





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
机器学习在中文期刊论文自动分类研究中的应用
[王昊 , 叶鹏, 邓三鸿]
, 叶鹏, 邓三鸿]
, 叶鹏, 邓三鸿]
|
|


提出研究方法和基本思路, 进行实验结果的分析和论证, 负责论文撰写;
叶鹏: 进行实验, 包括数据采集、清洗和计算;
邓三鸿: 对论文进行最后审阅并提出修改意见。
在机器学习的计算模式下, 利用特征加权和浅层次分类方法可以有效实现期刊论文的中图法分类。
【应用背景】传统的人工分类方式在大数据环境下显得力不从心, 而期刊电子化趋势使得自动分类技术能够有效缓解人工分类的压力。
【方法】将机器学习的思想运用到期刊论文的自动分类领域, 分析比较支持向量机和BP神经网络算法在期刊论文自动分类中的效果, 利用层次分类理念将中图法转化为三层分类体系, 将类目号的获取简化为三层分类的实现, 基于特征的来源设置特征值的权重。
【结果】分类实验表明, 支持向量机算法在大规模稀疏数据环境中较BP神经网络算法更合理, 三层体系的分类正确率自顶向下分别达到95.05%、92.89%和89.02%, 综合正确率接近80%, 多来源的特征权重在论文自动分类中较单一权重具有更好的分类效果。
【结论】研究表明机器学习方法在期刊论文的自动分类方面具有较高的可行性、合理性和有效性, 为期刊论文自动分类的实现提出新的思路。
Under the computing mode of machine learning, using the methods of feature weighting and shallow-hierarchical classification can effectively achieve Chinese Library Classification (CLC) classification for periodical articles.
[Context]The traditional way of artificial classification shows its own limits in the background of “Big Data”, and the trend of periodicals electronic makes that automatic classification techniques can effectively relief the pressure of artificial classification jobs.
[Methods]This paper introduces the thinking of machine-learning into the field of automatic classification of periodical articles. It analyzes and compares the effects of Support Vector Machine(SVM) and BP Neural Networks Algorithm(BPNN) in the procedure of automatic classification, transforms CLC into another classification system with three levels in the thoughts of hierarchical classification, and sets the weights based the sources of classification features.
[Results]The experiments of classification tests show that SVM is more reasonable than BPNN under the condition of large-scale sparse data, the accuracy rates of these three levels reach 95.05%, 92.89% and 89.02%, and the integrated accuracy rate is close to 80%, and the feature weights from mulit-sources can lead to better classification results than single-source.
[Conclusions]The study proves that the model of machine-learning with feature weighting and shallow-hierarchical classification in automatic classification of periodical articles has higher feasibility, rationality and effectiveness, and a new idea on automatic classification of periodical articles has been presented.
随着信息技术的发展, 人们对图书馆信息服务数字化的要求也越来越强烈, 数字图书馆建设已经成为图书馆事业发展的重要课题。期刊数字图书馆就是将期刊论文电子化, 主要面临两个工作: 期刊论文的格式必须有统一标准、期刊论文的分类管理[ 1]。经过多年的努力, 期刊论文现在已经形成了一套统一的著录标准(元数据), 然而期刊论文的分类管理基本还是以人工分类为主。人工分类目前面临的问题是: 随着期刊论文数量的快速增长, 人工分类显得心有余而力不足, 人工每天能分类的数量是固定的, 即使增加人力成本, 想要赶上期刊论文增长的速度还是很困难, 这无疑给分类工作增加了很大的压力。而期刊论文的机器自动分类能够有效缓解人工分类的压力。
目前国内外关于期刊论文的自动分类研究较少, 其思路大致可以分为两类:
(1) 借鉴传统的图书自动分类思想, 即通过人工标引和统计学方法构建分类库, 把每个类别都用一个特征词向量进行表示, 然后利用向量相似度模型计算样本和各类别特征向量的相似度, 值最高的类别就是该样本的所属类目[ 2, 3, 4, 5, 6, 7]。该方法中用于描述期刊的特征主要来自人工标引的关键词, 特征来源单一, 同时需要预先构建各类别的特征向量并不断补充和修正;
(2) 借鉴目前常用的文本自动分类方法, 将期刊书名作为文本, 首先对文本进行预分词处理, 将分词结果作为文本的特征描述, 构建文本-特征词矩阵, 然后对已分类文本(即带有分类标记的文本-特征词矩阵)进行机器学习或者分类, 最后将分类器用于未分类文本(没有分类标记的文本-特征词矩阵)以获得分类标记[ 8, 9, 10, 11, 12]。整个学习和分类过程几乎不需要人工干涉, 而且分类效果较好。但是期刊与文本毕竟存在差异, 期刊名在表示文献内容方面存在一定的局限性, 而且期刊分类号纷繁复杂, 采用单层次分类方法效果不佳。
因此, 本文在引入机器学习以构建分类器的基础上, 提出了多层次分类和基于特征加权的期刊描述矩阵构建等解决方案, 结果表明能够有效提高期刊分类效果。
本文主要研究中文期刊论文自动分类, 样本数据是文本, 属于线性不可分的样本, 故选择构造型策略[ 4], 将线性不可分样本映射为线性可分的形式来处理, 机器学习的学习形式选择监督学习[ 13], 即通过对已知类别的样本数据进行训练, 寻找类别与内容之间潜在关系, 最后得到分类模型, 然后将测试数据应用到分类模型中, 获得分类模型给出的类别集合, 与真实类别集合进行比较, 以检验分类模型的分类效果, 具体过程如图1所示。其中训练数据集包括特征矩阵和类别矩阵, 而测试数据集只包括特征矩阵, 测试数据集的类别矩阵最后用来对比分析分类模型的分类效果。
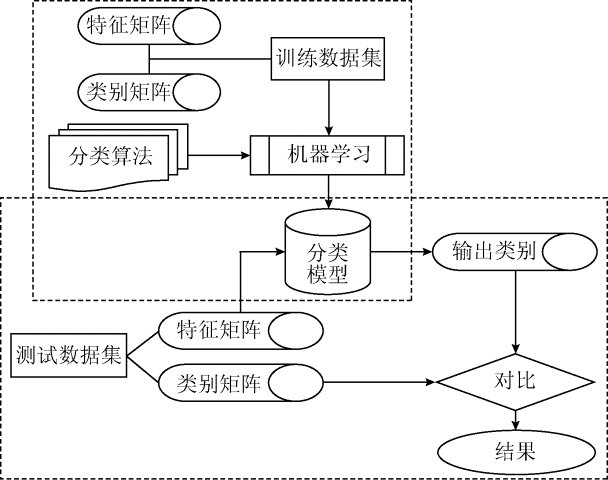 | 图1 基于机器学习的期刊论文自动分类模型 |
中国知网(CNKI)电子期刊论文元数据包括题名、作者、机构、摘要、关键词、分类号、下载频次和被引频次等信息。本文抓取了若干期刊论文的相关信息作为实验样本, 赋予编号, 将其导入数据库, 形成结构化数据, 抽取的信息主要包括编号、题名、摘要、关键词和类别5个字段。实验之前需要对数据进行预处理, 过程如图2所示:
 | 图2 数据清洗过程 |
在数据清洗之后, 期刊论文样本可用特征向量的形式表示, 如图3所示, 该向量表示期刊论文在特征T1到Tn上的表现程度, 其中X值越大, 说明该期刊论文与这个特征的关系越密切, 否则越不相关。
 | 图3 单样本的特征向量表示 |
在实际训练时, 训练数据为大量期刊论文, 将其纵向排列可构成向量组, 即矩阵形式表现, 如图4所示, Xji表示期刊论文j在特征词Ti上的权值。
 | 图4 论文×特征词矩阵示例 |
在模型中, 准备工作包括配置机器学习环境和准备实验样本, 前者包括计算机软件和分类算法的选择, 后者则是指特征矩阵的构建。机器学习环境配置是机器学习的基础, 本文选择Matlab作为机器学习软件, 在此基础上选定相对合适的分类算法; 实验样本的准备过程中所需解决的问题是特征的选取标准。
目前成熟的分类算法主要有神经网络(Nerve Net, NN)算法、决策树(Decision Tree)算法、K邻近(K-Nearest Neighbor, KNN)算法、支持向量机(Support Vector Machine, SVM)算法、朴素贝叶斯(Naive Bayes)算法[ 8]等。本文的样本是大量的中文期刊论文著录项, 包括题名、关键词、摘要等基本文本信息, 每个样本的文本表示具有很强的高维度、非线性、数据稀疏等属性特征, 要对这样大规模文本信息进行自动分类, 从分类效果和效率考虑, 本文拟选择大型分类模型BP人工神经网络算法[ 14, 15]和SVM算法。
考察算法的性能主要从算法的准确率和效率判断。在准确率方面, 本文采取固定实验样本, 分别运用两种算法进行实验, 最后获取准确率进行分析。为了客观地验证实验效果, 笔者引入十倍交叉验证的方法来进行实验。在效率方面, 主要是考察算法在数据量和运行时间方面的性能, 选择5个不同数量级别的样本进行实验, 以关键词作为特征来源, 分别获得两个算法在不同数据量下的准确率和实验时间, 并分析实验结果。最后综合以上两个方面的结果进行算法的分析。
准确性检测实验选择的样本是中图法中C、D、F、G、I、K、R、T 这8个大类的数据, 每个大类选取4 000条数据作为样本, 共计32 000篇论文, 其中28 800条作为训练样本, 剩余的3 200条为测试样本, 实验的最终结果如表1所示。
(1) 在同样本条件下, SVM算法的平均准确率到达89.42%, BP神经网络算法的平均准确率达到82.94%, 而且每次实验中SVM算法的准确率都高于BP神经网络算法, 结论是SVM算法在实验中的表现优于BP神经网络算法。
(2) 在十倍交叉验证实验中, SVM算法和BP神经网络算法的10次实验结果都在平均值的上下2%的区间波动, 结果相对比较稳定, 说明这两个算法在分类领域都是适用的, 没有明显缺陷, 只不过SVM算法由于其理论基础的优越性, 在分类性能上也占有一定的优势。
| 表1 十倍交叉验证结果 |
在上述实验的基础上, 本文检测了不同数据量下的实验耗时。实验的样本依旧是C、D、F、G、I、K、R、T这8个大类, 每个大类分别取5 000、4 000、3 000、2 000、1 000条数据进行5次实验, 每次实验取样本的前90%数据作为训练样本, 剩余10%样本作为测试样本, 分别使用SVM算法和BP神经网络算法, 对比实验准确率和运行时间, 以测试算法的质量, 实验的结果统计如表2所示:
| 表2 不同数据量下算法的性能表现 |
(1) 随着数据量的逐渐下降, SVM算法和BP神经网络算法的准确率都存在下降的趋势, 这说明了样本量的大小确实对机器学习的训练效果有一定的影响。
(2) 在不同的数据量下, SVM算法的实验准确率均高于BP神经网络算法, 前一个实验证明了在相同样本量条件下, SVM算法的效果明显优于BP神经网络算法。本实验中, 随着样本量的逐渐减少, SVM算法的准确率下降的速度很明显慢于BP神经网络算法, 在8 000级别的样本量上, BP神经网络算法的实验准确率已经下降到54.84%, 这再次证明了结构风险最小化理论的优越性, 随着样本量的减少, 样本的VC维必然会减少, 经验风险就会增大, 实验的准确率自然就会降低, 而结构化风险利用置信风险平衡了这一点, 优化了实验的风险。
(3) 从训练所需的时间看, SVM算法的时间都在6分钟以内, BP神经网络算法在第一次实验中出现报错, 系统提示“内存不足”, 在其他几次实验中机器学习的时间也都是大于等于6分钟, 从时间上来看, SVM算法相对来说还是优于BP神经网络算法的, BP神经网络算法报错的那一次实验说明它的算法复杂度较高, 对硬件的要求高于SVM算法, 但是随着数据量的下降, 两者使用时间的差距在不断缩小, 说明BP神经网络算法更适用于中小规模的文本分类任务。
综上所述, 无论是机器学习的准确率还是样本数量的影响和训练时间, SVM算法都相对优于BP神经网络算法, 故本文选择SVM算法作为研究中文期刊论文自动分类的算法, 并配置了算法核函数和相关参数[ 16, 17]。
本文以期刊论文作为样本, 包括题名、关键词和摘要等信息, 这些信息都可反映期刊论文类别主题, 故均可作为特征来源, 但它们对期刊论文类别反映的程度又各不相同。通常情况下, 关键词是作者为期刊论文精心挑选的能概括期刊论文最主要内容的词汇, 应该是最能够反映期刊论文类别的特征来源; 而题名是期刊论文内容最直接的体现, 能够给人对论文内容的第一印象, 故也是能够反映期刊论文类别的特征来源, 但由于其中包含了一些不相关的词汇, 加之有些文学性期刊论文的标题运用了一些文学手法间接表达期刊论文内容, 这就整体减弱了题名的表现能力; 摘要是期刊论文的压缩精简版, 但包含了一些介绍性的语句, 这些语句也降低了摘要对期刊论文类别的表现程度。这些是理论上这三种特征来源对内容的表现程度, 为了验证上述理论, 分别对这三种特征来源进行实验分析, 从实践角度来验证它们对期刊论文内容和类别的反映程度。
本实验选择上述8个大类32 000条样本数据, 分别选择题名、关键词和摘要作为特征来源, 进行两组实验: 一组考虑特征词在该特征来源中的词频, 将词频数作为该特征词的特征值; 另一组不考虑词频, 用布尔值作为该特征词的特征值。例如“数字化图书馆的图书馆”中“图书馆”出现两次, 考虑词频的实验会将它的特征值标为2, 不考虑词频的实验会标为1, 以28 800条期刊数据作为训练样本, 另外3 200条作为测试样本, 实验结果统计如表3所示:
| 表3 不同特征来源和词频下实验结果统计 |
 | 图5 词频对题名、关键词和摘要的分类效果影响 |
(1) 效果最突出的是以关键词作为特征来源, 最差的则是以摘要作为特征来源, 实验的结果验证了上文的理论分析。
(2) 在考虑特征词词频的情况下, 实验的准确率都有所提高, 特别是以题名和摘要作为特征来源的实验, 原因应该是这两种特征来源中都包含较多的重复词汇, 计算重复的次数会强化机器对这些词汇的学习效率, 从而提升了分类效果。
(3) 题名、关键词和摘要在类目区分能力上的不同表现, 为特征加权方法的权值分配提供了事实基础。
单以关键词作为特征来源可达到93%的准确率, 如果将几个特征来源加以综合, 实验的效果是否会更好?为此, 分别以“题名+关键词”、“关键词+摘要”、“题名+摘要”、“题名+关键词+摘要”进行分类实验, 探讨不同特征来源组合对结果的影响, 实验样本相同, 测试结果如表4所示:
| 表4 基于组合特征的实验结果统计 |
(1) 对特征来源进行组合后, 准确率均略有提升, 特别是综合三种来源的实验效果提升明显。
(2) 对比实验1和实验2说明题名和摘要的加入并没有产生拉低准确率的现象, 反而起到了提升分类准确率的作用, 从提升的程度来看, 题名和摘要基本处于同一水平, 题名略高于摘要; 对比实验1和实验3可以发现关键词对期刊论文类别的反映能力高于摘要; 对比实验2和实验3可以发现题名对期刊论文类别的反映能力低于关键词。可以得出以下结论: 在两个特征来源的实验中, 一般特征来源中包含关键词的实验, 效果都优于不包含关键词的实验, 这再次证明了关键词对期刊论文类别有较强的表现能力。
(3) 综合三种特征来源的实验4中, 机器学习的分类效果达到最优, 这表明随着特征来源的增多, 机器对期刊论文类别的识别能力增强, 分类效果相对提升。
综上可知, 三种特征的组合能够有效提高机器学习的效果, 本文将以“题名+关键词+摘要”的组合进行一定的加权来完成后续的实验分析, 并将特征权重比例设定为3:5:2。
CNKI中期刊论文的类目依据中国图书馆分类法(简称“中图法”), 如图6所示。中图法采用树形结构, 具有一定的深度和广度。目前文本分类一般都采用单层次分类法, 即把所有的类目都放到一个层面上, 不考虑类目之间的相互关系, 这种分类法比较适合类目层次较少、类目间关系不密切的分类情况。本文探讨的期刊论文类别位于中图法层次结构中的叶节点, 由于叶节点种类繁多, 关系密切, 至少有上百种, 而且不同的叶节点所处的深度也不一样, 直接将叶节点作为分类依据不合理, 原因是: 繁杂的类目会增加分类计算的复杂度; 叶节点的类目相互之间的区分度不好; 不同深度的类目不应该放在同一层次进行比较。这些因素都会影响分类的准确性和效率, 即单层次分类模型并不适合中图法这种具有复杂类目和不均匀深度的类目体系。
 | 图6 中图法分类体系结构 |
为此, 本文引入层次分类法, 即按照系统原有的结构, 从不同层次对期刊论文进行分类。具体描述如下: 从根节点出发, 中图法可分为A-Z 22个大类, 作为第一个层次; 再从这些大类出发, 每个大类又可以分为若干小类, 如A1、A2、A3等类别, 这是第二个层次; 再从其中一个出发, 以A2为例, 又有A21、A22等类别, 这是第三个层次。以此类推, 可以将中图法分为若干个层次。笔者可以从各个层次进行分类实验, 最后获取综合效果。
选取C、D、F、G、I、K、R、T这8类33 292数据, 对其进行特征的筛选, 其中30 000条数据作为训练样本, 3 292条数据作为测试样本, 训练样本和测试样本比例接近9:1; 二层实验选取G大类17 229条数据作为样本, 分别以G0、G1、G2、G3、G4、G8为第二层的类别, 选取15 500条数据作为训练样本, 1 729条数据为测试样本; 第三层实验选取G1类别的9 256条数据作为样本, 将G1类目下的所有类别都单独作为一个类, 例如像“G112”、“G113”、“G121”等类别都分别作为G1类下的一个单独的类别, 共计三类(12、13和22), 并不是把“G112”和“G113”归为一类“G11”, 以其中的8 500条数据作为训练样本, 756条数据作为测试样本。实验结果如表5所示:
| 表5 多层次中文期刊论文自动分类结果 |
第一层的分类实验达到了95.05%, 第二层也有92.89%的实验准确率, 到了第三层实验, 分类结果的准确率下降到89.02%。不难发现, 随着层次的加深, 能够使用的样本量也在逐渐减少, 分类实验的准确率也随之下降, 分类实验的准确率下降固然与训练样本的减少有一定关系, 但主要原因还是随着层次的加深, 类与类之间的区分度相对不够明显, 例如在第一层中, D类是“政治法律”, F类是“经济”, G类是“文化、科学、教育、体育”, 这些大类别之间区分非常明显; 到了第二层, 以G类为例, G0表示“文化理论”, G1表示“世界各国文化和文化事业”, 前者是文化领域的理论, 后者是各国具体的文化事业, 显然都是文化领域的知识, 从这个角度看, 它们之间的区分度就比较弱; 到了第三层, 以G0为例, G02表示“文化哲学”, G03表示“文化民族性”, 它们之间的距离更近了。这也是随着层次的加深, 分类准确率快速下降的主要原因。
在第一层和第二层的实验中, 分类的准确率都达到92%以上, 即使到了第三层, 虽然类别间的区分度降低了, 但是分类准确率依然接近90%, 保持在一个相当可观的水平, 可见随着层次的加深, 实验的准确率下降并不明显, 说明自动分类在中文期刊论文领域是可行的。第一层综合准确率就是第一次的准确率, 第二层综合准确率下降到95.05%×92.89%= 88.29%, 到了第三层, 综合准确率下降到88.29%× 89.02%=78.60%, 可以推测第4层实验的结果也能达到80%以上的水平, 但是综合准确率将会下降到60%左右的水平, 这个分类效果是难以接受的, 说明超过三层的分类体系结构在自动分类实验中不能达到一个较好的水平。
因此随着分类层次的加深, 分类的精度固然会上升, 但是分类的准确率会下降, 如何把握好这两者之间的关系是影响期刊论文自动分类效果的关键。分类的类别精确度随着层次的加深而提高, 故在条件允许的情况下尽量提高实验的层次深度, 实验证明在到达第三层的时候, 无论是单层准确率还是综合准确率, 都能达到一个较好的水平, 因此本文认为, 三层分类结构比较适合于中图法体系下的中文期刊论文分类。以此为基础, 可以对三层及以下的所有类目进行单层分类。
当前, 中文期刊论文主要采用中图法进行组织和描述, 论文的类目号一般由作者自行设置。由于期刊标注的规范, 使得大量期刊论文没有类目号, CNKI等期刊论文的收录平台往往需要大量的人力和物力来弥补这个数据缺失; 再由于缺乏分类专业性, 作者给出的类目号存在不准确性和主观性。随着期刊论文数量的逐渐增多及其电子化趋势, 借助已有的论文分类知识来实现新论文的自动分类对作者论文撰写以及论文的标注工作等具有重要意义。
为此, 本文引入机器学习方法, 使用计算机对已有的中文期刊论文分类知识进行学习, 构造分类器, 再将其应用于未分类期刊论文的自动分类工作中。本文的研究主要在于:
(1) 提出了基于机器学习的期刊自动分类方法, 并验证了SVM在高维、非线性、稀疏数据环境下文本分类中的巨大优势, 而神经网络(BPNN)算法在大数据环境下存在一定局限性。关于期刊论文中图法类目号的生成, 目前国内外研究甚少, 基本都上停留在单层次文本分类的水平上(参见3.1节), 而且测试规模较小[ 18]。
(2) 验证了不同著录项对论文内容的揭示度, 针对期刊论文的特点提出了对不同著录项进行加权以构造论文特征向量的合理思路, 从而对基于SVM的中文期刊论文自动分类模型进行了构建和优化。结果表明, 特征加权思想能够有效提高期刊分类的准确性, 这为中文文本自动分类研究的进一步深化提供了可参考的思路。
(3) 针对中图法的特点和分类系统的实用性, 笔者提出了期刊论文的三层分类体系, 即构建层次分类器, 逐层分步给出期刊论文的类目号, 其综合准确率可达到78.60%, 基本上达到了实际应用的水平, 期刊论文类目号的自动生成能够对论文作者以及期刊收录平台提供有效服务。然而, 不足之处在于并没有构造出针对中图法的完整分类器体系, 使得本研究仅停留在实验阶段, 没有付诸实际应用, 这将是笔者今后进一步实现和完善的方向。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|