

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
军事医学科研机构知识库建设实践与思考*
[郝继英 , 涂飞平, 陈锐, 路莹, 杨志滨, 王洪军]
, 涂飞平, 陈锐, 路莹, 杨志滨, 王洪军]
, 涂飞平, 陈锐, 路莹, 杨志滨, 王洪军]
|
|


作者贡献声明:
郝继英: 提出AMMS IR研建思路, 负责设计和实施研究方案;
陈锐, 路莹: 实施研究方案;
涂飞平, 路莹, 王洪军: IR软件的设计与实现;
路莹, 杨志滨: IR数据的采集、组织加工和入库;
郝继英, 涂飞平: 论文起草, 论文多次版本以及最终版本的修订。
【目的】研建军事医学科学院机构知识库(AMMS IR), 促进机构知识资产的科学组织、集中揭示、存储管理和重用。【应用背景】完全遵循DSpace开发原则, 采用B/S架构, 使用PostgreSQL开源数据库, 利用Java语言进行开发。【方法】在最核心的逻辑和功能上沿用DSpace-Core API部分, 但不再依赖DSpace默认的展示层, 在DSpace-Core API基础上重新设计, 加入全新的“事件机制”、“插件机制”和“访问链”等机制。【结果】实现Solr作为搜索引擎的递进式分面检索与浏览、科技档案管理、机构资源数据分析和相关作者数据分析等功能。【结论】在基于DSpace的机构知识库软件系统的分面检索、语义分析等功能方面进行有益的探索与实践。
[Objective] Study the construction of Institutional Repositories of the Academy of Military Medical Sciences (AMMS IR) in order to promote the scientific organization and concentrated reveal, storage, management and reuse of AMMS knowledge assets. [Context] In full compliance with the principle of the DSpace development, AMMS IR is constructed with the use of B/S architecture and Java language based on the PostgreSQL.[Methods] The DSpace-Core API is redesigned by keeping using the core logic and functionality of DSpace-Core API section and adding new “event mechanism”, “plug-in mechanism” and “Access chain” and other mechanisms instead of merely relying on DSpace default presentation layer.[Results] With Solr as the search engine, it is realized that the progressive faceted search and browsing, technological file management, data analysis of institutions and authors.[Conclusions] Useful exploration and practice is carried out in terms of the faceted retrieval, semantic analysis of software system based on the construction of institutional repositories with DSpace.
开放获取(Open Access, OA)运动于20世纪90年代末逐渐兴起, 在2001年“布达佩斯开放获取倡议(BOAI) ”的推动下[ 1], 得到了学术界、出版界和图书情报界等行业的积极响应, 一种基于互联网的、免费开放的、以促进信息共享为目的学术信息交流环境应运而生。目前, 在美国、英国等国家政府层面的开放获取政策的支持下, 开放获取正在进入一个快速发展的时代。截至目前, 根据DOAJ(Directory of Open Access Journals)的统计, 现有来自122个国家的9 919种开放获取期刊, 其中基于论文的开放获取期刊有5 616种[ 2]; 根据OpenDOAR(The Directory of Open Access Repositories)的统计, 已有2 566个开放获取知识库, 其中机构知识库(Institutional Repositories)2 113个, 政府知识库(Governmental Repositories)73个, 学科知识 库(Disciplinary Repositories)279个, 汇总类知识库(Aggregating Repositories)95个, 以机构知识库的发展最为显著。在2 113个机构知识库中, 根据国别的统计, 排名前10位的国家分别是美国(435个), 英国(219个), 德国(168个), 日本(143个), 西班牙(109个), 中国(96个, 其中台湾地区58个), 法国(82个), 意大利(75个), 巴西(81个), 波兰(80个)。由此可看出, 以美国、英国为代表的发达国家是机构知识库建设的主体力量, 以中国、巴西为代表的发展中国家拥有的机构知识库数量逐年增多, 发展较快。根据所采用软件平台的统计, 排名前10位的软件平台分别是DSpace (1 064个), Eprints( 373个), Digital Commons( 119个), dLibra ( 57个), Green Stone( 55个), CONTENTdm( 48个), HTML( 36个), Fedora( 32个), DiVA-Portal( 32个), Open Repository( 23个), DigiTool( 22个)。由此可看出, DSpace、Eprints、Digital Commons仍然是全球机构知识库建设者最为青睐的三个开源软件系统[ 3]。
在开放获取运动中, 图书情报界一直是积极的参与者和实践者, 充分发挥了自身在信息采集、信息组织和信息分析等方面的优势, 在开放获取理念的宣传、机构知识库建设、开放获取政策的研究与推动、参与学术出版等方面的实践中开展了卓有成效的工作。特别是在作为实施开放获取政策的基础信息设施的机构知识库的建设中, 图书馆对所在机构知识库的筹划与实施, 对于所在机构知识资产数据的科学组织与揭示, 使其正在成为本机构知识的管理者, 在机构知识资产的描述、存储、管理和重用中不断彰显着自身的价值, 如康奈尔大学的arXiv.org电子预印本文献库[ 4]、哈佛大学的DASH(Digital Access to Scho-larship at Harvard)[ 5]、麻省理工学院的DSpace@MIT[ 6]等。
中国人民解放军军事医学科学院是全军最大的军事医学科研机构, 在组织实施“数字化军事医学科学院”建设中, 高度重视本机构知识资产的管理与利用, 经中国人民解放军医学图书馆申请, 军事医学科学院机构知识库(Academy of Military Medical Sciences, Institutional Repository, AMMS IR)的研建列入该院“十二五”信息化建设规划任务, 并由解放军医学图书馆承建。
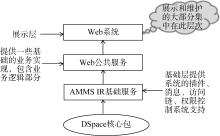
AMMS IR的体系架构如图1所示:
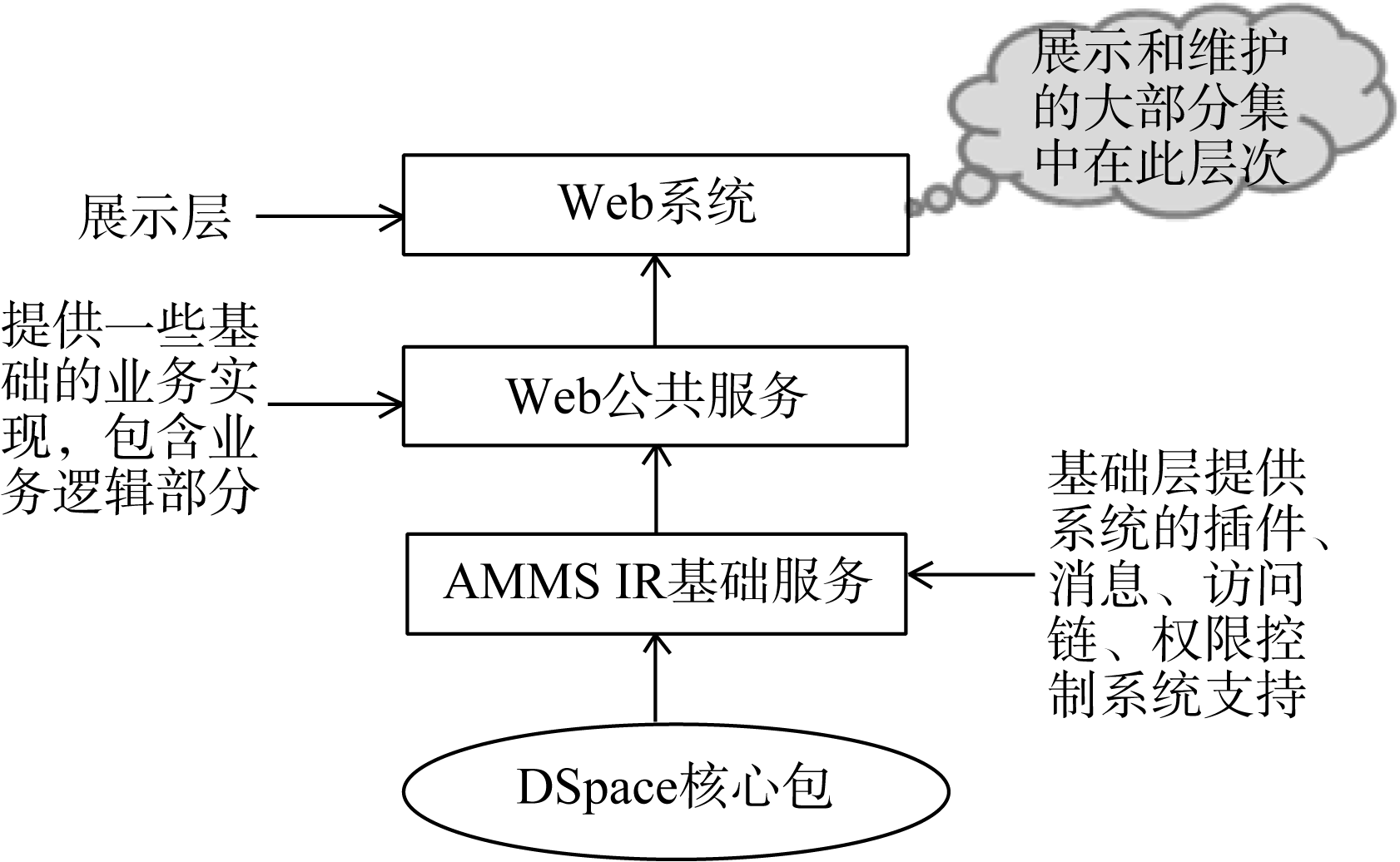 | 图1 AMMS IR的体系架构 |
AMMS IR的系统软件架构包括基础层、业务逻辑层和应用层三部分, 在最核心的逻辑和功能上, 还是沿用了DSpace-Core API部分, 因为这部分功能是DSpace最核心、最稳定的部分。但是, 为满足AMMS IR系统建设需求, 在系统设计上不再依赖DSpace系统中默认的展示层(JSPUI), 而是自行根据需要, 在DSpace核心部分DSpace-Core API基础上重新设计实现了业务逻辑层和应用层, 这样更利于系统与DSpace的升级保持同一步调。在AMMS IR系统建设过程中, 为了系统的快速开发和后期的维护, 在架构中引用了最新的Spring3.0框架, 并加入全新的“事件机制”、 “插件机制”和“访问链”等机制。
AMMS IR系统采用B/S架构, 使用PostgreSQL
开源数据库, 采用Java语言进行开发。在开发过程中, 完全遵循DSpace的开发原则, 包括数据库表建立和映射方式, 开发的过程中并没有改变DSpace已有的库表结构, 对于DSpace对象的操作, 也是完全基于DSpace-Core中的API, 不直接操作DSpace的库表。这样做的好处是可以紧随DSpace的版本升级进行快速升级。AMMS IR的应用环境与DSpace完全一致, 如图2所示:
 | 图2 AMMS IR的开放应用环境 |
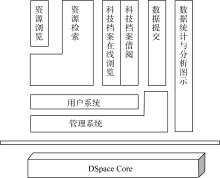
AMMS IR的系统功能主要包括资源浏览、资源检索、数字科技档案借阅与在线浏览、数据提交、用户系统、管理系统和数据统计与分析图示等模块, 这些功能模块之间存在层次和依赖关系。
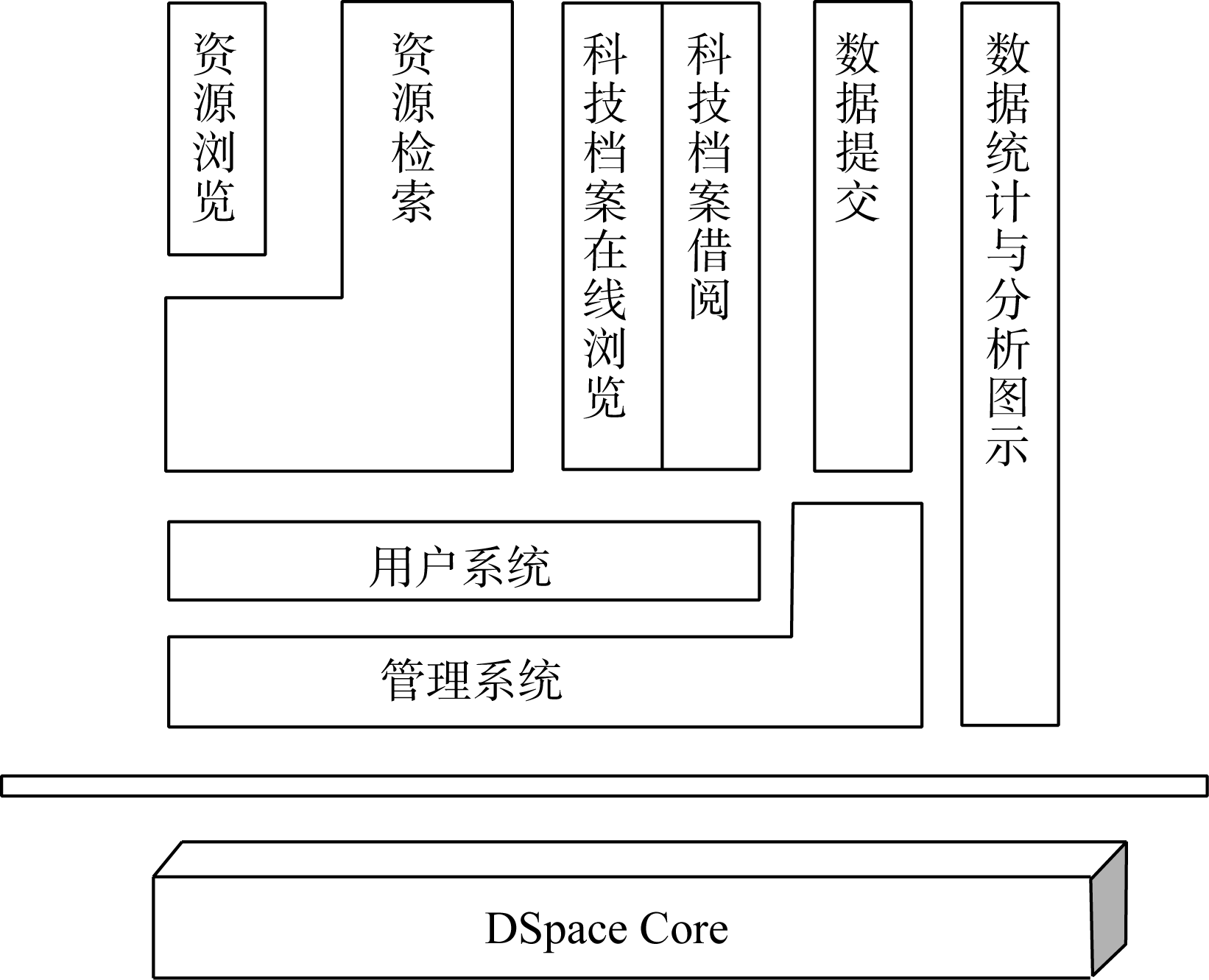 | 图3 AMMS IR的系统功能 |
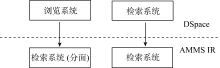
在资源浏览和检索功能的设计上, AMMS IR完整地使用了DSpace提供的资源类型、年份、作者和机构的浏览方式, 但是, 为了快速定位所需文献信息, AMMS IR摒弃了DSpace系统原有基于Lucene的检索API, 在检索部分全部采用Solr来完成, Solr的检索部分使用DSpace的事件机制[ 7], 使检索部分独立出来成为Web Service, 可以使院内其他的信息系统直接通过Web接口检索机构知识库的数据, 同时又可充分施展Solr在检索结果集合分面上的强大功能, 提供查询结果的递进式分面聚类。AMMS IR资源浏览模块是以资源检索模块为基础, 通过采用Solr来实现原有的浏览系统(DSpace是基于数据库快表完成此功能), 而对于资源类型、日期和作者等元数据的分类, 都直接采用Solr的分面来完成, 以利于把数据浏览和数据检索统一到同一个模块中, 如图4所示:
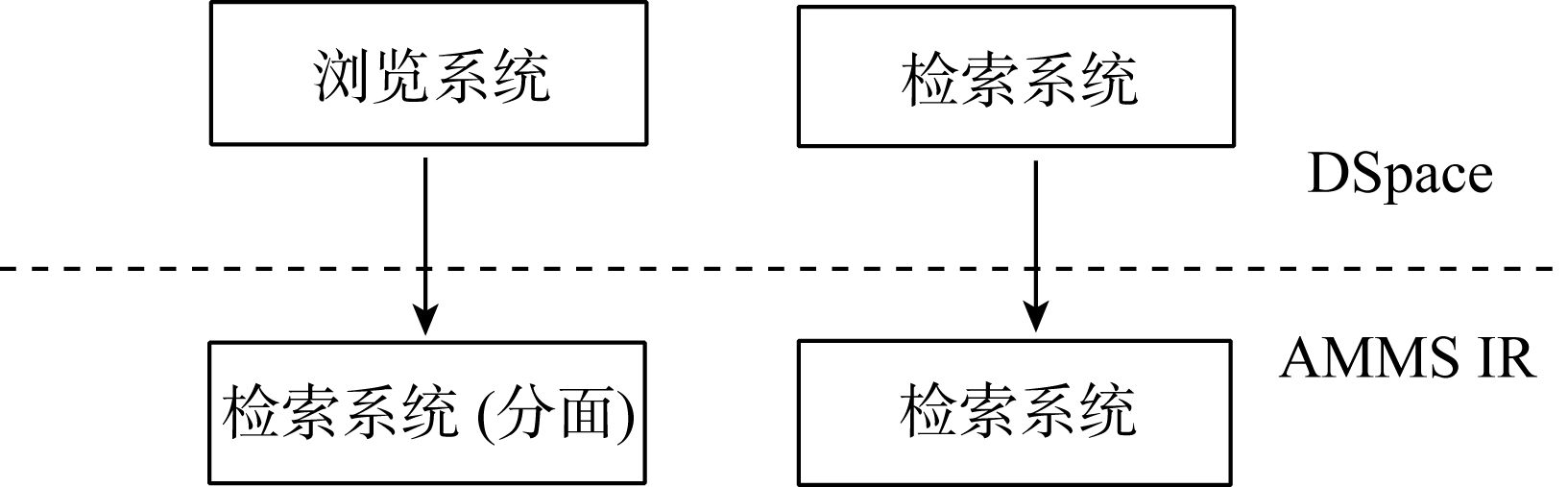 | 图4 AMMS IR的分面聚类检索 |
DSpace系统本身对机构知识库的数据分析功能的支持比较弱, AMMS IR在构建之初, 就考虑增加机构作者的分析功能。因此, 在AMMS IR后端数据加工方面和前端数据展示方面, 都进行了有关开发工作, 特别是在作者分析上进行了有益的探索。目前, AMMS IR后端的语义分析模块可以对4层相关联作者关系进行推算与分析, 在前端部分采用Flash展示分析结果。语义分析模块在整个AMMS IR系统中是作为一个插件进行开发的, 主要采用内存表和系统表结合的方式实现, 系统表作为数据缓存表, 而内存表采用HSQLDB建立, 主要作为运算中间结果的存储表。系统采用基于DSpace事件处理[ 9]方式建立了Semantic快表, 在第一次进行作者或关键词分析数据请求时会查找该表, 如果表中无指定缓存记录, 会在内存中创建运算表记录并开始分析。
系统在初始化时, 会自动创建内存表(Authors和Keywords, 目前仅支持作者和关键词的分析), 表的初始化部分采用多线程方式在后台运行, 并不影响Web服务的启动和响应。为提高检索效率, 在创建表的同时也创建了检索字段的索引。对于作者、关键词等常见的分析计算, 采用Java与数据库快表结合的方式, 在内存中完成运算, 由于运算部分比较占用服务器资源, 所以并未采用实时计算方式, 而是在第一次请求时完成计算, 然后将分析结果缓存到缓存表中, 因此在第一次对某个作者或者关键词进行分析和展示时会有一定延时。对于数据的处理, 以Author分析数据为例, 主要通过prepareAuthorData方法, 将DSpace系统中的作者数据加入到内存Authors表中, 在完成内存作者数据初始化后, 当有作者或者关键词分析请求时, 会调用processValue方法来返回关联信息, 代码如下:
// Author和Keyword分析检索SQL定义
private static String[] queryStrings = { "",
"select count(*) as cc, m2.keyword as tt from keywords m2,"
+ " (select * from keywords where keyword=?) m1 "
+ " where m2.itemid=m1.itemid group by m2.keyword order by cc desc limit ?",
"select count(*) as cc, m2.author as tt from authors m2,"
+ " (select * from authors where author=?) m1 "
+ " where m2.itemid=m1.itemid group by m2.author order by cc desc limit ?" };
// value is author or keyword value, type is AUTHOR or KEYWORD
public static void processValue(int type, String value,
List
throws SQLException {
//获取内存数据库链接
Connection conn = DBFactory.getConnection();
//根据类型获取指定的分析SQL, 然后开始检索
PreparedStatement st = conn.prepareStatement
(queryStrings[type]);
st.setString(1, value);
st.setInt(2, size + 1);
ResultSet rs = st.executeQuery();
while (rs.next()) {
String au = rs.getString("tt");
int cc = (int) rs.getLong("cc");
//合成分析结果对象
LinkObject link = new LinkObject(value, au, cc);
if (link.getDst().equals(link.getSrc()) && inf != null) {
inf.setCount(link.getCount());
}
if (event != null) {
if (event.process(link, links))
links.add(link);
} else {
if (!DBUtility.hasLinkObject(link, links))
links.add(link);
}
}
DBFactory.release(conn, st, rs);
}
算法部分则比较简单, 主要以指定作者所属的itemid为基础, 检索这些itemid相关的其他作者即可得到相关作者, 然后对返回记录进行Count运算, 即可得到与相关作者的资源合作篇数。由于运算部分采用数据库检索, 运算速度表现很好, 在首次运行时, 平均每个作者的计算时间都在1-3秒内。对于AMMS IR的数据量(以30 000条计算), HSQLDB的数据库内存占用量在同时支持相关作者和相关关键词的条件下稳定在60M左右, 资源占用和运算速度比较令人满意。
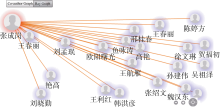
目前, AMMS IR系统中的分析功能仅包含机构资源数据分析和相关作者数据分析两个部分, 机构资源数据分析以机构、年份和资源数量作为分析的主体, 在分析界面的下方可列出对应选择的机构资源提交的前8名作者的信息; 相关作者数据分析以作者为主体, 通过作者所著知识资源包含的其他作者来推导作者所有的合作者或相关作者, 由于展示原因, 现仅显示与分析作者相关的前20位作者, 如图5所示:
上述数据分析的算法和相应速度虽然较理想, 但是分析内容比较简单, 仅是通过数据库方式来实现。
为实现更深入的数据挖掘, 在后期功能设计上拟加入Jena来重新编写分析这部分。
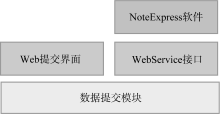
AMMS IR在开始设计时就考虑到与其他系统的数据交互, 例如数据的批量导入和导出, 所以将数据交互部分设计为单独的Web Service对外提供统一的接口, 以便其他系统(无论采用何种编程语言实现)可以方便地与AMMS IR系统进行数据交互和对接。数据交互Web Service在系统中的层次关系如图6所示, Web Service接口与Web界面处于同一层次, NoteExpress软件和其他语言的提交工具(如Python开发的工具)均可以调用Web Service接口。AMMS IR在实施中得到文献管理软件公司提供接口的大力支持, 顺利完成了交互接口的设计和实现, 提供了标准的网页单条提交方式、批量提交方式、标准化Excel表格元数据+对象数据的页面批量提交方式、NoteExpress提交方式等4种数据提交方式, 实现了多种资源格式数据的快速导入。此外, 在AMMS IR的实施过程中, 也使用Python编写了部分脚本, 与接口对接使用, 取得了较好的效果。
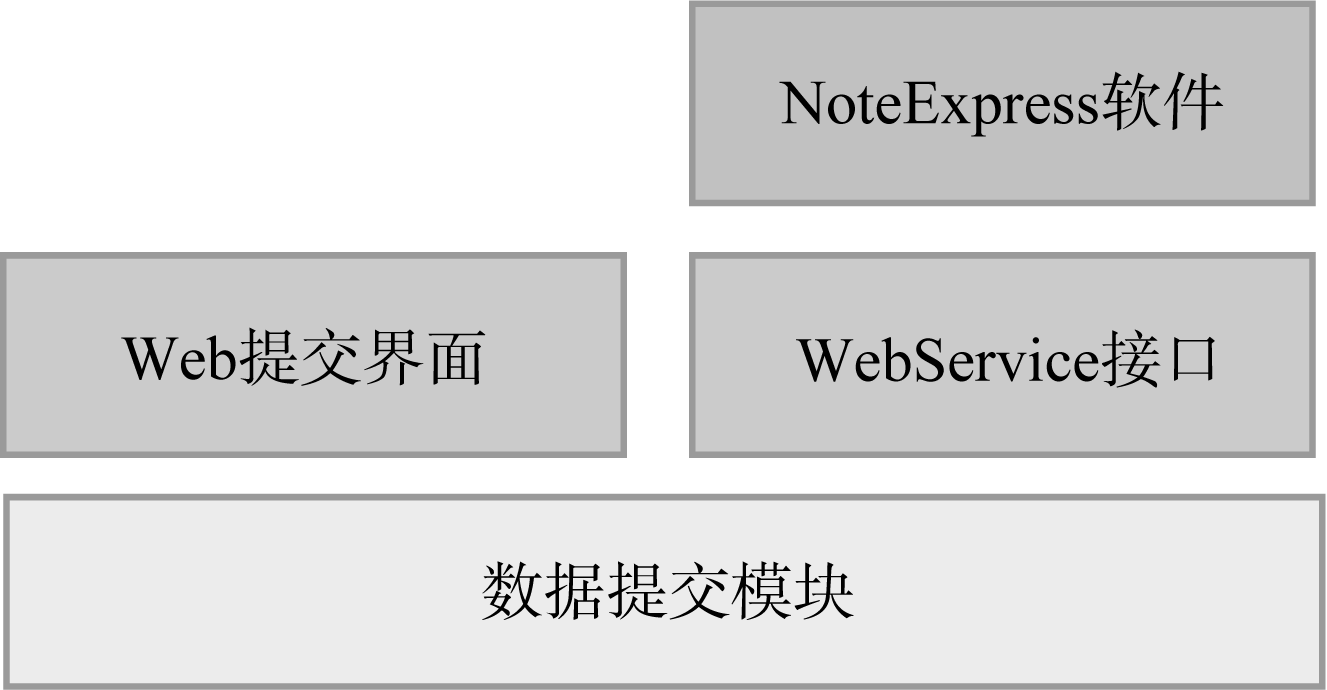 | 图6 与NoteExpress结合接口 |
目前, AMMS IR已完成系统软件的研发与测试, 军事医学科学院人员产出的各类知识资产正在收集和整理的过程中, 现已入库的元数据达到38 928条, 全文数据32 449条, 其中, 期刊论文31 300 篇, 学位论文2 356 篇, 会议论文2 691篇, 专利2 315篇, 涵盖军事医学科学院的11个研究所、1个附属医院等所有直属机构人员产出的期刊论文、学位论文、会议论文、专利、图书专著、科技档案、研究生教材等各类知识资产类型, 最早的数据追溯到1978年, 如图7所示。
 | 图7 AMMS IR系统首页 |
《2012 Top Ten Trends in Academic Libraries》一文在阐述学术图书馆的10大发展趋势时[ 8], 在学术交流体系中的价值(Communicating Value)、数据监管(Data Curation)、数字保存(Digital Preservation)、馆员队伍(Staffing)等方面都提到与机构知识资产管理和机构知识库的建设紧密相关的内容。文中指出, 在数字化网络化信息交流体系中, 图书馆必须证明自身对于所属科研学术机构的价值; 机构原生文献的收集、保存和管理日益受到关注, 学术图书馆将更加重视稀有、独有的资源或者机构特有资源(例如灰色文献等)的数字化及其服务; 随着科学数据的不断增长, 知识库不断出现, 数据监管的挑战也与日俱增, 图书馆将和所属科研机构合作, 共同推进知识库的建设和数据监管的进程。正如文中所述, 研究型图书馆的未来生存与发展, 取决于其是否是所在机构知识创造过程中的一个环节。随着科学技术的发展愈来愈趋向于协作化、数据化、计算化, 研究人员面临着大量科研数据管理的需求, 而美国国家科学基金会(National Science Foundation, NSF) 等科研项目资助者也陆续明确提出数据保存与开放获取的要求, 在这种信息环境下, 研究型图书馆近年来在机构知识库建设实践中已经发展成为所属机构知识数据的管理者和服务者。因此, 无论是现在还是未来, 图书馆在筹划与实施机构知识库建设时, 针对图书馆自身定位方面的考虑, 是一定要争取成为机构知识创造周期中更为积极的参与者, 甚至是机构知识的创造者。
Clifford Lynch在2003年曾这样阐述一个成熟的机构知识库的内涵[ 9], 他重点强调的是机构知识库的内容建设, 主要包括机构人员的所有知识产出(包括研究资料和教学资料)、机构学术生活的记录、机构成员学术活动中产生的实验数据和观测数据等三个方面。内容是机构知识库的生命, 对于AMMS IR下一步的发展, 目前主要考虑的是在继续加强内容建设的同时, 展开关于机构知识库内容的分析研究。具体包括以下几个方面:
(1) 全面揭示
在知识类型上, AMMS IR将从现有期刊论文、研究报告、技术报告等扩展到教学课件、科研简报等内部刊物、主办的会议资源(会议论文集及海报)、历史资料等其他原生知识资源, 从传统的文本型知识资源扩展至图像、视频、音频等非文本型知识资源, 非文本型知识资源的收集与组织, 无疑是目前急需研究的一个热点问题。从时间跨度上, AMMS IR将从目前1978年以来的数据回溯到1951年建院时间, 力求“全时长记忆”军事医学科学院科研学术的历史“印记”。目前入库的数万条机构知识库数据虽然经过数据清洗和人工逐条核查, 但从支撑科研管理和机构知识管理的角度来看, 数据还需要大量的精细组织与加工。例如著者信息在原文献中本身就可能存在着不规范、不统一等问题; SCI期刊和中文核心期刊的标注等问题。只有对机构知识资产全面、精确揭示, 机构知识库才能更为高效地支持科技创新, 才能与科研信息管理系统的数据进行共享与利用, 从而支持科研管理。
(2) 深度分析与服务
AMMS IR完成历史数据的收集、组织与入库后, 项目组在宣传推广利用的同时, 准备以AMMS IR所收录的资源为研究对象, 采用文献计量学等方法, 对于不同类别、不同时限、不同研究群体或个人的知识产出资源进行社会网络分析、共词分析等深度分析, 为科技管理人员、研究人员提供机构知识图谱、合著者网络、学科热点分析等基于文献或数据的另一视角的分析报告, 为其科研决策提供参考。项目组已经利用AMMS IR的数据完成了2006年-2010年、2011年、2012年全院SCI论文的统计分析报告, 在得到科研管理部门的认可和肯定的同时, 也增进了管理部门对机构知识库的认识。