

{kind=link}
{kind=link}
{kind=link}
面向用户任务的查询推荐研究*
引用本文
张晓娟, 唐祥彬. 面向用户任务的查询推荐研究* . 现代图书情报技术, 2014, 30(4): 34-41
Zhang Xiaojuan, Tang Xiangbin. Query Recommendation Based on User Task. New technology of library and information service, 2014, 30(4): 34-41
Permissions
Zhang Xiaojuan, Tang Xiangbin. Query Recommendation Based on User Task. New technology of library and information service, 2014, 30(4): 34-41
Copyright©2014, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
面向用户任务的查询推荐研究*
作者贡献声明:
张晓娟: 研究命题的提出﹑实验设计以及论文撰写;
唐祥彬: 数据处理与分析。
摘要
【目的】基于AOL查询日志数据集, 从Session级别实现面向用户任务的查询推荐。【方法】从用户任务级别衡量查询间关系, 再通过随机游走遍历图的思想为查询构建向量, 以此实现候选查询推荐。【结果】本文方法的推荐效果优于基于查询共现来衡量查询间关系的推荐效果。【局限】 未对拼写错误的候选查询进行拼写纠错; 未从查询级别来实现面向用户任务的查询推荐; 稀有查询和模糊性查询的推荐效果不佳。【结论】基于用户任务来衡量查询之间相关关系, 能提高查询推荐的实验效果。
关键词:
查询推荐; 用户任务; 查询日志
中图分类号:G353.4
文章编号:2014-4-34-41
Query Recommendation Based on User Task
Abstract
[Objective] This paper tries to realize user task-oriented query suggestion from session level based on AOL query log dataset.[Methods] This paper firstly measures the relationship between queries based on user task, and then realizes user task-oriented query recommendation by exploiting random walk to traversal graph model.[Results] The final results show that our query recommendation method outperforms that method which measures relationship between queries by exploiting queries occurrence information.[Limitations] Misspelled candidate queries are not implemented spell correction; Query recommendation are not realized from query level; The recommendation effect of rare queries and ambiguous queries are not good.[Conclusions] Measuring the relationship between queries based on user task can improve the performance of query recommendation.
Keyword:
Query recommendation; User task; Query log
1 引言
伴随着网络资源的不断增长, 用户的检索兴趣已从与查询相关的文档过渡到与用户信息需求相关的文档。而在大多数情况下, 用户所提交的有限关键词常常不能正确地表达其信息需求, 很难构造成功的查询, 对搜索引擎来说, 理解用户信息需求是一项比较困难的任务。鉴于此, 搜索引擎服务提供商如Google等努力尝试采用多种方法去探测用户的信息需求, 并将生成查询推荐作为其重要的环节。 其中, 基于查询日志方法是当前查询推荐的主流方法, 其主要思想为, 从Session级别或者查询级别分析候选查询与原查询的相关关系, 利用相应推荐方法生成查询推荐, 则查询间相关关系的计算方法在很大程度上影响着最终的查询推荐效果。当前相关研究大多基于查询共现信息来衡量查询之间关系, 使得最终的推荐结果是与原查询相关而并非是与用户信息需求相关的查询, 如某用户输入查询“苹果手机”想获得苹果品牌的相关电子产品, 其候选查询推荐“苹果沙拉”, 偏离了用户初始的信息需求。
用户提交查询的主要目的是为了完成特定搜索任 务, 用户任务是其从事搜索行为并且判断查询结果相关性的重要因素, 是用户信息需求的原子, 理解用户任务是理解用户信息需求的主要途径。本文拟从基于用户任务级别衡量查询之间相关关系, 从而实现面向用户任务的查询推荐。
2 相关研究综述
查询推荐的主流方法是基于日志方法, 该方法可分为以下两类子方法: 直接的查询共现挖掘与查询构图方法。其中, 基于查询共现挖掘的主要思想为, 若某查询与原查询共现于同一Session的概率越大, 该查询是原查询的候选查询推荐的概率越大。相关研究有: Huang等[
其中, 面向用户任务的查询研究主要体现在基于用户任务级别的查询日志切分研究中。早期的查询日志切分方法主要是基于时间间隔[
3 衡量查询间关系的模型
3.1 衡量查询间关系的一般方法
查询推荐方法的一般思路为: 通过相关模型来计算候选查询与原查询的关系权值, 在此基础上, 利用相关推荐方法生成候选查询推荐。衡量查询间相关关系的方法是查询推荐中的重要部分。计算原查询与候选查询关系权值的一般方法, 如下所示:
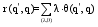 | (1) |
其中, r(q',q) 表示查询q'与原查询之间的关系值。θ(q',q)表示利用函数θ计算查询q'与原查询q之间的相关关系, λ表示函数θ的权值。 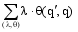
3.2 基于用户任务的查询间关系
利用查询共现信息来衡量查询间关系的研究大多基于如下假设: 同一Session中的查询描述相同的用户任务。而一些研究者发现同一Session的查询可能表达不同的用户任务: 如Lucchese等[
(1) 查询间时间距离
笔者假设, 对于查询q与q'来说, 若两查询之间时间距离越小(即在同一Session中, 两查询之间距离越近), 二者表达同一用户任务的可能性越大。设 S={q1, q2,q3...qt-1,q,qt+1...} 表示某一Session的查询集合, 该集合包含原查询q, 且该集合中查询按照提交时间先后进行排列, 其中, q1的提交时间早于q2的提交时间, q2的提交时间早于q3的提交时间。由以上假设可知, qt+1与qt-1表示与原查询q的相邻查询, 因此, 这两个查询包含的用户任务更可能与查询 q的用户任务相似。本文利用公式(2)中decay(i,j,S)计算在某Session S中原查询q与查询q'之间的距离权值。
decay(i,j,S)=β|j-i| (2)
其中, j表示查询q'在S中的排序, i表示查询q在S中的排序, β表示衰减系数[
公式(3)表示当q与q'共现于多个同一Session中时, 两查询间的时间距离权值T(q,q')为各Session中距离权值 decay(i,j,S)的平均值。T(q,q')值越大, 则两查询描述同一用户任务的可能性越大。
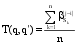 | (3) |
(2) 查询间表达式相似性
在大多数情况下, 用户常用表达式相似的查询来描述同一查询任务[
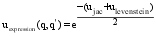 | (4) |
其中, ujac表示两查询之间的Di-gram Jaccard距离值, ulevenstein表示两查询之间编辑距离值[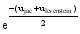
(3) 查询间语义相似性
考虑到表达式不同的两查询也可能包含同一用户任务, 本文也尝试利用查询间语义相似度来衡量查询间的用户任务相似度[

其中, W表示数据集中所包含的网页数目。ci表示词t在第i个网页中的权值, 其值是由tf-idf原理计算得出。
公式(5)表示查询q的向量为各个查询词(非停用词)向量之和。
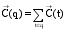 | (5) |
本文利用余弦值来计算两查询向量之间的相似度, 如下所示:
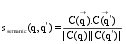 | (6) |
本文在计算r(q',q)(即查询q'是查询q的候选查询概率)时, 利用三个θ函数来衡量查询之间相关关系, 即综合考虑查询之间时间距离﹑查询间表达式相似性以及查询之间语义相似性三方面, 其计算方法分别参见公式(3)﹑公式(4)与公式(6), 这个三函数的权值分别为λ1﹑λ2与λ3, 且三者之和为1。
4 查询推荐方法
已有实验表明[
4.1 转移概率设定
首先构建图G=(V, E), 节点V由查询词及其所点击文档构成, E所包含的边集合有: 查询之间相关关系以及查询与文档之间的点击关系。本文将每个节点当作一个马尔科夫状态。查询之间转移概率, 如下所示:
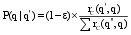 | (7) |
其中, P(q|q')表示查询与查询之间的转移概率, rC(q',q)表示查询q'与查询q的相关关系, 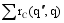
笔者在计算查询与文档之间转移概率时, 首先将URL加以区别对待, 即若一个URL被多个查询点击, 则该URL具有模糊性, 反之, 表明该URL具有专指性。查询转移到专指性URL的概率应大于模糊类URL。本文利用文献[19]提出的 iqf衡量URL对查询的区分度(与文档的idf思想相似), 公式如下所示:
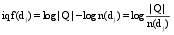 | (8) |
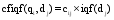 | (9) |
其中, n(dj)表示点击了文档dj的查询频次之和, |Q|表示查询日志中总查询数。 cfiqf表示点击频次与iqf的乘积, cij表示查询qi点击文档dj的次数。
则文献[19]中query-url之间的转移概率公式如下所示:
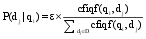 | (10) |
其中, 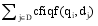
公式(11)表示文档状态是一个吸收状态(即自转移状态), 即转移到自身的概率为1, 而转移到查询状态的概率为0。根据马尔科夫吸收链的性质: 当状态转移到文档状态后, 则会一直停留在此状态; 从每一个非吸收状态出发, 有限次转移后能以正的概率到达某个吸收状态。
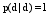 | (11) |
4.2 查询向量构建
基于如下假设: 用户所点击文档能描述用户的信息需求, 则点击同一文档的两查询可能具有相似用户任务[
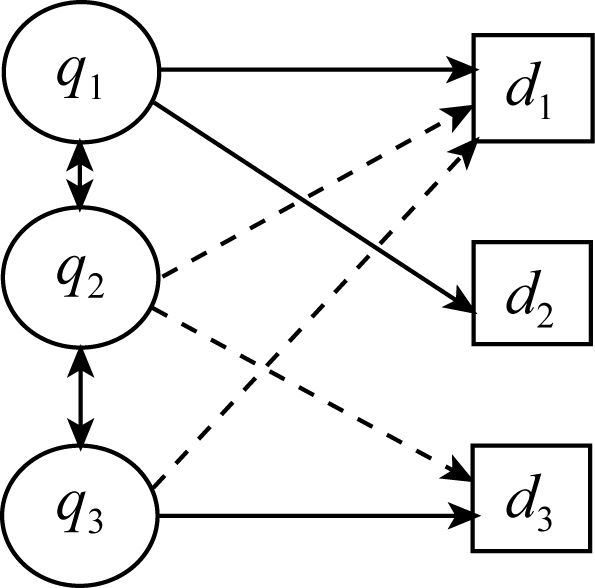 | 图1 经随机游走后的查询与文档间关系 |
5 实验及其结果评测
5.1 实验数据集
本文采用AOL[
 | 图2 AOL数据集格式 |
5.2 实验结果及其分析
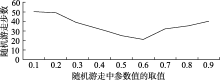
本文随机抽取200个不同查询作为原查询。考虑到某些参数会影响到实验的最终效果, 参数调节是本文的重要部分。图3表示公式(7)中随机游走参数ε取不同值时, 所构建图模型中90%的查询节点达到吸收状态时所需要的随机游走步数。可知, 当ε取值为0.6时, 所需的随机游走步数最少, 则ε的最优值为0.6。
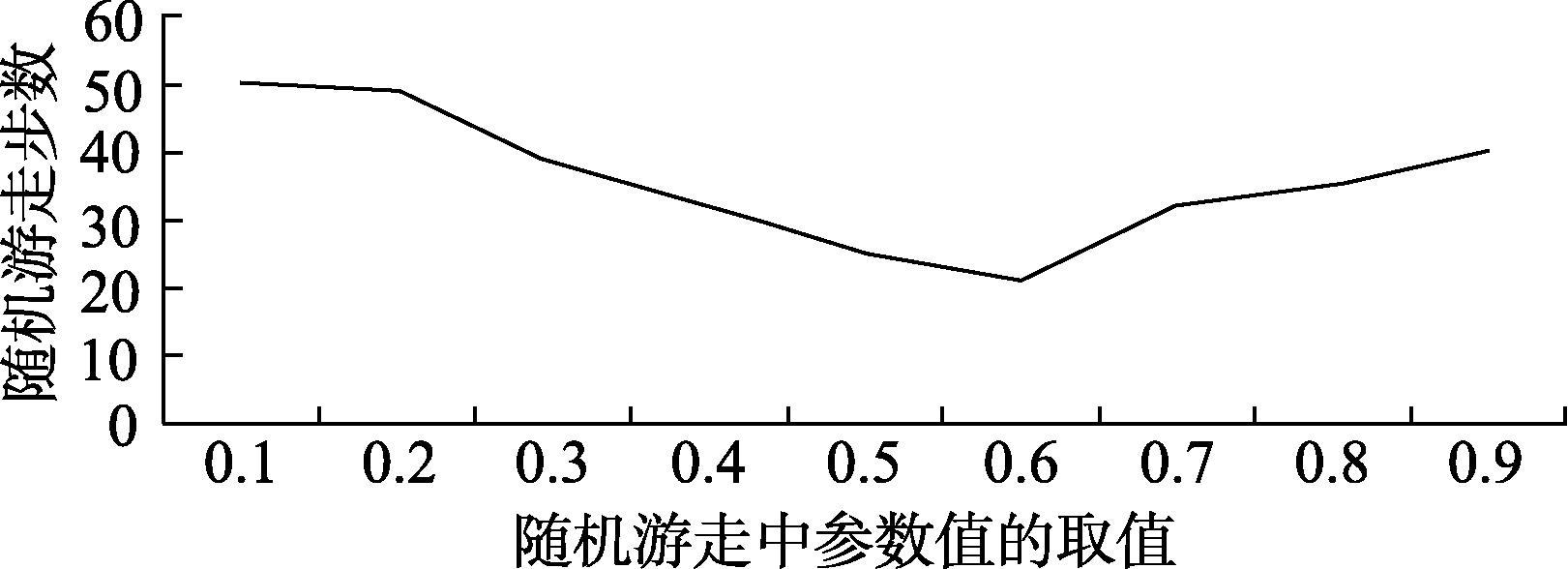 | 图3 随机游走参数ε取值与随机游走步数之间关系 |
在此基础上, 本文进行了4组不同的实验:
(1) 利用共现互信息计算公式(1)中θ(q',q)值, 并利用文献[6]中构图方法(图模型中只包含查询节点, 即只考虑查询间关系)来实现查询推荐(标记为“Baseline1”);]]>
(2) 利用共现互信息计算公式(1)中θ(q',q)值, 并利用本文构图方法来实现查询推荐(标记为“Baseline2”);
(3) 基于用户级别计算公式(1)中θ(q',q)值, 并利用文献[6]中构图方法实现查询推荐 (标记为“Baseline 3”);
(4) 基于用户任务级别计算公式(1)中θ(q',q)值, 并利用本文中构图方法来实现查询推荐(标记为“Our Work ”)。
据笔者所知, 目前尚未有公认的查询推荐公共评测语料, 人工评测是当前主要方法。本文选取三位专家对实验结果进行评测, 对于每个原查询, 三位专家分别判断每个结果的相关度, 本文中相关度的标注是基于二值判断即“相关”与“不相关”两类。另外利用Cohen kappa(κ)[
另考虑到“Our Work”与“Baseline3”两实验从用户任务级别计算查询间相似性时, 三函数(分别参见公式(3)﹑公式(4)与公式(6))权值λ1﹑λ2与λ3的不同取值会影响到的最终效果。在这两组实验中, 本文将200个原查询平均分为两份, 其中一份的100个原查询作为训练集, 获得三参数的最优解; 而将另外一部分的100个原查询作为测试集, 即在训练集中获得最优参数解的基础上, 获得实验的最终实验效果。其中, “Baseline3”最终实验结果的P@3﹑P@5﹑P@10与Recip_Rank值分别为0.47﹑0.54﹑0.67与0.68; “Our Work”最终实验结果的 P@3﹑P@5﹑P@10与Recip_Rank值分别为0.50、0.60、0.72与0.73。
| 表1 实验结果评测表 |
表1是4组实验的评测结果。从评测指标值可知, “Baseline 3”方法优于“Baseline 1”方法, “Our Work”方法优于“Baseline2”方法, 从这两组对比数据可以说明, 基于用户任务级别衡量查询之间相关关系可进一步提高查询推荐的效果。另也可知, “Baseline 2”方法优于“Baseline1”方法, “Our Work”方法优于“Baseline 3”方法, 从这两组对比数据中可知, 本文构图方法优于文献[6]中构图方法(图模型中只包含查询节点, 即只考虑查询间关系), 即在构建图模型时, 考虑查询与文档之间点击关系可进一步提高查询推荐的最终效果。
另考虑到查询的不同属性会影响到最终的查询推荐效果。表2表示将查询按照稀有性和模糊性进行分类后, 利用本文推荐方法后的各类别查询的评测结果。其中, 查询稀有性判断方法参见文献[23],查询的模糊性判断方法参见文献[24]。
| 表1 不同属性查询的实验评测结果 |
可知, 非稀有查询的实验效果优于稀有查询的实验效果, 非模糊性查询的实验效果优于模糊性查询的实验效果, 其主要原因在于: 因用户提交稀有查询的频次较少, 此类查询中所包含的Session信息较少, 相对非稀有查询来说, 此类查询较难从Session中推荐与之相关的候选查询; 又因用户提交模糊性查询时, 自身对该查询的意图不明确, 常常构造与之无关的查询, 相对非模糊性查询来说, 同一Session中包含更多噪声查询, 其最终查询推荐的效果较低。所以, 如何提高稀有查询和模糊查询的推荐效果是后续一项重要研究工作。
6 结语
查询推荐是用户与搜索引擎交互的途径之一, 是当前信息检索领域一研究热点。本文从Session级别, 在基于用户任务衡量查询间关系的基础上, 通过构建图模型来实现候选查询的推荐。实验结果表明, 本文的查询推荐效果优于基于查询共现衡量查询间关系的查询推荐方法。尽管如此, 本文仍存在一些不足之处, 在未来工作中还需从以下几个方面加以深入研究: 进一步采用聚类方法来衡量查询之间相似性; 在查询处理过程中, 进一步考虑查询的拼写纠错等; 如何在不借用查询日志的情况下, 基于其他推荐方法来实现面向用户任务的查询推荐; 探讨如何选取更合适的指标来对面向用户任务查询推荐进行有效评测; 为稀有查询和模糊性查询提供更有效的面向用户任务的推荐方法; 基于查询级别, 实现面向用户任务的查询推荐。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|