
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于分众分类法的图书馆书目推荐系统*
[罗琳 , 梁桂生, 蔡军]
, 梁桂生, 蔡军]
, 梁桂生, 蔡军]
|
|


作者贡献声明:
罗琳: 提出研究思路, 设计研究方案;
梁桂生: 数据收集, 系统设计;
蔡军: 系统评价;
罗琳, 梁桂生, 蔡军: 论文写作。
【目的】利用分众分类法构建用户、资源和标签的三元组关系实现图书推荐系统。【方法】利用协同过滤技术, 采用余弦算法计算资源相似度, 分别设计了书目权值和标签权值, 利用稀疏向量的表示方法来表示输入矩阵中的每个资源来压缩稀疏矩阵存储。【结果】计算后发现书目权值主要分布在0-200的区间内, 标签权值符合幂率分布。使用AP和MAP指标对比书目权值高的前20本书在本系统的相关推荐结果要优于豆瓣网。【局限】 因为目前图书馆参与书目标注行为的用户数量不够, 所以本文的数据是在采集图书馆的书目数据基础上获得豆瓣网上的该书所对应的用户标注数据。【结论】本研究有利于图书馆OPAC系统功能完善, 利用用户标注数据了解用户需求, 提供更好地个性化推荐服务。
[Objective] This paper tries to build a book recommender system based on folksonomy, which forms the triple relations among the users, resources and tags.[Methods] This paper calculates the cosine similarity and weights of books and tags, use sparse vector representation to represent the input matrix for each resource to compress sparse matrix.[Results] Experimental results show that the book weights varied from 0 to 200 and the tag weights followed a power law distribution. In the end, the relevant assessments are performed with the AP and MAP indicators.[Limitations] It fails to get enough data in the library catalogs, hence collects the additional data in book.douban.com.[Conclusions] The recommendation system can help the OPACs to improve its function and personalized services.
分众分类法自2004年被提出之后[ 1], 在网络应用系统中逐渐开始流行开来。该方法为Web2.0环境下的信息资源组织管理提供了一种可行的解决方案, 不仅表现在对数量日益增长的网络资源管理的有效性, 而且也适应了当前网络中资源的多元化类型。
分众分类法的本质是用户通过系统提供的标注接口, 给标注对象自由添加标签, 通过用户的标注行为生成的标注数据可以揭示出系统中资源的内容以及资源之间的关系, 体现了Web2.0环境以用户为中心的思想。本文借此将其应用到图书推荐系统中, 试图在图书管理系统中充分利用用户的自主性活动来揭示图书资源的内容以及资源之间的关系, 然后在此基础上通过协同过滤的方法来为用户实现图书资源推荐服务。
图书资源是图书馆中一种比较典型传统的资源类型。目前图书馆自动推荐研究主要利用用户的检索历史、借阅历史以及浏览历史等数据来为用户提供推荐。Gao等[ 2]利用用户的检索词以及用户的链接点击行为来构建用户的兴趣偏好, 提出了关于“4-R服务的目标”, 即将合适的信息在合适的时间以合适的方式提供给合适的用户。Avancini等[ 3]设计了在数字图书馆的环境下实现个性化的、协同的推荐系统, 提出了用户偏好模式的构建以及该模式系统所提供的一系列服务, 如预测用户的兴趣、发现用户之间的关系以及系统中的用户社群。王新筠[ 4]、蒋若珊[ 5]、雷蕾[ 6]提出的个性化推荐研究是基于对用户的借阅历史数据, 通过利用不同的数据挖掘方法对用户的借阅历史数据进行分析, 从而得到个性化书目推荐信息。王艳翠[ 7]通过Melvyl推荐项目分析了发展中的图书馆推荐服务, 其中系统采用了基于用户历史记录和基于书目记录术语方面的推荐服务。
基于分众分类法的推荐系统应用主要是在社交网站、电子商务网站等领域, 研究重点在于算法的改进和标签质量的控制等。前者主要表现在对传统推荐算法的优化, 如Milicevic等[ 8]提出了一种新的方法——PLSA来改善协同过滤方法的性能; Hotho等[ 9]提出了FolkRank算法, 它是PageRank算法的变体, 被应用在分众分类法的用户-资源-标签图上。后者表现在对用户的标注数据进行补充, 如Zheng等[ 10]在分众分类环境下引入了用户的标注时间信息来对标签信息进行补充。另外从传统的信息检索研究领域演变过来的基于内容分析的方法也被应用到分众分类系统的资源推荐中。Zhang等[ 11]结合资源内容分析的方法和相关性分析的方法来实现分众分类系统中的推荐服务, 用来改善用户标签数据的稀疏性问题。而图书馆应用仍然处于初级阶段, 根据Wakeling等[ 12]调查发现在英国图书馆OPAC系统中使用推荐服务的比例相当低, 公共图书馆和高校图书馆的应用比例分别为2%和11%。而笔者对我国高校图书馆OPAC系统使用分众分类技术的调查结果也显示其应用程度不高。
本文以分众分类法标注数据的相似性理论为基础, 试图构建一个基于用户标注行为的图书资源推荐系统, 并提出了新的资源权值计算方法。该系统包括标签推荐和资源推荐功能, 能够更好地为用户提供个性化推荐服务。
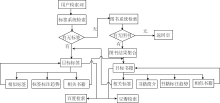
图书推荐系统的主要功能是: 基于用户检索词在标签系统和图书系统中检索, 执行相应的标签推荐和图书推荐功能, 将推荐结果返回给用户。其工作流程如图1所示。在标签系统中, 根据目标标签可以提供与目标标签语义有一定相似度的标签推荐、标签标注趋势和相关书籍推荐功能; 在图书系统中, 根据目标书籍可以提供与目标书籍相关的标签推荐、书籍简介、书籍标注趋势和相似书籍推荐功能。另外为方便用户进行目标标签和书籍的外部扩展检索, 本系统也提供了相关标签与书籍的百度链接和豆瓣链接的功能。
 | 图1 推荐系统工作流程 |
资源的相似性用于衡量系统中资源之间的语义关系距离。对于分众分类法中的资源相似性计算方法, Cattuto等[ 13]介绍了基于共现、余弦和FolkRank三个相关性算法, Markines等[ 14]提供了Match、Overlap、Jaccard、Dice、Cosine等相似性算法, 本文采用了基于向量空间模型的余弦算法, 如下所示:
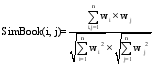 | (1) |
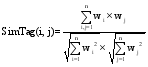 | (2) |
其中, 公式(1)为书目相似性计算公式, wi、wj分别表示第i、j本书目的权重值; 公式(2)为标签相似性计算公式, wi、wj分别表示第i、j个标签的权重值。
另外, 对于资源相似性的计算, 最主要的问题是稀疏矩阵的存储, 本文采用稀疏向量的表示方法来表示输入矩阵中的每个资源, 其表述形式如下所示:
Book(i) =(
Tag(j) =(
其中, 公式(3)中
在图书推荐系统中为用户推荐的资源集合结果, 通常需要按照资源的相关度或重要度等来进行资源的排序, 因此对于资源的权值计算是为了将系统推荐的结果更好地呈现给用户。传统的信息检索中通常采用共现或TF-IDF的方式来计算资源的权重值, 但是分众分类法由于其标注结构的特征性, 不能够直接利用现有的信息检索领域的权重计算方法, 因此本文分别对书目和标签定义了两种权值计算的方法, 如下所示:
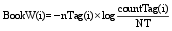 | (5) |
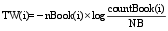 | (6) |
在公式(5)中, i表示图书编号, countTag(i)为书目被标注的次数, 反映了书目受用户关注的程度; nTag(i)为书目拥有的特征标签个数, 反映了书目内容的揭示程度; NT表示系统中参与标注的总标签数, 因此BookW(i)从书目内容以及受欢迎度两个方面反映了书目的重要度。与之类似地, 公式(6)中TW(i)从标签的特征性和流行性两个方面反映了标签的重要度。
本文首先获取了武汉大学图书馆小说类的约 3 000本图书书目记录, 鉴于武汉大学图书馆用户标签数据的稀缺, 将书目数据作为初始数据, 从豆瓣读书上采集了具体的用户标注记录205 090条, 其中包含1 465个用户记录、20 770个标签记录以及62 317个书目记录。对采集到的数据使用Markines等[ 14]提出的分布式降维方法, 将三元组形式的数据结构首先转换成标签-用户、书目-用户以及标签-书目三个二维矩阵, 以便进行后续处理。
(1)资源权值分布
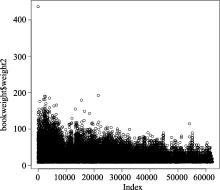
图2为书籍资源的权值分布散点图。通过观察可以看到, 图书资源的权重分布区间比较集中, 主要都分布在0-200的区间内。从书目的权值的分布可以发现书目的权值比较稳定, 因此对于书目资源来说, 在其权值分布区间进行推荐时可以减少推荐结果的偏差。另外散点图中出现了一个较突出的书目, 其权值的大小为436.3, 该书目的名称为“IN小说”, 对应的特异标签个数为79, 标注次数为83, 反映了该书目在被用户标注的同时也揭示了较多资源内容信息。
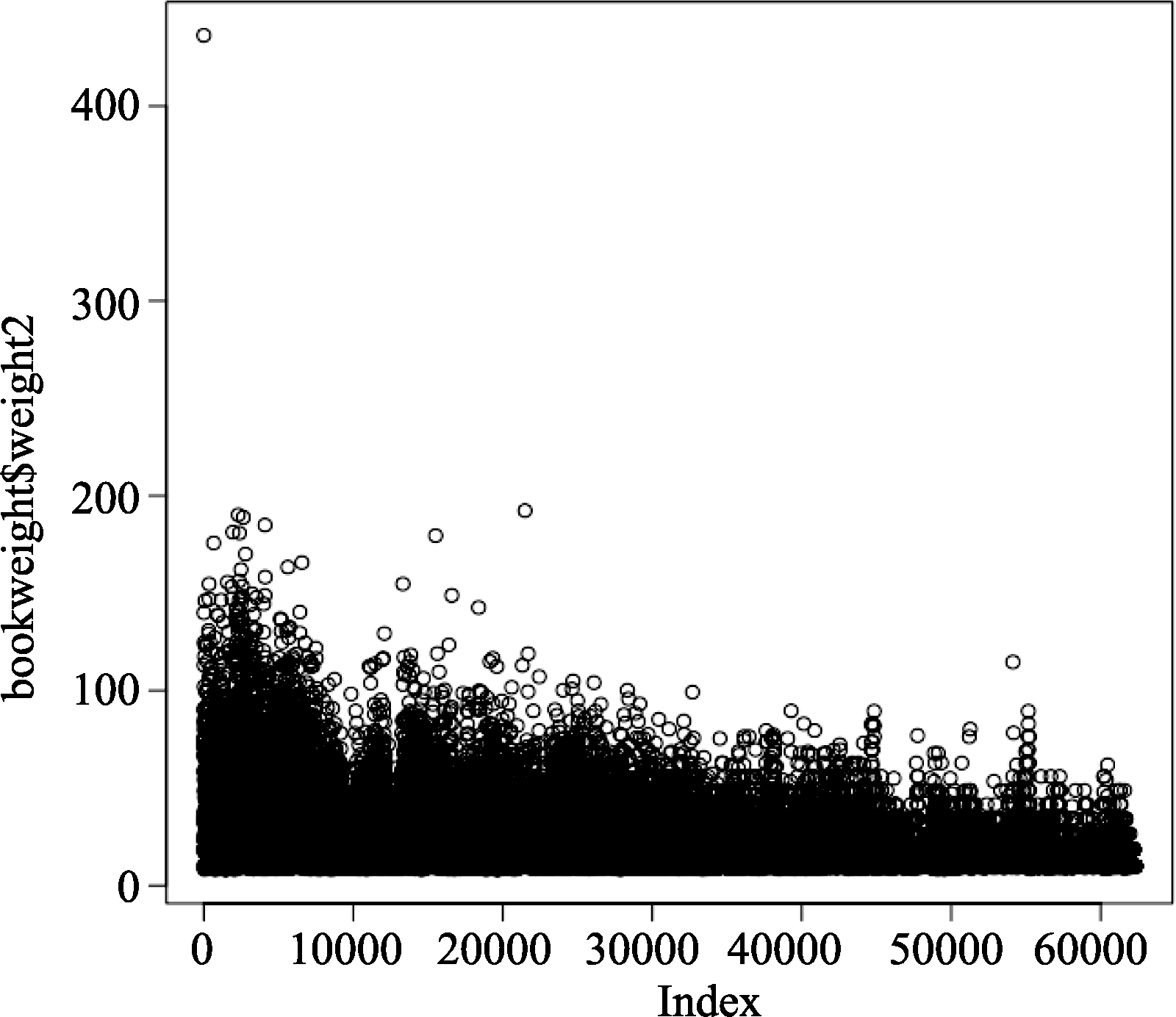 | 图2 书目资源的权重分布散点图 |
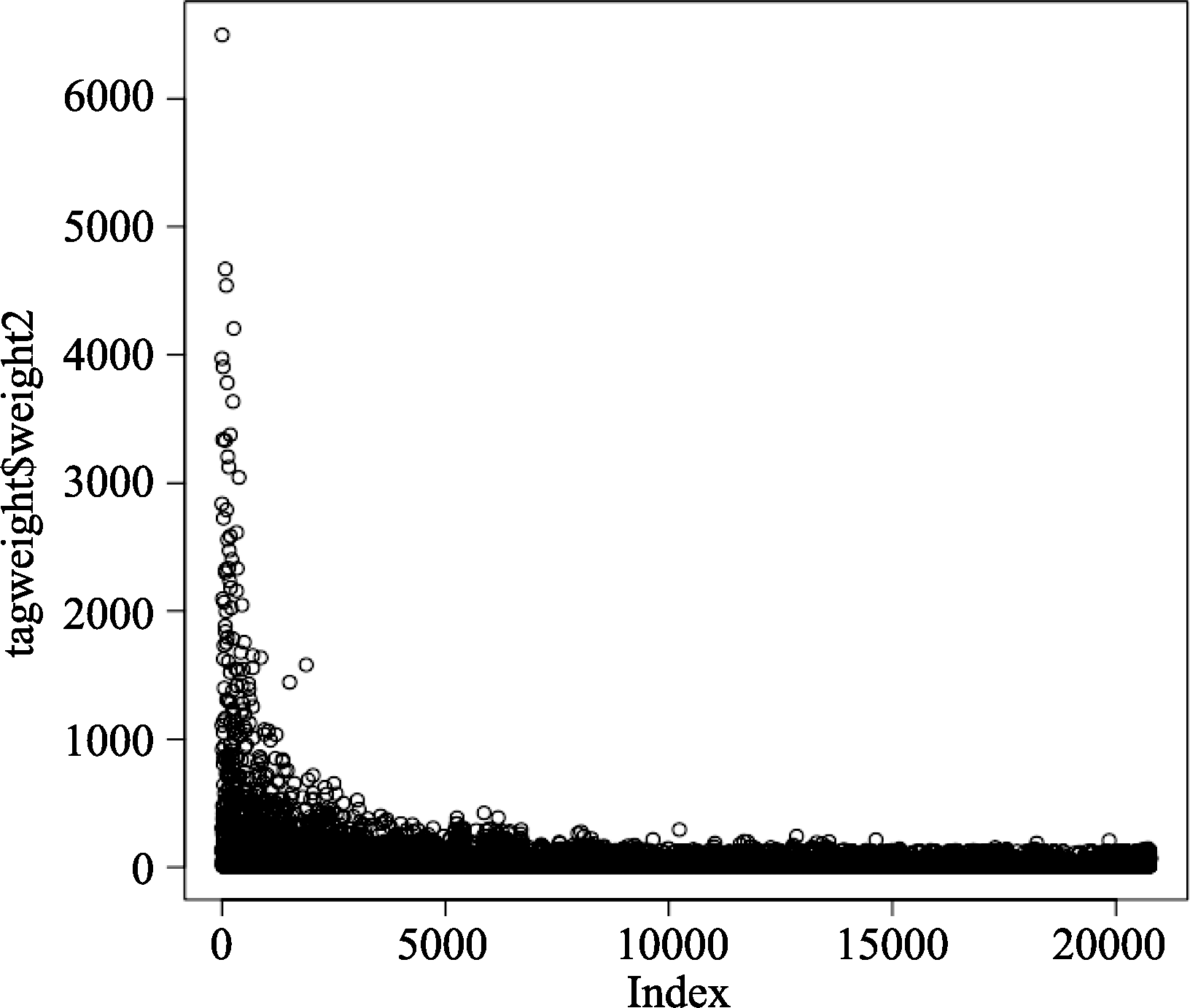 | 图3 标签资源的权重分布散点图 |
图3为系统中标签资源的权值分布散点图, 通过观察可以看到大量标签的权值分布在权值较小的区域, 少量标签的权值分布在左端权值较大的区域, 这也体现出分众分类系统中的标注数据的幂率分布相吻合的特征。与书目资源的权重分布相比, 标签的权值分布显得比较离散, 因此在进行标签资源推荐时, 需要考虑低权值区间分布的大量标签沉底以及提高标签资源利用率的问题。
(2) 系统功能展示
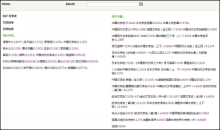
本实验的图书推荐系统基于用户输入关键词在标签库中进行检索, 并在此基础上实现标签相似性推荐和图书相似性推荐。如图4所示是以“文学史”作为检索词得到的系统标签检索推荐结果, 包括“相似标签”和“相关书籍”功能。“相似标签”提供了与目标标签对应的相似标签集合推荐, 为用户提供了额 外的资源发现功能, 该功能在“豆瓣读书”检索结果中没有提供; “相关书籍”中提供了与目标标签对应的相关书籍集合。
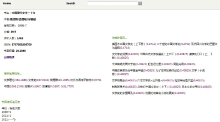
图5为点击图4“相关书籍”一栏中“中国现代文学三十年”书籍链接的结果, 结果包含“相关常用标签”和“你或许喜欢…”功能。“相关常用标签”中显示的是与目标书籍相关的标签集合推荐结果; “你或许喜欢…”是与目标书籍相关的书籍推荐集合。
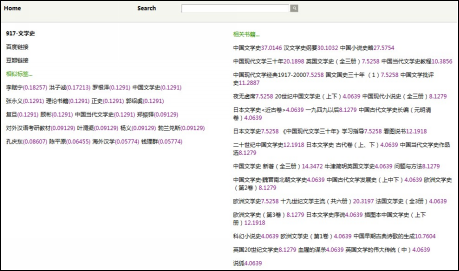 | 图4 图书推荐系统中的标签检索时书目资源推荐结果 |
 | 图5 图书推荐系统中的书籍链接检索的书籍详细页面 |
为了评价本系统的推荐效果, 采用信息检索中目前被广泛使用的评价标准来评估推荐的精确度: AP (Average Precision)和MAP(Mean Average Precision)[ 15]。其中AP评价指标衡量的是单个查询的效果, 用来评价返回结果中相关文档数目及其位置(Rank); MAP评价指标衡量的是多个查询的效果, 一般是对所有查询的AP求宏平均, 反映系统在全部相关文档上性能的单值指标。系统检索出来的相关文档越靠前(Rank 越高), AP和MAP就可能越高, 如果系统没有返回相关文档, 则准确率默认为0。此处的文档对应在图书推荐系统中指图书, 本文将两本图书相关定义为它们被标注的相同标签数量大于等于3个。
将系统中图书按权重值降序排列, 本次评价选择前20个Topic(图书)作为查询集合, 分别在本系统和“豆瓣图书”系统中进行检索, 对推荐结果中的Top 10本图书进行评价, 分析这10本图书中与查询图书相关的图书数量和Rank, 分别计算AP和MAP取值, 进而比较本系统和豆瓣图书推荐在不同Topic下的推荐系统效果。
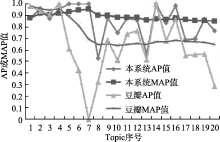
 | 图6 本系统和豆瓣的AP或MAP曲线 |
如图6所示, 横轴为按图书权重降序排列的Topic序号, 纵轴为其对应的AP或MAP取值。通过比较, 随着Topic的增多, 本系统的AP和MAP值大多数要比豆瓣推荐的高, 且MAP值变化幅度不大, 其中对于书名为“小王子”的图书, 豆瓣没有推荐任何内容, 所以其AP值为0。实验结果说明在这20个Topic的图书推荐上, 从语义匹配角度看本系统的推荐效果要好, 推荐的图书和查询图书相似性更高。
本文设计了一个基于分众分类法的原型图书推荐系统, 实验结果表明该系统具有良好的推荐效果。通过对本文的图书推荐系统的研究讨论可以发现, 系统用户生成的标注信息在揭示资源信息内容以及关联上显示出突出的能力。本文研究对改善高校OPAC系统应用分众分类法的效果提供了借鉴作用, 高校OPAC系统可以通过添加新功能与加强宣传等措施来吸引用户更多地参与图书标注, 利用用户标注的数据分析用户的兴趣点, 从而进行信息推荐, 为用户提供更多的个性化推荐服务, 提高系统的服务质量。基于用户标注数据实现用户个性化推荐是未来研究的方向。
同时笔者也注意到, 标签中含有的丰富语义如标签同现现象、同义词关系、上下术语、相关关系等还需进一步挖掘, 因此标签语义关系的挖掘、利用传统分类法和主题词表规范用户标签、弥补Folksonomy推荐系统的不足等, 是笔者今后的工作重点。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| 12 |
|
| [13] |
|
| [14] |
|
| [15] |
|