
{kind=link}
{kind=link}
面向情感分析的用户评论过滤模型研究*
[蔡晓珍1 , 徐健1  , 吴思竹
, 吴思竹2 ]
, 吴思竹|
|


作者贡献声明:
徐健: 提出研究思路, 设计研究方案;
蔡晓珍: 进行实验;
蔡晓珍, 吴思竹: 采集、清洗和分析数据;
蔡晓珍, 徐健: 论文起草;
徐健: 论文最终版本修订。
【目的】针对情感分析研究中网络用户评论质量良莠不一的问题, 构建过滤模型进行筛选。【方法】选取涉及产品词汇量、评论长度、情感强度、修饰词数量4个指标作为评判依据, 利用多元线性回归方法和来自购物网站的数据构建模型。【结果】发现涉及产品词汇量、评论长度、情感强度、修饰词数量与评论质量存在相关性。所构建的过滤模型具有较高的召回率和准确率, 为情感分析中数据源的筛选提供一种新方法。【局限】存在数据稀缺性影响, 所构建的模型具有局限性。【结论】在误差允许的范围内, 该模型能够对评论的质量等级进行自动判断。
[Objective] Aiming at the problem of quality testing in the process of sentiment analysis research, the paper constructs a filter model to select more suitable review.[Methods] It selects four indexes namely product words, length of review, emotional strength and adjunct words as judgment references, using multiple linear regression method and data from shopping website to construct the model.[Results] The four indexes are related to the quality of review, and the filter model gains high accuracy in terms of recall rate and precision so that it provides a new method for selection of data source in the sentiment analysis research.[Limitations] Data scarcity leads to the limitation of the filter model.[Conclusions] The model can judge the quality of customer reviews in the range of permitted errors.
随着Web2.0的兴起, 用户越来越多地参与到网络内容的建设工作中, 许多购物网站也提供了在线评论机制。商品评论一方面能够作为重要的参考依据, 帮助消费者更好地选购商品, 另一方面又能够为厂家提供良好的市场反馈信息, 有利于商品的改进以及对市场消费现状的了解。鉴于此, 人们开始重视对网络用户评论的研究, 期望能通过挖掘商品评论中的信息, 尤其是情感倾向, 来获取用户的看法或态度, 这就催生了用户评论的情感分析这一新兴研究领域的发展。然而, 由于评论书写自由, 在线评论的质量良莠不齐。在情感分析过程中, 大量劣质的评论会影响网络用户情感挖掘的准确性和可信性, 甚至会对商品整体意见的挖掘结果造成偏差。因此, 在考虑如何充分利用用户评论的价值之前, 有必要对评论进行自动过滤。
网络用户评论的过滤研究已经引起许多研究者的重视。相关研究可归纳为两类: 第一类以识别有助于消费者制定购物决策的有用评论为研究方向; 第二类的研究目的则在于识别有助于商家发现用户需求的有用评论。在第一类研究中, Liu等[ 1]认为对潜在消费者购买决策有用的在线商品评论取决于三个因素: 评论者的经验、评论的写作风格和评论的时效; 郝媛媛等[ 2]以电影的在线评论为研究对象, 考察了影响评论有用性的重要文本特征, 包括正负情感、观点表达形式、评论体裁以及评论标题等; Mudambi等[ 3]研究评论极端性、评论深度和商品类型对感知评论有用性的影响; Chen等[ 4]提出了评价在线商品评论质量的9个维度, 构造多类支持向量机模型对在线评论进行分类, 从而识别高质量的评论; 孙升芸等[ 5]也从垃圾评论的角度对评论的质量做出判断。在第二类研究中, 刘送英[ 6]选用卓越网上的实际评论数据构建评论有用性衡量体系; 苏雪佳[ 7]从评论者、评论阅读者、评论本身、评论发表时间4个维度来构建在线评论有用性影响因素指标, 分析在线评论有用性的具体影响因素; 姜巍等[ 8]则提出一种基于复杂网络的评论有用性分析方法。这些研究多数从消费者与商家的角度出发来研究评论的有用性, 主要目的是帮助消费者更快更好地发现高质量的评论, 或者帮助商家识别用户需求。然而, 在利用商品评论进行情感分析的过程中, 对消费者或商家来说有用性最大的评论并非完全适合用于情感倾向性研究。
除此之外, 在大多数进行情感分析的文献中, 对评论情感质量的判断仅仅简单停留在数据清理、去除无用信息、去除词频小于阈值的评论等浅层阶段, 并未对评论中所表达的情感强度、文本语义等方面进行分析。
本文尝试从情感分析的角度来构建在线评论质量过滤的指标体系, 以弥补上述相关研究不足。下文将分析相关指标, 详细阐述利用这些指标构建的评论过滤模型, 并使用来自购物网站上的数据进行实验, 观察该模型的过滤效果。
本文通过考察在线评论的形式特征和内容特征, 分析影响情感分析研究过程中评论质量的指标, 并利用样本评论集进行了指标效用证明, 剔除了部分不合理指标, 努力构建一个较为完善的过滤模型。
一条用户评论通常由形式特征和内容特征两部分组成, 其中, 形式特征包括句子长度、评论支持率、评论者活跃度等, 内容特征包括修饰词、情感强度、涉及产品词汇量等。这些组成部分能够反映该评论的价值, 同时也是情感分析过程中重要的分析内容, 故影响质量优劣的依据可以通过这两部分来进行考察。根据经验判断, 从中提取出可能影响评论质量的多个指标, 逐一分析如下。
(1) 涉及产品词汇量
涉及产品词汇量是指评论中出现用于描述产品各项属性的关键词个数。在构建词表时, 既可以通过该产品权威领域的关键词分析得到涉及产品词汇表, 也可以根据实际需要进行人工选择与构建。以手机产品为例, 手机产品属性可包括外观形态、技术指标、产品功能、产品性能及特殊术语5个方面。这5个方面的划分依据主要有两个来源: 各大手机网站及论坛对手机参数的介绍; 笔者根据实际使用情况对常用手机词汇的抽取。如图1列出了手机的一部分涉及产品词汇。在分析手机产品时, 出现涉及上述关键词或其近义词都可以认为评论中出现了涉及产品的词汇。
 | 图1 手机涉及产品词汇示例 |
情感分析任务的一个重要工作是分析用户评论中对不同产品或同一产品不同方面的情感倾向, 因此, 评论内容与产品的相关度就显得非常重要。如果一条评论中涉及产品属性的词汇出现频率越高, 则这条评论对产品特征及相应属性的描述也就越多, 评论内容与产品的相关度相应地会越大, 这样的评论就更适合作为产品情感挖掘的信息源。因此涉及产品的词汇出现频率越高, 越有利于用于情感分析任务的开展, 评论也就越有价值。
(2) 评论长度
评论长度是指评论中出现的字符总数。较长评论包含的信息往往更加详细、全面, 对产品各方面的描述也更加细致, 而且较长的评论反映了发布者对商品使用的强烈感受以及写评论时更加真诚和负责的态度。这样的评论一方面能够从中获得更多有用的信息, 另一方面可信度更高, 更适合做情感分析的信息源。以下两条评论:
①“作为很经典的一部机子现在处于这个价格很低了, 而且也快没了, 还是决定在最后入手一个给家里小妹妹用~发货很快, 第二天就到了, 赞一下!”
②“给朋友买的, 挺不错的。”
评论①的长度为64, 评论②的长度为11, 容易看出, 评论①比评论②的情感表达更强烈, 更适合作为情感分析的信息源。
虽然在某些文章中, 如文献[9], 认为过长评论观点比较分散, 容易偏离主题, 消费者不便于理解, 但是从考虑情感分析需求的角度来说, 可用性低并不一定代表不适合做信息源。较长的评论往往会包含较多信息, 因此句子长度可以拟作为影响评论质量的指标之一, 评论长度越长, 评论质量越高。
(3) 评论者活跃度
评论者活跃度反映评论发表者在该网站上活动的频繁程度, 可通过评论者发表的评论总数来确定。评论总数越多, 评论者活跃度越大。如以下两条评论:
③“机子特别好用, 很经典的一款手机, 值得拥有。”
④“买来送人的, 非常好, 外面的包装膜还在, 就是价格比apple的贵点。”
评论③发表者的评论总数为4, 评论④发表者的评论总数为15, 故评论③的评论者活跃度设定为4, 评论④的评论者活跃度设定为15。因此, 评论④的活跃度更大。评论者活跃度越大, 说明该评论者网购经历越丰富, 评论书写经验越多, 也就更有可能提供高质量的用户评论, 因此本文拟将其作为判断评论质量的依据之一。
(4) 修饰词数量
修饰词是在句子中具有修饰作用的词, 主要以形容词和副词为主, 同时也包括一些在句子中扮演修饰角色的其他词。在计算修饰词的数量时, 由于在句子不同位置出现时词的修饰效果不同, 故相同的词出现在不同的位置时按照不同词计算。如评论⑤中, 包含修饰词数量共有13个, 分别是“好”、“差”、“偏色”、“延迟”、“免费”、“不错”、“很”、“不”、“很”、“不”、“老是”、“都”、“也”。
⑤“IP4拍照效果很好, 不比现在的小米2差。而且小米2MS版拍照会存在偏色和延迟。苹果给人的用户体验很不错, 不像安卓老是弹广告, 虽然很多东西都要钱, 但也有很多免费的。”
修饰词可以更准确地表现评论者的感想、认识与经验, 丰富评论者所表达的情感, 从而能更好地表达其情感倾向及情感强烈程度。评论中的修饰词数量越多, 其表达用户情感的能力越强, 也就越能符合情感分析研究的需求。因此本文拟将其作为判断评论质量的依据之一。
(5) 评论支持率
评论支持率指评论在多大程度上能够获得其他用户的认可。大多数网站除了提供用户对商品的评价服务, 往往还允许其他用户对某一用户填写的评论进行投票或回复, 以评价该评论的可信度及有用性。不同的用户会综合多种不同的因素来判断, 如自己的使用经验、评论的价值或他人的影响等, 这使得评论的质量评判更加全面。依据经验判断, 评论支持率越高的评论真实性越强, 对产品的描述更贴近用户实际使用情况, 也就应当具有较高的质量。因此本文拟将其作为判断评论质量的依据之一。
(6) 情感表达强度
情感表达强度度量的是评论中用户所表达的情感的显性程度, 可以通过各种特殊句式(如感叹句、反问句、疑问句等)、特殊关键词(如“呢”, “唉”, “啊”等)或特殊符号(如表情符号、异化的标点符号等)来量化。评论者在发表评论时, 往往按照自己的意愿来发表观点, 因此不同的评论所使用的情感表达强度有时候是不同的。评论者对产品的体会越深刻, 使用感受越强烈, 则越有可能会在评论中表示赞美、惊叹、喜悦、厌恶、生气、不满等情感, 而这些感情的表达恰恰是情感分析的重要组成部分, 同时也最能够反映评论的真实性。因此, 情感表达强度越大, 评论价值越高, 在此拟将其作为判断评论质量的依据之一。
指标效用表示指标在多大程度上能够正确反映评论的价值, 通过双变量分析可以确定指标级别与评论级别的相关性, 从而证明不同指标的效用。在指标量化之前, 本实验先通过分析部分评论数据, 确定合理的划分规则。情感分析任务关注的是评论中词汇的描述详尽程度, 而非词汇相对于该评论的统计结果, 除此之外, 归一化处理可能会使得不同价值的评论出现相反的判断结果, 即描述越简单的句子越可能被判断为更有价值。考虑到词汇的统计价值和归一化后带来的误差, 因此本实验在量化时并不进行归一化处理。最终确定的指标量化方式如表1所示。
此分析过程的实验样本来自亚马逊[ 10]和京东商城[ 11]网站。经过预处理后得到三批数据, 第一批数据全部来源于亚马逊, 共500条评论; 第二批数据全部来源于京东商城, 共500条评论; 第三批数据部分来源于亚马逊, 部分来源于京东商城, 共500条评论。在量化其各指标级别和质量级别后, 本文利用SPSS软件[ 12]进行了Spearman相关系数[ 13]分析。各指标与质量级别的相关系数取三批数据的平均分析结果, 如表2所示:
| 表1 指标量化评分方式 |
| 表2 Spearman相关分析结果 |
由表2可以看出, 涉及产品词汇数量、评论长度、修饰词数量以及情感表达强度4个指标的Spearman相关系数分别为0.627、0.433、0.614、0.448, 表明各项指标与质量等级呈现正相关关系, 这与3.1节的分析结果相吻合。在显著性检验方面, 这5项指标都能达到95%以上, 显著性明显。对于剩下的两个指标, 评论者活跃度的相关系数为-0.094, 评论支持率的相关系数为0.099, 相关性都非常小, 并且均没有表现出明显的显著性。由此可知, 这两个指标与评论质量级别的高低并不存在决定性关系。通过查阅原样本评论集, 发现确实如此。如以下三条评论:
⑥“很好, 喜欢。没有别的问题。”
⑦“有两处瑕疵, 一个有个黑色的划痕, 另一个是边缘缺少, 都不是很大, 仔细看才能看出来, 还是让人窝火!!!!有些失望。”
⑧“翻新机, 让人郁闷, 太纠结。”
从评论者活跃度的角度来说, 评论⑥作者发表的评论数高达51条, 但该评论非常简单、粗略, 未能详细地表明评论者使用产品的情感; 评论⑦作者发表的评论总数虽然只有1条, 但是该评论中对产品的细节描述以及作者的使用感受描写都非常真实详细, 适合用于情感分析, 因此其质量级别比较高。通过分析可知, 评论者活跃度只能说明用户的网购经验多, 评论书写次数多, 但并不代表其书写评论的态度以及情感表达的充分性。评论支持率也存在相同的问题, 由于投票的随意性, 支持率并不一定能够充分表达用户的情感强弱。如评论⑦并没有获得任何的反对票或赞成票, 而评论⑧在63位投票者中获得高达57票的赞成票, 但从情感分析的可用性来说, 评论⑦的质量高于评论⑧。此外, 部分评论并没有获得用户的投票, 因此也就无法利用评论支持率进行质量判断和模型构建。
综上所述, 除评论者活跃度和评论支持率两个指标外, 涉及产品词汇数量、评论长度、修饰词数量以及情感表达强度4个指标都对评论质量级别产生了影响, 可以成为判断评论质量的依据。
不同指标对评论质量的影响程度不同, 因此, 可利用多元线性相关方程来构建过滤模型, 从而为不同的指标赋予不同的权重。在构建过程中, 本文剔除了两个错误指标, 即评论者活跃度和评论支持率, 以使得体系更加合理。最终构建的过滤模型如下:
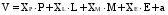 | (1) |
其中, V表示评论的价值, Xi(i=P, L, M, E)表示相应指标的权重, P、L、M、E分别表示各项指标的量化值, P表示涉及产品词汇的数量, L表示评论长度, M表示修饰词数量, E表示情感表达强度。a为常数, 用于模型调整。V越大, 表明评论的质量越高, 越适用于情感分析。
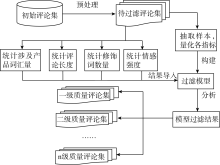
本文中评论过滤的过程如图2所示:
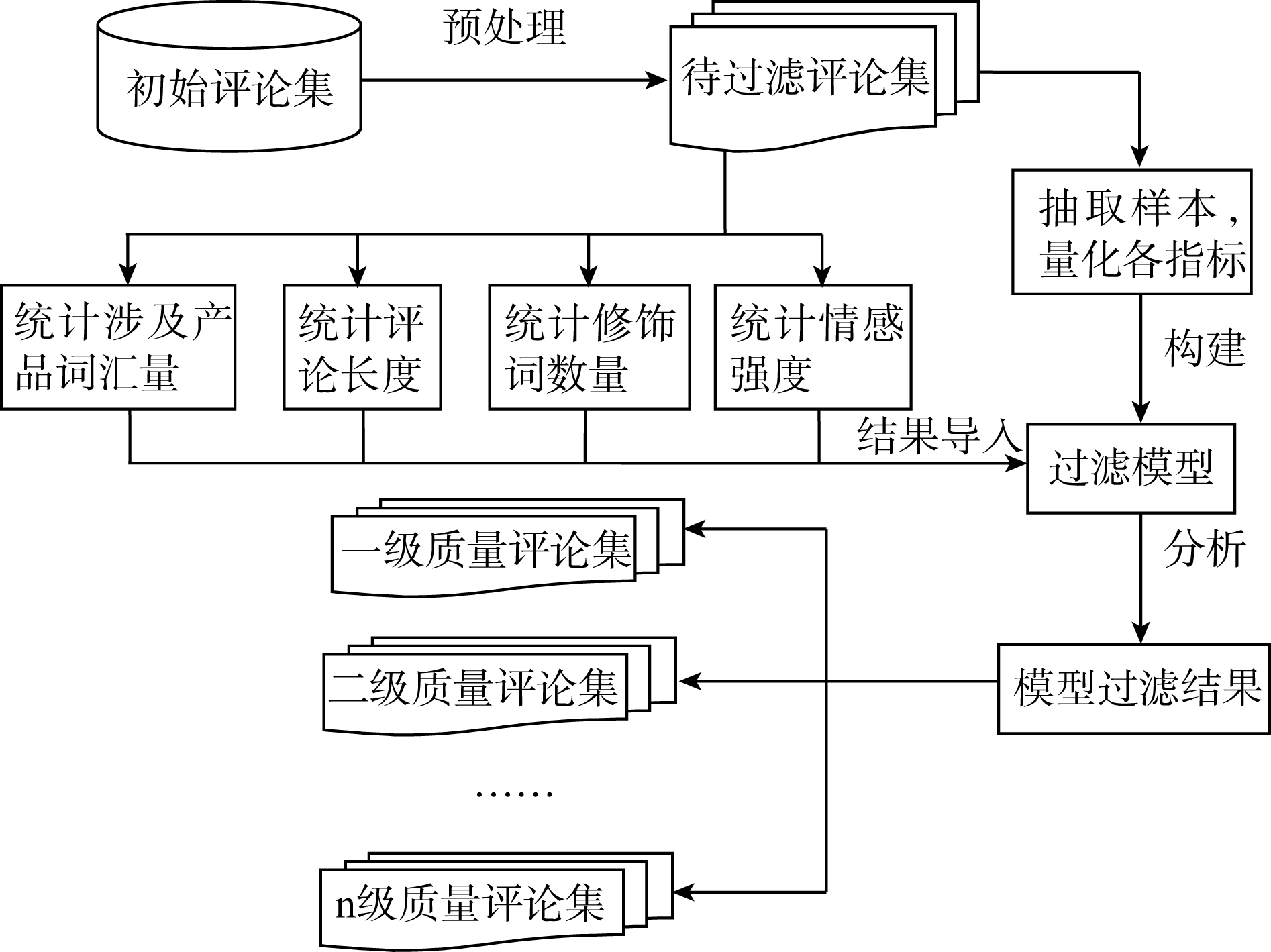 | 图2 评论过滤过程 |
如图2所示, 首先利用抓取程序获取初始评论集, 预处理后可得到待过滤评论集。接着, 可从待过滤评论集中抽取部分样本进行指标量化, 并构建过滤模型。待过滤评论集中的评论在统计完各指标值后, 将结果导入模型。最后, 利用模型的过滤结果即可筛选出不同质量等级的评论集。
根据上述过滤过程, 本文设计了实验进行模型构建与测试。
本实验所分析的数据是来自于亚马逊商城和京东商城上用户对iPhone4(黑色、白色)的商品评论。通过抓取程序, 获得商品评论共2 346条, 剔除针对购物网站本身(即亚马逊)或包含乱码的评论后剩下1 598条。这些评论在经过预处理后, 根据情感分析任务的需求被分成4个级别。如果一条评论能够强烈地表达用户对产品的观点, 对产品的表述恰当详尽, 特别适合用于情感分析, 则赋予4分; 如果一条评论能够表达用户对产品的强烈感受, 或者涉及部分产品表述, 适合用于情感分析, 则赋予3分; 如果一条评论中能够表达用户的使用感受, 但几乎不涉及产品的表述, 一般适用于情感分析, 则赋予2分; 如果一条评论不涉及用户的情感表达, 或用户的表达较为简单, 信息量极少, 又或者所谈论的东西与产品无关, 不适合用于情感分析, 则赋予1分。通过不同分值的表示, 能够直观地判断不同质量等级的评论, 得分越高的评论, 质量越高。逐一对比打分后可得到如表3所示的评论质量等级列表。实验过程从中抽取了1 000条评论用于模型训练以及随机抽取部分评论用于测试过滤效果。
| 表3 评论质量等级列表部分数据 |
本实验使用了作为训练数据的1 000条评论, 并以评论质量等级为因变量, 涉及产品词汇量、评论长度、修饰词数量、情感强度4个指标值为自变量进行分析。根据表1的指标量化方式统计得到每条评论各个指标的量化值后, 该过程利用SPSS构建多元线性回归方程, 从而得到模型中的参数。
由表4及表5可知, 回归平方和为585.572, 残差平方和为269.227, Sig.<0.05, 可以认为所建立的回归方程有效。常数及4个指标变量的显著性均十分明显(Sig.<0.05), 故所构建的方程为:
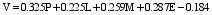 | (2) |
| 表4 方差分析表 |
| 表5 回归系数表 |
将评论的指标量化值导入上述模型(2)后, 得出的V值即为其质量得分。由于人工对各指标赋值存在的误差, 因此在误差允许的范围内, 质量级别为X的评论得分为[ X-0.75, X+0.75 ]。
为了验证该模型的准确性, 随机选取598条评论作为测试数据导入模型进行测试, 并将输出结果与人工判断结果相比较。测试数据仍采用与训练数据同样的指标量化及评分方式, 从而保证结果的可信度与一致性。
实验过程通过召回率和准确率[ 14]来说明该模型的过滤效果。两者计算方式如下:
 | (3) |
 | (4) |
模型过滤结果的召回率及准确率如表6所示:
| 表6 实验结果的召回率及准确率 |
如表6所示, 从召回率来看, 最高达到83%, 最低达到65%以上; 从准确率看, 最高能达到100%, 最低也不小于70%; 平均召回率达到76.90%, 平均准确率达到83.81%。总体来说, 召回率及准确率均达到较满意的水平。由此可见, 所构建的模型对评论质量的判定具有较好的效果。
用户评论是情感分析研究的重要数据来源。本文分析了用户评论的特征并构建了一个用于过滤用户评论的模型。构建过程中, 着重选取涉及产品词汇量、修饰词汇量、评论长度以及情感表达强度4个指标, 并证明了这些指标在面向情感分析的评论质量识别中确实有较大的影响。利用这些指标, 通过多元线性回归的方法可以构建评论质量的过滤模型。将各指标的量化值导入该模型后, 能够得到评论的质量得分, 从而可以识别评论的质量级别。实验阶段采用亚马逊网站的用户评论验证该过滤模型的真实效用。利用该过滤模型, 可获得更高质量的网络用户评论, 从而为今后网络用户评论情感分析任务的开展提供良好保障。后续的研究工作可在以下两方面进行改进: 一是根据情感分析任务的需求调整判断指标的权重, 使得模型的筛选结果更加符合实际需要; 二是进一步完善指标量化的评分方式, 以提高模型判断的准确性。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|