
{kind=link}
{kind=link}
学术论文大纲中关键术语抽取方法研究
引用本文
何远标, 乐小虬, 张帆. 学术论文大纲中关键术语抽取方法研究. 现代图书情报技术, 2014, 30(3): 73-79
He Yuanbiao, Le Xiaoqiu, Zhang Fan. Research on Keyphrase Extraction from Scholarly Article Outline. New Technology of Library and Information Service, 2014, 30(3): 73-79
Permissions
He Yuanbiao, Le Xiaoqiu, Zhang Fan. Research on Keyphrase Extraction from Scholarly Article Outline. New Technology of Library and Information Service, 2014, 30(3): 73-79
Copyright©2014, The modern information technology editorial office
This article is the open access journal literature, in the following situations are free to use: academic research and academic exchanges, scientific research and teaching, etc., but don't allow for commercial purposes.
学术论文大纲中关键术语抽取方法研究
负责调研, 细化研究方向及技术方法路线, 设计实验方案; 负责实验, 包括数据采集、清洗与结构化,编程及实验结果分析; 论文撰写与最终版本修订;
乐小虬: 提出研究方向和论文选题方向, 就研究思路、实验方案及技术路线提供指导;
张帆: 数据标注, 部分编程及数据分析; 参与论文修改。
摘要
【目的】
针对学术论文大纲内容精炼、层次性的特点, 研究从中抽取重要且具有实质意义术语的方法。
【方法】结合语言学规则和术语词典从大纲各级标题中识别出候选术语集, 然后根据术语间的句法依存关系计算tf-idf, 并利用大纲结构量化术语层级特征, 最后结合tf-idf与层级特征对候选术语进行排名, 选择出关键术语。
【结果】实验证明, 该方法的候选术语识别F值达到89.57%, 术语选择F值达到36.89%。
【局限】采用的术语抽取规则不完备, 且tf-idf计算过程中的权值设置仅使用经验值, 导致未能达到最优效果。
【结论】该方法能有效抽取大纲中的关键术语, 适用于层级结构中的关键术语抽取。
关键词:
候选术语识别; 候选术语选择; 句法依存关系; 层级特征
Research on Keyphrase Extraction from Scholarly Article Outline
Abstract
[Objective]
According to the succinct and hierarchical character of scholarly article outlines, this paper concentrates on finding a method to extract important and meaningful phrases from the outlines.
[Methods]This paper first adopts a combined method of linguistic rules and terminology dictionaries to identify the candidate phrases. Then, it calculates tf-idf based on syntactic dependencies between phrases, and quantifies the hierarchical feature according to hierarchical structure of outline. At last, it combines the tf-idf and the hierarchical feature to rank candidate phrases, and selects the keyphrases.
[Results]Experiments show that the F-score of the candidate phrases identification reaches 89.57%, and the F-score of candidate phrases selection reaches 36.89%.
[Limitations]In this method, the inadequate phrase extraction rules and the empirical values involved in weight setting during tf-idf calculation lead to non-optimal effect.
[Conclusions]This method can effectively extract the keyphrase from outlines, and is suitable for keyphrase extraction from hierarchical structure.
Keyword:
Candidate phrases identification; Candidate phrases selection; Syntactic dependencies; Hierarchical feature
1 引 言
关键术语(Keyphrase)是指反映文章主旨的词或短语, 常在自动文摘、信息检索、文档聚类和自动问答等自然语言处理系统中表示文档[
学术论文大纲是由各级标题组成的一个层级结构, 用于展示各个要点或子主题[
本文在分析对比已有关键术语抽取方法的基础上, 针对学术论文大纲的特点, 利用标题间的层次关系, 结合语言学规则与统计分析方法进行关键术语抽取。
2 关键术语抽取研究现状
关键术语抽取需要根据相关特征进行判定, 具体过程分为两个步骤[
(1) 候选术语识别, 利用统计学方法、语言学规则等方法初步将符合部分特征的词或词组抽取出来;
(2) 候选术语选择, 利用分类、排名等方法计算特征项, 筛选出最有代表性的术语作为关键术语。
2.1 术语特征
特征是指作为标志的显著特点[
| 表1 术语特征分类 |
这5类特征的测度范围依次扩大, 从不同的视角考量术语的专指性和概括性。实际应用中, 应针对文档集的特点及抽取方法的特性, 组合多个不同类别的特征对术语进行全面评估。
2.2 候选术语识别
候选术语识别是根据词或词组的外在形式判定, 获得初步术语集的过程。传统的候选术语识别方法可以归纳为利用语言学规则、基于术语词典和统计分析三种[
(1) 利用语言学规则。其核心是针对特定的语料环境, 通过分析术语构成的特征, 制定一系列共性规则及个性化规则来自动提取术语[
(2) 基于术语词典。该方法利用领域专业术语词典查找文本中的术语, 词典一般由领域专家编撰, 具有权威性。然而, 词典的更新速度慢, 不能识别学术论文中的衍生术语和新术语。
(3) 统计分析方法。核心思想是通过构建统计模型, 综合计算词频、互信息、信息熵等特征值, 抽取超过阈值的词串作为候选术语集。这种方法偏向于选择高频术语, 容易忽略低频术语。
实际应用中, 上述三种方法通常混合使用, 互补优缺, 改善识别效果, 如语言学规则与词典结合, 术语词典与统计分析结合。
2.3 候选术语选择
候选术语选择是根据术语的内在含义从候选集中筛选出最能代表文档主旨的术语的过程, 选择方法分为监督和无监督两种[
(1) 监督方法是将关键术语抽取看作分类问题[
(2) 无监督方法则将关键术语抽取看作术语排名问题[
2.4 小 结
关键术语抽取包括术语特征选取、候选术语识别和候选术语选择三个子问题。在目前已有的术语特征项(见表1)中, 除了短语级特征之外, 大多数针对长文本, 且没有考虑到同一句子中不同成分术语的重要度, 也没有考虑大纲层级给术语带来的影响。对于候选术语识别, 目前的研究大多将多种方法混合使用以达到更好的识别效果; 同时, 大纲中的标题简短, 语言学规则与词典结合的方法更适合。对于候选术语选择, 由于学术论文具有明显的领域特征, 使用监督方法需对各领域训练不同的分类器, 灵活性低, 语料标注难度大; 而无监督方法主要依赖于特征项的选取。本文利用改进的tf-idf和层级特征项进行无监督术语选择。
3 学术论文大纲中关键术语抽取方法
3.1 方法思路
本文抽取关键术语的基本思路是: 首先, 针对术语的词性特征、关键词特征和缩写词特征, 使用语言学规则和术语词典结合的方法对大纲各级标题进行候选术语抽取, 得到多个候选术语集。各术语集之间保留原大纲中的层级关系, 本文称之为层级术语集。然后, 利用句法依存关系计算各候选术语的tf-idf (Term Frequency-Inverse Document Frequency), 并根据层级关系计算层级特征。最后, 结合tf-idf和层级特征对候选术语进行排名, 选择关键术语。
(1) 候选术语识别。术语基本上都是名词或名词性短语[
(2) 候选术语选择。论文大纲的内容简短, 传统特征如tf-idf、出现位置、PMI等表现不显著, 本文使用基于句法依存关系的tf-idf和层级特征作为关键术语的主要考量特征。基于句法依存关系的tf-idf是结合句法特征及基于图排名算法来量化标题中的术语重要度。术语的支配或受支配关系越多, 重要度越高。层级特征则用于量化不同大纲层级术语的主旨覆盖能力, 层级越深, 能力越弱。本文采用无监督方法进行候选术语选择, 通过组合基于句法依存关系的tf-idf和层级特征对大纲所有的候选术语进行排名, 选取TopN个作为关键术语。
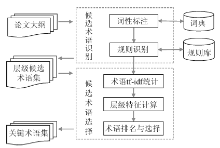
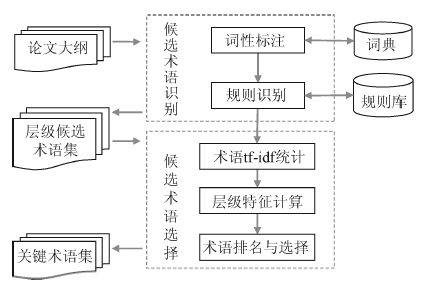
3.2 基本流程
处理流程分两部分: 候选术语识别, 通过对论文大纲标题进行词性标注, 并利用指定的词性规则识别出各标题中的候选术语, 按大纲的层级关系组织起来得到层级候选术语集; 候选术语选择, 利用句法依存关系计算术语tf-idf, 并根据层级关系计算层级特征, 最后结合tf-idf与层级特征进行术语排名, 从层级候选术语集中筛选出关键术语。整体处理流程如图1所示:
以下将对候选术语识别和候选术语选择两个步骤进行介绍。
3.3 候选术语识别
使用语言学规则和术语词典结合的方法进行候选术语识别: 首先将出现在词典中的词串标注为名词(NN), 在此基础上对其他部分进行词性标注, 然后利用规则抽取符合指定词性特征的词串。在该过程中, 术语词典与词性识别规则是决定抽取效果的核心要素。
(1) 术语词典
本文采用的词典数据来源于两方面: 领域内论文的关键词, 相对于外部知识库, 关键词具有更新速度快、主题覆盖能力强等特点; 论文大纲中的术语缩写及其原型, 通过对大纲进行缩写检测得到, 其内部结合紧密。
(2) 词性识别规则
名词性术语的词性组合主要有“JJ NN”、“NN”、“NN NN”、“VBN NN”几种[
(JJ(\\w){0,1})*(NN(\\w){0,2})*NN(\\w)*(1)
3.4 候选术语选择
对大纲进行候选术语抽取后得到的层级术语集既有术语内容, 又有层次关系信息, 这两方面的特征决定术语的重要度, 依此选择关键术语。
(1) 基于句法依存关系的tf-idf统计
在识别出候选术语的基础上, 对大纲各级标题进行句法关系分析, 将得到依存关系图。以文献[23]的标题“A Concept and Implementation of Higher-level XML Transformation Languages”为例, 如图2所示, 其中, 有向弧的起始端表示支配者, 箭头端表示从属者。
 | 图2 句法依存关系 |
根据句法依存关系, 抽取形如
S : concept ; P : and ; O : implementation;factor=1
S : concept ; P : of ; O : higher-level XML transformation
languages;factor=1.25
S:implementation ; P : of ; O : higher-level XML transformation languages;factor=1.25
在三元组中, S的词频默认为1, O的词频为1×factor(factor为权重因子)。术语w的词频是通过对
(2)
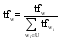 | (3) |
公式(3)中, U为候选术语集。利用公式(2)和公式(3)对上述关系集进行词频统计的结果为:
tf(concept)=0.208
tf(Implementation)=0.208
tf(higher-level XML transformation languages)=0.385
在idf计算过程中, 将标题看作一个文档, 为防止低频新术语导致idf过高, 本文通过引入平滑因子来改善idf计算, 如公式(4)所示:
 | (4) |
(2) 层级特征计算
层级特征是反映主题覆盖能力的测度指标。大纲描述的内容逐层深入和细化, 下级标题往往是上级标题的分面具体化描述或其子主题, 因此, 出现位于不同大纲级别的术语具有不同的主旨覆盖能力。一般来说, 层次越深其主题描述能力越弱, 重要度越低。本文提出公式(5)计算层级特征:
 | (5) |
其中, h是节点的层次深度, Count(i)是兄弟节点数量, e为平滑因子。
(3) 候选术语排名与选择
结合基于句法依存关系的tf-idf与层级特征计算候选术语的综合特征得分排名, 选择得分TopN个术语作为关键术语。本文提出公式(6)计算综合得分:
 | (6) |
4 关键术语抽取实验
为验证上述文章大纲中关键术语抽取方法的有效性, 本文对候选术语识别和关键术语选择两个环节分别进行实验。实验数据是从Elsevier上以“Concept Hierarchy”为关键字, 时间为2004到2013年, 检索得到前50篇学术论文的大纲。通过人工标注, 得到大纲标题443条, 候选术语921个及大纲关键术语150个。另外, 抽取检索结果中的前1 000篇文章的大纲及关键词, 用于构建词典。
4.1 候选术语识别
采用StanfordNLP工具[
| 表2 术语特征分类 |
实验结果显示, 单独使用一种词典时, 缩写词词典的准确率最高; 而关键词词典因词数量较多, 召回率高于缩写词词典。综合使用两个词典可以提高对术语的识别率。另外, 使用规则识别的F值比使用词典的F值有较大提升, 说明名词规则能够覆盖大纲中大部分术语。综合两个词典和规则识别的方法获得最佳识别效果, F值接近90%。实验存在的不足有:
(1) 术语匹配规则不足以覆盖所有的术语构成特征, 如“shoulder and neck pain”词性为“NN CC NN NN”, 并不符合3.3节所述的名词规则;
(2) 部分关键术语本身存在多种切分, 如“restricted Coulomb energy (RCE) neural network”可切分为{“restricted Coulomb energy”, “RCE”, “neural network”}或{“restricted Coulomb energy (RCE) neural network”}, 本实验没有考虑不同切分之间的兼容处理。
4.2 候选术语选择
在识别关键术语的基础上, 使用StanfordNLP工具[
| 表3关键术语选择评测结果 |
传统关键术语抽取方法取得的F值为30%左右(如Berend等[
(1) 实验中
(2) 未考虑论文大纲中各个层级自身的特殊性(如根节点和叶节点往往包含重要信息较多), 需进一步深入研究。
4.3 小 结
本实验使用语言学规则和术语词典结合的候选术语识别方法、基于句法依存关系的tf-idf和层级特征结合的关键术语选择方法从学术论文大纲中抽取关键术语, 并取得良好效果。对于候选术语识别, 使用词性特征和关键词、缩写词词典即可覆盖近90%的术语, 进一步改善可通过优化抽取规则以及扩大术语词典的方法来实现。对于候选术语选择, 基于句法依存关系的tf-idf能有效地从短文档中筛选关键术语, 结合论文大纲的层次结构特征的术语抽取结果的Top1 F值达36.89%(Top3 为48.68%)。优化三元关系权重因子以及层级特征计算方法均可提高关键术语选择的准确率。
5 结 语
学术论文大纲是内容的框架, 包含论文的主要信息以及不同子主题之间的关系, 充分利用这种关系能提高关键术语的抽取质量。本文分析了目前主流的关键术语抽取方法, 针对学术论文大纲的特点, 利用语言学规则和术语词典结合的候选术语识别方法, 以及基于句法依存关系的tf-idf和层级特征结合的候选术语选择方法进行关键术语抽取。实验表明, 这种方法取得了良好的抽取效果, 适用于大纲或类似大纲的层级结构中的关键术语抽取。下一步工作将针对识别规则、词典及三元关系的权重等方面的不足进行改进, 并深入研究论文大纲的层级特点, 挖掘术语间的语义关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|