


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
汉构: 面向深层语言处理的语法工程
引用本文
杨春雷. 汉构: 面向深层语言处理的语法工程. 现代图书情报技术, 2014, 30(3): 57-64
Yang Chunlei, Dan Flickinger. ManGO: Grammar Engineering for Deep Linguistic Processing. New Technology of Library and Information Service, 2014, 30(3): 57-64
Permissions
Yang Chunlei, Dan Flickinger. ManGO: Grammar Engineering for Deep Linguistic Processing. New Technology of Library and Information Service, 2014, 30(3): 57-64
Copyright©2014, The modern information technology editorial office
This article is the open access journal literature, in the following situations are free to use: academic research and academic exchanges, scientific research and teaching, etc., but don't allow for commercial purposes.
汉构: 面向深层语言处理的语法工程
负责语言学本体研究, 建立测试套件、词库, 部分语法规则的形式化描写; 论文的起草和最终版本修订;
Dan Flickinger: 提出技术思路, 负责语法定制和部分语法规则的形式化描写。
摘要
【目的】
开发面向深层语言处理的汉语普通话在线语法(简称汉构)。
【应用背景】汉构是在DELPH-IN环境内, 基于语法母体, 在LKB平台上开发的可计算汉语语法。它的句法和语义分析的理论框架分别是中心语驱动的短语结构语法和最简递归语义。汉构为进一步开发资源型语法和商用奠定良好基础。
【方法】根据系统的语言学本体研究对语言知识进行形式化描写; 汉构的计算实现经历语法定制、汉语MRS测试套件、词库建设、语法规则定义和MRS描写等环节。
【结果】汉构覆盖汉语基本词类和主要语言现象, 完全覆盖MRS测试套件。
【结论】汉构是最早的中型可计算汉语语法之一, 是形式语法理论和计算语言学领域间开展合作研究的桥梁和有效载体。
关键词:
普通话在线语法(汉构); 语法工程; 中心语驱动的短语结构语法; 自然语言处理
ManGO: Grammar Engineering for Deep Linguistic Processing
Abstract
[Objective]
This article contributes to the development of ManGO (Mandarin Grammar Online) for deep linguistic processing.
[Context]On the platform of LKB (the Linguistic Knowledge Builder) and based on Grammar Matrix, ManGO is developed in the environment of DELPH-IN (Deep Linguistic Processing with HPSG Initiative). The frameworks of its syntactic and semantic analysis are HPSG (Head-driven Phrase Structure Grammar) and MRS (Minimal Recursion Semantics) respectively. ManGO lays a solid foundation for further resource grammar development and commercial application.
[Methods]First, linguistic knowledge is formalized according to systematic Ontological studies. Then, the computational implementation of ManGO goes through grammar customization, creation of a Chinese MRS test suite, lexicon building, definition of grammar rules and MRS representation.
[Results]ManGO covers nearly all the major Chinese word types and grammar phenomona, and fully covers the Chinese MRS test suite.
[Conclusions]ManGO is one of the earliest medium-size computational grammars of Chinese. It serves as the bridge and effective carrier of the interdisciplinary studies across formal grammar theory and computational linguistics.
Keyword:
Mandarin Grammar Online (ManGO); Grammar engineering; Head-driven Phrase Structure Grammar (HPSG); Natural Language Processing (NLP)
1 引 言
计算语法的描写系统非常复杂, 描写对象涵盖词项标注和意义、短语规则、句法规则、篇章和修辞规则等多个层次。在国外, 面向深层语言处理的语法开发经过20多年的发展, 在语言学理论支持、多语种覆盖、计算实现技术和研究成果的商业运用等方面已经积累了许多成功经验[
汉语普通话在线语法(Mandarin Grammar Online, 简称ManGO或汉构)在许多方面符合陆俭明先生对汉语语法工程的期望。
(1) 该语法立足于挖掘和梳理汉语语言事实, 建立面向深层处理的语法体系, 属于基础“理论研究”。
(2) 本研究的理论基础是中心语驱动的短语结构语法(Head-driven Phrase Structure Grammar, HPSG)。该语法是高度“词汇”化、“句法语义”兼重的语法体系[
(3) 汉构是基于小句描写的计算语法, 属于“句处理”层面的研究, 而且在描写机制和计算实现技术方面具有向语篇扩展的潜力。汉构是国际上最早基于HPSG理论、面向深层语言处理的中型汉语语法系统之一。此外, 还有Zhang等[
2 基于HPSG并面向深层语言处理的语法工程
自然语言处理可以分为浅层和深层处理, 前者指基于数据和统计的处理方法。自20世纪80年代后期到21世纪初, 由于计算机的速度和存储量的增加, 浅层处理方法的性能和精确性有了长足进步, 于20世纪90年代成为自然语言处理的主要方法[
虽然浅层处理在稳健性和效率方面有优势, 但是由于自然语言本身的复杂性, 再加上处理大规模语法的计算系统速度缓慢而且空间有限, 计算机无法在合理的时间范围内处理大量文本或执行相对复杂的分析任务, 更无法投入处理效率要求更高的商业应用。
这个问题在2000年由斯坦福大学语言与信息研究中心、德国人工智能研究中心语言技术实验室以及东京大学自然语言处理实验室三方合作, 通过技术革新得到解决。较大文本分析可以在几秒钟内完成, 句子分析的速度可以满足语音识别等应用程序的需要, 甚至在普通的个人电脑上也可进行语法工程开发。
但是, 如果计算语言学家不清楚计算程序的任务和目的, 那么他将成为程序员的“噩梦”[
冯志伟[
2.1 国际合作研究组织: DELPH-IN
基于HPSG的深层语言处理的研究组织(Deep Linguistic Processing with HPSG-Initiative, DELPH- IN)由美国斯坦福大学语言与信息研究中心和德国人工智能研究中心共同发起[
该组织致力于通过综合运用语言学和统计学等方法, 理解文本和话语的含义, 其主要研究领域之一是多语种语法工程开发, 现已开发出8种资源型语法(具体参见EDLPH_IN官网www.edlph-in.net), 包括英语、日语、西班牙语、德语、保加利亚语、韩语、希腊语和挪威语, 并正在开发或完善其他十几种语法(具体参见EDLPH_IN官网www.edlph-in.net)。
DELPH-IN技术已经在全世界几十个研发中心得到广泛应用。DELPH-IN已经确立了面向深层语言处理的形式化标准, 具有可靠的稳定性并支持源代码开放。部分研究成果已经成功地投入商业运用, 如人机对话项目Verbmobil和YY科技公司研发的邮件自动回复系统等[
2.2 语法基础: 语法母体
斯坦福大学语言与信息研究中心“灵构” (Linguistic Grammar Online, LinGO) 实验室自2001年开始致力于建立语法表达的共享形式语法母体(Grammar Matrix), 作为不同语言的语法基础。语法母体的研究可以充分发挥多语种语法工程开发的专业知识优势, 建立涵盖范围广、精确、可执行的语法基础, 并从数据驱动和自下而上的角度, 提出并测试一系列关于语言共性的假设。
根据20多种语法工程开发的经验, 语法学家们提取了各语法之间共有的部分, 为新语法的建立提供帮助。语法母体主要包括基本的特征结构、技术手段、匹配语义描写的类别、基本规则与结构类别等信息[
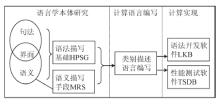
3 汉构的技术思路
本研究使用计算语言对语言学本体研究的发现进行形式化描写, 使用语法开发和性能测试软件开发和完善汉语语法, 主要包括语言学本体研究、计算语言编写和计算实现三个环节。在本体研究方面, 使用的主要语言学理论包括: HPSG理论, 作为句法体系和语义的描写基础; 最小递归语义(Minimal Recursion Semantics, MRS)描写体系[
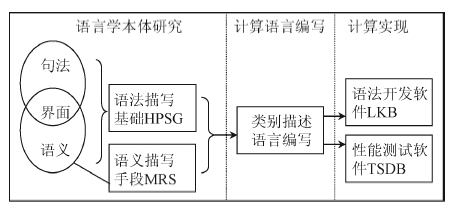 | 图1 汉构的开发流程和使用的工具 |
4 汉构的开发过程
4.1 定制语法
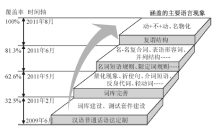
汉构的计算语言编写过程包括定制语法、建立测试套件(具体参见EDLPH_IN官网www.edlph-in.net)、建设词库、描写语法规则等环节。图2显示了汉构开发过程的主要时间节点、相应的测试套件覆盖率以及涵盖的主要语言现象。
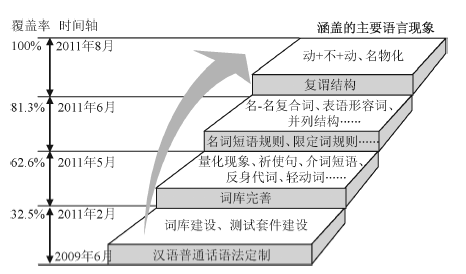 | 图2 汉构的开发进程 |
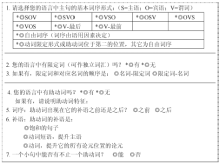
语法母体项目组建立了一系列资料库(Libraries), 用户可以通过基于网络的定制系统(Customization System)获取这些资料库中针对不同语言特征的基础语法描写系统(具体参见EDLPH_IN官网www.edlph-in.net)。用户填写一系列表格, 收集特定语言的特征, 在词序、数、人称、性、格、时体貌、否定、并列结构、一般疑问句、词库(包括主要词类和曲折变化形式)等方面进行参数化设置, 由此自动生成初始语法系统, 包括该语言的语法核心和根据表格信息定制的内容。定制系统使目标语法描写尽可能接近目标语言的特点, 节省新语法的开发成本。关于语法定制的细节可参看文献[3]。下面以“词序”定制页为例看基于语法母体的定制系统需要收集的信息, 该页的摘译如图3所示:
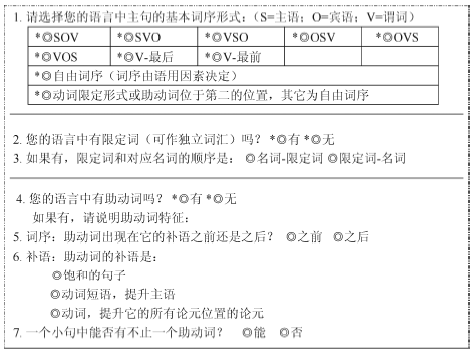 | 图3 语法定制系统的“词序”页 |
4.2 建立测试套件
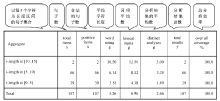
MRS测试套件是12种语言的平行语料, 包括107个原始英语句子、目标语言的翻译、注释(Annotation)和语法现象标记等信息(具体参见EDLPH_IN官网www.edlph-in.net)。该套件反映了语法母体和MRS关注的普遍语言现象, 如词性、语法范畴(如补语、修饰语等)、特殊句式(如被动句、双宾句、动结式等)、一致特征(包括数、性别和人称)、时体和句子类型等。笔者建立了MRS测试套件的汉语版(具体参见EDLPH_IN官网www.edlph-in.net)。该测试套件涵盖的主要词汇类别和语法现象如表1所示:
| 表1 汉语MRS测试套件的基本信息 |
关于测试套件有两点需要说明。首先, 基于定制语法和词库的系统只能覆盖测试套件中不到三分之一的语句。这说明语法母体不能覆盖许多汉语语言现象, 如时体表达、复杂谓语结构、光杆名词短语、反身代词、量化现象等[
b. 下了雨。(ID1(具体参见EDLPH_IN官网www.edlph-in.net))
② a. Zhangsan barked.
b. 张三叫了。(ID2)
①a和②a中的英语一般过去时由动词的过去式标志, 没有歧义。但汉语中的时体主要靠词汇手段(如“了”、“着”、“过”等)实现, 而且这些标记具有多种功能。例如②b可能表示过去的动作或现在的状态, 但如果“了”位于及物动词和它的宾语之间(如①a), 则没有歧义。
其次, 由于语言差异, 测试套件没有也不可能完全覆盖全部语言现象。譬如英语中的主谓一致、动名词、形式主语和小品词(Particle)等语言现象在汉语套件中没有体现出来。
4.3 词库建设
汉构开发的第三步是建立和完善词库。词库描写使用小写字母表示句法概念, 如adv表示副词, s表示小句, arg表示论元, lex表示词项, o-equi表示宾语控制, pfv表示完成标志, crs表示成句成分, post表示“……后”等。符号“:=”表示左端是右端的下层结构, 读为“属于”。双分号是对形式化描写的文字说明。还是以时体标记“了”为例, 具有不同功能的“了”在词库中被定义为不同词项, 如下所示:了_crs := int-adv-s-post & ; ; 成句“了”, 属副词范畴, 位于句末
[ STEM <"了">,] ; ; 书写形式
了_pfv := le-pfv-v-post & ; ; 完成“了”, 位于动词后
[ STEM <"了">]. ; ; 书写形式
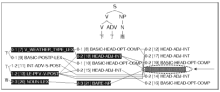
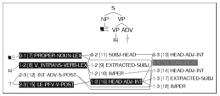
①中的“了”处于动词和名词之间, 做完成“了”解, 相应的分析结果只有一种, 如图4所示:
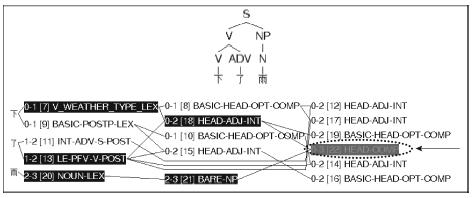 | 图4 “下了雨”的LKB剖析截图 |
本文中的LKB剖析截图包括两部分, 上方是树形图, 下方是分析流程图。通过树形图可以更清楚地看出句子的层次结构, 通过流程图可以看出词项类别、应用的短语和句法规则、句法组合步骤等详细信息。流程图的阴影部分表示最终成功组合的流程。流程图的每个节点包括三部分信息。以图4中箭头所指的被虚线圈出的部分为例, 第一部分用两个阿拉伯数字标明的区间(即0-3), 表示该节点覆盖的词项范围。词项标注按照0-1(第一个词项)、1-2(第二个词项)、2-3(第三个词项)的顺序依次进行。0-3表示此节点覆盖了前三个词项, 1-3表示覆盖了第二和第三个词项。第二部分是方括号中的数字, 是句法组合涉及的节点标识。最后一部分大写字母是HPSG的术语组合(即HEAD-COMP), 表示在该步骤形成的句法结构。因此圈出的部分表示在第22节点组合形成了“中心语-补语”结构。
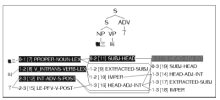
②中的“了”位于句末, 有歧义, 对应两种剖析结果, 分别如图5和图6所示:
 | 图5 “张三叫了”的LKB剖析截图(完成“了”) |
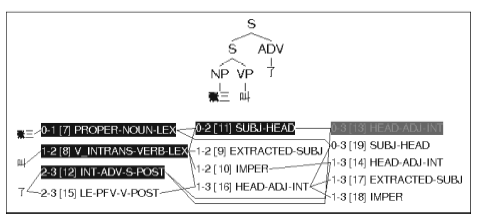 | 图6 “张三叫了”的LKB剖析截图(成句“了”) |
词项描写会直接影响句法分析的成败, 如③:
③ 号码五困扰张三。(ID 103)
③反映了汉语词汇兼类现象。如果在词库中仅仅定义“五”为数词, 如④所示, 由于定制语法中没有规则能把它与之前的“号码”或之后的“困扰”组合, 导致此句无法剖析, 如图7所示:
 | 图7 “号码五困扰张三”的LKB剖析截图(失败) |
④ 五_j := num-adj-lex &
可以看出, 图7中“五”(虚线圈出部分)没有和任何其他成分组合。其原因是此句中的“五”应该被视为名词, 表示数字本身, 而非数量概念, 因此需要增加“五”的名词词项定义, 如⑤:
⑤ 五_n := count-noun-lex &
作名词的“五”和另一个名词“号码”通过“名-名复合短语”规则成功组合, 如图8中的第13节点所示(箭头所指的虚线圈出部分)。
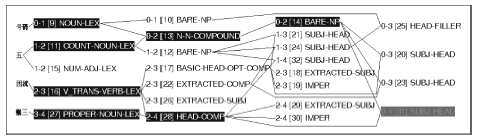 | 图8 “号码五困扰张三”的LKB剖析截图(成功) |
4.4 语法规则
通过特征结构还可对语法规则进行形式化描写, 包括结构类别定义和特征描写两部分, 由符号“&”连接。前者由符号“:=”引入更高层级的结构定义, 后者使用方括号“[]”内的HPSG理论的特征结构描写。描写中的大写字母表示HPSG术语, 如SYNSEM表示句法语义联合体, ARG-ST表示论元序列, LOCAL表示本地性, CAT表示范畴, VAL表示配价, SPR表示先行语, COMPS表示补语等。“[]”内特征之间的句号“.”表示特征结构的路径, 自左至右表示的层级越来越低, 靠左的特征结构包含靠右的结构。如[VAL. COMPS]表示位于更高层级的配价特征(VALENCE)包含的补语(COMPLEMENTS)特征。符号“< >”表示序列, 例如[ARG-ST
应用以上形式描写手段可以描写复杂的句法结构和语义关系。例如在词库描写的基础上, 基于宾语控制理论实现对汉语的兼语式的形式化描写, 如⑥所示:
⑥ 张三让李四叫。
特征描写从最低层次的宾语控制动词结构开始, 逐渐向高层级结构过渡(由黑体字标示)[
v_o-equi-lex := np-vp-comp-verb-oeq-lex.
np-vp-comp-verb-oeq-lex := np-vp-comp-verb-lex &
[SYNSEM.LOCAL.CAT.VAL.COMPS < [LOCAL.CONT. HOOK. INDEX #xarg ], [LOCAL.CONT.HOOK.XARG #xarg ] > ].
np-vp-comp-verb-lex := np-xp-comp-verb-lex &
[SYNSEM.LOCAL.CAT.VAL.COMPS<[OPT-], LOCAL.CAT. HEAD verb ] > ].
; ; 该结构中的第一个补语, 即NP2, 不可缺省且第二
个补语的中心语为动词。
; ; 该描写规定了NP2(即⑥中的“李四”)不能省略, 即
不能说“张三让叫”。
np-xp-comp-verb-lex := main-verb-lex & basic-three-arg-no- hcons &
[SYNSEM[LOCAL.CAT.VAL.COMPS< #comp1, #comp2>, LKEYS.KEYREL [ARG1 #ind, ARG2 #ind2,ARG3 #ltop]], ARG-ST < [LOCAL[CAT[HEAD noun, VAL.SPR<>], CONT.HOOK.INDEX #ind]], #comp1 &
[LOCAL[CAT [ HEAD noun, VAL.SPR<>], CONT.HOOK.INDEX #ind2]], #comp2 &
[LOCAL[CAT[VAL[SUBJ
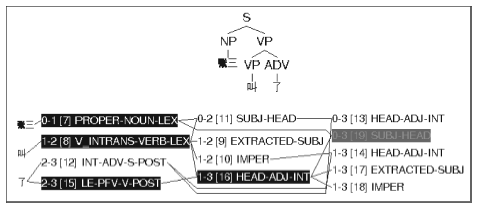
基于以上描写, 使用LKB对⑥进行自动剖析的结果如图9所示:
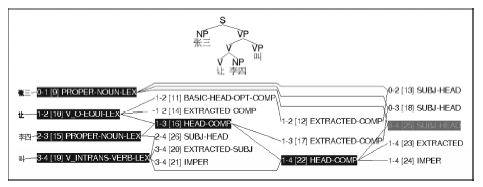 | 图9 兼语式的LKB分析截图 |
根据流程图, 首先, 宾语控制动词VP1“让”(第10节点)和NP2“李四” (第15节点)通过“中心语-补语”规则组合成短语(第16节点), 即“让李四”; 然后“让李四”再次通过“中心语-补语”规则与及物动词“叫”(第19节点)组合成短语(第22节点), 即“让李四叫”; 最后, “让李四叫”和专有名词“张三”(第9节点)通过“主语-中心语”规则组合成小句(第25节点), 即“张三让李四叫”。
4.5 汉构语法的测试结果
汉构的开发基于系统的语言本体研究, 挖掘语言学事实, 从面向深层语言处理的角度总结规律, 并使用HPSG的描写机制进行形式化描写。该系统涵盖了汉语的基本词类和语言现象, 如复谓结构、名词短语规则、“VP+不/没+VP”结构、双宾结构、“把”字句、名物化、定语-表语形容词转化、小句形式做名词性成分、并列结构、限定成分位置、结果补语等。
经过两年多的合作开发, 汉构的语法体系目前共有大约5 200行语法规则描写, 具有以下特点: 词汇信息丰富; 基于语法母体; 基于短语和句法规则; 基于HPSG和MRS; 完全覆盖MRS测试套件; 覆盖汉语的某些特殊语言现象, 如单枝名词短语规则、兼语式等。具体分析结果如图10所示:
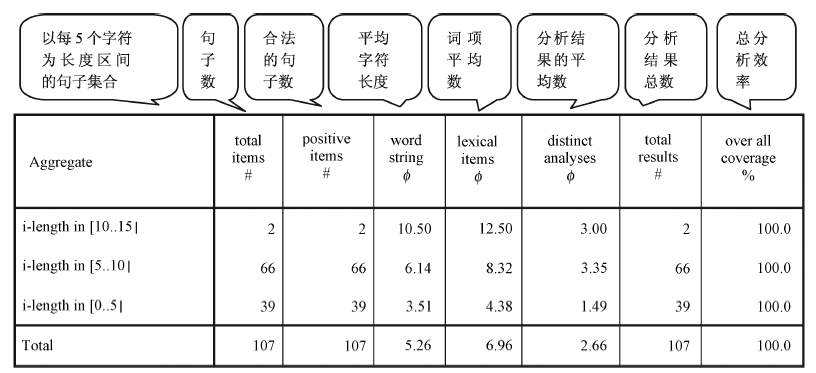 | 图10 汉构完全覆盖MRS测试套件的TSDB截图及说明 |
5 结 语
汉构完全覆盖但不限于MRS测试套件, 是最早的中型可计算汉语语法之一, 是形式语法理论和计算语言学领域间开展合作研究的桥梁和有效载体。汉构在国际上已经被多次使用和引用, 并受到良好评价[
下一步, 仍需拓展汉构的覆盖范围并提高分析效率。为此, 一方面, 将建设一个涵盖更广泛语言现的测试套件, 然后基于此套件不断扩充词库并完善汉构的语法规则; 另一方面, 计划通过甄别歧义素(Discriminant)等手段对树库中的树形图进行筛选并进行相应的系统改进, 消除自动剖析和语言生成(Generation)过程中不合理的歧义分析。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|