
{kind=link}
{kind=link}
面向用户意图的智能搜索引擎框架研究
引用本文
郑炜, 梁战平, 梁建. 面向用户意图的智能搜索引擎框架研究. 现代图书情报技术, 2014, 30(3): 65-72
Zheng Wei, Liang Zhanping, Liang Jian. Research on the Framework of a User Intent-oriented Intelligent Search Engine. New Technology of Library and Information Service, 2014, 30(3): 65-72
Permissions
Zheng Wei, Liang Zhanping, Liang Jian. Research on the Framework of a User Intent-oriented Intelligent Search Engine. New Technology of Library and Information Service, 2014, 30(3): 65-72
Copyright©2014, The modern information technology editorial office
This article is the open access journal literature, in the following situations are free to use: academic research and academic exchanges, scientific research and teaching, etc., but don't allow for commercial purposes.
面向用户意图的智能搜索引擎框架研究
设计研究方案, 研究过程实施(包括实验), 论文起草和最终修订;
梁战平: 提出研究思路, 实验方案设计;
梁建: 实验数据获取, 论文修订。
摘要
【目的】
提出一套基于用户搜索意图的智能搜索引擎系统框架理念, 并研究核心排序算法。
【方法】基于用户搜索意图从内容存储、内容检索以及内容排名三个方面出发对搜索引擎算法进行重构, 并在内容排名算法中综合考虑内容的相关性、可靠性、多样性以及热度等因素。
【结果】实验表明基于意图的智能搜索算法与传统的基于关键字的搜索算法相比返回结果的相关度更高, 而且高相关度表现具有较高的稳定性, 处于对传统方法的支配地位。
【局限】构建智能搜索引擎是一个庞大的工程, 还有诸多技术和工程问题没有深入研究和解决。搜索排序算法还需要进行大量的实验进行验证和改进。
【结论】本研究为构建新一代基于意图的智能搜索引擎奠定基础。
关键词:
智能搜索; 用户建模; 检索; 排序
Research on the Framework of a User Intent-oriented Intelligent Search Engine
Abstract
[Objective]
This paper proposes a framework of the intent-oriented intelligent search engine system, and studies the key content ranking algorithm in detail.
[Methods]This paper reinvents the search engine algorithms based on the user search intent in three aspects, i.e., content storage, content retrieval and content ranking, and considers multiple factors in the content ranking algorithm, including relevance, reliability, variety and hotness of the content.
[Results]Experiments indicate that the relavence of the search results from the intent-based intelligent search algorithm has stably better performance which dominates the traditional keywords-based algorithm.
[Limitations]Building intelligent search engine is so complicated that there are still many technical and engineering problems to resolve. Much more experiments need to be conducted to futher verify and improve the content ranking algorithm.
[Conclusions]This research lays a foundation of building the next generation intent-oriented intelligent search engine.
Keyword:
Intelligent search; User modeling; Retrieval; Ranking
1 引 言
在当今“信息爆炸”的时代, 互联网上的资源和信息浩瀚如海, 并且以惊人的速度持续增长, 因此准确有效地定位相关信息成为网络用户最为迫切的需求。谷歌、雅虎、必应、百度等各大搜索引擎充当着为用户快速有效获取有用信息的重要角色。然而, 随着网络信息的剧烈膨胀, 传统的搜索引擎渐渐不能满足用户日益个性化和精确化的搜索需求。目前的搜索引擎对于用户查询往往仅仅从关键词角度出发进行相似度匹配, 而不是从用户真正搜索意图出发搜寻相关信息, 使得返回结果和用户真实意图有较大出入。用户不得不在搜索信息时还得从搜索引擎返回的结果中一一筛选有用信息, 加重了用户负担。新一代“智能”的搜索引擎研究迫在眉睫。
本文在当前搜索技术研究成果基础上, 针对目前搜索技术存在的一些问题和缺陷, 使用数据挖掘领域前沿技术对海量网页数据进行分析处理, 从内容存储、内容检索以及内容排名三个方面出发对搜索引擎算法进行重新建模, 基于用户意图的模型构建方式使得提出的智能搜索算法更加贴合用户真实想法, 符合用户日益个性化的信息搜索需求。
2 互联网智能搜索引擎研究现状
经过近20年的发展, 互联网搜索引擎技术已经发展了三代。1994年第一代搜索引擎WebCrawler在美国诞生, 并随着Yahoo的成功而迅速发展。研究表明, 第一代搜索引擎仅仅能收集到互联网上全部页面的16%, 甚至更低。同时, 第一代搜索引擎还存在一系列问题, 比如结果相关性较差、排序缺乏合理性、检索结果数量超过用户接受能力等[
然而, 目前第三代智能搜索引擎仅仅是停留在概念和研究阶段, 还没有一个成熟有效的框架来支持信息的智能搜索, 也没有比较成熟的商业应用出现。目前围绕搜索引擎“智能化”的研究主要集中在两个方面: 一是对搜索请求的更好理解, 另一个是如何让搜索结果更加精准和个性化。用户在使用目前的搜索引擎时需要首先根据自身的搜索目的来决定搜索的关键词组合, 关键词选取的好坏很大程度上决定了搜索的结果。而智能搜索引擎的目标是支持用户直接以类似人与人交互的问答方式进行搜索, 用户直接用自然语言输入问题或者目标, 由搜索引擎来自动理解搜索请求。目前这方面的研究主要集中在自然语言理解以及语义网络等智能技术[
目前的搜索引擎主要是根据网页与搜索关键词的相关度来返回搜索结果, 并未考虑到用户的个性化信息。比如, 同样是搜索空调, 北方用户和南方用户对空调功能的需求是不同的, 因此搜索结果也应该有所差异。用户的地域、年龄、性别、个人爱好等诸多因素都会影响到他们对搜索结果的期望。实现个性化搜索的关键是要能够准确识别出用户的搜索意图。针对用户搜索意图识别研究的主要思路是通过分类研究等方法预先定义搜索意图的分类, 如信息寻找意图、知识询问意图、建议咨询意图、资源下载意图、导航意图等, 然后通过分析用户搜索关键词和搜索行为等数据动态匹配出用户的搜索意图进而定制搜索结果[
针对智能搜索引擎的研究和探讨一直是近10年来的热点, 然而市场上至今仍未出现真正意义上的智能搜索引擎, 从侧面说明了目前的研究和应用还存在很多问题, 仍然处于概念和探索阶段。建立第三代智能搜索引擎需要一系列关键技术来支撑, 而已有的研究多是偏重于实现智能搜索引擎的“点”技术, 在这一背景下, 本文提出一种整合的、社会化的新一代智能搜索算法框架, 以期实现个性化智能搜索技术的创新, 满足广大用户的个性化信息检索需求。同时, 基于此创新算法框架, 进一步深入探讨构建基于意图的智能搜索算法。
3 基于意图的智能搜索框架
本文提出的基于意图的智能搜索算法通过使用机器学习、数据挖掘技术对用户数据信息(包括用户个性化数据、用户行为数据、用户查询数据等)以及网页数据进行统计建模, 并考虑当前的一些环境热点, 智能分析当前查询用户的真实意图, 提高搜索引擎返回结果的相关性和准确度, 实现个性化的基于用户意图的智能搜索。算法在内容存储、内容检索以及内容排名三个方面都有技术创新。
基于意图的智能搜索框架主要分为基础离线运算、过渡离线运算、在线初级运算及在线深度分析4个主要步骤, 该框架中的关键智能算法模块以及各个算法模块之间的联系如图1所示:
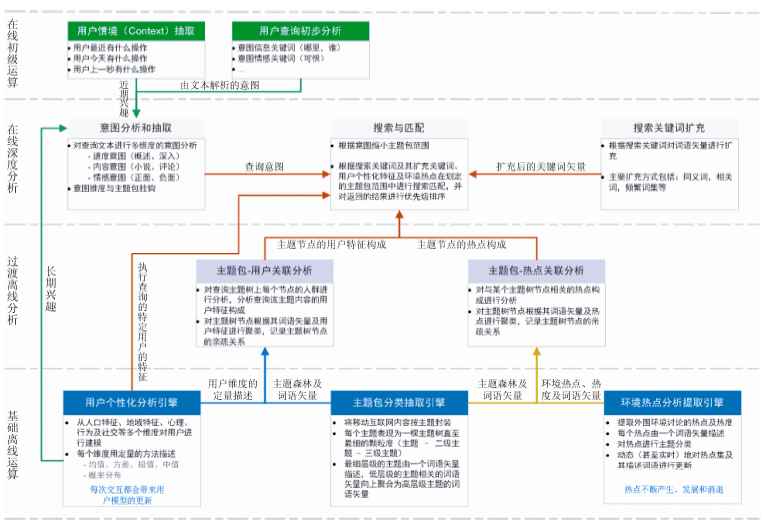 | 图1 基于意图的智能搜索框架 |
3.1 基础离线运算
离线运算意味着在没有接收任何用户请求的情况下, 系统会自动收集内容数据(包括网页、基于位置的服务信息、移动设备采集的信息)和用户信息, 智能地对这些数据进行分析, 探寻数据的分布状况和变化趋势, 构造统计模型。这些离线情况下构造的模型反映出数据的一定规律性, 为智能搜索提供了坚实的数据基础。离线运算主要包括用户个性分析引擎、主题包分类抽取引擎以及环境热点分析提取引擎这三个运算模块。
(1) 用户个性化分析引擎
将用户多维度的个性化特征(如人口特征、地域、心理、行为、社交和兴趣爱好等)进行抽取和统计, 然后使用并行核聚类算法(Parallel Clustering)[
利用贝叶斯逻辑回归模型(Bayesian Logistic Regression)[
(3) 环境热点分析提取引擎
利用能量模型、动态规划[
3.2 过渡离线运算
过渡离线运算是基础离线运算和在线深度分析的中间层, 起到了很好的过渡作用。由于基础离线运算中的用户个性分析引擎、主题包分类抽取引擎以及环境热点分析提取引擎模块获得的统计模型无法直接单独使用到在线深度分析中, 过渡离线运算层主要负责基础离线运算和在线深度分析的对接, 使用过渡离线运算中获得的离线统计模型重新构建出适合在线深度分析的新模型。过渡离线运算主要包括主题包-用户关联分析模块和主题包-热点关联分析模块。
(1) 主题包-用户关联分析
分析主题森林中每棵主题树节点的用户特征构成, 将主题森林所包含的主题信息与用户特征进行很好的关联, 从用户特征层面上为之后的基于用户意图的智能搜索做准备。主题包-用户关联分析可以看作是基于主题森林的用户个性化分析细化, 基于主题节点的用户特征聚类为根据用户特征进行互联网内容推荐奠定了坚实的基础。
(2) 主题包-热点关联分析
分析每个主题节点的热点构成, 将主题森林所包含的主题信息与环境热点进行很好的关联, 从环境热点层面上为之后的基于用户意图的智能搜索做准备, 这和主题包-用户关联分析方法相似。主题包-热点关联分析可以看作是基于主题森林的环境热点细化, 基于主题节点的热点特征聚类为相关热点内容(含背景内容)推荐提供统计模型。
3.3 在线初级运算
在线初级运算是系统在线对用户情境和查询语句进行初步分析, 从用户情境和用户查询语句中初步分析当前用户的查询意图, 从这两个层面为在线深度分析中的用户意图分析和抽取模块提供参照。在线初级运算主要包括用户情境抽取模块和用户查询初步分析模块。
(1) 用户情境抽取
收集用户历史浏览记录以及当前浏览记录组成用户的网络情境。由于用户的操作往往具有一定的持续性和连贯性, 通过网络情境分析用户的长期或短期关注点和兴趣所在对用户查询意图的分析和抽取具有关键的指导作用。搜索引擎可以返回更具针对性并且更加贴近用户当前兴趣的网页信息, 为基于意图的分析和抽取提供用户情境层面上的参照。
(2) 用户查询初步分析
通常情况下在用户的查询语句中显性或隐性包含部分用户的查询意图, 这些意图往往和某些关键词相关联。分析某些关键词所表达的潜在用户意图, 为基于意图的分析和抽取提供用户查询层面上的参照。
3.4 在线深度分析
在线深度分析是智能搜索框架最为核心的部分, 因为用户将直接获得在线深度分析所提供的搜索结果, 它的好坏直接影响到系统的整体性能。而基础离线运算、过渡离线运算、在线初级运算这三大部分为在线深度分析提供了基于用户意图搜索所必需的数据和统计模型, 是在线深度分析正常运行的基础。虽然对于用户而言这三大部分是虚拟的, 用户感觉不到这三部分的存在, 但它们却真正在为广大用户提供服务, 缺一不可。在线深度分析整合其他部分的成果, 为用户提供基于用户意图的个性化搜索。在线深度分析主要包括意图分析与抽取模块、搜索关键词扩充模块以及搜索与匹配模块。
(1) 意图分析与抽取
结合用户个性化分析、用户情境抽取以及用户查询初步分析这三个模块的分析结果, 使用加权模型推断出用户的真实意图。
(2) 搜索关键词扩充
用户输入的查询语句往往具有输入信息不全和二义性的情况存在, 这样会使得搜索引擎返回的相关结果较少, 准确度较低。通过关键词扩充是目前弥补用户输入信息不全和二义性情形的通用技术, 用于提高信息检索精度和召回率。
(3) 搜索与匹配
根据用户查询的关键字以及其意图返回内容。本文的方法并不遍历所有的主题包, 而是先缩小搜索范围, 再利用启发式算法找出相关内容, 最后考虑返回内容的可靠性、相关性、多样性和热度, 决定返回的内容及其优先级。
各个模块使用的主要算法和技术如表1所示:
| 表1 算法模块概要 |
4 基于用户意图、情境及偏好的搜索排序算法
在本文提出的基于意图的智能搜索框架中, 比较关键的技术是在用户发起搜索请求之后, 智能搜索算法如何综合离线和在线运算的结果, 考虑用户的意图、情境和偏好, 对海量的互联网上的内容进行搜索, 找到相关的内容, 并且根据内容的相关性、可靠性和多样性对其进行排序, 从而返回最符合用户需求的结果。
在最终根据用户的查询返回内容时, 可以分为三步: 根据扩充后的关键字缩小主题包范围; 根据关键字选定抽取内容; 从可靠性、相关性、多样性及热度等4个方面综合衡量对选定内容进行排序。下面是进行搜索排序的一些准则:
(1) 可靠性: 页面内容可靠的程度。主要通过指向该页面的其他页面的可靠度来评估。这也是谷歌搜索引擎所使用的排序方法[
(2) 相关性: 与用户意图的相关性。由于可靠性最高的页面未必是符合用户意图的页面, 因此需要对按可靠性决定优先级的方法进行调整。
(3) 多样性: 返回内容的多样性。在符合用途的情况下, 应尽量提供更多样化的内容, 而不是单一重复的内容。以用户查询“北京到上海的票”为例, 用户的意图是要从北京去上海, 但搜索引擎不能仅返回有关机票的信息, 而应返回航班、铁路、公路等多样化的信息供用户选择。
(4) 热度: 在考虑返回内容时, 会根据当前每个内容是否为热点信息、热度如何对返回的内容做一定程度的调整, 从而符合用户的短期兴趣, 是一种环境对个人发生影响的体现。
4.1 搜索排序算法
在技术上, 通过扩充后的用户查询关键词集合与各个主题节点对应关键词集合的相似性缩小待选主题包的范围。根据特征向量是连续或离散, 相似性的计算有多种方式, 如余弦相似性、欧几里得距离、Jaccard距离[
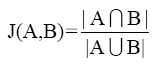 | (1) |
其中, 分子部分为向量A和向量B相同元素的数目, 分母部分为向量A和向量B所有元素的数目。当对应位置元素值相同(同为0或1)时, 记为1; 而当对应位置元素值不同时, 则记为2。将所有位置的值相加即获得分母。
在根据相似性缩小主题包范围后, 采用启发式算法对主题树的内容进行搜索, 而并非遍历所有的内容。这是由于本文的方法并不是简单的文字匹配, 而是有多次的相似性计算, 遍历会对搜索时间提出挑战。本文的启发式算法设计采用了分支定界与随机取样结合的思想。其中分支定界缩小了计算的时间, 而随机取样减轻了算法陷入局部最优的问题。算法的伪代码如下所示:① 遍历任一主题树的二级节点, 计算其与查询的相似性。
② while(未达到叶子节点)
{ 1) 剪枝 — 将相似性低于指定阈值的节点及子树从搜索中去除, 放到另一个集合。
2) 进入下一级节点, 并计算节点特征与查询的相似性。
}③ 返回叶子节点相似性高于指定阈值的内容。
④ 取出在第②步1)中被剪枝子树, 随机从子树中任意层级选定k个节点, 计算其与查询的相似性。
⑤ for(第④步中出现大于阈值的节点)
{ if (该节点为叶子节点) 遍历其兄弟节点, 并返回高于阈值的内容。
else 对该节点的子树执行第②步。
}
在获得将要返回的内容后, 将所有内容再度进行聚类, 并在每个类别内部对所有内容的可靠性、相关性和热度进行评估。
(1) 可靠性评估: 利用谷歌的PageRank方法[
(2) 相关性评估: 利用协同过滤方法[
(3) 热度评估: 从环境热点分析提取引擎中获得热度Hi。
通过加权或其他函数映射的方法, 可以获得对一个内容可靠性、相关性和热度的总评估分数Si。公式(2)给出一种最基本的加权映射方法:
| Si= wRRi+ wCCi+ wHHi | (2) |
在加权时需要对评估分数Ri、Ci和Hi进行归一化处理, 因此有wR+ wC+ wH =1。加权系数wR、wC和wH则可以根据主题动态选取或者进一步建立用户兴趣模型通过优化算法得出。
此外, 返回内容时将从每个类别中都选取部分内容, 从而保证内容返回的多样性。
4.2 算法性能分析
基于意图的智能搜索是当前互联网公司尚未采用的创新方法, 因此本文在已实现的原型系统上设计了10组不同的查询实验, 每组针对一特定主题选取100个不同的用户进行查询(如查询“北京 上海”、“生日礼物”、“北京 酒店”、“苹果 价格”等), 并分别由本文提出的基于意图的方法和目前第二代搜索引擎广泛使用的基于关键字的方法(以PageRank[
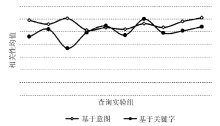
图2显示了在大部分情况下本文的方法返回结果的相关程度(均值)较关键字的方法高。而通过表2所示的方差可以看出基于意图的方法的高相关性表现出较高的稳定性, 并且处于对传统方法的支配地位。
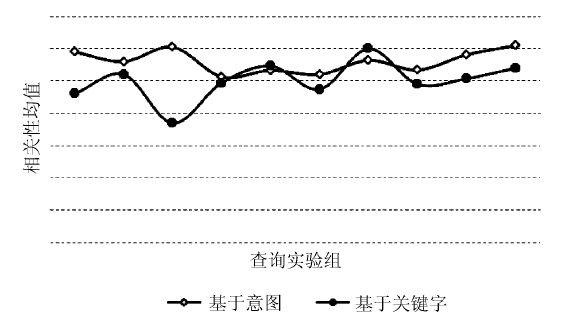 | 图2 查询结果相关性均值比较: 基于意图的方法 vs. 基于关键字的方法 |
| 表2 查询结果相关性均值及方差比较: 基于意图的方法 vs. 基于关键字的方法 |
5 结 语
本文针对互联网信息服务中日益增长的精确化和个性化需求, 提出了一套新的面向用户真实搜索意图的智能搜索引擎系统框架, 从识别用户搜索意图的全新角度, 在内容存储、内容检索以及内容排名三个方面对搜索引擎算法进行重新建模, 规划了基础离线运算、过渡离线运算、在线初级运算及在线深度分析4个主要步骤, 并对核心搜索排序算法进行了详细介绍和分析。基于该框架构建的智能搜索引擎具有搜索流程中间件化、搜索结果个性化、快速响应性、生态化等多个特性。本文提出的智能搜索引擎框架和技术已经在小范围的环境中进行了技术实现和验证, 并正在进行商业化探索。
构建智能搜索引擎是一个庞大的系统工程, 涉及到多方面的技术和工程问题。限于篇幅, 本文仅重点介绍了整个框架中的一个关键技术——搜索排序算法, 对于实现这一搜索引擎的其他技术以及工程问题并没有进行过多介绍。未来还需要对实现整个框架的诸多具体算法进行反复实验验证和改进。
基于意图的智能搜索一方面使得用户能够更加方便、准确地获取信息, 另一方面更有助于互联网应用及服务提供者为用户提供精准的个性化服务。新一代的智能搜索通过社会化大数据的分析与挖掘, 必将促进移动互联网时代应用以及服务的个性化和智能化, 并造就商业模式的创新。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|