
{kind=link}
{kind=link}
{kind=link}
多源专家特征信息融合研究*
[李纲, 叶光辉 ]
]
]
|
|


【目的】为全面获取专家资源, 探究多源专家特征信息融合方法。【方法】从传感器工作过程出发, 依次论述基于知识传感器、Web传感器和社会网络传感器的专家特征识别方法。鉴于三种方法获取的专家特征向量存在冲突, 围绕资源均衡度设计基于多源信息融合的专家特征识别方法。【结果】与C-DBLP统计专家特征进行匹配, 相似度达到38.97%, 与同类型方法比较, 结果在正常范围内。【局限】 识别对象多来自高校及科研院所, 用于特征识别的资源也多为学术资源, 同时Web传感器采集网址集合还有待扩展。【结论】 在语词关系控制情形下, 该方法可用于科研团队构建、专家推荐、专家检索等方面。
结果准确率
[Objective] In order to fully get expert resources, the authors have carried out the information fusion research based on multiple-sensor expert features.[Methods] Firstly, in the view of working process of sensor, this paper brings out three methods based on knowledge sensor, Web sensor and social network sensor in sequence. Secondly, focusing on resource balancing degree, it designs the method of expert feature recognition based on multiple-sensor information to solve the conflict which three obtained eigenvectors give rise to.[Results] Matching the expert feature from C-DBLP, the degree of similarity is close to thirty-nine percent, which can be accepted among similar methods.[Limitations] On one hand, many experts identified are from universities and institutes, correspondingly, academic resources for feature recognition are of great account. On the other hand, the site collection for Web sensor can be extended further.[Conclusions] Under the circumstance of controlled relationship between keywords, this method can be applied to many aspects, such as the construction of expert teams, the recommendation and retrieval of experts, and so on.
知识经济时代, 专家在社会实践中发挥着重要的作用。专业知识体系构成了领域内的知识共同体——专家团队, 但共同体中的节点总体上并不一定具有明晰的架构。这一方面说明研究正趋于集群化, 另一方面也表明专家知识具有模糊性和不精确性, 其特征识别研究有待进一步深入[ 1]。
专家特征识别就是要从相关资源中提取出足以表征专家特征的主题词, 这些主题词不一定规范, 但一定要准确全面地揭示专家特征。最早专家通过实物型文献和人际网络来传播自己观点, 如今, 新兴计算机及网络技术正改变着他们与周围沟通的方式。从目前对互联网创新最具启发意义的几种技术出发, 笔者认为专家特征识别可基于三种智能来设计①(①引自微软亚洲研究院首席研究员周明博士2012年在华中师范大学所做的报告: 《Use Knowledge Intelligence, Web Intelligence and Social Intelligence for Internet Innovations》。): 第一种是知识智能, 学术数据库存储了大量的知识资源, 它们反映了专家的研究领域; 第二种是Web智能, 通过专
家所属机构网址、百度百科、Wikipedia等, 可获取专家简介, 进而借助文本分析等方法获取专家特征; 第三种是社会网络智能, 通过科研群体的社会网络平台, 如微博(如Twitter)、学术论坛(如小木虫)、技术社区(如CSDN)、学术博客等, 可获取用户标签, 标签反映了专家在公众中的印象, 也反映了专家的关注点和兴趣点[ 1]。基于这三种智能提取的专家特征将在专家名录设计、专家推荐、专家检索、科研团队建设等方面发挥作用[ 3, 4]。
不仅如此, 网络环境下, 专家内涵也在发生着变化。“专家”已不再仅仅局限于传统意义上的学术专家、技术专家, 网络使得每一个人都可能成为领域内的专家。如QA系统(百度知道、Yahoo! Answers等)中的多数用户在现实生活中可能只是普通人, 但在QA网络中却可能是中心性极高的答疑专家。网络环境下专家的内涵更广, 其特征识别所关联到的信息资源也更多更复杂, 本文将集中围绕此来展开相关研究工作。
基于知识智能、Web智能和社会网络智能的专家特征识别方法形成了网络环境下专家特征识别的方法体系。同一专家可被多种方法揭示其特征, 但当揭示结果间存在一定差异时, 就需要探究合理的多源信息融合方法。
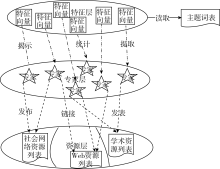
专家特征识别方法体系旨在建立一个层级鲜明、覆盖面宽、联络密切的“抽象过程”, 它包括三个层级和两组联系, 如图1所示:
 | 图1 专家特征识别“抽象过程” |
上层是特征层, 特征词的选取需参考词量大且语义关系丰富的主题词表, 如SKOS描述的叙词表或OWL表述的本体。下层是资源层, 资源类型包括学术资源、Web资源和社会网络资源, 资源载体形式涵盖学术数据库、社会网络、电子公告板等。中层是专家层, 关联特征层和资源层, 每一个专家所关联的特征词构成专家特征向量, 每一个专家所关联的资源构成专家资源列表。两组联系则是指特征层与专家层元素间存在着揭示、统计、提取等关系, 资源层与专家层元素间存在着发表、链接、发布等关系。
围绕图1, 相关专家学者已做了部分研究工作, 集中表现为:
(1) 基于知识资源的识别方法: 夏立新等[ 5]借助XTM绘制图书馆专家知识地图来改善专家自动化识别效果, Fang等[ 6]构建专家搜索引擎FacFinder来自动化甄选科研团队成员。
(2) 基于Web资源的识别方法: 巩军等[ 3]以维基百科为背景知识构建专家个人知识地图, 度量专家的知识构成和研究兴趣。
(3) 基于社会网络资源的识别方法: 廖开际等[ 7]借助语义网络对专家知识发现及表示方法进行了研究, 有效地解决了专家识别过程中特征揭示简单、推荐结果不准等问题。Lin等[ 8]将文本分析和社会网络分析相结合, 构建专家搜索软件SmallBlue来辅助企业进行专家特征识别。
(4) 综合多种资源的识别方法: 陆伟等[ 9]、王曰芬等[ 10]通过网络数据库、搜索引擎、专家推荐表等渠道获取专家个人及关系信息, 分别完成了专家组织工作和系统构建。Moreira等[ 11]使用D-S理论和熵计算从专家作品、引文网络、专家简介获取专家信息, Liu等[ 12]整合专家个人信息、专家声望和用户问答链接, 分别为在线学术社区和QA网站设计了专家排名综合算法, 并实证各自方法相较单一基准方法更全面准确。
综上可知, 多源专家特征信息融合是该主题领域当前研究热点, 但融合方法不一而足, 大多基于某一平台展开, 可移植性不强, 不仅如此, 多源信息权重分配算法还有待拓展, 既要减少人为的经验估计, 又要避免客观但过分复杂的算法。
(1) 结合2.1节, 笔者采取三种专家特征识别方法, 为了形象表述识别过程, 将这些方法物化为具体的“传感器”: 知识传感器、Web传感器和社会网络传感器, 如图2所示。每一类传感器都设定了需要捕捉的事件, 多个事件构成事件列表。
 | 图2 专家特征识别方法体系构建思路 |
(2) 通过传感器获取相关资源后, 需要系统评估资源库中不同资源的分布比例, 其值用“资源均衡度”来度量, 它反映了专家与外界沟通的方式和专家所属的类型。
(3) 三类传感器揭示出的专家特征可能会存在较大噪声信息和冲突信息, 为此需要根据资源均衡度来寻求解决方法。
(4) 通过实验法或专家法来对比测试(3)中解决方法相比以往单一基准方法的识别效果。
知识传感器适用于识别高校、科研院所的专家, 资源类型多为期刊、专著、专利等学术资源。学术资源经历了由实物型到数字型的发展过程, 知识传感器要利用学术数据库中的数字资源来进行专家特征识别, 所提取的事件如表1所示:
| 表1 知识传感器事件 |
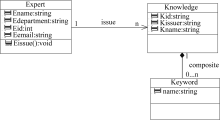
由表1可推知, 专家和学术资源具有一对多的发布(Issue)关系, 关键词是组成(Composite)学术资源的一部分(对不存在关键词的部分学术文献可通过对其摘要或标题做词频统计来生成), 笔者采用类图描述了三个实体的属性及关系, 如图3所示。
专家和学术资源存在外部特征维度和内容维度。专家的外部特征维度采用四元组
 | 图3 专家-学术资源关联结构 |
在此, 笔者使用内容维度来完成专家特征向量的设计。作为弱实体, 关键词有效地连接了设计过程。图3中, 实体间多重性经过两次传递, 可推知专家特征向量vc等于其发布的n个学术资源中关键词向量vc的叠加, 如公式(1)所示, 这样做考虑到了科研的时间跨度和成员研究方向演化等因素。
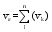 | (1) |
Web传感器特征表现为: 资源多来源于专家所属机构、百度百科、维基百科等简介页面。目前多用检索模型来处置专家识别过程[ 13], TREC 2005 和TREC 2006甚至为相关研究者提供了一个通用的平台, 用于实证专家识别算法和技术, 但目前可供测试的数据集只有1 092个(TREC 2005), 后来Fang等[ 6]构建的FacFinder数据量可达到12 000条, 目前还在扩张中。专家特征(如名称、研究方向等)以关键词包括在非结构化或半结构化的文本中, 需要采用文本分析方法获取属性数据, 所需提取的事件如表2所示:
| 表2 Web传感器事件 |
表2指出基于Web文本的专家特征识别常用的方法: 基于模板的信息识别方法、基于规则的信息识别方法和基于统计的信息识别方法。前两种方法都需要事先定义模板或规则, 如在专家简介中常常都会出现“XX的研究领域是...”、“XX的研究兴趣...”等句式, 这些为规则或者模板的设计提供了可能。基于统计的信息识别方法不需要事先定义规则或模板, 但需要统计词频和逆文档频率。前两种方法多涉及自然语言处理, 设计难度相对较高, 但生成的专家特征向量准确性较高。第三种方式多涉及分词和统计, 设计难度较低, 在实际中应用得更广也更成熟。
社会网络传感器特征表现为: 连通的社会网络使得任何一个节点都可作为候选专家, 这样就获得了更大的数据量, 如SmallBlue目前拥有400 000的测试集[ 8], 尽管它面向公司专家识别, FacFinder面向科研机构专家识别, 但也从侧面反映了社会网络传感器更易捕获数据。社会网络多表现为标签网络、引用网络等, 这些网络是属性数据和关系数据的集合。社会网络传感器可用在科研交流平台上提取专家特征, 所提取的事件如表3所示:
| 表3 社会网络传感器事件 |
由表3可知, 社会网络传感器需要提取两方面专家信息: 专家属性信息和专家关系信息, 专家属性识别揭示专家自身特征, 关系属性识别包括关系类型识别、标签识别和关系强度识别。关系类型识别和标签识别具有一一对应的关系。专家在社交网络平台上对音频、视频、文本、网页等资源进行自定义标签标注, 就建立了专家-资源关系网络。同理, 专家对自身社会网络账号所做的自定义标注, 就建立了专家-实体关系网络, 在此实体就是专家在社会网络中虚拟符号[ 2]。专家间的关系可通过专家-资源矩阵与其转置相乘获取, 专家间的同质化程度使用关系强度指标来度量。鉴于标签与关键词具有同样的表述功能, 仿照知识传感器中特征向量的生成方式, 对与专家相关联资源的标签进行频次统计, 最终获取社会网络传感器中的特征向量。
利用3.1-3.3节中的方法得到的同一专家的特征向量可能存在噪声或冲突, 主要表现为: 不同方法得到的专家特征向量可能存在特征词间联系不紧密, 甚至相悖的情形。综合三种方法得到的专家特征向量, 又无法确定每一种专家特征向量应该赋予的权重大小。每一种专家特征向量都存在噪声, 简单叠加无疑会加大噪声。综上所述, 笔者设计了解决机制——多传感器信息融合。
(1) 资源均衡度
资源均衡度旨在说明三种传感器获取资源的分布情况, 因为资源类型可能不一致, 为了便于比较, 统一按可用于揭示专家特征的资源单位数来统计, 其中知识传感器统计通过识别获取的关键词向量(与文献单元相对应)数目, Web传感器统计基于模板、规则和统计方式获取的关键词向量(与文本单元对应)数目, 社会网络传感器统计专家-资源和专家-实体关系类型的组例数目, 这些组例数目代表着标签向量的个数。设r1、r2、r3分别表示知识传感器、Web传感器、社会网络传感器获取的资源量, p1=r1/(r1+r2+r3)表示知识传感器获取资源占总资源的比例, p2和p3类同, 则资源均衡度σ的计算如公式(2)所示[ 14]:
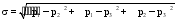 | (2) |
可知, σ越小表示与专家特征识别相关联的资源分布越均衡, 表明专家同时采用多种方式传播自己观点和见解, 多传感器信息融合更倾向于通过权重设置来设计解决机制。当p1=p2=p3时, σ为0, 此时资源分布完全均衡。反之, σ越大则资源分布越不均衡, 表明专家知识传播的出口相对单一, 各特征向量可信度存在较大差异, 多传感器信息融合更倾向于通过优先级设置来解决各特征向量间的噪声或冲突。
(2) 解决算法
由公式(2)可知σ值域为[0, 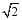
Input: v1, v2, v3, p1, p2, p3, σ, σt
Output: v
Process: Read v1, v2, v3, σ
If σ∈[0,σt] Then v=p1*v1+ p2*v2+ p3*v3
Else if σ∈(σt, 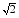
Else if σ∈(σt, 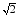
Else v=v3
End if
为解决专家特征向量v1、v2、v3间的噪声或冲突, 笔者采用分段函数来生成综合专家特征向量v。由3.4节可知, σ决定了综合专家特征向量生成中各基准向量的权重分配。当 σ在[0,σt]区间内, 笔者通过权重设置法来生成综合专家特征向量, 其大致过程可描述为: 专家使用p1、p2、p3作为三个传感器生成的专家特征向量的权重, 综合专家特征向量v等于对应权重与向量乘积之和(向量的几何平均值)。当σ等于0时, 则v等于三个向量的算数平均值。当 σ在(σt, 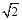
综合两种设置方法可知, 3.4节综合方法融合了3.1-3.3节中的单一基准方法, 是一种更加灵活的方法。另外, σt是形参, 其值可根据用户反馈在一定范围内自主定义, 从而实现“以我为主”的专家特征提取, 改变其被动接受结果的局面, 为个性化专家识别与定位提供可能性。
综合过往方法[ 9, 11]可知, 多传感器信息融合效果评测以实验法为主, 专家法为辅, 籍此本文展开实证分析。
(1) 识别对象: 以CNKI为学术知识库, 以计算机类11种IF排名靠前的期刊作为知识资源源刊, 依据检索结果, 从发文量排名前20的计算机专家中随机选取10位。
(2) 对照组: 以C-DBLP提供的专家研究兴趣(http://www.cdblp.cn)为对照组。C-DBLP是中国人民大学网络与移动数据管理实验室开发的学术展示平台, 揭示的专家特征具有一定可信度, 但在计算机领域其收录期刊仅有5种(《软件学报》、《计算机学报》、《计算机研究与发展》、《中国图象图形学报》和《中文信息学报》)与本文所用刊源一致。
(1) 利用知识传感器获取专家特征向量v1, 资源量为r1。
(2) 利用社会网络传感器获取专家特征向量v2, 资源量为r2。在此, 社会网络节点为步骤(1)中“知识资源”, 关系为“引用”, 知识资源被引用次数越多表明文章影响力越高。为了简化运算, 本文只分析专家高被引论文的引文, 且刊源为4.1节中的11种期刊。类比齐夫第二定律, 高被引论文和低被引论文界限区分采用公式(3):
 | (3) |
其中, ri表示知识传感器获取资源量, r'i表示将ri开方再四舍五入后得到的高被引论文数量, 由此知r2为引用高被引论文的期刊论文数量。
(3) 利用Web传感器获取专家特征向量v3, 资源量为r3。鉴于关联到的Web信息数量大、质量参差不齐, 且部分信息来源于学术知识库, 因此限定在4类可信度较高网址中进行专家Web信息搜集, 依次是专家所属机构网址、科学网(
| 表4 Web资源统计分析结果 |
(4) 设σt=1.0, 遵照多传感器信息融合算法, 生成综合专家特征向量v, 如表5所示。
| 表5 多源专家特征信息融合结果 |
将多源信息融合得到的专家特征同C-DBLP统计的专家兴趣进行相似性比较, 方法是将C-DBLP专家特征与表5中对应专家特征通过ICTCLAS软件进行无标注分词处理后, 再用ROST软件统计词频, 最后使用向量余弦公式计算相似度, 这种方法相比专家法更加客观。对照分析结果如表6所示:
| 表6 对照分析结果 |
由表6知, 分词后, 在无词间关系控制的情形下, 相似度为0.2766。当人工对语词同义及等级关系进行控制, 如合并“计算机动画”与“卡通”、Petri与Petri网等, 相似度提升为0.3897。同理, 如果引入外部词表系统, 加入语词相关关系控制, 则相似度可能会进一步提升。鉴于二者在刊源上存在一定的差别, 且与其他多源信息融合方法(如MSDFS[ 11])对比可知, 上述结果在可接受范围内。但通过表6数据, 笔者也发现不同专家相似度差别较大, 因此在假定C-DBLP结果准确的前提下, 还需要对多源信息融合方法做出改进, 如增加专家特征词数量、加入词表来规范关键词选择等。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|