霍亚勇 E-mail:
413261403@qq.com
作者贡献声明:
李湘东: 提出研究方向和思路, 介绍相关技术的应用;
霍亚勇: 实验流程设计, 实验材料采集及分析, 进行实验;
黄莉: 实验数据分析;
霍亚勇: 论文起草;
李湘东: 最终版本修订。
基金:*本文系湖北省高校图工委基金项目“传统分类体系下多种类型文献自动分类研究”(项目编号: 2012YB02)的研究成果之一。;
Study of Book Pages Automatic Identification and Bibliographic Information Extraction
1 引言伴随着互联网的快速发展, 网络信息逐渐覆盖了政治、经济、文化等各个领域。网页文档本身作为一种信息传递的载体, 丰富人们信息来源的同时, 也给人们获得有用信息带来了极大的困难。面对浩瀚的网络信息资源, 如何有效地抽取网页信息, 帮助用户快速获得所需要的细粒度信息, 已经成为了迫切需要解决的问题。
图书网页是指含有图书的书名、作者、出版社、摘要及ISBN号等书目信息的网页; 不含书目信息或者不含有完整书目信息的任何网页, 本文统称为非图书网页。作为一种获取图书信息的重要渠道, 准确高效的信息抽取技术, 对图书网页的组织、管理和书目信息获取都起着至关重要的作用。对于图书馆的书目信息录入来说, 自动化的信息抽取技术, 不但可以弥补传统手工录入的不足, 节省大量人力和时间, 而且
可以为读者提供更加优质的服务; 对于网络用户来说, 合理地将网络中异构的书目信息进行抽取和集成, 将有利于提高用户体验, 更好地实现图书信息资源共享; 对于出版发行机构、书店以及图书经销商等销售企业来说, 图书作为一种重要的文献类型, 已成为其主要的收集和处理对象, 高效准确的图书信息抽取技术对相关企业具有较强的商业价值。
为了能够准确高效地从网页中自动识别并抽取书目信息, 本文以相关的图书类网页为研究对象, 根据网页的标签使用特征、布局结构以及信息表征, 构建图书网页自动识别及书目信息抽取模型, 通过共现词技术和信息分析方法实现图书网页的自动识别, 并利用页面分析和启示性规则等过滤技术, 自动抽取图书网页中的书目信息。实验证明, 此方法针对来自图书专门性网站和各类一般性网站中的图书网页自动识别和抽取均能取得较为理想的效果。
2 相关研究在网页中, 抽取信息经历了不断进化与完善的过程, 从网页信息抽取的对象角度分析, 其研究多集中在新闻类网页的标题或内容的抽取[ 1, 2, 3, 4, 5, 6, 7]。近些年来对于博客网页的信息抽取也逐渐成为热门的话题[ 8, 9, 10, 11]。随着网络购物的快速崛起, 对于网页商品信息抽取工作的研究[ 12, 13, 14]也具有了时代意义。有效地实施信息抽取工作不仅对中文网页尤为重要, 同时对少数民族网页信息抽取的意义也是不言而喻的, 目前研究成果主要包括文献[15-17]。此外, 对于旅游、医药、农业等领域的网页信息抽取也有部分学者分别做过相关研究工作[ 18, 19, 20]。虽然目前对于网页信息抽取的研究涉及了诸多的对象或领域, 但尚未发现针对图书网页开展书目信息抽取的研究。
从网页信息抽取方法角度分析, 目前的研究主要围绕以下几个方面开展:
(1) 基于网页DOM树分析, 如文献[3,17,18,20]将解析后的树形结构网页根据特定的抽取规则或算法完成信息抽取。
(2) 基于网页结构和视觉特征方法, 如文献[1]充分利用HTML标记和新闻特征, 从发布者对新闻内容的修饰角度出发, 提出了内容分割的抽取算法; 文献[8] 针对博客网页的特点与规律, 提出一种根据网页结构和关键字计算相似度的方法识别博客网页。
(3) 基于统计方法, 文献[6]提出了一种基于统计的方法实现抽取所有的正文信息都放在一个table中的特定情况, 文献[7]提出的基于标记窗(Tag Window)的网页正文获取方法扩大了成果[ 6]使用范围, 有效地弥补了它不能处理非table结构的网页正文提取的缺点。
(4) 结合复杂语义特征和网页结构的方法, 文献[10]充分利用页面中“首页”等指示性短语的特点, 提出利用具有明确语义和功能指示作用的功能语义单元来抽取评论信息的技术, 有效抽取博客评论, 文献[14]充分利用了商品的语义特征和网页结构的表现形式, 提出了一种基于语义熵的节点聚集度判别算法, 生成DOM树; 通过计算语义熵来获取商品的属性标签和其对应的属性值。文献[19]提出了基于多维语义的互联网药品信息提取方法, 通过使用从多个维度描述互联网药品领域语义的语义词典, 发现来自不同网页内容中隐藏的共性信息, 从而获取药品信息。
总之, 对于网页信息抽取的研究已经涉及到诸多领域, 但是这些方法都存在一些不足, 传统的依据特定的数据源或者训练集生成抽取模板来完成信息抽取的方法, 效率较低, 通用性较差; 单独基于视觉特征或统计的方法, 又很难排除网页噪声的干扰; 基于DOM树的方法准确率有了保证, 但是实现过程较为复杂, 时间效率不佳; 结合语义特征和网页结构的方法, 能够准确定位抽取元素, 但是构建词义规则的方法相当复杂。而本文应用的共现词等相关技术具有简单、高效等特点, 能够充分根据图书网页的特点弥补上述方法中的不足之处, 应用于图书网页识别及抽取的相关研究中, 具有较强的实用价值。
图书网页上的信息主要包括两类: 显性知识, 即浏览器直接呈现给用户的可视化书目信息; 隐性知识, 即对信息进行修饰的各类网页标签。因此, 本文充分利用图书网页自身特征, 将显性知识和隐性知识相结合, 提出了一种图书网页识别和信息抽取的方法, 有效地解决了由于网页差异化而难以高效、准确抽取有关图书的书目信息的难题。
3 基于规则的图书网页书目信息抽取3.1 模型主体框架本文研究目的在于图书网页的自动识别和书目信息抽取, 因此, 针对来自图书专门性网站和各类一般性网站等不同来源的图书网页, 首先使用信息分析和共现词技术区分图书网页和非图书网页; 然后对图书网页进行预处理, 过滤无用标签及字符; 最后根据信息抽取规则完成图书网页的书目信息抽取。基本模型框架如图1所示。
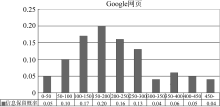
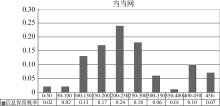
3.2 图书网页的识别通过Google的布尔逻辑与高级检索, 选取能够代表图书网页独有特征的共现词进行检索, 并且认为“图书、ISBN、出版社、价格”共现一次, 则所得网页极有可能为图书网页, 将此类网页进行保留, 以备二次判别, 因此使用此4项关键词获得来自各种图书专门性网站以及各类一般性网站、混合有图书网页和非图书网页的网站上的相关网页数千篇。对其中的部分网页内容进行统计和分析发现, 同时含有该4项关键词的网页中, 70%以上为图书网页。由此可见, 该4项关键词是采用共现词技术实施判别图书网页的基本要素。但为进一步提高图书网页的识别率, 本文同时使用信息分析技术对Google检索出的网页中的显性知识分析发现, 在非图书网页中, 虽然也含有“图书、ISBN、出版社、价格”等4项关键词, 但其相关信息并不完整, 如“ISBN:”、“出版社:”等, 其内容为空值; 在这些非图书网页中出现此类现象的比例高达近80%。而与之相比, 图书网页中仅有不到8%的网页出现了上述现象。除此之外, 它们在网页标签使用特征等方面基本无差别。因此, 利用这一显著特点, 与共现词技术相结合, 可以有效区分图书网页和非图书网页, 达到图书网页自动识别的目的, 在本研究中已达到78%的识别率, 详见实验1。
3.3 图书网页的书目信息抽取(1) 预处理阶段
本文首先针对网页标签进行过滤处理, 删除对图书网页书目信息抽取没有实质意义的标签, 排除噪声干扰, 缩小抽取范围, 为下一步书目信息抽取奠定基础。通过对各类网页结构布局和标签使用特征比较分析发现, 网页标签大致分为以下几类:
类型1: 主体标签, 主要由
和两部分构成, 大量描述网页的其他标签可以嵌套在其中。
类型2: 布局标签, 主要是为合理布局网页而使用的部分标签, 包括
、
< /DIV>、
、
| 等。
类型3: 视觉标注标签, 主要是方便浏览者阅读, 突出重点信息而使用的一类标签, 包括 、 、 、 等。分析发现, 大量的视觉标注标签中基本不会含有主要信息, 这些标签很可能对信息抽取造成干扰, 因此, 可以首先采用顺序遍历的方法, 过滤掉这部分标签; 而对于布局标签, 虽然含有部分网页噪声, 但是绝大部分的主要信息包含在其中, 所以将其保留。
(2) 书目信息抽取阶段
图书网页的信息主要是用来描述图书内容的, 往往具有较长的文字表达篇幅。HTML的主体标签中,
、<KEYWORDS> 、<DESCRIPTION> , 这些标签中的内容高度概括了网页的主要内容, 在图书网页中表现为: 介绍图书名称、作者、出版社等相关书目信息。通过对识别出的图书网页统计发现, 其中85%左右的网页使用<KEYWORDS> 和< DESCRI-PTION >标签准确地描述了图书的基本书目信息, 而且与<TITLE> 标签内容具有高度相关性, 为图书网页书目信息的抽取提供了便利。针对第一步预处理后的结果, 图书网页信息抽取步骤归纳如下:</p><p>①使用正则表达式抽取<TITLE> 、<KEYWORDS> 、<DESCRIPTION> 标签中的信息。</p><p>②对网页源文件按顺序分段截取“>”和“<”中间的内容, 并输出结果。</p><p>③过滤步骤②中截取得到的特殊字符, 得到仅含有标点符号的字符串。</p><p>④删除步骤③结果中的非汉字文本内容, 排除对书目信息抽取可能造成的干扰, 保证了下一步计算字符串长度时, 所统计的为中文字符个数。</p><p>⑤设定特定阈值L, 根据字符串长度, 获得此范围内的段落; 对各段及步骤①所获得图书名称进行预处理, 将每个文本看作是由一组词(t1,t2,…,tn)构成, 采用向量空间模型对其进行量化, 使用最常用的TF*IDF方法, 为每个特征词赋权值wi, 如公式(1)所示, 因此将(t1,t2,…,tn)分解得到的正交词条矢量组就构成了一个文本的向量空间,使用公式(2)分别计算每段文本与书名的相似度, 抽取最相似段落作为图书网页书目信息。</p><p><table><tr><td><img src="1003-3513-30-4-71/img_2.png"/></td><td>(1)</td></tr></table></p><p>其中, tf<sub>i</sub>表示特征词t<sub>j</sub>在当前文本d<sub>i</sub>中出现的频率, |D|是文本总数, df<sub>i</sub>是在所有文本中特征词t<sub>j</sub>出现的频率, 其中为了消除文档长度的影响, 对所有的特征项权重进行规一化处理。</p><p><table><tr><td><img src="1003-3513-30-4-71/img_3.png"/></td><td>(2)</td></tr></table></p><p>⑥采用综合评定等级方法评价实验结果。</p></div></div><div class="paragraph"><span class="paragraph_title outline_anchor" level="1">4 实验与结果分析</span><div class="paragraph"><span class="paragraph_title outline_anchor" level="2">4.1 实验数据集</span><p>本文力图建立一种具有普适性的图书网页识别和书目信息抽取模型, 因此选取了来自各种图书专门性网站以及各类一般性网站中的网页进行实验。目前, 自动抓取各类网页的手段繁多, 既可借助火狐浏览器的DataScraper和MetaStudio等辅助插件来完成, 也可以使用各种开源网络爬虫软件获得。但为确保实验的透明性和准确性, 本研究在图书网页信息抽取过程中使用的实验材料主要采用手动下载的方式获取。这些网页既包括国内知名的图书专门性网站, 如当当网(http://book.dangdang.com/)、孔夫子网(http://www.kongfz.com/)上的网页,也包括利用Google搜索引擎以 “图书 ISBN 出版社 价格”等4个关键词和布尔逻辑与方式检索得到的任意网页(检索时间: 2013年4月15日10时05分)。为方便比较和表述, 以下各种材料以100篇为单位统一进行统计分析, 如<a anchor="table">表1</a>所示:</p><div class="table outline_anchor"><div class="table_anchor" style="display: none;"><b>表1</b></div><div class="caption_title" style="display: none;"><b>表1</b></div><table><tr><td class="table-icon-td"><img class="table-icon" src="http://manu44.magtech.com.cn/Jwk_infotech_wk3/html_resources/images/table-icon.gif"/><div style="display: none;" class="table_content"><span class="caption"> <b>表1</b> 实验材料来源</span><table><thead><tr><th valign="middle" align="center" style="border-top:1px solid #000;border-bottom:1px solid #000;">网页来源</th><th valign="middle" align="center" style="border-top:1px solid #000;border-bottom:1px solid #000;">样本数量(篇)</th></tr></thead><tbody><tr><td valign="middle" align="center" style="border-top:1px solid #000;">Google网页</td><td valign="middle" align="center" style="border-top:1px solid #000;">100</td></tr><tr><td valign="middle" align="center">当当网</td><td valign="middle" align="center">100</td></tr><tr><td valign="middle" align="center" style="border-bottom:1px solid #000;">孔夫子网</td><td valign="middle" align="center" style="border-bottom:1px solid #000;">100</td></tr></tbody></table><table-wrap-foot><fn id="nt1"/></table-wrap-foot></div></td><td align="left" valign="middle"><span class="caption"> <b>表1</b> 实验材料来源</span></td></tr></table></div></div><div class="paragraph"><span class="paragraph_title outline_anchor" level="2">4.2 实验结果与分析</span><p>(1) 实验1: 图书网页识别</p><p>采用人工标注方法对来自Google检索的100篇实验材料进行处理, 之后由系统自动识别, 实验结果如<a anchor="table">表2</a>所示。</p><p>(2) 实验2: 确定阈值L范围</p><p>考虑到实验样本间的均衡性, 图书网页书目信息抽取过程使用的实验材料构成如下所述: 实验1识别出的图书网页、来自于当当网和孔夫子网等图书专门性网站的图书网页各100篇。为获得最佳L值, 通过设定不同取值区间, 分别对以上三个不同来源的图书网页进行实验, 用信息保留概率, 即: 图书网页中摘要、简介等信息包含在过滤后的字符串内的概率, 来确定最佳的L区间。</p><div class="table outline_anchor"><div class="table_anchor" style="display: none;"><b>表2</b></div><div class="caption_title" style="display: none;"><b>表2</b></div><table><tr><td class="table-icon-td"><img class="table-icon" src="http://manu44.magtech.com.cn/Jwk_infotech_wk3/html_resources/images/table-icon.gif"/><div style="display: none;" class="table_content"><span class="caption"> <b>表2</b> 图书网页识别结果</span><table><thead><tr><th valign="middle" align="center" style="border-top:1px solid #000;border-bottom:1px solid #000;">材料来源</th><th valign="middle" align="center" style="border-top:1px solid #000;border-bottom:1px solid #000;">网页总数(个)</th><th valign="middle" align="center" style="border-top:1px solid #000;border-bottom:1px solid #000;">正确结果 (个)</th><th valign="middle" align="center" style="border-top:1px solid #000;border-bottom:1px solid #000;">错误结果(个)</th><th valign="middle" align="center" style="border-top:1px solid #000;border-bottom:1px solid #000;">准确率 (%)</th></tr></thead><tbody><tr><td valign="middle" align="center" style="border-top:1px solid #000;border-bottom:1px solid #000;">Google网页</td><td valign="middle" align="center" style="border-top:1px solid #000;border-bottom:1px solid #000;">100</td><td valign="middle" align="center" style="border-top:1px solid #000;border-bottom:1px solid #000;">78</td><td valign="middle" align="center" style="border-top:1px solid #000;border-bottom:1px solid #000;">22</td><td valign="middle" align="center" style="border-top:1px solid #000;border-bottom:1px solid #000;">78</td></tr></tbody></table><table-wrap-foot><fn id="nt2"/></table-wrap-foot></div></td><td align="left" valign="middle"><span class="caption"> <b>表2</b> 图书网页识别结果</span></td></tr></table></div><p><div class="figure outline_anchor"><div class="figure_anchor" style="display: none;"><b>图2</b></div><table><tr><td></td><td><ul id="sddm"><li><a href="#" onmouseover="mopen('F2A')" onmouseout="mclosetime()">Figure Option</a><div id="F2A" onmouseover="mcancelclosetime()" onmouseout="mclosetime()"><a class="group3" href="1003-3513-30-4-71/img_4.png" title=' <p>Google网页确定阈值L的实验结果</p>'>View</a><a href="1003-3513-30-4-71/img_4.png.zip" >Download</a><a href="1003-3513-30-4-71/img_4.png.html" target="_blank" >New Window</a></div></li></ul> </td></tr> <tr id="F2" ><td align="center" valign="middle"><a class="group3" href="1003-3513-30-4-71/img_4.png" title=' <p>Google网页确定阈值L的实验结果</p>'><img src="1003-3513-30-4-71/thumbnail/img_4.png" /></a></td><td align="left" valign="middle"><span class="caption"><b>图2</b> Google网页确定阈值L的实验结果</span></td></tr></table></div></p><p>由<a anchor="figure">图2</a>的实验结果可以得出: 当阈值L在0-50和300以上的时候, 信息保留概率均在0.1以下, 最高概率仅为350-400时的0.06, 未达到平均水平; 而L在区间50-300时的平均水平均在0.1以上。因此对于来自Google检索的图书网页, L在50-300时, 信息可以被有效保存下来, 且概率总和为0.76。</p><p><div class="figure outline_anchor"><div class="figure_anchor" style="display: none;"><b>图3</b></div><table><tr><td></td><td><ul id="sddm"><li><a href="#" onmouseover="mopen('F3A')" onmouseout="mclosetime()">Figure Option</a><div id="F3A" onmouseover="mcancelclosetime()" onmouseout="mclosetime()"><a class="group3" href="1003-3513-30-4-71/img_5.png" title=' <p>当当网确定阈值L的实验结果</p>'>View</a><a href="1003-3513-30-4-71/img_5.png.zip" >Download</a><a href="1003-3513-30-4-71/img_5.png.html" target="_blank" >New Window</a></div></li></ul> </td></tr> <tr id="F3" ><td align="center" valign="middle"><a class="group3" href="1003-3513-30-4-71/img_5.png" title=' <p>当当网确定阈值L的实验结果</p>'><img src="1003-3513-30-4-71/thumbnail/img_5.png" /></a></td><td align="left" valign="middle"><span class="caption"><b>图3</b> 当当网确定阈值L的实验结果</span></td></tr></table></div></p><p>由<a anchor="figure">图3</a>的实验结果可以得出: 当阈值L在0-100、300-400和450以上的时候信息保留概率均在0.1以下, 最高概率仅为0.07; 虽然在区间400-450时信息保留概率达到0.1, 但比较孤立, 不具有代表性。因此认为平均概率在0.1以上多集中在区间100-300, 对于来自当当网的图书网页, L在100-300时, 信息可以被有效保存下来, 且概率总和为0.72。</p><p><div class="figure outline_anchor"><div class="figure_anchor" style="display: none;"><b>图4</b></div><table><tr><td></td><td><ul id="sddm"><li><a href="#" onmouseover="mopen('F4A')" onmouseout="mclosetime()">Figure Option</a><div id="F4A" onmouseover="mcancelclosetime()" onmouseout="mclosetime()"><a class="group3" href="1003-3513-30-4-71/img_6.png" title=' <p>孔夫子网确定阈值L的实验结果</p>'>View</a><a href="1003-3513-30-4-71/img_6.png.zip" >Download</a><a href="1003-3513-30-4-71/img_6.png.html" target="_blank" >New Window</a></div></li></ul> </td></tr> <tr id="F4" ><td align="center" valign="middle"><a class="group3" href="1003-3513-30-4-71/img_6.png" title=' <p>孔夫子网确定阈值L的实验结果</p>'><img src="1003-3513-30-4-71/thumbnail/img_6.png" /></a></td><td align="left" valign="middle"><span class="caption"><b>图4</b> 孔夫子网确定阈值L的实验结果</span></td></tr></table></div></p><p>由<a anchor="figure">图4</a>的实验结果可以得出: 当阈值L在0-100和350以上的时候信息保留概率均在0.1以下, 最高概率仅为区间0-50上的0.07。因此, 对于来自孔夫子网的图书网页, 认为L在100-350时, 信息可以被有效保存下来, 且概率总和达到0.82。</p><p>综上所述, 针对三组不同实验材料, L均有各自最佳的取值范围。如<a anchor="figure">图5</a>所示, L在不同取值范围内, Google网页、当当网和孔夫子网的图书网页信息保留概率大致服从正态分布, 因此可知, 将L阈值界定在100-300范围内, 效果比较理想。</p><p><div class="figure outline_anchor"><div class="figure_anchor" style="display: none;"><b>图 5</b></div><table><tr><td></td><td><ul id="sddm"><li><a href="#" onmouseover="mopen('F5A')" onmouseout="mclosetime()">Figure Option</a><div id="F5A" onmouseover="mcancelclosetime()" onmouseout="mclosetime()"><a class="group3" href="1003-3513-30-4-71/img_7.png" title=' <p>各类网页不同L取值下信息保留概率变化趋势</p>'>View</a><a href="1003-3513-30-4-71/img_7.png.zip" >Download</a><a href="1003-3513-30-4-71/img_7.png.html" target="_blank" >New Window</a></div></li></ul> </td></tr> <tr id="F5" ><td align="center" valign="middle"><a class="group3" href="1003-3513-30-4-71/img_7.png" title=' <p>各类网页不同L取值下信息保留概率变化趋势</p>'><img src="1003-3513-30-4-71/thumbnail/img_7.png" /></a></td><td align="left" valign="middle"><span class="caption"><b>图 5</b> 各类网页不同L取值下信息保留概率变化趋势</span></td></tr></table></div></p><p>(3) 实验3: 图书网页书目信息抽取</p><p>本文对图书网页书目信息抽取结果采用综合评定等级的方法, 将抽取结果与正确的书目信息从内容完整性和相关性两个方面进行衡量, 等级共分为5级。第1级: 能够100%正确完整地抽取信息; 第2级: 能够90%以上完整抽取信息, 但有小部分信息丢失; 第3级: 能够70%-90%完整抽取信息, 但掺杂了部分无关信息; 第4级: 仅能很少部分抽取出书目信息, 噪声很大; 第5级: 抽取的信息与书目信息无关, 属于纯噪声信息。</p><p>从<a anchor="table">表3</a>可以得出: 来自于当当网的100篇实验材料在抽取信息时, 其完整性和相关性方面要明显好于另外两个材料来源, 准确率达到84%, 主要是因为当当网的图书网页布局界限比较分明, 标签使用更加规范, 图书摘要和相关简介信息与抽取模型的设计更加匹配。来自孔夫子网站的图书网页, 虽然抽取信息效果与当当网的有一定差距, 但准确率也达到79%; 其主要原因是来自孔夫子网的图书网页, 图书介绍远不如当当网规范, 其中部分网页甚至省略或者使用较少文字描述图书内容, 这就导致抽取过程一些纯噪声信息的出现。虽然通过Google检索获取的图书网页抽取书目信息效果不及当当网和孔夫子网, 但是准确率也达到了75%左右, 分析其主要原因是因为Google检索出的网页分别来自以非图书网页为主的各类一般性网站, 无论是在网页设计布局方面, 还是网页信息纯度方面都存在很大差异性, 一些以盈利为目的的商业网站, 经常在主要信息附近添加广告内容, 这就给信息提取造成了很大干扰, 部分网页在设计时为了追求个性化, 经常将主要信息使用网页标签进行分割处理, 很难将其辨别抽取出来。即使存在诸多问题, 本文提出的图书网页书目信息抽取模型仍然取得了较为理想的效果, 平均准确率达到79%左右, 具有较强的实用价值。</p><div class="table outline_anchor"><div class="table_anchor" style="display: none;"><b>表3</b></div><div class="caption_title" style="display: none;"><b>表3</b></div><table><tr><td class="table-icon-td"><img class="table-icon" src="http://manu44.magtech.com.cn/Jwk_infotech_wk3/html_resources/images/table-icon.gif"/><div style="display: none;" class="table_content"><span class="caption"> <b>表3</b> 各类图书网页书目信息抽取结果</span><table><thead><tr><th valign="middle" align="center" style="border-top:1px solid #000;border-bottom:1px solid #000;">等级 来源</th><th valign="middle" align="center" style="border-top:1px solid #000;border-bottom:1px solid #000;">1级</th><th valign="middle" align="center" style="border-top:1px solid #000;border-bottom:1px solid #000;">2级</th><th valign="middle" align="center" style="border-top:1px solid #000;border-bottom:1px solid #000;">3级</th><th valign="middle" align="center" style="border-top:1px solid #000;border-bottom:1px solid #000;">4级</th><th valign="middle" align="center" style="border-top:1px solid #000;border-bottom:1px solid #000;">5级</th><th valign="middle" align="center" style="border-top:1px solid #000;border-bottom:1px solid #000;">合计(篇)</th><th valign="middle" align="center" style="border-top:1px solid #000;border-bottom:1px solid #000;">准确率(%)</th></tr></thead><tbody><tr><td valign="middle" align="center" style="border-top:1px solid #000;">Google网页</td><td valign="middle" align="center" style="border-top:1px solid #000;">38</td><td valign="middle" align="center" style="border-top:1px solid #000;">22</td><td valign="middle" align="center" style="border-top:1px solid #000;">15</td><td valign="middle" align="center" style="border-top:1px solid #000;">4</td><td valign="middle" align="center" style="border-top:1px solid #000;">21</td><td valign="middle" align="center" style="border-top:1px solid #000;">100</td><td valign="middle" align="center" style="border-top:1px solid #000;">75</td></tr><tr><td valign="middle" align="center">当当网</td><td valign="middle" align="center">54</td><td valign="middle" align="center">19</td><td valign="middle" align="center">11</td><td valign="middle" align="center">10</td><td valign="middle" align="center">6</td><td valign="middle" align="center">100</td><td valign="middle" align="center">84</td></tr><tr><td valign="middle" align="center" style="border-bottom:1px solid #000;">孔夫子网</td><td valign="middle" align="center" style="border-bottom:1px solid #000;">45</td><td valign="middle" align="center" style="border-bottom:1px solid #000;">15</td><td valign="middle" align="center" style="border-bottom:1px solid #000;">19</td><td valign="middle" align="center" style="border-bottom:1px solid #000;">6</td><td valign="middle" align="center" style="border-bottom:1px solid #000;">15</td><td valign="middle" align="center" style="border-bottom:1px solid #000;">100</td><td valign="middle" align="center" style="border-bottom:1px solid #000;">79</td></tr></tbody></table><table-wrap-foot><fn id="nt3"/></table-wrap-foot></div></td><td align="left" valign="middle"><span class="caption"> <b>表3</b> 各类图书网页书目信息抽取结果</span></td></tr></table></div></div></div><div class="paragraph"><span class="paragraph_title outline_anchor" level="1">5 结 论</span><p>本文提出的模型主要针对各类图书网页进行网页自动识别及书目信息抽取。实验证明, 该方法实现简洁, 复杂度低, 并且对于当前网页多样化、差异化、复杂化等特点具有很强的普适性, 效果比较理想; 但是, 对于极特殊的部分网页, 还是存在误判和抽取失败等问题, 下一步的工作重点在于完善抽取方法, 进一步提高抽取准确率。</p></div>
</div>
<div class="article_reference">
<span class="outline_anchor article_reference_title"><b>参考文献</b></span>
<div class="layout-btn">
<div id="layout-btn1">
<a href="javascript:;">View Option</a>
<div id="layout-btn-arrows1" class="layout-btn-arrows-down"></div>
</div>
<ul id="layout-btn-ul1" style="display: none;">
<li><a href="javascript:;" class="ref_sort" type="1">原文顺序</a></li>
<li><a href="javascript:;" class="ref_sort" type="2">文献年度倒序</a></li>
<li><a href="javascript:;" class="ref_sort" type="3">文中引用次数倒序</a></li>
<li><a href="javascript:;" class="ref_sort" type="4">被引期刊影响因子</a></li>
</ul>
</div>
<div class="clear"></div>
<table>
<tr id="R1" >
<td class="label"><span>[1]</span></td>
<td class="citation">
<mixed-citation publication-type="journal" xmlns: xlink="http: //www. w3. org/1999/xlink" xlink: type="simple"><name MTML-type="CN">罗永莲</name>, <name MTML-type="CN">秦振吉</name>. <article-title><strong> <strong> 新闻网页主题内容提取方法研究</strong></strong></article-title>[J]. <source MTML-type="CN">微计算机应用</i></i></source>, <year>2007</year>, <volume>28</volume>(<issue>5</issue>): <fpage>556</fpage>-<lpage>560</lpage>. </mixed-citation></br><mixed-citation>(<name><surname>Luo</surname> <given-names>Yonglian</given-names></name>, <name><surname>Qin</surname> <given-names>Zhenji</given-names></name>. <article-title><strong> Research on Extracting Topic Content from News Web Pages</strong></article-title>[J]. <i><source>Microcomputer Applications</i></source>, <year>2007</year>, <volume>28</volume>(<issue>5</issue>): <fpage>556</fpage>-<lpage>560</lpage>. )</mixed-citation>
<span class="cited" id="cited_R1">[本文引用:1]</span>
<span class="j_cf">[CJCR: 0.2529]</span>
</td>
</tr>
<tr id="R2" >
<td class="label"><span>[2]</span></td>
<td class="citation">
<mixed-citation publication-type="journal" xmlns: xlink="http: //www. w3. org/1999/xlink" xlink: type="simple"><name MTML-type="CN">施洋</name>, <name MTML-type="CN">张奇</name>, <name MTML-type="CN">黄萱菁</name>. <article-title><strong> <strong> 含有语义特征的网页新闻自动抽取</strong></strong></article-title>[J]. <a href="http://118.145.16.217/magsci/article/article?id=1028021" target="_blank"><source MTML-type="CN">计算机工程</i></i></source>, <year>2010</year>, <volume>36</volume>(<issue>7</issue>): <fpage>173</fpage>-<lpage>178</lpage>. </mixed-citation></a></br><mixed-citation>(<name><surname>Shi</surname> <given-names>Yang</given-names></name>, <name><surname>Zhang</surname> <given-names>Qi</given-names></name>, <name><surname>Huang</surname> <given-names>Xuanjing</given-names></name>. <article-title><strong> Automatic Web News Extraction with Semantic Features</strong></article-title>[J]. <i><a href="http://118.145.16.217/magsci/article/article?id=1028021" target="_blank"><source>Computer Engineering</i></source>, <year>2010</year>, <volume>36</volume>(<issue>7</issue>): <fpage>173</fpage>-<lpage>178</lpage>. )</mixed-citation></a>
<span class="cited" id="cited_R2">[本文引用:1]</span>
<span class="j_cf">[CJCR: 0.492]</span>
</td>
</tr>
<tr id="R3" >
<td class="label"><span>[3]</span></td>
<td class="citation">
<mixed-citation publication-type="journal" xmlns: xlink="http: //www. w3. org/1999/xlink" xlink: type="simple"><name MTML-type="CN">孔胜</name>, <name MTML-type="CN">王宇</name>. <article-title><strong> <strong> 一种基于正文特征的新闻网页抽取方法</strong></strong></article-title>[J]. <source MTML-type="CN">情报杂志</i></i></source>, <year>2010</year>, <volume>29</volume>(<issue>8</issue>): <fpage>122</fpage>-<lpage>125</lpage>. </mixed-citation></br><mixed-citation>(<name><surname>Kong</surname> <given-names>Sheng</given-names></name>, <name><surname>Wang</surname> <given-names>Yu</given-names></name>. <article-title><strong> A News Page Information Extraction Based on Web Feature</strong></article-title>[J]. <i><source>Journal of Intelligence</i></source>, <year>2010</year>, <volume>29</volume>(<issue>8</issue>): <fpage>122</fpage>-<lpage>125</lpage>. )</mixed-citation>
<span class="cited" id="cited_R3">[本文引用:1]</span>
<span class="j_cf">[CJCR: 0.951]</span>
</td>
</tr>
<tr id="R4" >
<td class="label"><span>[4]</span></td>
<td class="citation">
<mixed-citation publication-type="journal" xmlns: xlink="http: //www. w3. org/1999/xlink" xlink: type="simple"><name MTML-type="CN">刘伟</name>, <name MTML-type="CN">严华梁</name>. <article-title><strong> <strong> 一种统一的Web新闻对象自动抽取方法</strong></strong></article-title>[J]. <a href="http://118.145.16.217/magsci/article/article?id=17821656" target="_blank"><source MTML-type="CN">计算机工程</i></i></source>, <year>2012</year>, <volume>38</volume>(<issue>11</issue>): <fpage>167</fpage>-<lpage>169</lpage>. </mixed-citation></a></br><mixed-citation>(<name><surname>Liu</surname> <given-names>Wei</given-names></name>, <name><surname>Yan</surname> <given-names>Hualiang</given-names></name>. <article-title><strong> A Unified and Automatic Web News Object Extraction Approach</strong></article-title>[J]. <i><a href="http://118.145.16.217/magsci/article/article?id=17821656" target="_blank"><source>Computer Engineering</i></source>, <year>2012</year>, <volume>38</volume>(<issue>11</issue>): <fpage>167</fpage>-<lpage>169</lpage>. )</mixed-citation></a>
<span class="cited" id="cited_R4">[本文引用:1]</span>
<span class="j_cf">[CJCR: 0.492]</span>
</td>
</tr>
<tr id="R5" >
<td class="label"><span>[5]</span></td>
<td class="citation">
<mixed-citation publication-type="journal" xmlns: xlink="http: //www. w3. org/1999/xlink" xlink: type="simple"><name MTML-type="CN">朱红灿</name>, <name MTML-type="CN">龙朝阳</name>. <article-title><strong> <strong> 基于熵的新闻网页抽取方法的研究</strong></strong></article-title>[J]. <a href="http://118.145.16.217/magsci/article/article?id=5839772" target="_blank"><source MTML-type="CN">现代图书情报技术</i></i></source>, <volume>2007</volume>(<issue>4</issue>): <fpage>48</fpage>-<lpage>51</lpage>. </mixed-citation></a></br><mixed-citation>(<name><surname>Zhu</surname> <given-names>Hongcan</given-names></name>, <name><surname>Long</surname> <given-names>Chaoyang</given-names></name>. <article-title><strong> An Entropy-Based Approach for News Article Extraction from Web Page</strong></article-title>[J]. <i><a href="http://118.145.16.217/magsci/article/article?id=5839772" target="_blank"><source>New Technology of Library and Information Service</i></source>, <volume>2007</volume>(<issue>4</issue>): <fpage>48</fpage>-<lpage>51</lpage>. )</mixed-citation></a>
<span class="cited" id="cited_R5">[本文引用:1]</span>
<span class="j_cf">[CJCR: 1.073]</span>
</td>
</tr>
<tr id="R6" >
<td class="label"><span>[6]</span></td>
<td class="citation">
<mixed-citation publication-type="journal" xmlns: xlink="http: //www. w3. org/1999/xlink" xlink: type="simple"><name MTML-type="CN">孙承杰</name>, <name MTML-type="CN">关毅</name>. <article-title><strong> <strong> 基于统计的网页正文信息抽取方法的研究</strong></strong></article-title>[J]. <a href="http://118.145.16.217/magsci/article/article?id=8646876" target="_blank"><source MTML-type="CN">中文信息学报</i></i></source>, <year>2004</year>, <volume>18</volume>(<issue>5</issue>): <fpage>17</fpage>-<lpage>22</lpage>. </mixed-citation></a></br><mixed-citation>(<name><surname>Sun</surname> <given-names>Chengjie</given-names></name>, <name><surname>Guan</surname> <given-names>Yi</given-names></name>. <article-title><strong> A Statistical Approach for Content Extraction from Web Page</strong></article-title>[J]. <i><a href="http://118.145.16.217/magsci/article/article?id=8646876" target="_blank"><source>Journal of Chinese Information Processing</i></source>, <year>2004</year>, <volume>18</volume>(<issue>5</issue>): <fpage>17</fpage>-<lpage>22</lpage>. )</mixed-citation></a>
<span class="cited" id="cited_R6">[本文引用:2]</span>
<span class="j_cf">[CJCR: 1.13]</span>
</td>
</tr>
<tr id="R7" >
<td class="label"><span>[7]</span></td>
<td class="citation">
<mixed-citation publication-type="journal" xmlns: xlink="http: //www. w3. org/1999/xlink" xlink: type="simple"><name MTML-type="CN">赵欣欣</name>, <name MTML-type="CN">索红光</name>, <name MTML-type="CN">刘玉树</name>. <article-title><strong> <strong> 基于标记窗的网页正文信息提取方法</strong></strong></article-title>[J]. <a href="http://118.145.16.217/magsci/article/article?id=5400086" target="_blank"><source MTML-type="CN">计算机应用研究</i></i></source>, <year>2007</year>, <volume>24</volume>(<issue>3</issue>): <fpage>144</fpage>-<lpage>148</lpage>. </mixed-citation></a></br><mixed-citation>(<name><surname>Zhao</surname> <given-names>Xinxin</given-names></name>, <name><surname>Suo</surname> <given-names>Hongguang</given-names></name>, <name><surname>Liu</surname> <given-names>Yushu</given-names></name>. <article-title><strong> Web Content Information Extraction Method Based on Tag Window</strong></article-title>[J]. <i><a href="http://118.145.16.217/magsci/article/article?id=5400086" target="_blank"><source>Application Research of Computer</i></source>, <year>2007</year>, <volume>24</volume>(<issue>3</issue>): <fpage>144</fpage>-<lpage>148</lpage>. )</mixed-citation></a>
<span class="cited" id="cited_R7">[本文引用:1]</span>
<span class="j_cf">[CJCR: 0.601]</span>
</td>
</tr>
<tr id="R8" >
<td class="label"><span>[8]</span></td>
<td class="citation">
<mixed-citation publication-type="confproc"><name><surname>Zheng</surname> <given-names>S Y</given-names></name>, <name><surname>Song</surname> <given-names>R H</given-names></name>, <name><surname>Wen</surname> <given-names>J R</given-names></name>. <article-title><strong> Template-independent News Extraction Based on Visual Consistency[C]. In: Proceedings of the AAAI’07, Vancouver, Canada</strong></article-title>. <year>2007</year>. </mixed-citation>
<span class="cited" id="cited_R8">[本文引用:1]</span>
</td>
</tr>
<tr id="R9" >
<td class="label"><span>[9]</span></td>
<td class="citation">
<mixed-citation publication-type="journal" xmlns: xlink="http: //www. w3. org/1999/xlink" xlink: type="simple"><name MTML-type="CN">郑德权</name>, <name MTML-type="CN">张迪</name>, <name MTML-type="CN">赵铁军</name>, <etal MTML-type="CN">等</etal>. <article-title><strong> <strong> Blog网页分类与识别技术研究</strong></strong></article-title>[J]. <a href="http://118.145.16.217/magsci/article/article?id=4951952" target="_blank"><source MTML-type="CN">通信学报</i></i></source>, <year>2007</year>, <volume>28</volume>(<issue>12</issue>): <fpage>156</fpage>-<lpage>160</lpage>. </mixed-citation></a></br><mixed-citation>(<name><surname>Zheng</surname> <given-names>Dequan</given-names></name>, <name><surname>Zhang</surname> <given-names>Di</given-names></name>, <name><surname>Zhao</surname> <given-names>Tiejun</given-names></name>. <article-title><strong> Study on the Classification and Identification of Blog Pages</strong></article-title>[J]. <i><a href="http://118.145.16.217/magsci/article/article?id=4951952" target="_blank"><source>Journal of Communication</i></source>, <year>2007</year>, <volume>28</volume>(<issue>12</issue>): <fpage>156</fpage>-<lpage>160</lpage>. )</mixed-citation></a>
<span class="cited" id="cited_R9">[本文引用:1]</span>
</td>
</tr>
<tr id="R10" >
<td class="label"><span>[10]</span></td>
<td class="citation">
<mixed-citation publication-type="journal" xmlns: xlink="http: //www. w3. org/1999/xlink" xlink: type="simple"><name MTML-type="CN">范纯龙</name>, <name MTML-type="CN">夏佳</name>, <name MTML-type="CN">肖昕</name>, <etal MTML-type="CN">等</etal>. <article-title><strong> <strong> 基于功能语义单元的博客评论抽取技术</strong></strong></article-title>[J]. <a href="http://118.145.16.217/magsci/article/article?id=11981508" target="_blank"><source MTML-type="CN">计算机应用</i></i></source>, <year>2011</year>, <volume>31</volume>(<issue>9</issue>): <fpage>17</fpage>-<lpage>23</lpage>. </mixed-citation></a></br><mixed-citation>(<name><surname>Fan</surname> <given-names>Chunlong</given-names></name>, <name><surname>Xia</surname> <given-names>Jia</given-names></name>, <name><surname>Xiao</surname> <given-names>Xin</given-names></name>, <etal>et al</etal>. <article-title><strong> Extraction Technology of Blog Comments Based on Functional Semantic Units</strong></article-title>[J]. <i><a href="http://118.145.16.217/magsci/article/article?id=11981508" target="_blank"><source>Journal of Computer Application</i></source>, <year>2011</year>, <volume>31</volume>(<issue>9</issue>): <fpage>17</fpage>-<lpage>23</lpage>. )</mixed-citation></a>
<span class="cited" id="cited_R10">[本文引用:1]</span>
<span class="j_cf">[CJCR: 0.646]</span>
</td>
</tr>
<tr id="R11" >
<td class="label"><span>[11]</span></td>
<td class="citation">
<mixed-citation publication-type="journal" xmlns: xlink="http: //www. w3. org/1999/xlink" xlink: type="simple"><name MTML-type="CN">曹冬林</name>, <name MTML-type="CN">廖祥文</name>, <name MTML-type="CN">许洪波</name>, <etal MTML-type="CN">等</etal>. <article-title><strong> <strong> 基于网页格式信息量的博客文章和评论抽取模型</strong></strong></article-title>[J]. <a href="http://118.145.16.217/magsci/article/article?id=3139950" target="_blank"><source MTML-type="CN">软件学报</i></i></source>, <year>2009</year>, <volume>20</volume>(<issue>5</issue>): <fpage>1282</fpage>-<lpage>1291</lpage>. </mixed-citation></a></br><mixed-citation>(<name><surname>Cao</surname> <given-names>Donglin</given-names></name>, <name><surname>Liao</surname> <given-names>Xiangwen</given-names></name>, <name><surname>Xu</surname> <given-names>Hongbo</given-names></name>, <etal>et al</etal>. <article-title><strong> Extraction Model Based on Web Format Information Quantity in Blog Post and Comment Extraction</strong></article-title>[J]. <i><a href="http://118.145.16.217/magsci/article/article?id=3139950" target="_blank"><source>Journal of Software</i></source>, <year>2009</year>, <volume>20</volume>(<issue>5</issue>): <fpage>1282</fpage>-<lpage>1291</lpage>. )</mixed-citation></a>
<span class="cited" id="cited_R11">[本文引用:1]</span>
<span class="j_cf">[CJCR: 2.181]</span>
</td>
</tr>
<tr id="R12" >
<td class="label"><span>[12]</span></td>
<td class="citation">
<mixed-citation publication-type="journal" xmlns: xlink="http: //www. w3. org/1999/xlink" xlink: type="simple"><name MTML-type="CN">唐伟</name>, <name MTML-type="CN">洪宇</name>, <name MTML-type="CN">冯艳卉</name>, <etal MTML-type="CN">等</etal>. <article-title><strong> <strong> 网页中商品“属性-值”关系的自动抽取方法研究</strong></strong></article-title>[J]. <source MTML-type="CN">中文信息学报</i></i></source>, <year>2012</year>, <volume>27</volume>(<issue>1</issue>): <fpage>21</fpage>-<lpage>29</lpage>. </mixed-citation></br><mixed-citation>(<name><surname>Tang</surname> <given-names>Wei</given-names></name>, <name><surname>Hong</surname> <given-names>Yu</given-names></name>, <name><surname>Feng</surname> <given-names>Yanhui</given-names></name>, <etal>et al</etal>. <article-title><strong> Automatic Extraction of the Product “Attribute-Value” Pair from the Web Pages</strong></article-title>[J]. <i><source>Journal of Chinese Information Processing</i></source>, <year>2012</year>, <volume>27</volume>(<issue>1</issue>): <fpage>21</fpage>-<lpage>29</lpage>. )</mixed-citation>
<span class="cited" id="cited_R12">[本文引用:1]</span>
<span class="j_cf">[CJCR: 1.13]</span>
</td>
</tr>
<tr id="R13" >
<td class="label"><span>[13]</span></td>
<td class="citation">
<mixed-citation publication-type="journal" xmlns: xlink="http: //www. w3. org/1999/xlink" xlink: type="simple"><name MTML-type="CN">杨舟</name>, <name MTML-type="CN">卓林</name>, <name MTML-type="CN">赵朋朋</name>, <etal MTML-type="CN">等</etal>. <article-title><strong> <strong> 一种针对商品数据记录的自动抽取方法</strong></strong></article-title>[J]. <a href="http://118.145.16.217/magsci/article/article?id=1025294" target="_blank"><source MTML-type="CN">计算机工程</i></i></source>, <year>2010</year>, <volume>36</volume>(<issue>23</issue>): <fpage>262</fpage>-<lpage>265</lpage>. </mixed-citation></a></br><mixed-citation>(<name><surname>Yang</surname> <given-names>Zhou</given-names></name>, <name><surname>Zhuo</surname> <given-names>Lin</given-names></name>, <name><surname>Zhao</surname> <given-names>Pengpeng</given-names></name>, <etal>et al</etal>. <article-title><strong> Automatic Extraction Method for Product Data Records</strong></article-title>[J]. <i><a href="http://118.145.16.217/magsci/article/article?id=1025294" target="_blank"><source>Computer Engineering</i></source>, <year>2010</year>, <volume>36</volume>(<issue>23</issue>): <fpage>262</fpage>-<lpage>265</lpage>. )</mixed-citation></a>
<span class="cited" id="cited_R13">[本文引用:1]</span>
<span class="j_cf">[CJCR: 0.492]</span>
</td>
</tr>
<tr id="R14" >
<td class="label"><span>[14]</span></td>
<td class="citation">
<mixed-citation publication-type="journal" xmlns: xlink="http: //www. w3. org/1999/xlink" xlink: type="simple"><name MTML-type="CN">吴晓彦</name>, <name MTML-type="CN">郑骁庆</name>, <name MTML-type="CN">顾轶灵</name>, <etal MTML-type="CN">等</etal>. <article-title><strong> <strong> 基于结构语义熵的网上商品信息提取系统</strong></strong></article-title>[J]. <a href="http://118.145.16.217/magsci/article/article?id=1098673" target="_blank"><source MTML-type="CN">计算机应用与软件</i></i></source>, <year>2010</year>, <volume>27</volume>(<issue>9</issue>): <fpage>49</fpage>-<lpage>53</lpage>. </mixed-citation></a></br><mixed-citation>(<name><surname>Wu</surname> <given-names>Xiaoyan</given-names></name>, <name><surname>Zheng</surname> <given-names>Xiaoqing</given-names></name>, <name><surname>Gu</surname> <given-names>Yiling</given-names></name>, <etal>et al</etal>. <article-title><strong> Extraction Algorithm of Merchand ise Information on Networks Based on Structured-Semantic Entropy</strong></article-title>[J]. <i><a href="http://118.145.16.217/magsci/article/article?id=1098673" target="_blank"><source>Computer Application and Software</i></source>, <year>2010</year>, <volume>27</volume>(<issue>9</issue>): <fpage>49</fpage>-<lpage>53</lpage>. )</mixed-citation></a>
<span class="cited" id="cited_R14">[本文引用:1]</span>
</td>
</tr>
<tr id="R15" >
<td class="label"><span>[15]</span></td>
<td class="citation">
<mixed-citation publication-type="journal" xmlns: xlink="http: //www. w3. org/1999/xlink" xlink: type="simple"><name MTML-type="CN">李文博</name>. <article-title><strong> <strong> 基于XML的藏文网页的信息抽取与转存技术研究</strong></strong></article-title>[D]. <source MTML-type="CN">兰州: 西北民族大学</i></i></source>, <year>2006</year>. </mixed-citation></br><mixed-citation>(<name><surname>Li</surname> <given-names>Wenbo</given-names></name>. <article-title><strong> The Research of XML-Based Tibet Web Page Information Extraction and Conversion Storage</strong></article-title>[D]. <i><source>Lanzhou: Northwest University for Nationalities</i></source>, <year>2006</year>. )</mixed-citation>
<span class="cited" id="cited_R15">[本文引用:1]</span>
</td>
</tr>
<tr id="R16" >
<td class="label"><span>[16]</span></td>
<td class="citation">
<mixed-citation publication-type="journal" xmlns: xlink="http: //www. w3. org/1999/xlink" xlink: type="simple"><name MTML-type="CN">蔡李</name>, <name MTML-type="CN">单艳</name>, <name MTML-type="CN">薛化建</name>. <article-title><strong> <strong> 维吾尔文网页正文抽取系统的研究与实现</strong></strong></article-title>[J]. <source MTML-type="CN">计算机工程与设计</i></i></source>, <year>2012</year>, <volume>33</volume>(<issue>2</issue>): <fpage>551</fpage>-<lpage>555</lpage>. </mixed-citation></br><mixed-citation>(<name><surname>Cai</surname> <given-names>Li</given-names></name>, <name><surname>Shan</surname> <given-names>Yan</given-names></name>, <name><surname>Xue</surname> <given-names>Huajian</given-names></name>. <article-title><strong> Research and Implementation of Uyghur Web Content Extraction System</strong></article-title>[J]. <i><source>Computer Engineering and Design</i></source>, <year>2012</year>, <volume>33</volume>(<issue>2</issue>): <fpage>551</fpage>-<lpage>555</lpage>. )</mixed-citation>
<span class="cited" id="cited_R16">[本文引用:1]</span>
<span class="j_cf">[CJCR: 0.789]</span>
</td>
</tr>
<tr id="R17" >
<td class="label"><span>[17]</span></td>
<td class="citation">
<mixed-citation publication-type="journal" xmlns: xlink="http: //www. w3. org/1999/xlink" xlink: type="simple"><name MTML-type="CN">王瑞</name>, <name MTML-type="CN">周喜</name>, <name MTML-type="CN">李晓</name>. <article-title><strong> <strong> 基于正文相关度的维吾尔网页正文提取</strong></strong></article-title>[J]. <a href="http://118.145.16.217/magsci/article/article?id=17822375" target="_blank"><source MTML-type="CN">计算机工程</i></i></source>, <year>2012</year>, <volume>38</volume>(<issue>21</issue>): <fpage>153</fpage>-<lpage>160</lpage>. </mixed-citation></a></br><mixed-citation>(<name><surname>Wang</surname> <given-names>Rui</given-names></name>, <name><surname>Zhou</surname> <given-names>Xi</given-names></name>, <name><surname>Li</surname> <given-names>Xiao</given-names></name>. <article-title><strong> Content Extraction of Uighur Web Based on Content Correlativity</strong></article-title>[J]. <i><a href="http://118.145.16.217/magsci/article/article?id=17822375" target="_blank"><source>Computer Engineering</i></source>, <year>2012</year>, <volume>38</volume>(<issue>21</issue>): <fpage>153</fpage>-<lpage>160</lpage>. )</mixed-citation></a>
<span class="cited" id="cited_R17">[本文引用:1]</span>
<span class="j_cf">[CJCR: 0.492]</span>
</td>
</tr>
<tr id="R18" >
<td class="label"><span>[18]</span></td>
<td class="citation">
<mixed-citation publication-type="journal" xmlns: xlink="http: //www. w3. org/1999/xlink" xlink: type="simple"><name MTML-type="CN">王爽</name>. <article-title><strong> <strong> 面向数字旅游网页的Web信息抽取技术研究</strong></strong></article-title>[D]. <source MTML-type="CN">西安: 西安电子科技大学</i></i></source>, <year>2012</year>. </mixed-citation></br><mixed-citation>(<name><surname>Wang</surname> <given-names>Shuang</given-names></name>. <article-title><strong> Research of Web Information Extraction Technology Oriented to Digital Tourism Website</strong></article-title>[D]. <i><source>Xi’an: Xidian University</i></source>, <year>2012</year>. )</mixed-citation>
<span class="cited" id="cited_R18">[本文引用:1]</span>
</td>
</tr>
<tr id="R19" >
<td class="label"><span>[19]</span></td>
<td class="citation">
<mixed-citation publication-type="journal" xmlns: xlink="http: //www. w3. org/1999/xlink" xlink: type="simple"><name MTML-type="CN">顾轶灵</name>. <article-title><strong> <strong> 基于多维语义的互联网药品信息提取方法</strong></strong></article-title>[J]. <source MTML-type="CN">计算机系统应用</i></i></source>, <year>2011</year>, <volume>20</volume>(<issue>11</issue>): <fpage>50</fpage>-<lpage>54</lpage>. </mixed-citation></br><mixed-citation>(<name><surname>Gu</surname> <given-names>Yiling</given-names></name>. <article-title><strong> Multidim-ensional-Semantics-Based Web Medicine Information Extr-action</strong></article-title>[J]. <i><source>Computer Systems and Applications</i></source>, <year>2011</year>, <volume>20</volume>(<issue>11</issue>): <fpage>50</fpage>-<lpage>54</lpage>. )</mixed-citation>
<span class="cited" id="cited_R19">[本文引用:1]</span>
</td>
</tr>
<tr id="R20" >
<td class="label"><span>[20]</span></td>
<td class="citation">
<mixed-citation publication-type="confproc"><name MTML-type="CN">王文生</name>, <name MTML-type="CN">谢能付</name>. <article-title><strong> <strong> 基于Web的农业信息自动抽取方法研究</strong></strong></article-title>[C]. <source MTML-type="CN">见: 全国农业信息分析理论与方法学术研讨会</i></i></source>. <year>2007</year>: <fpage>77</fpage>-<lpage>83</lpage>. </mixed-citation></br><mixed-citation>(<name><surname>Wang</surname> <given-names>Wensheng</given-names></name>, <name><surname>Xie</surname> <given-names>Nengfu</given-names></name>. <article-title><strong> Research on Web-based Agriculture Information Extraction</strong></article-title>[C]. <i><source>In: National Seminar on Agricultural Information Analysis Theory and Method</i></source>. <year>2007</year>: <fpage>77</fpage>-<lpage>83</lpage>. )</mixed-citation>
<span class="cited" id="cited_R20">[本文引用:1]</span>
</td>
</tr>
</table>
<div id="article_reference_meta" style="display: none;">
<div id="article_reference_meta_R1">
<div id="article_reference_meta_R1_citedNumber">1</div>
<div id="article_reference_meta_R1_nian">2007</div>
<div id="article_reference_meta_R1_jcr">0.0</div>
<div id="article_reference_meta_R1_cjcr">0.2529</div>
<div id="article_reference_meta_R1_articleCitedText">
<div class="sentence">... 2 相关研究在网页中, 抽取信息经历了不断进化与完善的过程, 从网页信息抽取的对象角度分析, 其研究多集中在新闻类网页的标题或内容的抽取<sup>[<xref ref-type="bibr" rid="R1">1</xref>,<xref ref-type="bibr" rid="R2">2</xref>,<xref ref-type="bibr" rid="R3">3</xref>,<xref ref-type="bibr" rid="R4">4</xref>,<xref ref-type="bibr" rid="R5">5</xref>,<xref ref-type="bibr" rid="R6">6</xref>,<xref ref-type="bibr" rid="R7">7</xref>]</sup> ...</div>
</div>
</div>
<div id="article_reference_meta_R2">
<div id="article_reference_meta_R2_citedNumber">1</div>
<div id="article_reference_meta_R2_nian">2010</div>
<div id="article_reference_meta_R2_jcr">0.0</div>
<div id="article_reference_meta_R2_cjcr">0.492</div>
<div id="article_reference_meta_R2_floatContent">
<div class="float_article_cited_format">. 2010, 36(7):173-178 </div>
<div class="float_article_title"><a href="http://118.145.16.217/magsci/article/article?id=1028021" target="_blank">Automatic Web News Extraction with Semantic Features</a></div>
<div class="float_article_affiliation">(School of Computer Science, Fudan University, Shanghai 200433)</div>
<div class="float_article_abs">This paper analyzes the semantic features and the similarity of Web news pages, and presents an automatic Web news extraction method with semantic features. It utilizes semantic classifier to find the seed information, and uses portion features to build information extraction rules. The F1-Value of Web news extraction can reach to 94.2% when add semantic features to classifier. The performance of F1-Value can reach to 96.9% when combine semantic classifier and portion features based information extraction method. Experimental result shows that the method can effectively improve the accuracy of Web information extraction method and cut the cost of manual labeling work.</div>
<div class="float_article_abs">通过分析新闻网页的语义特征以及网页之间存在的通用性质,提出一种含有语义特征的网页新闻自动抽取方法,包括利用语义分类器识别新闻网页中的种子信息以及页面中的局部信息来完成抽取。在分类器中加入语义特征可以使F1值达到94.2%。在语义分类器与局部特征结合的情况下,F1值可以达到96.9%。实验结果证明,该方法能有效提高网页信息抽取算法的精度,降低机器学习所需要的标注成本。</div>
<div>
</div>
</div>
<div id="article_reference_meta_R2_articleCitedText">
<div class="sentence">... 2 相关研究在网页中, 抽取信息经历了不断进化与完善的过程, 从网页信息抽取的对象角度分析, 其研究多集中在新闻类网页的标题或内容的抽取<sup>[<xref ref-type="bibr" rid="R1">1</xref>,<xref ref-type="bibr" rid="R2">2</xref>,<xref ref-type="bibr" rid="R3">3</xref>,<xref ref-type="bibr" rid="R4">4</xref>,<xref ref-type="bibr" rid="R5">5</xref>,<xref ref-type="bibr" rid="R6">6</xref>,<xref ref-type="bibr" rid="R7">7</xref>]</sup> ...</div>
</div>
</div>
<div id="article_reference_meta_R3">
<div id="article_reference_meta_R3_citedNumber">1</div>
<div id="article_reference_meta_R3_nian">2010</div>
<div id="article_reference_meta_R3_jcr">0.0</div>
<div id="article_reference_meta_R3_cjcr">0.951</div>
<div id="article_reference_meta_R3_articleCitedText">
<div class="sentence">... 2 相关研究在网页中, 抽取信息经历了不断进化与完善的过程, 从网页信息抽取的对象角度分析, 其研究多集中在新闻类网页的标题或内容的抽取<sup>[<xref ref-type="bibr" rid="R1">1</xref>,<xref ref-type="bibr" rid="R2">2</xref>,<xref ref-type="bibr" rid="R3">3</xref>,<xref ref-type="bibr" rid="R4">4</xref>,<xref ref-type="bibr" rid="R5">5</xref>,<xref ref-type="bibr" rid="R6">6</xref>,<xref ref-type="bibr" rid="R7">7</xref>]</sup> ...</div>
</div>
</div>
<div id="article_reference_meta_R4">
<div id="article_reference_meta_R4_citedNumber">1</div>
<div id="article_reference_meta_R4_nian">2012</div>
<div id="article_reference_meta_R4_jcr">0.0</div>
<div id="article_reference_meta_R4_cjcr">0.492</div>
<div id="article_reference_meta_R4_floatContent">
<div class="float_article_cited_format">. 2012, 38(11):167-169 DOI:<a href="http://dx.doi.org/10.3969/j.issn.1000-3428.2012.11.051" target="_blank">10.3969/j.issn.1000-3428.2012.11.051</a></div>
<div class="float_article_title"><a href="http://118.145.16.217/magsci/article/article?id=17821656" target="_blank">A Unified and Automatic Web News Object Extraction Approach</a></div>
<div class="float_article_affiliation">(1. Institute of Scientific and Technical Information of China, Beijing 100038, China; 2. Institute of Computer Science & Technology, Peking University, Beijing 100871, China)</div>
<div class="float_article_abs">This paper proposes a unified and automatic approach for extracting Web news object. By extracting the category, title, date, source, author, content, comments, related links and news links in the news pages as category properties, and through page analysis, candidate extraction and true value identification, news object can be extracted automatically. Experimental results show that the method for extracting information of objects multiple properties has high accuracy, and the result does not depend on a specific page template.</div>
<div class="float_article_abs">提出一种统一的Web新闻对象自动抽取方法。通过抽取新闻页面中的分类、标题、发布时间、来源、作者、内容、相关评论链接和相关新闻链接作为分类属性,经页面解析、候选值抽取、真值识别3个步骤,实现新闻对象的自动抽取。实验结果表明,该方法在同时抽取新闻对象的多个属性方面具有较高的准确性,且抽取结果不依赖于特定的页面模板。</div>
<div>
</div>
</div>
<div id="article_reference_meta_R4_articleCitedText">
<div class="sentence">... 2 相关研究在网页中, 抽取信息经历了不断进化与完善的过程, 从网页信息抽取的对象角度分析, 其研究多集中在新闻类网页的标题或内容的抽取<sup>[<xref ref-type="bibr" rid="R1">1</xref>,<xref ref-type="bibr" rid="R2">2</xref>,<xref ref-type="bibr" rid="R3">3</xref>,<xref ref-type="bibr" rid="R4">4</xref>,<xref ref-type="bibr" rid="R5">5</xref>,<xref ref-type="bibr" rid="R6">6</xref>,<xref ref-type="bibr" rid="R7">7</xref>]</sup> ...</div>
</div>
</div>
<div id="article_reference_meta_R5">
<div id="article_reference_meta_R5_citedNumber">1</div>
<div id="article_reference_meta_R5_nian"></div>
<div id="article_reference_meta_R5_jcr">0.0</div>
<div id="article_reference_meta_R5_cjcr">1.073</div>
<div id="article_reference_meta_R5_floatContent">
<div class="float_article_cited_format">. , 2007(4):48-51 </div>
<div class="float_article_title"><a href="http://118.145.16.217/magsci/article/article?id=5839772" target="_blank">An Entropy-Based Approach for News Article Extraction from Web Page</a></div>
<div class="float_article_affiliation">(Management School of Xiangtan University, Xiangtan 411105, China)</div>
<div class="float_article_abs"><p>In this paper,an approach for news article extraction from Web page is proposed and this approach applies information theory to DOM tree. Experiment on several news Web sites shows that it is practical.</p></div>
<div class="float_article_abs"><p>为了减少或根除新闻网站中大量非主题信息的干扰,提出一种新闻网页抽取方法,采用基于熵的计算和DOM树的知识,从新闻网页中抽取主题文档和相关链接。</p></div>
<div>
</div>
</div>
<div id="article_reference_meta_R5_articleCitedText">
<div class="sentence">... 2 相关研究在网页中, 抽取信息经历了不断进化与完善的过程, 从网页信息抽取的对象角度分析, 其研究多集中在新闻类网页的标题或内容的抽取<sup>[<xref ref-type="bibr" rid="R1">1</xref>,<xref ref-type="bibr" rid="R2">2</xref>,<xref ref-type="bibr" rid="R3">3</xref>,<xref ref-type="bibr" rid="R4">4</xref>,<xref ref-type="bibr" rid="R5">5</xref>,<xref ref-type="bibr" rid="R6">6</xref>,<xref ref-type="bibr" rid="R7">7</xref>]</sup> ...</div>
</div>
</div>
<div id="article_reference_meta_R6">
<div id="article_reference_meta_R6_citedNumber">2</div>
<div id="article_reference_meta_R6_nian">2004</div>
<div id="article_reference_meta_R6_jcr">0.0</div>
<div id="article_reference_meta_R6_cjcr">1.13</div>
<div id="article_reference_meta_R6_floatContent">
<div class="float_article_cited_format">. 2004, 18(5):17-22 </div>
<div class="float_article_title"><a href="http://118.145.16.217/magsci/article/article?id=8646876" target="_blank">A Statistical Approach for Content Extraction from Web Page</a></div>
<div class="float_article_abs">为了把自然语言处理技术有效的运用到网页文档中,本文提出了一种依靠统计信息,从中文新闻类网页中抽取正文内容的方法.该方法先根据网页中的HTML标记把网页表示成一棵树,然后利用树中每个结点包含的中文字符数从中选择包含正文信息的结点.该方法克服了传统的网页内容抽取方法需要针对不同的数据源构造不同的包装器的缺点,具有简单、准确的特点,试验表明该方法的抽取准确率可以达到95%以上.采用该方法实现的网页文本抽取工具目前为一个面向旅游领域的问答系统提供语料支持,很好的满足了问答系统的需求.</div>
<div>
</div>
</div>
<div id="article_reference_meta_R6_articleCitedText">
<div class="sentence">... 2 相关研究在网页中, 抽取信息经历了不断进化与完善的过程, 从网页信息抽取的对象角度分析, 其研究多集中在新闻类网页的标题或内容的抽取<sup>[<xref ref-type="bibr" rid="R1">1</xref>,<xref ref-type="bibr" rid="R2">2</xref>,<xref ref-type="bibr" rid="R3">3</xref>,<xref ref-type="bibr" rid="R4">4</xref>,<xref ref-type="bibr" rid="R5">5</xref>,<xref ref-type="bibr" rid="R6">6</xref>,<xref ref-type="bibr" rid="R7">7</xref>]</sup> ...</div>
<div class="boundary"></div>
<div class="sentence">... (3) 基于统计方法, 文献[6]提出了一种基于统计的方法实现抽取所有的正文信息都放在一个table中的特定情况, 文献[7]提出的基于标记窗(Tag Window)的网页正文获取方法扩大了成果<sup>[<xref ref-type="bibr" rid="R6">6</xref>]</sup>使用范围, 有效地弥补了它不能处理非table结构的网页正文提取的缺点 ...</div>
</div>
</div>
<div id="article_reference_meta_R7">
<div id="article_reference_meta_R7_citedNumber">1</div>
<div id="article_reference_meta_R7_nian">2007</div>
<div id="article_reference_meta_R7_jcr">0.0</div>
<div id="article_reference_meta_R7_cjcr">0.601</div>
<div id="article_reference_meta_R7_floatContent">
<div class="float_article_cited_format">. 2007, 24(3):144-148 </div>
<div class="float_article_title"><a href="http://118.145.16.217/magsci/article/article?id=5400086" target="_blank">Web Content Information Extraction Method Based on Tag Window</a></div>
<div class="float_article_abs">提出了基于标记窗的网页正文信息提取方法.该方法不仅适合于处理一个网页中所有正文信息均放在一个td 中的情况,也适合于处理网页正文放在多个td中的情况,还可以处理网页正文文字短到与网页其余部分文字(如广告、导航条、版权)长度相当的情况.尤其重要的是,它能够解决非Table 结构的网页正文提取问题.实验表明,该方法可以提高网页正文提取的准确率,适用性强.</div>
<div>
</div>
</div>
<div id="article_reference_meta_R7_articleCitedText">
<div class="sentence">... 2 相关研究在网页中, 抽取信息经历了不断进化与完善的过程, 从网页信息抽取的对象角度分析, 其研究多集中在新闻类网页的标题或内容的抽取<sup>[<xref ref-type="bibr" rid="R1">1</xref>,<xref ref-type="bibr" rid="R2">2</xref>,<xref ref-type="bibr" rid="R3">3</xref>,<xref ref-type="bibr" rid="R4">4</xref>,<xref ref-type="bibr" rid="R5">5</xref>,<xref ref-type="bibr" rid="R6">6</xref>,<xref ref-type="bibr" rid="R7">7</xref>]</sup> ...</div>
</div>
</div>
<div id="article_reference_meta_R8">
<div id="article_reference_meta_R8_citedNumber">1</div>
<div id="article_reference_meta_R8_nian">2007</div>
<div id="article_reference_meta_R8_jcr">0.0</div>
<div id="article_reference_meta_R8_cjcr">0.0</div>
<div id="article_reference_meta_R8_articleCitedText">
<div class="sentence">... 近些年来对于博客网页的信息抽取也逐渐成为热门的话题<sup>[<xref ref-type="bibr" rid="R8">8</xref>,<xref ref-type="bibr" rid="R9">9</xref>,<xref ref-type="bibr" rid="R10">10</xref>,<xref ref-type="bibr" rid="R11">11</xref>]</sup> ...</div>
</div>
</div>
<div id="article_reference_meta_R9">
<div id="article_reference_meta_R9_citedNumber">1</div>
<div id="article_reference_meta_R9_nian">2007</div>
<div id="article_reference_meta_R9_jcr">0.0</div>
<div id="article_reference_meta_R9_cjcr">0.0</div>
<div id="article_reference_meta_R9_floatContent">
<div class="float_article_cited_format">. 2007, 28(12):156-160 </div>
<div class="float_article_title"><a href="http://118.145.16.217/magsci/article/article?id=4951952" target="_blank">Study on the Classification and Identification of Blog Pages</a></div>
<div class="float_article_abs">为了找到一种自动将Blog网页区别于其他Web页面的方法,以便针对Blog语料进行内容抽取、对Blog社区进行规律性研究和发现等,针对Blog网页的特点与规律,提出一种根据网页结构和关键字计算相似度的方法识别Blog网页,初步的实验结果表明,达到了较高的识别正确率.</div>
<div>
</div>
</div>
<div id="article_reference_meta_R9_articleCitedText">
<div class="sentence">... 近些年来对于博客网页的信息抽取也逐渐成为热门的话题<sup>[<xref ref-type="bibr" rid="R8">8</xref>,<xref ref-type="bibr" rid="R9">9</xref>,<xref ref-type="bibr" rid="R10">10</xref>,<xref ref-type="bibr" rid="R11">11</xref>]</sup> ...</div>
</div>
</div>
<div id="article_reference_meta_R10">
<div id="article_reference_meta_R10_citedNumber">1</div>
<div id="article_reference_meta_R10_nian">2011</div>
<div id="article_reference_meta_R10_jcr">0.0</div>
<div id="article_reference_meta_R10_cjcr">0.646</div>
<div id="article_reference_meta_R10_floatContent">
<div class="float_article_cited_format">. 2011, 31(9):17-23 </div>
<div class="float_article_title"><a href="http://118.145.16.217/magsci/article/article?id=11981508" target="_blank">Extraction Technology of Blog Comments Based on Functional Semantic Units</a></div>
<div class="float_article_author"> Fan Chunlong , Xia Jia , Xiao Xin</div>
<div class="float_article_abs"><span class="style48">博客作为一类重要的网络信息资源,其评论信息抽取是舆情分析等研究工作的基础.总结了当前主流的博客评论抽取算法,介绍了页面结构在信息抽取中的应用,并结合人理解网页时充分利用“首页”等指示性短语的特点,提出利用具有明确语义和功能指示作用的功能语义单元来抽取评论信息的技术;详细介绍了抽取过程中涉及的页面结构线性化、功能语义单元识别、正文识别和评论抽取算法等内容.最后,通过实验证明,该技术在博客的正文和评论信息抽取上能取得良好效果.</span></div>
<div>
</div>
</div>
<div id="article_reference_meta_R10_articleCitedText">
<div class="sentence">... 近些年来对于博客网页的信息抽取也逐渐成为热门的话题<sup>[<xref ref-type="bibr" rid="R8">8</xref>,<xref ref-type="bibr" rid="R9">9</xref>,<xref ref-type="bibr" rid="R10">10</xref>,<xref ref-type="bibr" rid="R11">11</xref>]</sup> ...</div>
</div>
</div>
<div id="article_reference_meta_R11">
<div id="article_reference_meta_R11_citedNumber">1</div>
<div id="article_reference_meta_R11_nian">2009</div>
<div id="article_reference_meta_R11_jcr">0.0</div>
<div id="article_reference_meta_R11_cjcr">2.181</div>
<div id="article_reference_meta_R11_floatContent">
<div class="float_article_cited_format">. 2009, 20(5):1282-1291 </div>
<div class="float_article_title"><a href="http://118.145.16.217/magsci/article/article?id=3139950" target="_blank">Extraction Model Based on Web Format Information Quantity in Blog Post and Comment Extraction</a></div>
<div class="float_article_abs">从信息论的角度出发,提出了-个基于网页格式信息量的博客文章和评论抽取模型.首先,结合网页视觉上的位置信息和文本的有效信息来定位网页正文.其次.利用博客网页中的格式信息作为信息单元并计算每个信息块所包含的格式信息量,通过计算最小切分位置信息量来切分正丈中的文章和评论.该模型具有与语言无关的特点,因此具有-定的通用性.实验结果表明,该模型在博客正文定位和正丈切分方面达到了较高的精确率.</div>
<div>
</div>
</div>
<div id="article_reference_meta_R11_articleCitedText">
<div class="sentence">... 近些年来对于博客网页的信息抽取也逐渐成为热门的话题<sup>[<xref ref-type="bibr" rid="R8">8</xref>,<xref ref-type="bibr" rid="R9">9</xref>,<xref ref-type="bibr" rid="R10">10</xref>,<xref ref-type="bibr" rid="R11">11</xref>]</sup> ...</div>
</div>
</div>
<div id="article_reference_meta_R12">
<div id="article_reference_meta_R12_citedNumber">1</div>
<div id="article_reference_meta_R12_nian">2012</div>
<div id="article_reference_meta_R12_jcr">0.0</div>
<div id="article_reference_meta_R12_cjcr">1.13</div>
<div id="article_reference_meta_R12_articleCitedText">
<div class="sentence">... 随着网络购物的快速崛起, 对于网页商品信息抽取工作的研究<sup>[<xref ref-type="bibr" rid="R12">12</xref>,<xref ref-type="bibr" rid="R13">13</xref>,<xref ref-type="bibr" rid="R14">14</xref>]</sup>也具有了时代意义 ...</div>
</div>
</div>
<div id="article_reference_meta_R13">
<div id="article_reference_meta_R13_citedNumber">1</div>
<div id="article_reference_meta_R13_nian">2010</div>
<div id="article_reference_meta_R13_jcr">0.0</div>
<div id="article_reference_meta_R13_cjcr">0.492</div>
<div id="article_reference_meta_R13_floatContent">
<div class="float_article_cited_format">. 2010, 36(23):262-265 </div>
<div class="float_article_title"><a href="http://118.145.16.217/magsci/article/article?id=1025294" target="_blank">Automatic Extraction Method for Product Data Records</a></div>
<div class="float_article_affiliation">(1.Institute of Intelligent Information Processing and Application, Soochow University, Suzhou 215006, China;2.Jiangsu Province Support Software Engineering R&D Center for Modern Information</div>
<div class="float_article_abs">This paper proposes an automatic extraction method for Product Data Record(PDR) of list page on Ecommerce website. According to the characteristics of the product records, it calculates value for each node in the DOM tree of page by the node type information of text, image, layout and so on, classifies these nodes according to their similarity of value, and gets the final node collection which contains data record, so that the data records of the whole page are extracted. Experimental results show that the method is effective and with high efficiency.</div>
<div class="float_article_abs">提出一种针对电子商务网站商品列表页数据记录的自动抽取方法。该方法根据商品记录的特点,通过商品记录中商品的文本、图片以及布局等节点类型信息计算节点对应的值,依据节点值的相似度对节点进行分组,再从不同分组中过滤出包含数据记录节点的集合,从而抽取整个页面的数据记录。实验结果证明该方法有效且抽取效率较高。</div>
<div>
</div>
</div>
<div id="article_reference_meta_R13_articleCitedText">
<div class="sentence">... 随着网络购物的快速崛起, 对于网页商品信息抽取工作的研究<sup>[<xref ref-type="bibr" rid="R12">12</xref>,<xref ref-type="bibr" rid="R13">13</xref>,<xref ref-type="bibr" rid="R14">14</xref>]</sup>也具有了时代意义 ...</div>
</div>
</div>
<div id="article_reference_meta_R14">
<div id="article_reference_meta_R14_citedNumber">1</div>
<div id="article_reference_meta_R14_nian">2010</div>
<div id="article_reference_meta_R14_jcr">0.0</div>
<div id="article_reference_meta_R14_cjcr">0.0</div>
<div id="article_reference_meta_R14_floatContent">
<div class="float_article_cited_format">. 2010, 27(9):49-53 </div>
<div class="float_article_title"><a href="http://118.145.16.217/magsci/article/article?id=1098673" target="_blank">Extraction Algorithm of Merchandise Information on Networks Based on Structured-Semantic Entropy</a></div>
<div class="float_article_abs">目前网上销售已成为一种重要的商品销售途径,其中商品网页信息提取是商品发布信息监测、商品比价等应用的技术基础.传统的网页信息提取系统在提取这些商品信息时存在人工干预过多和提取数据的针对性不强的问题.针对商品销售网站数据的具体表现形式,提出了一种基于结构语义熵的商品信息提取算法.该算法结合了商品的语义特征和网页的结构表现形式,可以实现全自动的网页商品提取.并通过实验证明了算法的有效性,和其在网上商品销售领域的普适性.</div>
<div>
</div>
</div>
<div id="article_reference_meta_R14_articleCitedText">
<div class="sentence">... 随着网络购物的快速崛起, 对于网页商品信息抽取工作的研究<sup>[<xref ref-type="bibr" rid="R12">12</xref>,<xref ref-type="bibr" rid="R13">13</xref>,<xref ref-type="bibr" rid="R14">14</xref>]</sup>也具有了时代意义 ...</div>
</div>
</div>
<div id="article_reference_meta_R15">
<div id="article_reference_meta_R15_citedNumber">1</div>
<div id="article_reference_meta_R15_nian">2006</div>
<div id="article_reference_meta_R15_jcr">0.0</div>
<div id="article_reference_meta_R15_cjcr">0.0</div>
</div>
<div id="article_reference_meta_R16">
<div id="article_reference_meta_R16_citedNumber">1</div>
<div id="article_reference_meta_R16_nian">2012</div>
<div id="article_reference_meta_R16_jcr">0.0</div>
<div id="article_reference_meta_R16_cjcr">0.789</div>
</div>
<div id="article_reference_meta_R17">
<div id="article_reference_meta_R17_citedNumber">1</div>
<div id="article_reference_meta_R17_nian">2012</div>
<div id="article_reference_meta_R17_jcr">0.0</div>
<div id="article_reference_meta_R17_cjcr">0.492</div>
<div id="article_reference_meta_R17_floatContent">
<div class="float_article_cited_format">. 2012, 38(21):153-160 DOI:<a href="http://dx.doi.org/10.3969/j.issn.1000-3428.2012.21.041" target="_blank">10.3969/j.issn.1000-3428.2012.21.041</a></div>
<div class="float_article_title"><a href="http://118.145.16.217/magsci/article/article?id=17822375" target="_blank">Content Extraction of Uighur Web Based on Content Correlativity</a></div>
<div class="float_article_affiliation">(1. Xinjiang Technical Institute of Physics and Chemistry, Chinese Academy of Sciences, Urumqi 830011, China; 2. Graduate University of Chinese Academy of Sciences, Beijing 100049, China)</div>
<div class="float_article_abs">In addition to the main content, most Uighur Web contain noises such as navigation panels, advertisements which are not related to the main content. To improve the efficiency of security detection, this paper presents a content extraction algorithm of Uighur Web based on Web text correlativity, and designs the model of text density and content scale to improve the algorithm. Experimental result shows that this algorithm can extract the main content from the Uighur Web efficiently.</div>
<div class="float_article_abs">网页表达的主要信息通常隐藏在大量无关的结构与文字中,使正文信息不能被迅速获取,影响文本检测的效率。为此,根据维吾尔网页的非规范化编码、论坛型网页较多等特点,提出一种基于正文相关度的正文提取算法,并建立上下文正文密度和节点间正文比例等数学模型对算法进行改进。对大量维吾尔网页的实验结果表明,该算法具有较好的正文提取正确率和召回率,能够有效地从维吾尔网页中提取到所需的正文信息。</div>
<div>
</div>
</div>
</div>
<div id="article_reference_meta_R18">
<div id="article_reference_meta_R18_citedNumber">1</div>
<div id="article_reference_meta_R18_nian">2012</div>
<div id="article_reference_meta_R18_jcr">0.0</div>
<div id="article_reference_meta_R18_cjcr">0.0</div>
<div id="article_reference_meta_R18_articleCitedText">
<div class="sentence">... 此外, 对于旅游、医药、农业等领域的网页信息抽取也有部分学者分别做过相关研究工作<sup>[<xref ref-type="bibr" rid="R18">18</xref>,<xref ref-type="bibr" rid="R19">19</xref>,<xref ref-type="bibr" rid="R20">20</xref>]</sup> ...</div>
</div>
</div>
<div id="article_reference_meta_R19">
<div id="article_reference_meta_R19_citedNumber">1</div>
<div id="article_reference_meta_R19_nian">2011</div>
<div id="article_reference_meta_R19_jcr">0.0</div>
<div id="article_reference_meta_R19_cjcr">0.0</div>
<div id="article_reference_meta_R19_articleCitedText">
<div class="sentence">... 此外, 对于旅游、医药、农业等领域的网页信息抽取也有部分学者分别做过相关研究工作<sup>[<xref ref-type="bibr" rid="R18">18</xref>,<xref ref-type="bibr" rid="R19">19</xref>,<xref ref-type="bibr" rid="R20">20</xref>]</sup> ...</div>
</div>
</div>
<div id="article_reference_meta_R20">
<div id="article_reference_meta_R20_citedNumber">1</div>
<div id="article_reference_meta_R20_nian">2007</div>
<div id="article_reference_meta_R20_jcr">0.0</div>
<div id="article_reference_meta_R20_cjcr">0.0</div>
<div id="article_reference_meta_R20_articleCitedText">
<div class="sentence">... 此外, 对于旅游、医药、农业等领域的网页信息抽取也有部分学者分别做过相关研究工作<sup>[<xref ref-type="bibr" rid="R18">18</xref>,<xref ref-type="bibr" rid="R19">19</xref>,<xref ref-type="bibr" rid="R20">20</xref>]</sup> ...</div>
</div>
</div>
</div>
<div class="clear"></div>
</div>
</div>
<div class="clear"></div>
</div>
<input type="hidden" id="resourceLink" value="http://manu44.magtech.com.cn/Jwk_infotech_wk3/html_resources/"/>
<div id="title-banner" style="top: 0px;display: none;">
<div class="content">
<div class="btn-g"><span class="img"></span>
<a href="#close" class="btn-close"></a></div>
<div class="title" align="center">
图书网页的自动识别及书目信息抽取研究<sup>*</sup>
</div>
<div class="author_name_list" align="center">
[李湘东<xref ref-type="aff" rid="aff1" MTML-type="CN"><sup>1,</sup></xref><xref ref-type="aff" rid="aff2" MTML-type="CN"><sup>2</sup></xref>, 霍亚勇<xref ref-type="aff" rid="aff1" MTML-type="CN"><sup>1</sup></xref><sup><a href="mailto:413261403@qq.com"><img src="http://manu44.magtech.com.cn/Jwk_infotech_wk3/html_resources/images/REemail.gif" border=0 /></a></sup>, 黄莉<xref ref-type="aff" rid="aff1" MTML-type="CN"><sup>1</sup></xref>]
</div>
</div>
</div>
</body>
</html> 






{kind=link}