引用本文
俞仙子, 高英莲, 马春霞, 刘金星. 提取核心特征词的惩罚性矩阵分解方法—— 以共词分析为例.现代图书情报技术, 2014, 30(3):88-95
Yu Xianzi, Gao Yinglian, Ma Chunxia, Liu Jinxing.The Penalized Matrix Decomposition Method of Extracting Core Characteristic Words ——Taking Co-word Analysis as an Example. New Technology of Library and Information Service, 2014, 30(3):88-95
Yu Xianzi, Gao Yinglian, Ma Chunxia, Liu Jinxing.The Penalized Matrix Decomposition Method of Extracting Core Characteristic Words ——Taking Co-word Analysis as an Example. New Technology of Library and Information Service, 2014, 30(3):88-95
Copyright©2014, The modern information technology editorial office
This article is the open access journal literature, in the following situations are free to use: academic research and academic exchanges, scientific research and teaching, etc., but don't allow for commercial purposes.
提取核心特征词的惩罚性矩阵分解方法—— 以共词分析为例.现代图书情报技术
俞仙子: 采集、清洗、分析数据和论文起草;
高英莲: 数据的分析与论文修订;
马春霞: 实验调试;
刘金星: 提出研究思路, 设计研究方案和论文修订。
摘要
【目的】
在共词分析时对高维共词矩阵进行稀疏降维, 直观快速地凸显出高维矩阵中的核心特征词。
【方法】提出基于惩罚性矩阵分解(PMD)的文本核心特征词提取方法, 选取有关高校图书馆使用社交网络这一主题的文献进行实验, 用Matlab R2012a对构建的共词矩阵进行PMD分解降维。
【结果】利用PMD从1 648个特征词中提取出65个核心特征词, 不仅大于用主成分分析提取的34个特征词, 而且揭示出高校图书馆使用社交网络的研究热点。
【局限】实验中提取的高校图书馆使用社交网络的特征词未能全面涉及, 有一定的主观性。
【结论】用PMD方法对高维共词矩阵进行稀疏后, 所获核心特征词更容易被理解和解释, 也能够表明一些边缘化的主题。
关键词:
惩罚性矩阵分析;
特征词提取;
主成分分析;
The Penalized Matrix Decomposition Method of Extracting Core Characteristic Words ——Taking Co-word Analysis as an Example
Abstract
[Objective]
Highlight core characteristic words directly by reducing the high-dimensional co-matrix sparely in co-word analysis.
[Methods]This article proposes, based on the Penalized Matrix Decomposition (PMD) method, a method to extract core characteristic words from texts of characteristic words.The authors experiment on articles which are related to university libraries that take advantage of SNS, and use Matlab R2012a to decompose high-dimensional co-word matrix by PMD.
[Results]By using PMD method, 65 core characteristic words are extracted from all 1648 characteristic words, which more than 34 characteristic words that extracted by the principal components analysis, and also reveal research hotspots of the university libraries using social networks.
[Limitations]The authors don’t refer to all the characteristic words that acquired from literature, and have a certain subjectivity.
[Conclusions]Converting into sparse matrix by PMD, core characteristic words are comprehended and explained more easily, meanwhile, they can show some marginal subjects.
Keyword:
PMD; Extracting core characteristic words; PCA;
目前, 有关共词分析的文献中, 基本是应用数学指标和关系范式与共词矩阵相结合, 通过揭示共词矩阵中的关键词或主题词, 来表现某一领域的研究热点和趋势。但是, 在互联网技术飞速发展的今天, 文本数据激增使得这一传统方法的使用受到了一定限制。
1 基于共词分析方法提取特征词概述
国内大部分学者从其研究领域出发, 将构建的高频词共词矩阵导入SPSS软件, 利用多元统计方法, 寻找各自领域所关注的主题和新兴学科的研究范式[
文献[6,7]用改进的共词分析, 对关键词或者主题词进行加权, 但跳脱不出因子分析等多元统计方法, 抽取的主题词或关键词不能充分体现该领域文本繁杂的特性。鉴于此, 本文提出了一种基于惩罚性矩阵分解 (Penalized Matrix Decomposition, PMD)[
2 惩罚性矩阵分解的概述
目前, 稀疏约束的方法广泛应用于人脸识别和基因提取等领域, 充分说明稀疏的方法在减少数据的复杂性方面具有显著的优势。同样的, 稀疏约束可以使复杂的文本变得容易识别和理解。PMD就是一种基于稀疏约束的矩阵分解降维方法, 在生物基因提取领域, Zheng等[
2.1 惩罚性矩阵分解的概念
惩罚性矩阵分解方法最早由Witten等[
X=UDVT UTU=Im VTV=In (1)
PMD通过对U和V施加惩罚性的约束条件来进行稀疏矩阵分解, 单因子PMD可以通过如下目标函数进行优化[
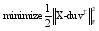 | (2) |
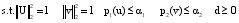
其中, u和v分别是分解后的矩阵U和V的一列, d是矩阵D对角线上的元素, ∙是Frobenius范式, p1和p2是具有多种函数形式的惩罚函数[
maximize uTXv (3)
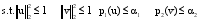
其中, 目标函数uTX在列向量u和v中是双线性的, 如果u是固定的, 那么v就是线性函数, 反之亦然。利用p1或p2对u和v进行惩罚性约束, 使p1(u)≤α1, p2(u)≤α2, 选取适当的参数α1、α2使u或v是稀疏的[
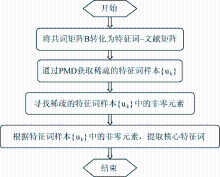
2.2 基于PMD的核心特征词的提取
本文利用PMD的目的是从大量杂乱的特征词文本中提取核心特征词, 这些核心特征词代表了所要探究领域的研究热点。由于PMD基于稀疏约束, 经过约束的矩阵的大多数系数都会变成零, 从而凸显出特征词样本的最主要部分, 使高维矩阵更加容易识别和解释。所以, 提取出的核心特征词可以捕捉到相同条件下所有特征词样本的变化, 能够直观迅速地分析出所研究领域的热点和研究方向, 为后续发现文本中主要特征词提供了参考方法。
对于共词分析中的n×n维的共词矩阵B, 有B=XTX, 再求得特征词-样本矩阵X后, 参照文献[11]用PMD将其分解成两个基本的矩阵U和V, 即X~UV, 它们分别为左奇异矩阵和右奇异矩阵[
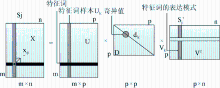
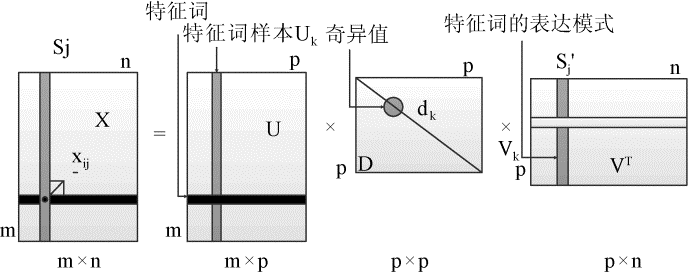 | 图1 文本数据的元样本模型图 |
{kind=link}
通常, 文本数据的元样本定义为原始样本的线性组合, 元样本数据应包括数据的本征结构, 从另一方面说, 每个样本都可以看成元样本的线性组合[
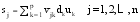
本文中矩阵X的第j列元素, 即m维的向量sj, 是特征词样本{uk}中各样本的线性函数, 可以由特征词样本{uk}来表示, 通过选择适当的惩罚函数p1, 使u1≤α1, 可以得到一个有很多零元素的稀疏矩阵u, 其中的非零元素就代表核心特征词。由于 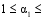
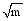
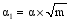
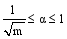
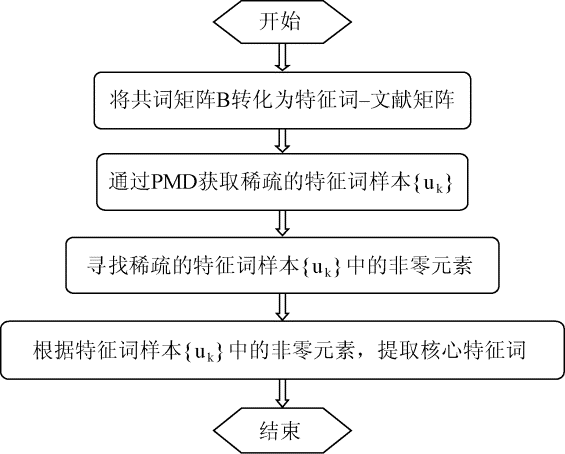 | 图2 基于PMD的核心特征词流程 |
{kind=link}
3 实验过程及结果
主要选取有关高校图书馆使用社交网络这一主题的文献进行分析, 对构建的特征词共词矩阵进行PMD分解降维, 并提取出核心特征词, 通过对比基于主成分分析和PMD提取出的核心特征词, 验证PMD方法的有效性。
3.1 数据来源
以CNKI中国期刊全文数据库为文献来源, 对有关高校图书馆使用社交网络的文献进行调研查询, 以期得出高校图书馆使用社交网络的核心主题和今后的发展趋势, 希望能有别于针对某一社交网站的案例调研分析, 深入研究文献内容中隐含的潜在信息, 客观总结出能够将高校图书馆服务融入社交网络的好方法。
利用专业检索, 设定检索式为SU=(‘SNS’+‘社交网络’+‘社交网站’+ ‘twitter’+‘facebook’+‘微博’+‘人人网’+‘校内网’+‘豆瓣网’+‘开心网’+‘QQ空间’)+(‘图书馆’), 可以检索到主题为“SNS”或“社交网络”或“社交网站”或者“微博”或者“人人网”等有关“图书馆”的所有文献信息。然后对检索的407篇(除去与主题无关的论文、报告和通知等)相关文献, 统计出各个文献的题目、摘要和关键词。
将所有文献的标题和摘要导入武汉大学开发的ROST软件, 加载分词自定义词表, 如将“微”“博”统一为“微博”, 将“豆瓣”“网”统一成“豆瓣网”等, 最终得到分词后的标题和摘要中的文本。然后, 对分词后的标题和摘要文本及原有关键词进行表面特征的简单整合, 如将“高校学生”统一为“大学生”等。另外, 将影响本文研究内容的关键词“图书馆”进行舍弃, 进而邀请4位专家对每篇文献中剩余的特征词进行判定, 决定这些特征词是否代表了该文献的主题内容, 最终得到特征词1 648个。用ROST软件统计词频并排序, 如表1所示:
| 表1 高频特征词局部 |
3.2 数据处理
通过简单的词频统计可以清楚地看到在应用社交网络提升图书馆服务这一方面, 高校图书馆远远高于公共图书馆。其次, 特征词“微博”出现的最多, 为199次, 可见, “微博”平台的使用率和研究率是最高的。通过高频特征词可以了解该领域研究的基本情况, 但是会忽视低频词对这个研究领域的影响。况且, 单凭词频统计还不能进一步反映这些主题词之间的关系[
| 表2 特征词共词矩阵局部 |
表2中单元格的数据是两个关键词共同出现的次数, 这一数字越大, 说明这两个关键词在整个样本中相遇的机会越大, 如“微博”和“高校图书馆”的共词频次为62, 即有62篇论文同时使用了这两个特征词。
3.3 实验结果
利用PMD方法对搜集到的所有特征词样本进行分析, 因为PMD是一种基于稀疏约束的降维方法, 可以将大量复杂的矩阵向量变稀疏, 因此忽略选取高频特征词这一步骤, 对所有特征词所构成的共词矩阵进行分析。这样, 不仅将能够统计出表现热点的高阈值的特征词, 还能够统计出代表边缘化主题的低阈值特征词, 使共词分析结果更加客观和完整。
在Matlab R2012a中, 首先将特征词共词矩阵转化为特征词-文献矩阵(详见本篇论文的网络版本), 并对其进行标准化处理, 其中要求均值为0, 方差为1。再利用PMD方法对这一样本进行核心特征词的提取, 通过对特征词-文献矩阵进行奇异分解即X~UV, 利用l1范数对U进行约束, 设迭代100次后u变得收敛。由于 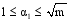
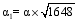
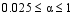
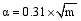
| 表3 基于PMD提取的核心特征词 |
从提取出的65个核心特征词中, 可以清晰地看到目前国内学者对于高校图书馆使用社交网络的讨论情况: 越来越多的高校图书馆使用微博这一社交网络提供信息服务, 各高校图书馆如何选择适合自己的微博平台成为当之无愧的焦点; 更加关注高校图书馆如何高效率地在其社交网络的主页上组织和发布信息; 探讨国外高校图书馆开展社交网络服务的具体内容, 给我国高校图书馆社交网络应用出现的问题提供解决措施。
其中, 特征词“媒体推广”“图书搜索”“同行关注”“重庆大学图书馆”“清华大学图书馆”等都是阈值低于4的低频词, 而特征词“微博信息推送”是一个阈值为1的低频词, 充分说明利用惩罚性矩阵分解可以清晰地发现高校图书馆应用社交网络这一研究领域的一些边缘化主题, 特别突出了对社交网络使用贡献较大的高校图书馆, 即清华大学图书馆和重庆大学图书馆。这些阈值低的特征词不仅表现出高校图书馆可以利用社交网络进行媒体推广和形象维护, 而且在将微博融入图书馆服务这一方面, 表现出高校图书馆可以在多种商业平台上建立系统化的微博账户, 分层分级, 充分利用现有的资源, 扩大服务的受众面等。
3.4 对比分析
(3) 结果对比
为了验证本文提出的PMD方法的有效性和优越性, 笔者对该组特征词样本进行主成分分析, 提取出特征词样本的主成分和影响主成分的特征词。根据经验选取词频大于4的高频特征词, 构建一个176×176的高频特征词共词矩阵T, 并对其进行分析。
(1) 主成分分析过程
主成分分析(Principal Components Analysis, PCA)由Pearson提出[
在Matlab R2012a中, 运用协方差矩阵进行主成分分析(Pcacov), 得到主成分(COEFF)、协方差矩阵T的特征值(Latent)和每个特征向量表征在观测量总方差中所占的百分数(Explained)。笔者分析的矩阵T是一个n×n的矩阵, 得到的主成分中每列数据代表了主成分与变量的相关系数, Latent中存放对应矩阵的特征值, 这些特征值在函数里面是通过矩阵奇异值分解实现的。
(2) 主成分分析结果
最终提取出67个主成分, 其累计贡献率为85.15%, 即这67个主成分可以解释高校图书馆使用社交网络全部信息的85%以上。其中, 前7个主成分解释的方差比例较高, 累计方差解释贡献率为37.30%, 表明这7个主成分可以解释我国高校图书馆使用社交网络现状的37%以上的隐含信息。基于主成分分析的特征词如表4所示, 其中每一个数字代表主成分与特征词样本间的相关系数, 即主成分的因子载荷量, 它的大小和它前面的正负号直接反映了主成分与相应特征关系的密切程度。
根据统计学惯例, 并结合本研究的样本数量, 规定因子负载的绝对值超过0.3的才被接受, 超过0.4则对解释该主成分有帮助[
| 表4 基于主成分分析的特征词 |
将主成分分析方法提取出的主要特征词与用PMD方法提取出的核心特征词对比, 发现有17个重复的特征词, 说明这17个特征词必然表示了高校图书馆使用社交网络研究现状的热点, 而主成分分析方法提取出的主要特征词基于阈值大于4的高频特征词, 在进行分析初始就有一定的局限性和主观性, 而提取出的34个主要特征词, 从数量上来说就远小于基于PMD方法提取出的65个核心特征词, 从质量上看PCA方法提取出的特征词未能体现边缘化的主题, 但PMD方法能够比较客观和全面地反映出过去和现在的研究热点, 揭示了一些潜在的研究趋势。
值得注意的是, 基于PMD提取的核心特征词表明在现阶段越来越多的研究不再反映高校图书馆使用社交网络的途径和目的, 而是关注高校图书馆如何组织社交网络的主页, 对社交网络上的信息进行内容分析, 研究实践中的高校图书馆在社交网络上运营自己的主页的情况。比如清华大学图书馆和重庆大学图书馆, 这一热点是在主成分分析中没有明确体现出来的。除此之外, 虽然两种分析方法都提取出了“公共图书馆”和“杭州图书馆”这两个特征词, 但是基于PMD提取的核心特征词有明确的指向性, 即高校图书馆应用社交网络时也要向公共图书馆学习, 不仅要提高图书馆的服务质量, 也要重复利用社交网络来进行图书馆营销和宣传推广, 维护各高校图书馆的形象。
4 结 语
本文中提出了一种新的方法对共词矩阵词进行降维处理, 即基于惩罚性矩阵分解的核心特征词提取方法, 根据实验和对比发现, 这一新的方法获得的核心特征词更容易被理解和解释, 它超越了之前共词分析中习惯使用的主成分分析法, 所以这种方法在进行共词分析时是十分有效的。
Reference
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|