



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
遗传算法在改进文本特征提取方法中的应用*
[路永和 , 梁明辉]
, 梁明辉]
, 梁明辉]
|
|


作者贡献声明:
路永和: 提出研究思路, 设计研究方案; 最终版本修订;
梁明辉: 实验, 数据的获取与分析;
路永和, 梁明辉: 论文起草。
【目的】综合分析特征提取方法并对传统特征提取流程和方法进行改进。【方法】利用特征池进行特征词预选, 引入遗传算法对候选特征词分组编码并提取最佳特征向量。【结果】改进的文本特征提取方法在使用KNN计算适应度值时效果最佳, 而且在特征维数较少时效果更为明显。同时在针对不同特征维数和语料库时, 分类准确率更加稳定。【局限】实验语料库质量有待提高; 构造特征池时只使用CHI和IG两种特征提取方法; 使用分组编码时没考虑词与词之间的语义关系; 种群数量和迭代次数受限于计算的复杂性。【结论】加入特征池进行特征预提取能够提高文本分类准确率的稳定性, 而加入遗传算法到文本特征提取中可以提高特征提取的效果, 遗传算法利用分组编码规则可以减少特征的过拟合现象并提高算法运行速度。
[Objective] To comprehensively analyze many feature extraction methods and improve traditional feature extraction process.[Methods] Firstly, the paper uses feature pool to pre-extract features, then extract best feature set by genetic algorithm and group coding.[Results] When the fitness function uses KNN classification algorithm, the method using in this paper shows the best performance. Besides, the effect is more obvious with less feature dimensions. Simultaneously, the proposed method has better stability in text classification for different feature dimensions and corpuses.[Limitations] The corpus is not abundant enough. Only IG and CHI are used to extract features for feature pool construction. It ignores semantic relationships among words for group coding. The population size and the number of iteration in genetic algorithm are restricted by experimental conditions.[Conclusions] The stability of text classification is improved by adding a feature pool to pre-extract features. The result of text classification is more accurate by adding genetic algorithm in the text feature extraction. To use proposed method reduces overfitting of features and improves efficiency by utilizing group coding in the genetic algorithm.
文本分类方法主要有贝叶斯、KNN、类中心、支持向量机等[ 1], 文本表示一般使用向量空间模型(Vector Space Model, VSM)中的特征向量来表示, 其维数可以达到几万维甚至几十万维。特征向量能否很好地表示不同文本的特性直接影响到文本分类的精度, 因此文本分类中特征提取方法的好坏对文本分类的效果有重要影响。因为特征维数过多会影响分类器的训练效果, 而过少则又不足以很好地表示各类文本的特点。所以有必要研究并找到一种既能减小特征向量空间维数又能保证有较优的分类效果的特征提取方法。本文采用遗传算法并且加入特征池和候选特征分组编码来优化特征提取, 以进一步提高文本分类的准确率。
目前常用的特征提取方法有文档频率(DF)、信息增益(IG)、互信息(MI)、卡方检验(CHI)、期望交叉熵(ECE)和几率比(OR)等[ 2]。卡方检验和互信息都表示文本分类中的特征和类别之间的相关性, CHI或MI的值越大, 表明特征与类别的相关性越强。信息增益IG主要是根据特征项在文档中出现与否来计算它为分类预测所贡献的信息比特数。特征的文档频率DF是指在训练样本集中出现该特征的样本数[ 3]。
这几种文本特征提取方法没有绝对的最优, CHI的分类效果好但计算代价较高[ 4]。对于分类效果而言, 在英文数据集的分类中, CHI与IG效果最佳, DF 效果基本与前两者一致, 而MI则相对较差[ 2]; 在中文数据集的分类中, CHI的效果最佳, 其次为IG, 而MI则相对较差[ 5], DF的效果居中[ 4]。
遗传算法(Genetic Algorithm)是一类借鉴生物界的进化规律演化而来的随机化搜索方法。遗传算法组成部分主要有[ 6]: 编码机制、适应度函数、遗传算子(选择、交叉和变异)和控制参数。利用遗传算法求解问题时, 问题的可能解都将被编码成染色体, 即个体。若干个个体组成初始解群, 通过适应度函数计算后, 满足终止条件的个体可以被输出, 算法结束。否则, 个体经过交叉、变异再组合生成下一代新种群, 新种群继承了上一代的优良性状, 优于上一代, 这样就可以逐步朝着更优解的方向进化。
在国外, 密歇根州立大学学者Raymer等利用遗传算法来进行特征降维, 主要思想是通过测量该特征在线性状态和非线性状态下的权重来进行特征的选择[ 6]。美国劳伦斯利弗莫尔国家实验室学者Cantú-Paz提出了一种基于类间分离性的混合遗传算法来进行特征提取[ 7]。印度Dr. M.G.R.大学学者Rajavarman和Rajagopalan提出了一种2-Phase Approach的遗传算法, 并将其应用到大量的多因性疾病数据的特征提取上[ 8]。美国佐治亚州立大学学者Tan等提出了一种改进的数据挖掘的特征提取方法, 结合特征池和遗传算法来进行特征提取[ 9]。
在国内, 天津大学学者郝占刚和王正欧提出了采用潜在语义索引进行首次特征降维, 再用遗传算法进行进一步特征降维的方法[ 10]。中国石油大学学者刘亚南在利用标准的遗传算法进行特征提取的基础上, 提出了一种根据文本特征而设计的适应度函数和交叉规则[ 11]。天津大学学者张志宏等设计了一种基于遗传算法的多种群特征提取方法并应用到顾客行为特征提取领域, 该方法采用最近邻替代遗传策略和局部搜索策略[ 12]。长沙理工大学学者龙鹏飞等将蚁群算法应用到遗传算法的选择操作中, 提出了一种蚁群算法和遗传算法相结合的特征提取方法[ 13]。学者高贤维等将遗传算法与神经网络结合起来运用于特征提取, 实验表明可以有效地提取出重要特征[ 14]。
现在国内外学者利用遗传算法改进文本特征提取方法主要有两个方向:
(1) 把遗传算法和其他智能算法结合使用, 例如将蚁群算法应用于遗传算法中的适应度计算步骤中, 又如用神经网络分类器的效果作为遗传算法的适应度函数。这种改进的好处是能够结合不同算法的优点, 减少遗传算法缺陷的影响。但是这种方法在设计多种算法结合时存在较高难度, 因为不同算法的内在运行机制不尽相同。
(2) 对遗传算法本身的步骤进行改进, 这种方法是目前研究较多的改进方法。对于遗传算法的不同步骤分别提出有针对性的改进方法, 例如设计变量包含特征维数和分类效果的适应度函数、设计高效的特征编码规则等。利用这种方法进行改进的研究有很多并取得一定成果, 但是不足之处是无论怎样修改还是无法避免遗传算法本身不足对整个特征提取方法的影响。
本文提出的方法属于第二个方面。首先, 借鉴了国外学者进行特征预提取的方法, 提出的改进方法在利用遗传算法前加入特征池进行特征预提取, 并且预提取的方法根据中文文本特征的实际情况选取。然后, 在利用遗传算法进行文本特征提取时, 尝试采用分组编码的规则对候选特征进行编码, 意在减少最终特征与训练文本集的过拟合程度, 同时也希望这种分组编码规则可以提高遗传算法在文本特征提取中的运行效率。
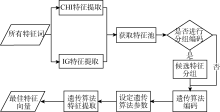
综合分析现有文本特征提取方法优劣的基础上, 应用遗传算法, 提出一种新的文本特征提取方法, 其基本流程如图1所示:
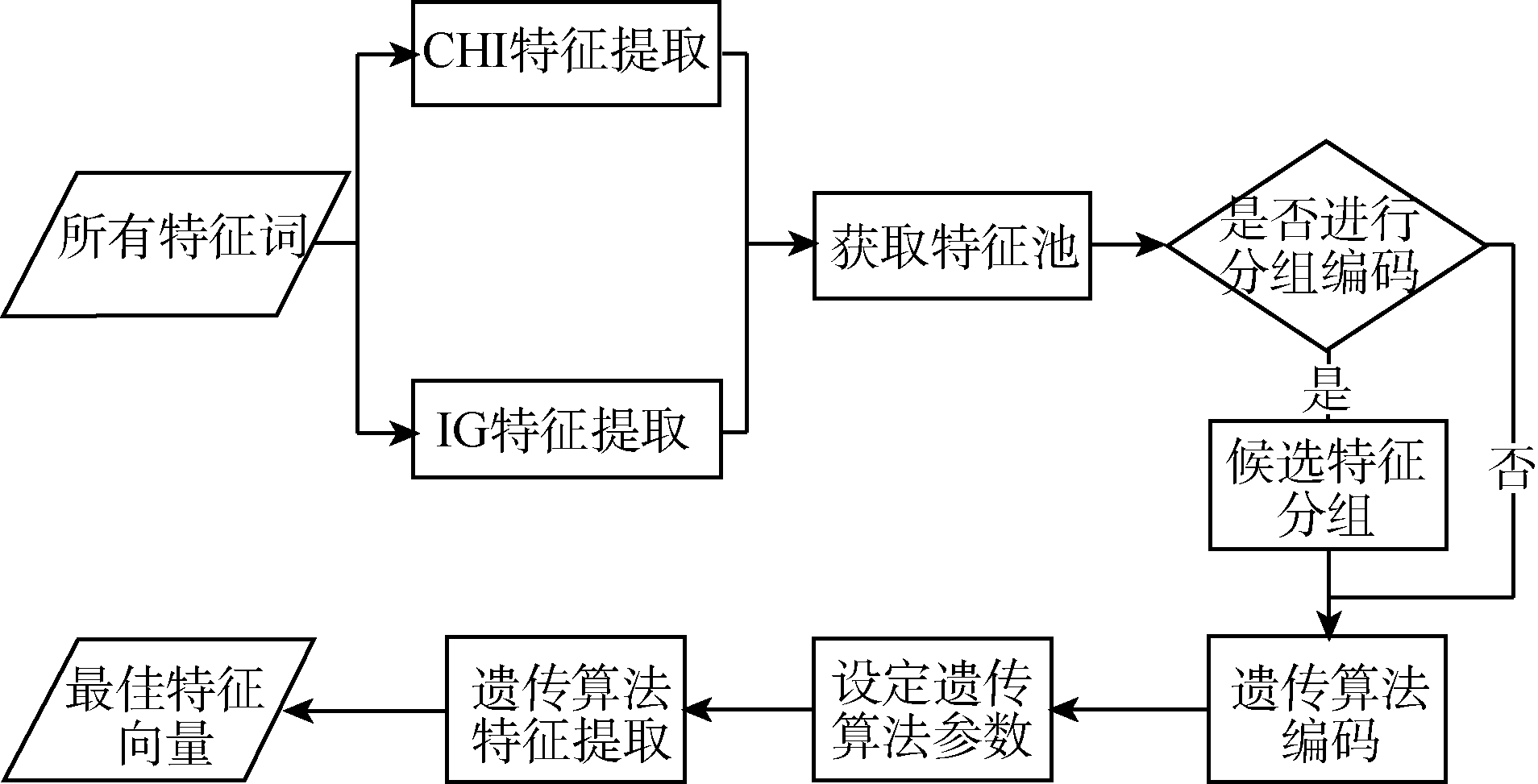 | 图1 改进的文本特征提取流程 |
利用CHI、IG特征提取方法各抽取指定维数的特征, 然后通过比较去除重复的词, 得到一个有较多数量的特征词列表, 即特征池。将特征池内的候选特征进行分组。针对特征分组进行遗传算法的个体编码。设定遗传算法的基本参数, 包括交叉概率、变异概率和选择机制等。通过遗传算法迭代选择出最优的特征向量。
国外有学者在进行数据挖掘的特征提取时采用多种提取方法, 然后将其提取结果进行整合, 最后得出一个由多种提取方法选择的特征组成的特征池[ 9]。这个特征池为进一步提取最优特征向量提供了候选特征。
对于文本分类而言, 卡方检验(CHI)和信息增益(IG)的特征提取方法是较为常用的特征提取方法, 但是各有其优点和不足, 因此根据这两种方法提取出来的特征向量都不可能是最优的特征向量。为了寻找最优的特征向量, 本文也采用特征池来进行预提取, 整合上述两种特征提取方法所得到的特征, 然后利用遗传算法在特征池中提取出更优的特征向量。
遗传算法的编码机制有二进制编码、实数编码、格雷编码、符号编码等。针对不同的问题要采用不同的编码方法。本文采用二进制编码机制, 即当该维特征被选择时, 表示为1; 而当该维特征不被选择时, 表示为0。
由于候选特征的数量比较多, 倘若每维特征都用一个码来表示其选择情况, 那么整个特征提取方法的运算效率必将受到较大影响。因为其他智能优化算法的编码步骤与遗传算法有一定的相似性, 所以本文的编码规则参考了采用粒子群算法进行特征提取时的编码方法[ 15]。此外, 遗传算法的个体在不断进化的过程中, 提取出来的特征集合有可能对训练文本集产生过拟合现象。而因为分组是由几个特征一同组成的, 进化时必须考虑整个分组所有候选特征对分类效果的影响, 因此采用这种编码规则能减少只符合训练文本集特点的特征数量, 从而避免过拟合现象出现。为了减少候选特征分组消耗的时间, 本文采取候选特征随机分组的方法, 组内的特征数量设定为5。
(1) 交叉概率(Pc)
本文使用的遗传算法中的个体是特征向量, 当进行交叉操作时, 两个不同的特征向量中的一部分相互交换, 产生了两个新的特征向量。而这些新的特征向量将会通过选择机制来确定是否留下。交叉操作的目的就是产生新的个体, 防止局部最优解的情况产生, 交叉概率大, 进行交叉的基因就会多一些。相反, 交叉概率较小, 参加交叉的基因则较少一些。交叉概率一般取值0.4-0.9[ 16]。经过多次测试发现, 本文方法的交叉概率取0.5时效果最佳, 因此后续实验均采用0.5作为交叉概率。
(2) 变异概率(Pm)
在遗传算法中, 仅仅通过交叉操作不可能得到新的基因, 而变异操作则可以产生新的基因, 增大种群的多样性。为了防止最优解会因变异而遭到破坏, 变异概率应取较小的值, 一般取值0.001-0.1[ 16]。本文实验采用的变异概率为0.001。
(3) 选择机制
本文采用的是最简单但也是最常用的选择机制: 轮盘赌选择法。在该方法中, 各个个体的选择概率和其适应度值成比例。设群体大小为n, 其中个体i的适应度为fi, 则i被选择的概率为:
(4) 适应度函数
个体对环境的适应程度叫做适应度(Fitness)。本文提出的特征提取方法主要是为文本分类而做的预处理, 因此适应度函数采用分类准确率。
(5) 其他控制参数
其他控制参数还包括种群规模(M)和进化代数(T)。种群规模M一般定为20-100, 因为M的取值太小不能提供足够的采样点, 而M太大会增加计算量, 延长收敛时间。进化代数T则控制了整个进化过程的迭代次数。由于本文中的特征提取方法计算量比较大, 为了保证运算的效率, 种群规模设定为20, 进化代数设定为20。
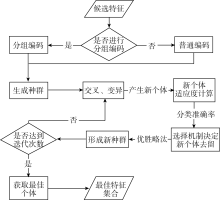
本文使用遗传算法进行文本特征提取主要有以下几个步骤:
(1) 对候选特征进行编码;
(2) 根据设置的种群数量产生个体(文本特征集合), 形成种群(若干个文本特征集合的集合);
(3) 种群的各个个体根据设置的交叉概率和变异概率进行进化, 产生新个体;
(4) 新个体根据适应度函数计算适应度值(分类准确率);
(5) 根据选择机制决定新个体是否能留下, 形成新的种群;
(6) 如果没有达到设置的迭代次数, 重复步骤(3)-(5), 否则继续步骤(7);
(7) 根据适应度值的大小选出最优个体, 即最佳文本特征集合。
具体流程如图2所示:
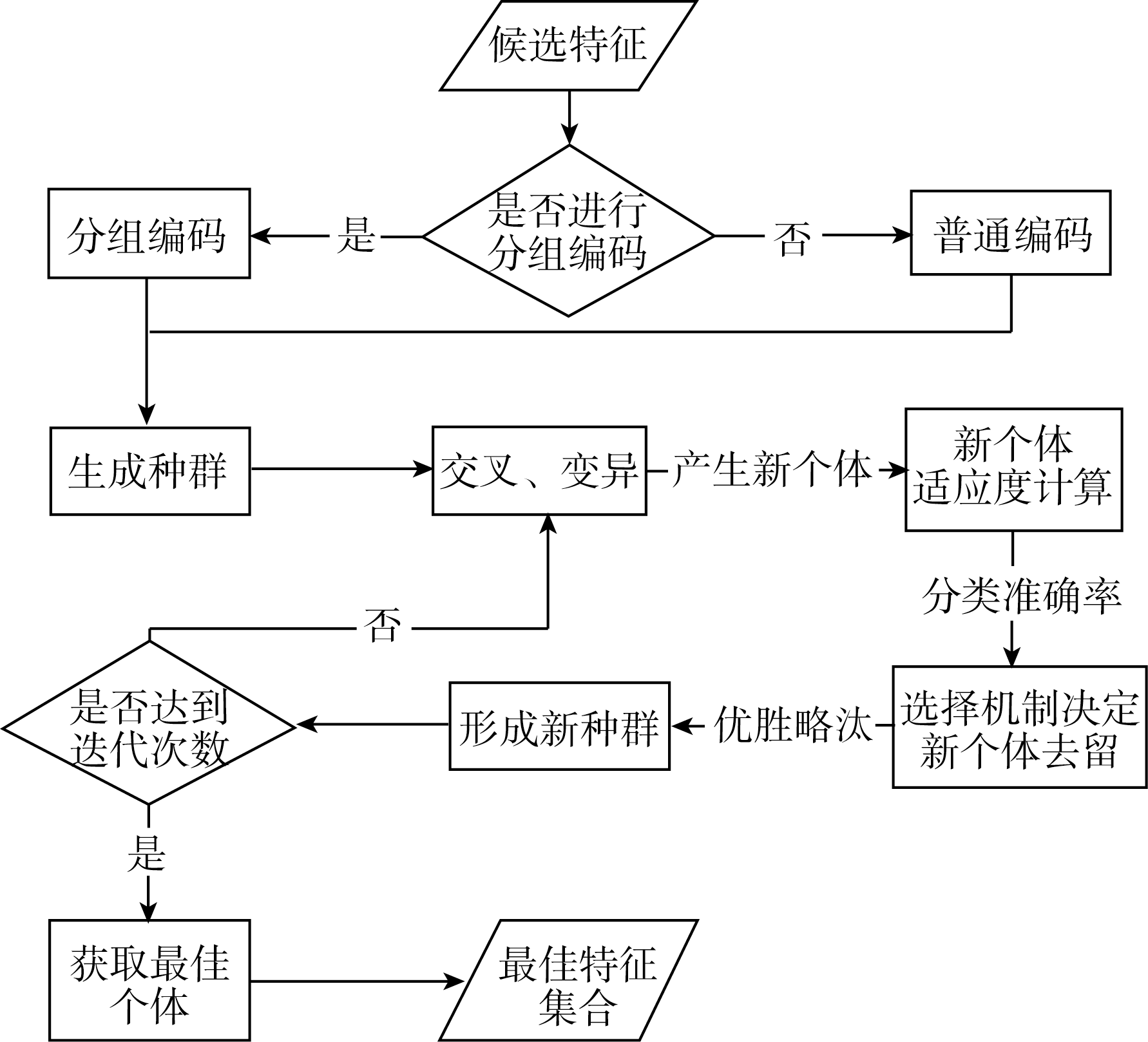 | 图2 遗传算法进行文本特征提取具体流程 |
实验使用的语料库是搜狗文本分类语料库中的一部分和复旦李荣陆教授提供的中文语料库的一部分, 搜狗语料库选取其中的9个类别, 分别是教育、财经、IT、健康、体育、旅游、招聘、军事、文化。训练文本集中每个类别各200篇文本, 共1 800篇。测试文本集每类各100篇, 共900篇。所有文本分词去重后, 共有词语44 158个。复旦语料库选取20个类别中文本较多的9个类别, 分别是Agriculture、Art、Computer、Economy、Environment、History、Politics、Space、Sports。训练文本集中每个类别各200篇文本, 共1 800篇。测试文本集每类各100篇, 共900篇。所有文本分词去重后, 共有词语109 499个。
实验平台基于Java语言开发, IDE环境是Eclipse, 集成了多种开源软件。其中实验平台的文本分词器采用中国科学院分词器ICTCLAS, 索引器采用Lucene 3.0, 各种分类算法调用的是Weka算法, 而遗传算法模块则是改写于遗传算法开源包jpag。所有实验均采用TF-IDF特征权值计算方法。为了减少计算量, 遗传算法的适应度函数中的训练文本集与测试文本集均采用整个实验的训练文本集。
实验采用参照对比方法。针对两个语料库的文本都做了以下实验进行对比: 候选特征分组与不分组进行编码对比, 适应度函数采用KNN分类法与采用朴素贝叶斯分类法的对比, 不同特征维度的对比。对比指标包括: 运行时间、自测分类准确率和分类准确率。因为遗传算法在初始化染色体时每个基因是1还是0的概率一样, 均为0.5, 所以为了保证初始化的种群中大部分个体可用, 特征池中的候选特征数量应少于并尽量接近限制条件的2倍。本实验采用的限制条件有两个, 分别是300维和600维。
实验数据中各种特征提取方法的表述如下:
①CHI: 卡方检验特征提取方法;
②IG: 信息增益特征提取方法;
③CHI_IG: 采用CHI和IG获取的特征池直接作为最终特征集合的方法;
④CHIIG_GAKG: 采用CHI_IG方法获取特征池和遗传算法特征提取方法, 采用KNN分类法结果作为适应度函数, 采用候选特征分组编码规则;
⑤CHIIG_GAKNG: 采用CHI_IG方法获取特征池和遗传算法特征提取方法, 采用KNN分类法结果作为适应度函数, 不采用候选特征分组编码规则;
⑥CHIIG_GABG: 采用CHI_IG方法获取特征池和遗传算法特征提取方法, 采用朴素贝叶斯分类法结果作为适应度函数, 采用候选特征分组编码规则;
⑦CHIIG_GABNG: 采用CHI_IG方法获取特征池和遗传算法特征提取方法, 采用朴素贝叶斯分类法结果作为适应度函数, 不采用候选特征分组编码规则;
⑧CHI_GAKG: 采用CHI方法获取特征池和遗传算法特征提取方法, 采用KNN分类法结果作为适应度函数, 采用候选特征分组编码规则;
⑨CHI_GAKNG: 采用CHI方法获取特征池和遗传算法特征提取方法, 采用KNN分类法结果作为适应度函数, 不采用候选特征分组编码规则;





征提取方法, 采用朴素贝叶斯分类法结果作为适应度函数, 采用候选特征分组编码规则;

遗传算法提取的特征维数为600以下(包括600维), CHI、IG和CHI_IG提取的特征均为600维。通过CHI与IG方法预提取800维, 再去除重复后形成的特征池候选特征数量为1 125。遗传算法提取的特征维数为300以下(包括300维), CHI、IG和CHI_IG提取的特征均为300维。通过CHI与IG方法预提取350维, 再去除重复后形成的特征池候选特征数量为527。
600维条件下与300维条件下实验数据的对比, 分别如图3至图6所示:
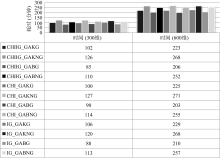
 | 图3 时间性能对比图(搜狗语料库) |
(2) 复旦语料库
遗传算法提取的特征维数为600以下(包括600维), CHI、IG和CHI_IG提取的特征均为600维。通过CHI与IG方法预提取750维, 再去除重复后形成的特征池候选特征数量为1 199。因为复旦语料库的词量比搜狗语料库的词量要大, 在采用遗传算法进行特征提取时运算的复杂度相对高, 所以由于机器性能所限, 对于600维的特征提取, 实验中将遗传算法中种群数量调整为10, 进化代数保持不变。遗传算法提取的特征维数为300以下(包括300维), CHI、IG和CHI_IG提取的特征均为300维。通过CHI与IG方法预提取400维, 再去除重复后形成的特征池候选特征数量为609。
600维条件下与300维条件下实验数据的对比,
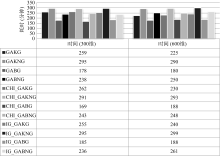
 | 图4 KNN分类效果对比图(搜狗语料库) |
 | 图5 朴素贝叶斯分类效果对比图(搜狗语料库) |
 | 图6 时间性能对比图(复旦语料库) |
 | 图7 KNN分类效果对比图(复旦语料库) |
 | 图8 朴素贝叶斯分类效果对比图(复旦语料库) |
从以上的结果可以看出: 采用本文提出的特征提取方法比传统特征提取方法的效果有一定提高, 特别是在特征维数较少的情况下。
(1) 时间性能
在时间性能上, 是否采用候选特征分组编码来使用遗传算法会影响整个算法的运行时间。由两个语料库的时间性能对比(图3和图6)可看出, 无论是在300维还是600维的限制条件下, 采用分组编码的方法比不采用分组编码的方法要节省不少时间。其中针对搜狗语料库节省的时间平均为31.25分钟, 限制条件300维为23.17分钟, 而限制条件600维的是为39.33分钟。而针对复旦语料库节省的时间平均为56.67分钟, 限制条件300维为48.33分钟, 而限制条件600维为65分钟。
(2) 分类效果
在特征维数上, CHI、IG和CHI_IG方法都根据限制条件选取不同维数的特征。而对于采用遗传算法进行特征提取的4种方法, 如果限制条件是N维, 那么4种方法最终提取的特征维数略小于或等于N维。在分类的准确率上, 无论从采用KNN分类的对比图还是从采用朴素贝叶斯分类的对比图中都可看出, 在训练文本集自测下采用本文提出的特征提取方法的分类效果均比采用CHI或者IG的方法要好, 比起CHI_IG方法则在不同测试环境下表现各有优劣, 而且采用朴素贝叶斯分类法作为适应度函数的方法自测效果最佳。但是从测试文本集的分类效果来看, 采用KNN分类法作为适应度函数的方法的分类效果普遍比CHI和IG传统两种方法要好, 比起CHI_IG方法表现略好, 但是采用朴素贝叶斯分类法作为适应度函数的方法的分类效果的提高却不明显, 有些情况还会不如传统方法。这种现象表明采用朴素贝叶斯分类法作为适应度函数比采用KNN分类法作为适应度函数更容易出现过拟合现象, 即训练文本集自测分类效果很好, 而测试文本集测试分类效果却不尽理想。
对于限制条件300维和600维, 采用本文提出的特征提取方法在300维的条件下分类效果的提高更为明显。从上面各个实验对比图可以看出, 对于测试文本集, 在CHI、IG或CHI_IG三种方法形成特征池后使用遗传算法进行特征提取, 无论是否采用分组编码规则、采用KNN或朴素贝叶斯作为适应度函数, 都能在分类效果上有所提高。GAKG、GAKNG、GABG和GABNG 4种利用遗传算法提取特征的方法中, GAKG的表现最好。另外, CHI和IG两种方法在不同的测试环境下分类效果很不一致, 例如在300维的情况下, 对于搜狗语料库, 采用KNN分类法时IG方法的效果达到69.33%, 而CHI方法只有42.33%, IG方法比CHI方法要优胜得多。但是对于复旦语料库, IG方法效果只有52.22%, 而CHI方法却达到59.33%。因为在利用CHI或IG方法进行预提取后利用遗传算法继续进行特征提取, 分类效果也只会在CHI或IG方法的基础上有所提高, 所以这些利用遗传算法的特征提取方法的效果是很不稳定的。从实验数据可以看出, CHI_IG方法的分类效果比CHI和IG要稳定得多, 同样在CHI_IG方法基础上利用遗传算法进行特征提取的4种方法的效果也比较稳定。对于是否采用分组编码规则、适应度函数采用KNN或朴素贝叶斯的4种利用遗传算法的特征提取方法中, GAKG的效果最好、GABNG的效果最差, 而且采用分组编码的方法优于不采用的分组编码的方法。从稳定性和分类效果综合来看, CHIIG_GAKG的效果最好。
综上所述, CHI_IG方法和以它作为特征池的遗传算法特征提取方法在不同的测试环境下分类效果表现最为稳定, 并且总体上比CHI和IG这两种传统的方法表现要好。而相比之下, 采用GAKG方法的表现优于CHI_IG方法。这表明了特征池与不同传统文本特征提取方法的结合能有效提高文本分类在不同环境下分类效果的稳定性, 而加入分组编码的遗传算法则可以进一步提高分类的精度和稳定性, 同时减少特征集合的过拟合程度, 并且提高算法运行效率。
从实验数据可以看出, CHI和IG两种特征提取方法在搜狗语料库和复旦语料库的表现大不相同。对于不同特征维度和采用不同的分类方法, 两种传统的特征提取方法的表现各有优劣, 因而无法得出谁优谁劣的结论。因此在实际应用中, 可以将各具优点的传统特征提取方法选出来的特征汇总, 然后采用本文提出的基于优化的遗传算法文本特征提取方法在汇总的候选特征中进行选择, 使得选出的特征集合能综合多种传统方法的优势, 文本分类效果更为稳定。
综合考虑上述实验结果, 在特征维数不多的情况下, 采用分组编码和KNN分类法作为适应度函数时效果最佳。但在特征维数较高的情况下提高效果不明显, 因此这种特征提取方法还有值得改进的地方:
(1) 针对文本分类的评价指标和特征维数来设计遗传算法中的适应度函数, 希望能在特征维数和分类效果之间取得平衡。
(2) 优化特征池中特征的获取方法, 其中一个方向是增加预提取的特征提取方法, 增加候选特征的数量。
(3) 优化候选特征的分组编码方法, 根据特征与特征之间的词义关系来设定分组规则, 使得分组编码更具合理性。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|