{kind=link}
{kind=link}
利用术语定义的汉语同义词发现* , , 张运良
[殷希红 , 乔晓东, 张运良]
, 乔晓东, 张运良]
, 乔晓东, 张运良]
|
|


作者贡献声明:
乔晓东, 张运良: 提出研究思路, 设计研究方案;
殷希红: 进行实验;
殷希红, 张运良: 采集、清洗和分析数据;
殷希红: 论文起草;
张运良, 殷希红: 最终版本修订。
【目的】借鉴Lesk词义消歧思想, 提出并实现一种利用术语定义来发现汉语同义词的方法。【方法】将新能源汽车领域汉语科技词系统中的术语及其定义作为测试集, 首先对术语定义做分词和词性标注, 并进行人工校对, 然后抽取出动词和名词词性的实词, 再根据两个术语定义中相同的实词数量及位置信息计算术语的相似度, 最后根据相似度和给定的阈值得到同义词关系的推荐。【结果】利用准确率、召回率、F值对同义词发现效果进行评价, 论证该方法的有效性, 结果表明该方法可以达到较高的准确率, 但是召回率比较低。【局限】该同义词发现方法不能剔除反义关系和相关关系的术语对, 造成召回率较低。【结论】该方法较为简便快捷有效, 并且可达到较高准确率, 但召回率有待提高。
[Objective] Enlightened by Lesk’s research about sense disambiguation, an approach based on the term definition to find synonyms is proposed.[Methods] This experiment set up the test set on the Chinese scientific and technical vocabulary system(new energy vehicles). First the Chinese word segmentation, part-of-speech tagging and manual correction of term definition are given. Then verbs and nouns content words are extracted, and the similarity of two terms is calculated according to the number of terms defined in the same content words and the position of the same content words. At last, according to the similarity and given threshold, the synonym relations are recommended.[Results] The precision, recall, F value is used to evaluate the effect of synonyms found, to demonstrate the effectiveness of this method. The result shows that the method can achieve a high precision, but the recall is low.[Limitations] This method can not exclude terms with antisense relationships or related relationships, resulting in lower recall rate.[Conclusions] This method is simple and more effective, and can achieve a high accuracy, while higher recall rate is expected.
在大数据时代, 用户要从海量的数据中查询到需要的信息变得更为困难, 用户对信息检索的要求越来越高, 也就是对查准率与查全率提出更高的要求, 为了达到用户需要, 可以建立一个较为完备的同义词表, 将能够相互替换、表达相同或者相似概念的同义词均关联起来, 进行扩展检索提高查全率, 而同时可以通过聚类等手段提高查准率。因此同义词抽取在信息检索领域有着重要的研究意义和应用价值。另外同义词是分类表、主题表、语义网络、本体等一些知识组织系统中必不可少的部分, 通过构建同义关系、对术语名称进行概念归并, 有利于提高知识组织工具的适用性和用户友好性, 实现不同知识组织工具之间的互操作, 对于词表映射、语义检索和百科知识服务等具体应用具有重要意义[ 1, 2]。因此同义词发现对于知识组织系统的构建至关重要。
在构建知识组织系统尤其是科技知识组织系统
时, 大部分都会对术语进行定义以助于用户理解, 并且核心词的定义是词系统加工的第一步。这些定义来源广泛, 其中包括专业百科全书、网络百科、国家标准、名词委员会、专业书籍及论文等。利用这些术语定义信息进行同义关系发现就成了一项水到渠成的工作, 无需增加太多额外工作, 无需额外资源。本文正是基于中国科学技术信息研究所已有的新能源汽车领域汉语科技词系统中的术语定义信息, 展开利用术语定义中出现的实词数量及实词位置信息进行同义关系发现的方法研究和实证分析, 探讨其技术上的可行性, 为下一步工作提供理论基础和例证。
汉语同义词发现的方法可以分为4种:
(1) 根据词汇本身获取同义关系, 其中包括基于词汇字面相似度算法、基于词素的语义相似度算法、基于《同义词词林》和《知网》等语义词典的语义相似度算法[ 3]。
(2) 根据词汇间关系及特征进行同义词识别, 钟伟金[ 4]根据同义关键词的“互斥互信”理论设计了相应的统计模型, 从复杂的词汇共现关系网中识别出同义关键词, 自动识别的准确率达到77.5%。谷歌公司的Grushetsky等[ 5]申请了基于文档的同义词抽取的专利, 主要是用共现的词来表示当前词语, 并以此作为相似度度量的计算素材。
(3) 基于模式匹配的方法识别同义词, 主要是通过研究文本的句法特征来设计模式匹配方法, 宋丹等[ 6]提出了术语同义词的自动抽取, 认为文献中多用同义词做术语诠释, 根据在做诠释时用到的“亦称”、“简称”、“也叫”等标志性的词语进行模式匹配, 从学术文献全文中抽取同义词对, 其准确率达到88.7%, 召回率为86.3%。 孙霞等[ 7]将同义关系抽取看成一个二值分类问题, 认为同时出现在一个句子中的两个领域词有可能具有某种语义关系, 如同义关系, 找出所有含有两个或两个以上领域词汇的句子, 将其中的领域词汇两两组对, 把所有可能的词对用分类器根据语义分成两类, 一类是具有同义关系的词对, 另一类是不具有同义关系的词对, 其准确率为93.3%, 召回率为87.3%。
(4) 基于术语翻译进行同义词识别。采用翻译词对作为双语对齐语料, 将术语同义词作为等价翻译的过程, 提出基于“翻译镜像” (Translation Mirror) 的同义词计算方法, 有助于提高同义词计算的效率, 展现出了较好的研究前景[ 8, 9, 10]。张运良等[ 11]利用双语语对中单词条的翻译数量、翻译共现强度等作为基本输入, 通过简单布尔判断、条件互信息或向量空间模型余弦相似度来计算术语之间的相似度, 进而发现并构建同义关系, 其中使用互信息方法的准确率最高为64.53%。
综上所述, 国内外对于同义词发现的研究已步入成熟阶段, 同义词抽取的方法研究多种多样, 并在同义词发现结果上均取得较高的准确率和召回率, 但是这些同义词抽取方法有的需要依赖一些语义资源, 而一些专业细分领域还没有类似WordNet和同义词词林这样好的资源可以利用; 有的需要依赖大规模的语料库, 计算量相对较大; 有的在抽词过程中依赖人工确定规则, 并区分正反样例, 耗时费力。总之, 以上方法在构建知识组织系统中均略显不足。
本文以知识组织系统中现有的术语定义信息作为切入点进行同义词发现算法研究, 基于定义的语义相似度计算方法可以分为两种:
(1) 利用词汇间的解释与被解释关系构建词汇关系网络图, 然后利用不同相似度方法进行计算[ 12, 13, 14]。这种方法需要构建词汇关系网络图, 而对于大型的网络图不易计算和分析, 因此这种方法不适用于大型的知识组织系统。
(2) 根据概念定义中出现的共同特征词数量来计算语义相似度, 该思想首先由Lesk[ 15]提出, 其研究主要应用于语义消除, 针对一词多义现象, 词语的每个意思都有一个定义与之相对应, 通过将目标词的每一个定义与出现该词的上下文中的词语定义进行比较, 统计定义中出现相同词的数量, 来计算词语间的相关度, 把最大的相关度值对应的意思作为该词语的意思。Lesk算法基于两个前提: 同时出现在一个句子中的词语被认为是相关词; 可以根据两个词语定义中含有相同词的数量来确定两个词的相似度。之后Banerjee等[ 16]对该方法进行扩展研究, 增加了被比较概念的范畴, 利用WordNet中概念间的关系, 将与被比较概念相关的概念的定义也囊括进来进行比较, 构建一个二阶共现向量, 计算概念间的语义关联度, 达到60%的准确率。该方法仅需要统计定义中出现的共同特征词数量, 简便易行, 能够快速发现知识组织系统中的同义关系, 而且对于知识组织系统的大小不受限制, 可实现快速构建知识组织系统。
因此, 本文将Lesk[ 15]的思想引入到汉语同义词研究上, 利用术语定义中的实词及实词位置信息进行汉语同义词发现。
基于术语定义的同义词发现是根据两个术语的定义的相似程度来判定两个词是否为同义词, 将术语间相似度的判断转化为术语定义之间相似度的判断。基本假设前提是: 如果两个术语是同义词, 那么它们的定义中必定还有很多相同的实词, 它们的相似度会接近1, 如果两个术语不是同义词, 那么它们定义中相同实词会相对较少, 相似度也会较小。
在算法设计上借鉴朱毅华[ 17]的基于词素的字面相似度算法, 假设定义术语term1的实词为集合A, 定义术语term2的实词为集合B, 而两个术语定义中含有相同实词为C, 则术语term1和术语term2的相似度如下所示:
sim
(1)
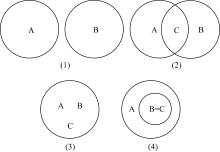
即术语term1和term2定义中相同的实词占两个术语定义所有实词的比例。根据两个术语定义中是否含有相同实词构建术语关系图, 其中术语关系可以分为以下4种情况, 如图1所示:
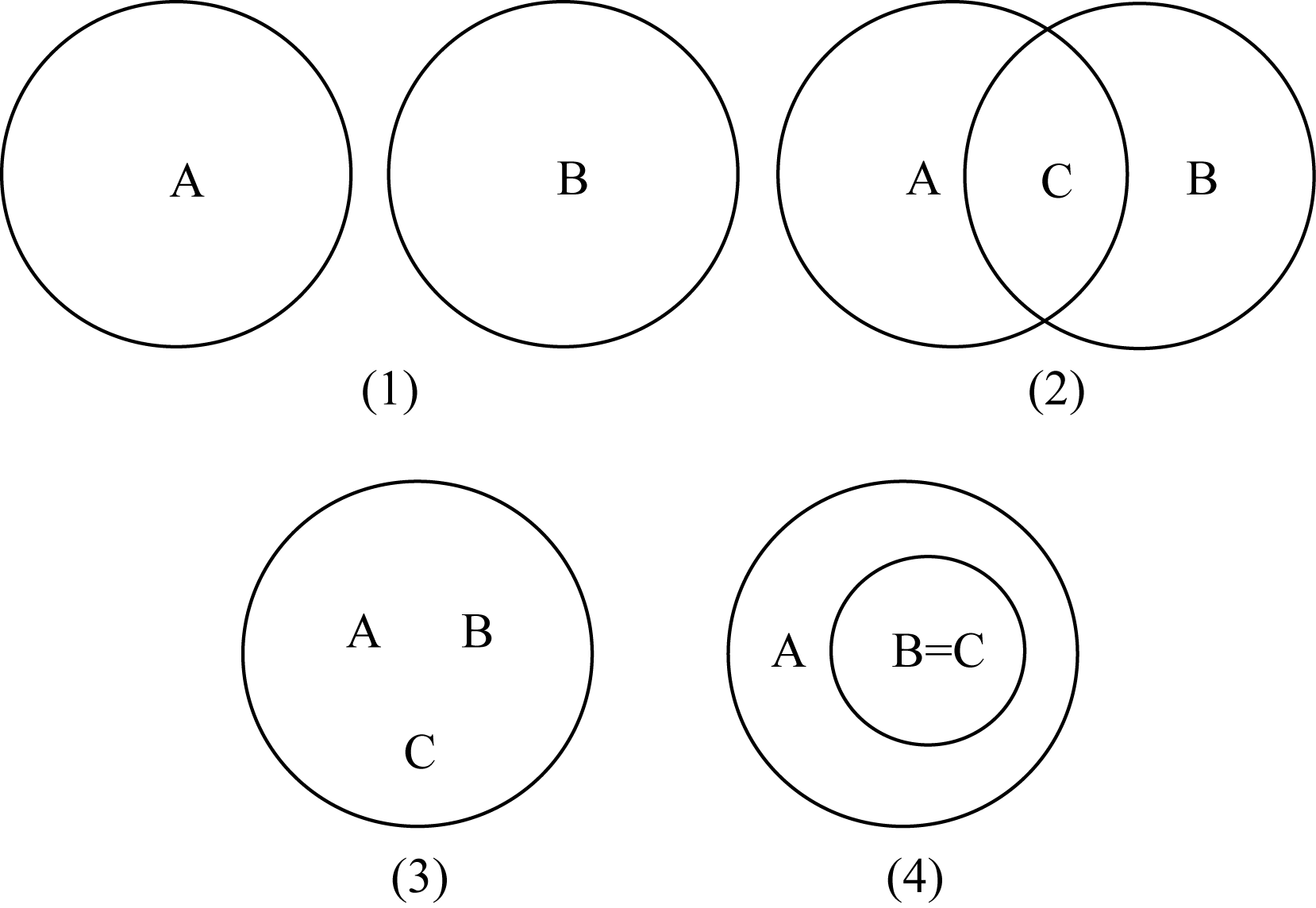 | 图1 术语关系图 |
第一种情况表示术语term1和term2定义中不包含相同实词, 其相似度为:
sim
第二种情况表示术语term1和term2定义中含有部分相同的实词, 其相似度为:
sim
第三种情况表示术语term1和term2定义中的实词完全相同, 其相似度为:
sim
第四种情况表示术语term2定义中的实词为术语term1定义中实词的一部分, 其相似度为:
sim
由此可以看出, sim
令m= 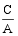
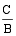
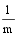
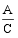
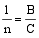
sim
= 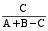
(2) 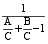
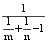
其中, m, n表示相同实词分别在术语term1和term2中占的比例, 这样只要知道m和n的值, 就能计算出两个术语的相似度, 计算m与n的值可以采用两种方法。
方法一: 根据术语term1和term2定义中相同实词的数量占两个术语定义总的实词数量的比例计算两个术语的相似度, 则:
m=
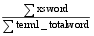 | (3) |
n=
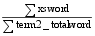 | (4) |
其中, xsword表示两术语定义中含有的相同实词的数量, term1_totalword表示定义术语term1的实词的总数, term2_totalword表示定义术语term2的实词的总数。
方法二: 考虑实词的位置信息, 根据术语定义的句法结构, 定义中实词出现在不同位置, 其重要程度不同, 经观察定义中出现在开始和结束位置的实词更能反映定义信息, 因此可以根据实词位置信息利用函数f(x)对实词赋予不同的权值, 公式如下所示:
f(x)=|cos( 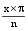
其中, x表示实词出现的位置, n为定义中实词出现的最大位置, f(x)为对应的x位置实词的权值。则m、n 的值对应公式(6)和公式(7):
m=
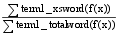 | (6) |
n=
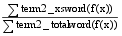 | (7) |
其中, xsword表示两术语定义中含有相同的实词, totalword表示术语定义中含有的所有实词, ∑term1_xsword(f(x))表示两术语定义含有的相同实词在术语term1中权值之和, ∑terml_totalword(f(x)) 表示术语term1定义中含有的所有实词权值之和, ∑term2_xsword(f(x)) 表示两术语定义含有的相同实词在术语term2中权值之和, ∑term2_totalword(f(x))表示术语term2定义中含有的所有实词权值之和。
(1) 根据sim值的大小作为区分度来进行同义词的筛选, 优先选择sim值较大的术语对作为候选同义词。
(2) 设定阈值, 首先预定一个初始值进行测试, 再根据测试结果调整初始值, 如此反复确定一个最佳的阈值, 使同义词发现效果保证较高的准确率和召回率。
(3) 对术语对进行字面相似度判断, 根据术语term1与term2是否互为子串判断两个术语是否为上下位关系, 若term1是term2的子串, 则term2为term1的下位词, 则将下位词term2剔除; 若term2是term1的子串, 则term2为term1的上位词, 同样将上位词term2剔除。
选取“新能源汽车领域”汉语科技词系统[ 18]中的术语及其定义作为测试集。该书收录中文核心词6 117条, 在此基础上, 经过增补, 截至2013年1月, 核心词数量为6 216条, 其中含有定义的不重复术语为5 331条, 因为一条术语可能包含两条以上的定义, 术语定义总共为5 888条。
首先, 对数据进行清洗, 主要包括删除一些定义的出处, 例如, 天然气气瓶: 安装在车辆上用于储存供给车辆自身使用的天然气或液化石油气、可反复充装的气瓶, 参考《GB/T17895-1999天然气汽车和液化石油气汽车词汇》。要将参考《GB/T17895-1999天然气汽车和液化石油气汽车词汇》删除, 同时还要删除一些特殊的字符和无用的字符。数据清洗后, 利用中国科学院自动化研究所Urheen词法分析系统对术语定义进行分词和词性标注, 词性标注采用宾州树库标准(见文后附表), 将术语定义转换为词汇串。术语定义分词后的结果如下:
(1) 干式汽缸套##汽缸/NN 套/VV 的/DEC 外表/NN 不/AD 直接/VA 与/P 冷水/NN 接触/VV
(2) 橡胶式曲轴扭转器##与/P 曲轴/NN 带轮/NN 结合/VV 在一起/AD 。/PU
(3) 气门锥角##气门/NN 头部/NN 与/CC 气门/NN 座圈/NN 接触/VV 的/DEC 工作面/NN , /PU 是/VC 与/P 杆部/NN 同心/VV 的/DEC 锥面/NN , /PU 通常/AD 将/BA 这/DT 一/CD 锥面/NN 与/CC 气门/NN 顶部/NN 平面/NN 的/DEG 夹角/NN 称为/VV 气门/NN 锥角/NN 。/PU
(4) 实心推杆##锥杆/NN 两/CD 端/NN 与/CC 杆身/NN 做成/VV 一体/NN , /PU 球头/NN 与/CC 杆身/NN 做成/VV 整体/NN 。/PU
(5) 空心推杆##两/CD 端/NN 与/CC 杆身/NN 用/P 焊接/VV 或/CC 液压/NN 的/DEC 方法/NN 连成/VV 一体/AD 且/AD 具有/VV 不同/VA 的/DEC 形状/NN 。/PU
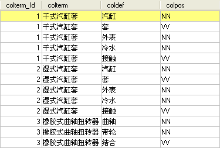
其中, “##”前面的是术语, “##”后面的是术语定义。对术语定义分词处理后利用Java程序将术语定义中的词性为NN(普通名词)、NR(专业名词)和VV(动词)的词汇存入MySQL数据库中, 结果如图2所示:
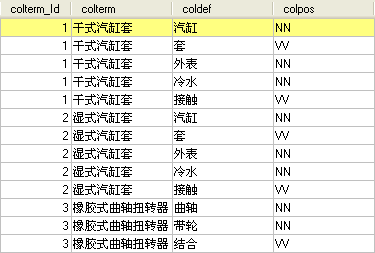 | 图2 术语定义分词结果 |
利用Java程序编写并运行定义的两种相似度算法, 并且分别将阈值设定为0.3、0.4、0.5、0.6, 测试在这4种不同的阈值下分别利用两种方法的同义词发现情况, 存储到MySQL数据库中。如表1所示为在阈值设置为0.3时分别使用方法一和方法二的同义词发现的部分情况, 其中term1与term2组成一个术语对, sim为term1与term2的相似度值。
用准确率和召回率来对同义词发现结果进行评估, 准确率是指发现的正确的同义词关系的术语对占发现的总的术语对的比例; 召回率是指发现的正确的同义词关系的术语对占语料库中存在的同义词关系术语对的比例, 同时运用综合评价指标F来进行评价, 其计算公式如下。
| 表1 阈值0.3时方法一和方法二同义词发现情况 |
Precision=]]> (8)
Recall=]]> (9)
F1-measure=F1=]]> (10)
经过人工判断, 使用方法一和方法二的同义词发现效果分别如表2和表3所示。
| 表2 方法一在不同阈值下的同义词发现效果 |
| 表3 方法二在不同阈值下的同义词发现效果 |
从表2可以看出, 方法一可以取得较高的准确率, 在阈值设置为0.6时, 取得最高准确率为74.1%, 但是使用方法一的召回率普遍较低, 最高仅有23.4%。从表2可以看出, 方法二取得的准确率相对较低, 最高仅有45.3%, 而且召回率也均不高, 最高仅有38.4%。造成方法二准确率较低的原因可能有: 一条术语定义可能由多个句子构成, 如果由多个句子构成, 那么上面的假设就需要修订, 需要按照句子赋权值之后, 再按照每个句子中的实词出现的位置赋权值; 另外可能是假设的函数不准确, 后续会使用其他的函数进行实验。
将表2和表3对比分析, 可以发现在同一阈值设置下方法二比方法一发现的同义词总数明显增多, 但是发现的正确的同义词对总数却增加不明显。因此造成方法二的准确率明显低于方法一, 而召回率仅仅略高于方法一, 因此在本次实验中方法一比方法二更具优势。
综合来看, 随着阈值设置越来越大, 准确率越来越高, 召回率越来越低, 并且两种方法的召回率均相对较低。由于召回率选定的标准比较严格, 实验结果是可以接受的。当阈值设为0.3时, 方法一达到较高的准确率和召回率, 为本次实验发现同义词的最佳效果。当然在不同的实验中方法一和方法二的效果可能不同, 不能完全确定哪个方法更具优势。并且在不同的需求下, 阈值的大小可以根据实际需要进行调整, 也可以分别在不同的阈值下对结果进行筛选, 从而达到更好的同义词发现效果。
造成本次实验召回率比较低的可能原因有: 选取的新能源汽车汉语科技词系统领域的术语定义本身存在一定缺陷, 因为其定义大部分是从不同的词典中获取的, 没有统一的标准, 造成同义词的发现数量有限; 之前语料库中存在的同义词总数统计本身具有一定误差; 该相似度算法只根据定义中出现的相同实词的数量及位置信息进行计算, 对实词出现的频次尚未考虑, 另外该算法对反义词也尚未处理, 因此使结果未达到理想状态。
根据术语定义提出了一种新的同义词发现方法, 可实现利用现有的知识组织系统中的资源对同义关系进行构建, 该方法相对于其他相似度计算方法来说不仅比较简单快捷, 而且同样能够达到一个较高的准确率, 说明该相似度算法是可行的, 但是该方法的召回率还相对较低, 因此对进一步研究提出以下几点建议: 将术语定义中相同实词出现的频率考虑进去, 使该相似度算法更加准确; 统计术语定义中出现否定词的数量及其位置, 从而可以发现反义词; 本方法不仅可以应用到同义词发现方面, 在发现相关词方面也很有意义, 因此可以将算法改进进行术语的相关词发现, 然后将本算法和其他同义词发现方法结合使用, 使同义词发现效果更佳。
| 表1 宾州中文树库5.0 POS标记集合 |
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|