

{kind=link}
{kind=link}
{kind=link}
{kind=link}
机构知识库语义知识获取方法分析及实验研究*
[王思丽 , 祝忠明, 姚晓娜]
, 祝忠明, 姚晓娜]
, 祝忠明, 姚晓娜]
|
|


作者贡献声明:
王思丽, 祝忠明: 提出研究思路, 设计研究方案;
王思丽, 姚晓娜: 进行实验; 从IR GRID中采集、抽取和分析数据;
王思丽: 论文起草和最终版本修订。
【目的】通过分析总结和实验研究, 提出并形成一种有效的语义知识获取方法, 为实现机构知识库的语义化提供理论基础和可行技术路线。【方法】对国内外的语义知识获取方法进行对比分析, 提出机构知识库语义知识获取的体系框架, 并总结和深度解析其关键技术; 同时, 以中国科学院机构知识库平台为例进行实验研究。【结果】该方法可有效地从机构知识库底层的关系数据库的数据和实体关系结构中自动获取语义知识信息并转化为RDF三元组形式进行浏览和查询。【局限】定义一个合理有效的语义映射规则, 需要经过领域专家评估、较多的人工干预以及反复实验才能确定; 不同机构知识库间同一实体对象的语义知识获取关联没有涉及。【结论】有利于帮助后续研究人员和机构知识库开发人员更好地了解和掌握机构知识库语义知识获取的方法和关键技术, 从而为提升机构知识库的服务能力奠定基础。
[Objective] The paper proposes and forms an effective method of semantic knowledge acquisition through analysis, summary and experiment, in order to provide theoretical principle and possible technological route for the semantization of Institutional Repository.[Methods] Based on the contrastive analysis of methods of semantic knowledge acquisition both at home and abroad, the paper proposes a system framework of semantic knowledge acquisition for Institutional Repository, and sums up its key technologies for deep analysis and then takes the CAS IR GRID for an experimental study.[Results] This method can automatically and effectively acquire semantic knowledge information from data and entity relationship structure of relational database of underlying Institutional Repository and convert it into RDF triples for browse and search.[Limitations] To define a reasonable and effective mapping rule may need domain expert evaluation, more manual intervention and repeated experiments. The semantic knowledge acquisition and relevance study for the same entity object between different Institutional Repository is not involved in this paper.[Conclusions] This study may better help follow-up researchers and developers quickly understand and master the method and key technologies of semantic knowledge acquisition, then lay the foundations for enhancing knowledge service capabilities of Institutional Repository.
机构知识库(Institutional Repository, IR), 是研究机构实施知识管理的重要工具, 如何增强其知识服务能力成为近几年来图书情报界的研究热点。语义知识获取[ 1]是指通过一定的理解、分析、筛选、归纳或转化过程将用于问题求解的核心专业知识从源知识库中提炼出来, 转化为计算机可理解的形式的过程。它是机构知识库语义化的核心技术之一, 由于其存在一定的技术难度, 成为长期以来阻碍机构知识库服务能力提升的瓶颈。有效的语义知识获取方法可以推进机构知识库的语义化发展, 加速机构知识库和语义网的开放关联, 大大提升机构知识库知识服务应用的深度和广度。
本文在对国内外知识获取技术的发展现状进行调研分析的基础上, 结合前人的研究工作, 重点归纳和解析机构知识库语义知识获取的方法和关键技术: 首先, 以W3C的RDB2RDF指南标准为技术思路, 提出了机构知识库语义知识获取的体系框架, 并将其关键技术归纳为三个层次——关系数据库语义逆向获取技术、ER模式与知识本体的语义映射技术、数据记录的语义映射技术进行具体分析说明; 其次, 以中国科学院机构知识库平台CAS IR GRID为例进行实验, 并对实验结果及存在的问题进行分析和讨论。本文旨在通过分析总结和实验研究, 提出并形成一种有效的机构知识库语义知识获取方法, 从而为后续研究和推进机构知识库的语义化发展提供理论基础和可行技术路线。
知识获取技术是以人工智能和机器学习的方法为核心, 并结合统计分析方法、模糊数学方法、科学计算可视化技术、模式识别技术等多种方法发展形成。目前, 主要有以下三大类:
(1) 基于OLAP的知识获取方法
该方法是最早的具有代表性的并得到广泛应用的知识获取方法。联机分析处理(OnLine Analytical Processing, OLAP)[ 2], 主要是指通过多维系统化方法对数据仓储中的数据进行切片、钻取、切块、旋转等进行在线分析以获取信息的过程。它的局限性是缺乏对大量数据进行归纳以获取一般性规律知识的能力。
(2) 基于文本挖掘的知识获取方法
该方法适用于源知识库中包含大量文本的情况。其知识获取方法主要依赖于自然语言处理技术, 通过对单文本进行句法、结构分析和对多文本进行关联、聚类分析等建立基于语法的获取规则从而获取结构化的知识如概念、知识图谱和对象等。但因为不同的文本信息中包含很多模糊的事实定义和多层次的词汇歧义, 是一个多学科混杂的领域, 需要建立比较完善的大规模语料库进行辅助处理, 知识获取的复杂性很高。代表性的工具有TSIMMIS[ 3]、WHISK[ 4]、KnowItAll[ 5]、CluxTex[ 6]等。
(3) 基于本体的知识获取方法
该方法是语义网产生之后, 针对语义网提出的最核心的知识获取方法。基于本体的知识获取方法是一个良性循环的过程, 一方面, 可以利用本体来指导传统的知识获取过程, 另一方面, 又可以把获取到的知识进行语义标注后与语义网开放关联, 方便以后进行自动化的语义知识获取。本体驱动的知识获取方法, 不仅有助于增强知识库自身的能力建设, 更有助于发展语义网, 加快知识获取的步伐。但基于本体的知识获取方法其局限性在于某一领域的本体一般由相关领域的专家创建, 设定的本体关联规则只适用于特定的领域, 对于多学科多类型交叉的领域, 很难具有通用性和普适性。
例如Cheng等[ 7]提出了一种基于本体对知识库文本进行分类的方法, 其基本思想是利用本体对文本中的领域知识进行预处理后再进行语义分类, 用户背景和兴趣都通过本体模型反应出来, 这有利于知识库分类结果更满足用户的个性化需求。同时, 他还提出了一种基于上下文的自由文本翻译机器对句子进行语法分析和对词语进行语义处理, 有利于分类结果与用户的背景知识相关。再例如Khasawneh等[ 8]提出了基于用户和本体的知识库日志预处理算法用于进行用户识别。该算法构建了一个知识库本体, 从语义层面上分析知识库结构以及用户访问行为的断点, 进而通过IP地址和用户的非活跃时间来实现对用户的语义识别。
从本质上来讲, 以上三种方法都是从知识库中挖掘信息, 所获取的知识类型包括模型、规则、类别、关系和约束等。但相对于方法(1)和方法(2), 基于本体的知识获取方法更倾向于对知识的理解和转化, 更能挖掘到潜在的隐含语义信息, 具有系统相关性和语义一致性, 更符合语义网对知识组织的需求, 因而对研究机构知识库语义知识获取具有指导性作用。
机构知识库的语义知识获取与一般基于HTML或基于Web的语义知识获取过程相比, 数据结构和关系比较稳定, 数据模式比较规则化, 省去了数据清洗的过程。目前, 关系数据库是几乎所有的机构知识库的数据存储基础, 因而研究从机构知识库底层的关系数据库中获取语义知识, 显得非常重要。而本体是语义的基础, 如今, 有关从关系数据库中获取语义本体的研究工作, 正随着本体语义标注技术的发展而逐渐引起高度关注。
Volz等[ 9]提出了一种深度标注方法, 设计了从关系数据库中直接或间接生成语义元数据的框架, 并可以根据该框架直接对数据库模式或依赖于该数据库模式生成的动态网页进行语义标注, 从而实现将存储在关系数据库中的历史数据向语义网进行映射和移植。
Astroval[ 10]从数据库逆向工程角度出发, 通过深入分析关系数据库中主键、外键、数据、属性的关联关系提出了从关系数据库中获取本体的新算法。该算法可以继承关系数据库关系和优化数据结构, 从而在不需要用户干预的情况下获取较为丰富的语义知识。
Xu等[ 11]提出了一种将实体关系模式ER转换为OWL本体的形式化算法, 并开发了软件工具自动地实现转换过程。该方法首先将ER模式转换为XML格式, 然后根据预定义的ER模式与OWL本体之间的映射规则, 将ER模型翻译成基于RDF/XML语法的OWL本体形式。
Bizer等[ 12]提出了利用D2RQ映射语言和D2R Server工具通过将关系数据库表和字段关系映射为本体中的类或属性从而转化为RDF数据形式进行发布的方法。该方法已经成为被国内外学者应用最广泛的语义知识获取方法之一。
由于缺少一定的标准规范, 各种自定义的映射语言和规则互不相通, 为语义知识库之间的互操作带来了难题, 影响了语义获取的自动化。鉴于这种情况, W3C的RDB2RDF工作组经过多番调研之后, 于2012年正式发布了DM (Direct Mapping)和R2RML (RDB2RDF Mapping Language)两种映射语言作为推荐标准[ 13], 该映射语言吸收了过去研究工具如D2RQ和相关实体关系转换算法的众多成果, 成为目前关系数据库语义知识获取的指南标准。下文就是以该指南标准为技术思路, 以前人的研究工作为基础, 深入剖析机构知识库语义知识获取的方法和关键技术。
根据前人的研究工作进行总结发现, 机构知识库语义知识获取过程的起点一般是机构的关系数据库, 终点是语义知识模型, 如RDF模型、基于XTM(XML Topic Maps)的知识表达模型等。其中的体系框架如图1所示:
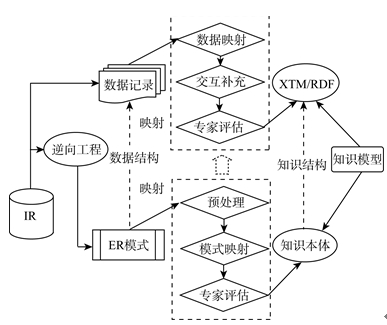 | 图1 语义知识获取的体系框架 |
整个过程大致可以分为三个阶段:
(1) 数据库逆向工程阶段
该阶段也对应了RDB2RDF标准规范中R2RML工作机制的“Input Database”阶段。在这个阶段中, 需要根据已有的关系数据库结构, 逆向推理出其内在ER模式。
(2) ER模式向知识本体映射阶段
该阶段对应了R2RML的“R2RML Processors and Mapping Documents”, 即映射规则的产生过程。这个阶段是整个语义知识获取过程的核心, 实现了ER模式和本体这两种语义知识表示结构之间的过渡和转换。
(3) 数据库记录向知识模型的映射阶段
该阶段对应了R2RML的“Output Dataset”, 是本体的实例化阶段。需要按照阶段(2)中的本体语义知识结构重新组织关系数据库中的数据记录, 是一个数据映射和交互补充的过程。
(1) 关系数据库语义逆向获取
从机构知识库的底层关系数据库中, 首先可以直接获取的信息是: 表定义和表的数据记录。通过对其解析, 可以识别出ER模式中重要的语义信息。以中国科学院机构知识库平台CAS IR GRID[ 14]为例, 它的一个完整的SQL语句的书写格式通常如下:
CREATE TABLE IR_table_name (
Column_name column_type
[NULL|NOT NULL][UNIQUE][DEFAULT value]
[column_constraint_clause|PRIMARY KEY [...]]
[,...]
[, PRIMARY KEY(column_name [,...])]
[, FOREIGN KEY (column_name) REFERENCES IR_table_ name(column_name) [,...]]
[, CHECK (condition)]
[, table_constraint_clause]
);
从上述定义中, 可以获取到主键、外键(表之间的关系)、表属性和完整性约束等信息。通过对其进一步分析, 识别出各种结构性元素, 然后分别在映射本体中进行定义, 为下一步的ER模式与本体映射做准备。以FOREIGN KEY为例, 它一般定义了两个表之间的显性关联关系。如果一张表没有定义外键, 则可在本体中定义该表为空关系。空关系表明该表语义独立。再如若某表T1的某一主键字段是表T2的外键, 并且该外键是在表T2的主键集合中, 则表T1和表T2具有关键性依赖关系。转化为映射本体中的定义方法如下:
(define-relation KeyRelation(?t1, ?t2)
: def(and(instance-of ?t1 SQL-CAS_Table)
(instance-of ?t2 SQL-CAS_table)
Existing ?x (=> and ((instance-of ?x SQL- Column)
(is_key ?x ?t1)
(is_foreignkey ?x ?t2)
(member ?x (keylist-of ?t2 ))))))
表数据逆向获取语义主要是指对两个或多个表中的数据记录进行分析, 获取隐性语义关系的过程。因为主键属性集一般反映了数据库表记录的唯一性, 所以一般选取主键属性值域集关系作为获取语义的目标数据集, 以一些非主键属性值域集作为补充。主键属性值域集的关系一般有相等、包含、相交和分离(Disjoint Relation)4种。整体过程如图2所示, 转化方法同上。
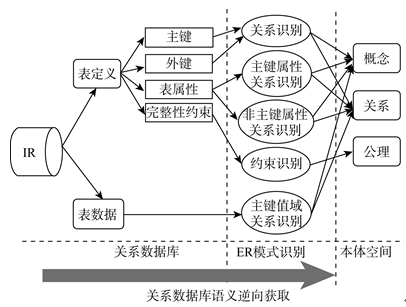 | 图2 关系数据库语义逆向获取 |
(2) ER模式与知识本体的语义映射
经过上述的语义知识逆向获取过程, 将数据库中的表转化为构成ER模式的各种结构性元素, 然后以这些结构性元素为基础, 实现ER模式与知识本体间的语义映射。整个过程可分为4个阶段:
① 预处理
主要用于过滤掉ER模式中仅用于消除关系模型中结构性限制或其他管理原因而存在的ER元素。这些元素与ER模式的语义无关, 过滤掉它们将有助于提高后续映射的效率。这个过程需要人工干预进行处理。
② 表关系映射
根据语义逆向获取得出的显性关系和隐性关系, 执行经匹配而筛选和定义出的表关系映射规则, 生成本体空间中的概念和概念之间的关系, 从而搭建本体的基本框架。
③ 表属性映射
在表关系映射结果的基础上, 根据表属性映射规则将表属性映射到本体空间里概念或关系的属性中。主要包含属性名称和属性类型的映射, 一般采用逐一对应的方式。但对于表主键属性的映射则应该区分该主键是否具有语义, 如果只是SQL中通过递增形式产生的仅仅起到简单的唯一标示符作用、并无有意义的语义的主键属性, 则只在表关系映射阶段做识别表关系用, 在表属性映射过程中需要将其忽略掉。
④ 表约束映射
完整性约束是关系数据库重要的语义之一。表约束映射的目的是实现完整性约束向本体语义知识模型中公理的转换。可分为实体完整性约束、参照完整性约束和用户自定义的完整性约束。实体完整性约束主要是针对表的主键属性, 如约束主键属性不能为空, 并且不能取重复值等。在CAS IR GRID SQL表定义中是以PRIMARY KEY来识别的。当然, 实体完整性也可以定义其他任意一列不能取空值或重复值等, 可通过SQL表定义中的NOT NULL、UNIQUE等关键字来识别。参照完整性约束一般包含两层含义: 其一是指两个表的主键和外键的数据应对应一致, 即外键取值只有两种情况, 要么为空, 要么取参照表中的主键值; 其二是当对表进行修改而违反第一层参照完整性约束时需要采取的限制性修改策略, 以及当参照表的数据记录发生变化时, 被参照表中相应外键对应的数据采取的适应变化策略。用户自定义完整性约束主要是指用户通过在SQL语句中定义CHECK字句而形成的条件表达式来约束表属性值域的取值范围, 或约束表属性之间的关系。这些都必须要注意到, 从而进行映射。
此后, 如果还存在未映射的表关系, 则返回阶段②, 循环该映射过程, 直到所有的表关系映射完毕。在上述的映射过程中, 自动生成的本体命名空间可能会不一致或者缺失部分命名空间, 为保证获取到本体的有效性和一致性, 必须通过专家评估或人工干预的方法进行二次确认和交互修改。
(3) 数据记录的语义映射
数据记录的语义映射, 是指在ER模式和本体语义知识模型的驱动下, 完成本体实例化的过程, 也是数据记录进行知识重组的过程。主要包括概念实例化和关系实例化两个阶段。主要存在的问题是可能出现一张表中的属性会被划分到多个本体概念中, 或一张表的记录被划分为多个部分, 每个部分也可能被划分到不同的概念中, 更或者是两者结合的情况出现。都需要根据已定义好的映射规则进行分步处理。常用的处理方法是基于Jena或Sesame提供的API进行编程来操作本体映射规则, 批量完成数据记录的映射。
笔者以中国科学院机构知识库平台CAS IR GRID[ 14]为例, 对上述的语义知识获取方法进行了实验研究。CAS IR GRID中主要有机构(各研究所等成员单位)、作者、内容类型(期刊论文、会议论文等)、学科主题等相关实体的表定义以及表数据。为了在有限的时间内量化研究对象, 使得研究对象更明晰更具体, 研究工作更可行, 笔者着重抽取了CAS IR GRID数据库中中国科学院软件研究所的期刊论文200篇(元数据)、会议论文100篇(元数据)进行自动语义转换研究。通过分析其实体关系结构及借助开源工具D2RQ和基于Jena的语义编程进行语义知识获取系统的设计和实现, 定义的映射规则是一个N3格式的RDF序列化文件, 已成功地获取了上述所选择的全部数据的相关语义知识信息并发布为RDF三元组形式进行浏览和查询。一篇会议论文映射后的RDF Data如图3所示:
 | 图3 机构知识库的RDF Data示例 |
根据映射规则进行发布后, 可以通过基于Property和Value的本体形式进行浏览, 如图4所示:
 | 图4 机构知识库的RDF浏览示例 |
目前, 最新版本的D2RQ工具已经能够支持W3C的DM标准映射语言。随后, 笔者又分别以上述数据为例测试了开源工具DB2RDF以及Protégé关系数据库插件DataMaster[ 15], 主要功能是解析IR关系数据库中的Schema Structure, 获取潜在的语义关系, 实验结果大同小异。
当然, 一系列的实验也存在一些问题, 笔者总结如下:
(1) 定义合理的映射规则是机构知识库语义知识获取技术的核心所在。但这又是个难点。就目前的发展来看, 虽然W3C的RDB2RDF工作组发布了标准的映射语言DM和R2ML, 具体的操作仍需要较多的人工干预进行实现, 再加上大部分的映射规则使用的是一种JDK编译生成的配置文件, 当RDB模式发生变化时, 该文件基本都需要重新映射和修改。
(2) 笔者在后续实验研究中还遇到过在通过定义的映射规则利用Jena将整个数据记录映射到知识本体的内存模型中时, 一旦数据量过大, 如超过10万条, 经常会出现内存溢出甚至是服务器宕机的情况。总体来说, 就是映射规则仍存在一定的不可移植性以及非健壮性。然而究竟是映射规则不合理, 还是采用的技术工具有缺陷, 还需要进一步的深入研究。而且一个符合标准语法的映射规则, 不一定是合乎逻辑的。反之亦然。这应当是一个在应用中反复修正的过程。
目前, 中国科学院机构知识库服务网格主要以OAI-PMH接口的形式采集中国科学院各研究所IR的数据, 数据量每天都在快速增长, 截至2013年11月20日, 来源IR有90个, 数据总量已达498 564条。面对如此庞大的数据源和信息源, 仅仅靠传统的由领域专家和知识工程师结合进行人工的知识获取方法已经远远不能满足知识经济时代的需求, 而网络化协同工作环境中大量的知识又经常被存储在关系数据库中, 因此探索如何从遗留系统的关系数据库中获取带有语义信息的知识显得非常重要。本文在大量前人的研究工作和语义本体驱动理论的基础上, 尝试进行基于逆向工程和语义挖掘ER模式的关系数据库语义知识获取的理论和实验研究, 为探索新兴的智能知识获取技术和推进机构知识库的语义化发展提供可行路线。
但同时根据关系数据库逆向工程和ER模式获取到的语义知识是严格依赖于原有机构知识库底层数据模式的, 仅仅限于机构知识库内部的语义知识获取, 生成的语义本体模型也是“内部本体”。如何与外部的语义数据关联起来, 这涉及到了不同本体间对准问题。本体对准研究虽然本文没有涉及, 但也是一个今后必须要深入研究的重点和难点。机构知识库语义知识获取研究的重点是如何“走进来”, 但如何“走出去”也是未来机构知识库向语义化发展必须考虑的问题。只有“怀抱”知识, 带着语义“走出去”, 融进语义网, 才能真正实现机构知识库的语义化, 扩大机构知识库的规模, 最终将机构知识库的服务能力提升到一个新的层次。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|