{kind=link}
面向供应链的产品评论中客户关注特征挖掘方法研究*
[郝玫 , 王道平]
, 王道平]
, 王道平]
|
|


作者贡献声明:
郝玫: 提出研究命题, 设计研究方法, 采集数据和进行实验, 论文起草;
王道平: 分析数据和最终版本修订。
【目的】针对电子商务平台的中文产品评论, 提出一种面向供应链的客户关注特征挖掘方法。【方法】以产品评论数据预处理方法为核心, 改进关联规则挖掘产品特征方法。预处理技术包括产品评价概念树、产品评价特征库和MA_Apriori算法。数据实验以京东商城平板电脑为例, 在Weka环境中完成客户关注特征的挖掘。【结果】实验表明, 对于相同的事务文件, 采用数据预处理再进行关联规则的产品特征挖掘, 特征查全率为90.5%, 而关联规则挖掘方法查全率仅为71.4%。并且本方法可实现产品特征挖掘结果的层次化和规范化。 【局限】需要进一步补充汉语分词系统的用户词典, 添加产品领域相关的专业词汇, 以提高分词准确性。【结论】本方法有助于供应链各节点企业灵活选择产品评价概念层次, 从而有针对性地实施产品改进和服务提升。
[Objective] This paper proposes a customer focus feature mining method oriented supply chain.[Methods] The association rule mining is improved by adding data preprocessing, which includes product evaluation conception tree, product evaluation feature database and MA_Apriori algorithm. Based on the data of tablet PC of Jingdong Mall, the data experiment mines the customer focus features in Weka.[Results] The experiments show that the recall radio of new method is 90.5%, but the association rule method is 71.4%. In addition, it can get the hierarchical and standardized products features.[Limitations] Considering the accuracy of word segmentation, the user dictionary of segmentation system needs to be replenished by adding the product professional vocabulary.[Conclusions] This paper can help each enterprise select the product evaluation conception hierarchies flexibly, then improve the qualities of products and service.
电子商务的蓬勃发展使网上购物成为人们的日常消费模式, 产品在线评论作为用户体验的反馈信息, 以其获取方便且成本低廉的优势, 已逐渐成为潜在顾客挑选商品的重要参考依据。这也启示网络时代的企业要更多掌握情报收集工具的应用并注重分析消费者的线上言行[ 1]。
评论挖掘正是以获取产品评论中的有用信息为目标的一种非结构化数据挖掘技术, 它主要包括4个子任务: 产品特征挖掘; 挖掘关于产品特征的评论观点; 判断评论观点的情感倾向; 挖掘结果的汇总及排序[ 2]。其中, 产品特征挖掘是通过分析海量的客户评论, 获取用户最关心的产品特征。通过在线评论中产品特征的挖掘管理, 企业能以低廉的成本获取客户最感兴趣的功能和最希望改进的性能。
就目前产品特征挖掘的研究现状来看, 主要存在 两个方面的问题: 缺乏系统的方法指导评论语料库的数据预处理工作; 挖掘结果多是针对产品评论特征的无层次集合展示, 不能从供应链角度反映产品特征, 也不能反映出特征间的包含和隶属关系。基于此, 本文研究面向供应链的产品评论中客户关注特征的挖掘方法, 在数据挖掘的数据预处理方法的指导下, 研究实现评论数据规范化、层次化的预处理方法, 并基于关联规则挖掘产品的客户关注特征。
产品特征的提取方法主要包括人工定义方法和自动提取方法两种。
Kobayashi等[ 3]提出汽车的产品特征提取可以采用人工定义方法, 并建立了287个产品特征, 特征的表示形式采用三元组。姚天昉等[ 4]对于汽车领域的产品特征的提取, 主要基于本体知识。Zhuang等[ 5]主要分析电影的产品特征, 也采用人工定义方法, 将电影的产品特征分为电影的元素和电影相关的人员两类。人工定义方法最大的缺陷是不具有移植性, 即产品功能发生变化时, 只有领域专家才能完成产品新特征的补充[ 6]。
自动提取方法可实现语句中产品特征的自动识别, 可借助词性标注、句法分析等自然语言分析技术。这种方法的优点是通用性强, 但也存在正确率可能较差的缺陷。Hu等[ 7]认为产品特征有直接在句子中出现的显式特征, 还有需要经过语义理解才能产生的隐式特征。隐式特征由于不能做到语义的完全理解, 其技术还不成熟, 所以显式特征是目前产品特征挖掘研究的主要对象[ 6]。Hu等先对评论语料进行词性标注, 提取每个句子中的名词和名词短语, 通过利用关联规则挖掘方法(Agrawal and Srikant)[ 8]从评论语料中提取满足最小支持度的名词或名词短语, 生成transaction file, 再使用CBA(Classification Based on Associations)[ 9]从transaction file中挖掘出频繁项, 把频繁项作为产品特征候选集。Popescu和Etzioni[ 10]构建了一个非监督式信息抽取系统OPINE, 通过计算点互信息(PMI), 然后进行贝叶斯分类, 从而提取产品特征。
李实等[ 11]考虑到英文的研究成果不适用于中文客户评论的挖掘, 于是在分析中文语言特点的基础上, 提出了中文客户评论的挖掘方法, 该方法借鉴了英文评论挖掘中的关联规则挖掘方法。Wang等[ 12]在标注少量评论训练集的基础上, 构建了产品特征词的朴素贝叶斯分类器, 并将其应用于未标注的评论语料, 从而获得可信度最高的几个产品特征词, 再将其加入初始的训练集, 最后通过Bootstrapping迭代来获取所有评论语料中的产品特征。Zheng等[ 13]不仅把中文产品评论中的所有名词作为候选产品特征, 还使用同现频率, 判定评论中多词构成的特征和可能会被分词误判的词汇, 并将其也作为候选特征。
本文将改进李实等学者的关联规则挖掘方法[ 11], 以评论数据预处理作为核心, 而不是对频繁特征项做剪枝和过滤处理, 这样可以提高原方法的产品特征查全率, 并且实现产品特征挖掘结果的层次化和规范化, 为供应链各节点企业的产品改进和服务提升提供重要信息参考。
本文所提出的结合概念树的产品评论中客户关注特征挖掘方法主要分为两个阶段: 结合概念树的产品评论数据预处理; 基于关联规则提取产品的客户关注特征。
(1) 产品评价概念树的构建
借鉴数据挖掘中的概念层次树这一结构[ 14], 产品评价概念树定义的是面向整个供应链的产品评价领域中的概念层次和隶属关系, 是严格划分层次的树状结构。
定义1: 产品评价概念树
产品评价概念树是一个二元组, 即T={C, HC}。其中C表示所有概念集合, HC(C1,C2)表示概念层次。HC是部分有序集(C, 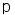


产品评价概念树具有以下特性:
①树的节点表示概念, 树枝表示有序关系。
②有序关系包括包含关系、属性关系、部分-整体关系。
供应链按照核心企业的不同, 可分为供应商驱动、制造商驱动和销售商驱动三种类型[ 15]。本文研究的是销售商驱动的供应链, 供应链各环节下位概念的归属原则遵循产品参数归属供应商、客户服务归属销售商的基本原则。
面向供应链的产品评价概念树的构建方法分为4个步骤:
①概念树的根节点为供应链总概念, 称为第0层概念。
②概念树的第1层概念为供应链的组成环节, 选取典型供应链的组成环节: 供应商、制造商、分销商和零售商。
③概念树的第2-n层概念为供应链各环节的下位概念。按照本体复用的思想[ 16], 可提取产品参数中的概念作为供应商概念的下位概念, 提取服务项目中的概念作为零售商概念的下位概念。
④通过学习产品评论数据, 完成评论数据中概念的提取、清理及同义词合并, 形成用户评论概念集合, 以确定用户评论概念集合与步骤③所得概念的有序关系。用户评论数据的选取遵循以下原则: 数据覆盖面要广, 同产品类别至少5个不同品牌, 至少5 000条评论数据; 评论数据有效, 即评论要含有产品特征。
产品评论数据中概念的提取、清理及同义词合并:
①评论页面下载: 采用聚焦爬虫技术[ 17]。
②评论内容抽取: 利用正则表达式技术可将单纯的文本评论数据提取出来。
③中文分词: 采用中国科学院计算技术研究所开发的汉语分词系统ICTCLAS。因为从评论内容中抽取的产品特征通常为名词, 所以只需保留名词成为词性标注集合。
④概念同义词合并: 在哈尔滨工业大学同义词词林扩展版的基础上, 设计同义词合并算法SCA(Synonyms Combined Algorithm)。
同义词合并算法SCA的具体步骤如下:
1) 在中文分词后的名词词汇集W中, 去掉重复词, 形成初始词汇集IW, 其中的词汇按照拼音排序。
2) 依据哈尔滨工业大学同义词词林扩展版, 建立词汇集IW中每个词的同义词序列SL(Synonyms List)。
3) 比较每个词汇的SL及其后的各词汇序列, 若二者有两项以上的词相同, 则合并为一个序列, 如此遍历整个词汇集的同义词序列, 生成新同义词序列SL’。
4)将SL’转换成标准词-同义词列表[一个二元关系S_S {SW, SL}, SW(Standard Word)为对应同义词序列的标准词]。每一序列中词频最高的为标准词, 其他为该词的同义词。
⑤概念分类: 对标准词-同义词列表S_S中的SW进行分类, 此阶段需请产品领域专家参与。
产品评价概念树的构建采用本体构建工具Protégé实现。
(2) 产品评价特征库的构建
定义2: 产品评价特征库
产品评价特征库是一个二元关系, 即FD{LN, CN}, 其中LN为概念层次编号(Level Number), CN为概念名称集合(Concept Name), CN∈C。
产品评价概念树到产品评价特征库的转换规则为:
①概念树第0层概念为产品供应链总概念, 转换到产品评价特征库时, LN=0, CN为概念名称。
②概念树第1层概念为供应链各环节概念, 转换到产品评价特征库时, LN= 
③概念树第2层概念为供应链各环节概念的下位概念, 转换到产品评价特征库时, LN= 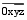


④概念树的第3层至第n层概念转换规则以此类推。
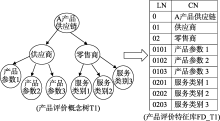
将建立的产品评价概念树生成产品评价特征库, 并将产品评价特征库以关系表的形式存放。图1为产品评价概念树T1到产品评价特征库FD_T1的转换过程。
 | 图1 产品评价概念树T1到产品评价特征库FD_T1的转换过程 |
(3) 产品评论特征词到产品评价特征库的映射
因待挖掘的产品评论内容是网页形式, 故先要完成数据清理, 再进行数据到评价特征库的映射。数据清理后评论数据的存放形式是一个序列表, 一条评论为一个名词序列, 这称为不规范评论词序列表NSR(Non-Standard Review)。接下来需要完成各评论特征词到评价特征库的映射。
映射算法MA(Mapping Algorithm)的具体描述如下:
①规范评论词序列表。将NSR中的每一条评论词与标准词-同义词列表S_S中的SL和SW对照, 若能在SL或SW中找到该评论词, 就替换为标准词, 否则保留原词, 从而得到规范评论词序列表SR(Standard Review)。
②将规范评论词序列映射到评价特征库。对于SR中的评论词, 通过遍历产品评价特征库FD中的概念名称集合CN, 若能找到与其相同的概念名称, 则用对应的概念层次编号LN代替, 否则删除该评论词。最终得到全部用LN表示的映射后的评论特征词序列表MRF(Mapping Review Features), 每条评论为一个序列。
本文基于关联规则提取产品的客户关注特征, 是在数据预处理中的MA算法的基础上创建关联规则事务文件, 然后再采用Apriori算法提取频繁规则项, 并转为客户关注特征, 所以将其合称为MA_ Apriori算法。
(1) 基于数据预处理中的MA算法创建关联规则的事务文件
事务文件以句子为单位, 一行语句中的名词和名词短语是一个事务, 每一个名词和名词短语是事务中的项, 事务文件用关系数据库表存放, 属性列为评价特征库中的所有CN名称。例如: “外观/n 电池/n 速度/n 屏幕/n 色彩/n”是事务文件中的一个事务。通过数据预处理方法中的MA算法, 完成各评论特征词到评价特征库的映射, 得到全部用LN表示的映射后的新的事务文件。如上述评论语句中的项经过MA算法后, 映射结果为: “010104, 0108, 010205, 0103, 01030501”。
(2) 采用Apriori算法提取频繁规则项
一般来讲, 关联规则的挖掘分两步: 预定义的最小支持计数, 找出所有的频繁项集; 由频繁项集生成强关联规则。在评论的产品特征挖掘中, 不需进行第二步, 因为产品的客户关注特征决定了只需挖掘出满足设定的最小支持度的频繁规则项。本文挖掘产品的客户关注特征将采用Apriori算法, Apriori算法规定参数设置采用的最小支持度为1%, 即将事务数据库中平均100个事务中至少出现过一次的项集作为频繁项集; 同时, 采用英文评论的商品特征挖掘中的解决方法, 将不考虑三维以上的频繁项集[ 18]。
(3) 频繁规则项转换为产品的客户关注特征
经上述Apriori算法挖掘后的频繁项集将构成一个以LN编号表示的特征集合, 需将其转换为产品评价特征库中的概念名称才具有直观性, 但转换前必须按LN编号的层次进行概念的层次划分。
①将特征集合中的LN编号按位数不同分为不同子集合。例如: “010104, 0108, 010205, 0103, 01030501”可分为“0108, 0103”, “010104, 010205”, “01030501”。
②将特征集合中位数多的LN编号转为位数少的LN编号, 可向上层LN编号转换。例如: 将“010104, 010205, 01030501”转换为“0101, 0102, 0103”。
经过划分特征集合的层次子集, 明确挖掘出的客户关注特征所在的概念层次, 从而解决特征无层次的问题, 并可实现概念的泛化, 反映出客户所关注的供应链中节点企业的产品相关信息。
以京东商城平板电脑的产品参数、服务类别和8个品牌22 142条评论数据为基础数据, 经过数据预处理后得到的平板电脑评价特征库如表1所示。
选取京东商城平板电脑华硕(ASUS)EeePad TF101标准版的300条客户评论进行提取客户关注特征的实验。基于产品评价特征库和映射算法MA, 得到的待挖掘特征为135项, 所以建立的关联规则事务文件为300行135列的MySQL数据库表。
| 表1 平板电脑评价特征库(部分数据) |
本文在Weka环境中完成Apriori算法对频繁规则项的挖掘, 整理频繁项集后得到LN编号的客户关注特征如表2所示:
| 表2 LN编号的客户关注特征 |
对于相同的事务文件, 若采用参考文献[11]中的方法, 不经数据预处理而直接进行关联规则的产品特征挖掘, 得到的特征数量为15, 查全率为71.4%。而本文方法的查全率为90.5%(真实的产品特征以人工标注的特征数量为准), 可见本方法确实可以提高挖掘效率和知识发现的准确性。
按照层次不同, 可以灵活对客户关注特征进行各层的划分, 表3完成的是第3层的客户关注特征提取。
| 表3 第3层的客户关注特征 |
在对产品的客户关注特征进行面向供应链(销售商驱动类型)分析时, 可从以下几个方面展开:
(1) 供应商的产品特征分析
客户对供应商的哪些产品特征最为关注, 将反映在挖掘到的特征集合中LN编号前两位为01的所有特征中。供应商可对客户关注的产品特征从多个角度进行分析, 一方面, LN编号位数最多的特征是产品划分最细的特征。例如: 挖掘结果中的“01090103”, 对应的是产品规格中的“厚度”, 这表明用户对该产品的厚度较为关注, 供应商应在厚度上加强质量监管或提升研发技术。另一方面, 能将LN编号位数多的特征向上层概念泛化。例如: 挖掘结果若为“010104, 0108, 010205, 0103, 01030501”, 如果选择第2层, 那么结果可转换为“0101, 0108, 0102, 0103, 0103”, 对应的具体特征名称是“主体, 电池, 配置, 主体, 主体”。
(2) 核心企业的服务分析
客户对销售商的哪些产品服务最为关注, 可以在挖掘得到的特征集合中查询LN编号前2位为02的所有特征。销售商能从多个角度对客户关注的服务特征进行分析, 一方面, LN编号位数最多的特征是具体的服务环节或服务质量。如“02050101”, 对应的是产品服务中的“换机手续”, 这将帮助销售商调整售后环节换机手续的服务流程和条款规定。另一方面, 也能将LN编号位数多的特征向上层概念泛化。
(3) 核心企业的供应商选择分析
挖掘出的产品特征可实现整个供应链的知识共享, 这为核心企业选择供应商提供了重要的信息参考。一方面, 核心企业可以从客户关注的产品特征中了解消费者的购物侧重点, 从而择优挑选供应商, 迎合顾客的需求。例如: 若评论挖掘结果显示客户关注“外观”, 某供应商的产品外观时尚, 那么该供应商就可纳入核心企业的合作伙伴。另一方面, 挖掘出的产品特征也可帮助核心企业随时对合作的供应商做出调整, 促使其完善产品或者提升服务水平。
本文以非监督方法为主, 基于概念树的产品评论数据预处理, 在对数据进行规范和分层后, 采用Apriori算法, 对面向供应链的产品的客户关注特征进行了数据挖掘及实例分析, 并验证了方法的可行性和有效性。
产品的客户关注特征是面向整个供应链的产品评论最集中和最热点的特征, 但每项特征具体的评价倾向性还需进一步分析和处理, 今后的研究重点是通过提取客户对每项关注特征所持有的褒贬态度, 定量表示其评价情感倾向性, 实现由评价语句的模糊表达形式向数量化评价倾向的转换。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|