 实现了资源集合更新、映射关系更新以及无效数据检测等功能, 并自定义元数据格式CASDC, 解决了服务提供方和数据提供方的数据同步问题。本文对OAI的扩展是在保持OAI基于默认的公共元数据开放服务接口的基础上进行的, 并不影响与相关系统之间基于OAI的各种标准互操作和服务。本文利用OAI的扩展机制, 通过扩展支持自定义元数据模式和操作, 解决了机构知识库系统之间基于复杂元数据格式进行数据交换和共享的实际需求。但如何使这种扩展能够更好地兼容或融入OAI标准体系, 将继续进行深入研究。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|