

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
SCI论文作者甄别软件设计及应用*
[于健1  , 吴霞
, 吴霞2 , 赵春梅2 ]
, 吴霞|
|


作者贡献声明:
于健: 软件功能设计实现和论文撰写;
吴霞, 赵春梅: 参与软件功能需求分析和软件测试。
【目的】结合机构产出SCI论文统计需求,设计一款自动甄别目标机构作者和实验室的软件。【应用背景】可辅助论文统计部门快速准确识别机构论文作者和实验室(部门), 进而获得机构作者和实验室的论文产出分布情况。【方法】从技术上实现综合利用相同研究单元内作者合作较多的科研特点、自定义作者唯一关键词或合作者字段以及SCI数据库作者相关字段的文本特征来甄别目标机构作者。【结果】允许用户通过目标机构人员名单维护来实现SCI论文作者甄别的自动化和高准确度。【结论】有效解决SCI论文中文作者因拼音写法多样且易重名而造成作者相关论文数据难以准确统计的问题, 其设计思路也适用于EI及其他数据库论文作者甄别。
[Objective] The software to discriminate one scientific institute’s authors of scientific papers is designed to meet demands of the statistics of papers indexed by SCI.[Context] It can be used to help the department of statistical analysis on papers in SCI to determine Chinese characters for the Chinese author name belong to their institute and its corresponding lab.[Methods] Author discrimination is implemented technically by the comprehensive utilization of one characteristics of scientific research that people from the same research units are more likely to co-author papers, custom unique keywords or co-authors and text features of author fields in SCI.[Results] Automation and high accuracy of author discrimination can be achieved based on maintenance of a personnel list of one scientific institute.[Conclusions] It effectively solves the duplication problem of Chinese names during the analysis of papers in SCI and its design ideas also apply to other databases such as EI and Inspec.
近年来, 高校和科研机构愈加重视机构产出SCI学术论文的统计管理和分析利用[ 1, 2, 3], 也有越来越多的机构为此参与建设了机构知识库等学术资产管理系统[ 4]。目前机构产出SCI论文统计服务通常有两种形式: 先由作者自行提交论文, 后由科研论文统计部门核查并汇总; 先由科研论文统计部门搜集整理论文, 后由作者确认后汇总。据一份调查结果显示, 多数科研人员都有找不到科研成果的经历[ 4], 他们为了节省时间和精力往往提交不够标准的成果数据, 因此会希望科研统计部门辅助统计其成果数据, 而他们只需从中复核挑选自己的论文。但是, 科研论文统计部门在进行SCI论文统计时常会面临一个棘手的问题: 如何甄别本机构的SCI论文作者?尤其中文作者拼音写法具有多样性, 易出现重名和引发混淆, 从而导致即便机构管理系统里存储了大批SCI论文数据却无法快速准确得到某作者或实验室(部门)的产出情况[ 5]。本文所述SCI论文作者甄别软件可通过综合利用目标机构人员名单中的作者不同拼音写法、合作者、自定义唯一关键词和合作者字段来实现目标机构作者的准确自动识别。甄别后的SCI论文数据表上传到机构知识库或者直接进行分析后, 可实现准确、快速统计目标机构作者和实验室SCI论文的产出情况[ 6]。
目前, 许多机构论文管理系统的作者识别需要在很大程度上依赖人工逐一判断确认[ 7, 8], 其中有的利用机构作者的各种拼音写法来辅助人工进行确认, 例如中国科学院IR机构知识库系统, 在一定程度上提高了论文确认工作效率。此外, 目前已有很多关于文献重名作者处理方法的研究[ 9, 10], 研究领域涉及文献检索、文献数据库等, 研究对象是海量文献的重名作者处理, 主要是基于文献的合作者关系以及文献文本属性特征(包括题名、来源出版物、主题词等)来处理重名问题, 有的也达到了较高的准确率, 但是仍无法满足知识管理领域的机构这类特定对象的论文统计准确率和灵活性的需求。
本软件的特点主要在于专门针对机构论文统计的需求, 在从微观角度深入挖掘和利用SCI数据库文献特征(包括作者全简称写法和地址字段)的基础上, 充分利用研究机构内同研究单元(同课题组或实验室)内作者合作较多的科研规律, 并且通过机构内重名作者的自定义唯一关键词或合作者来实现目标机构作者的自动和高准确率识别。
本软件设计思路是基于机构人员名单(含所属课题组和实验室)来甄别SCI论文作者, 主体结构由以下三个模块构成。
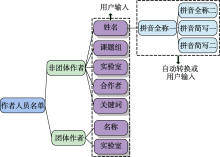
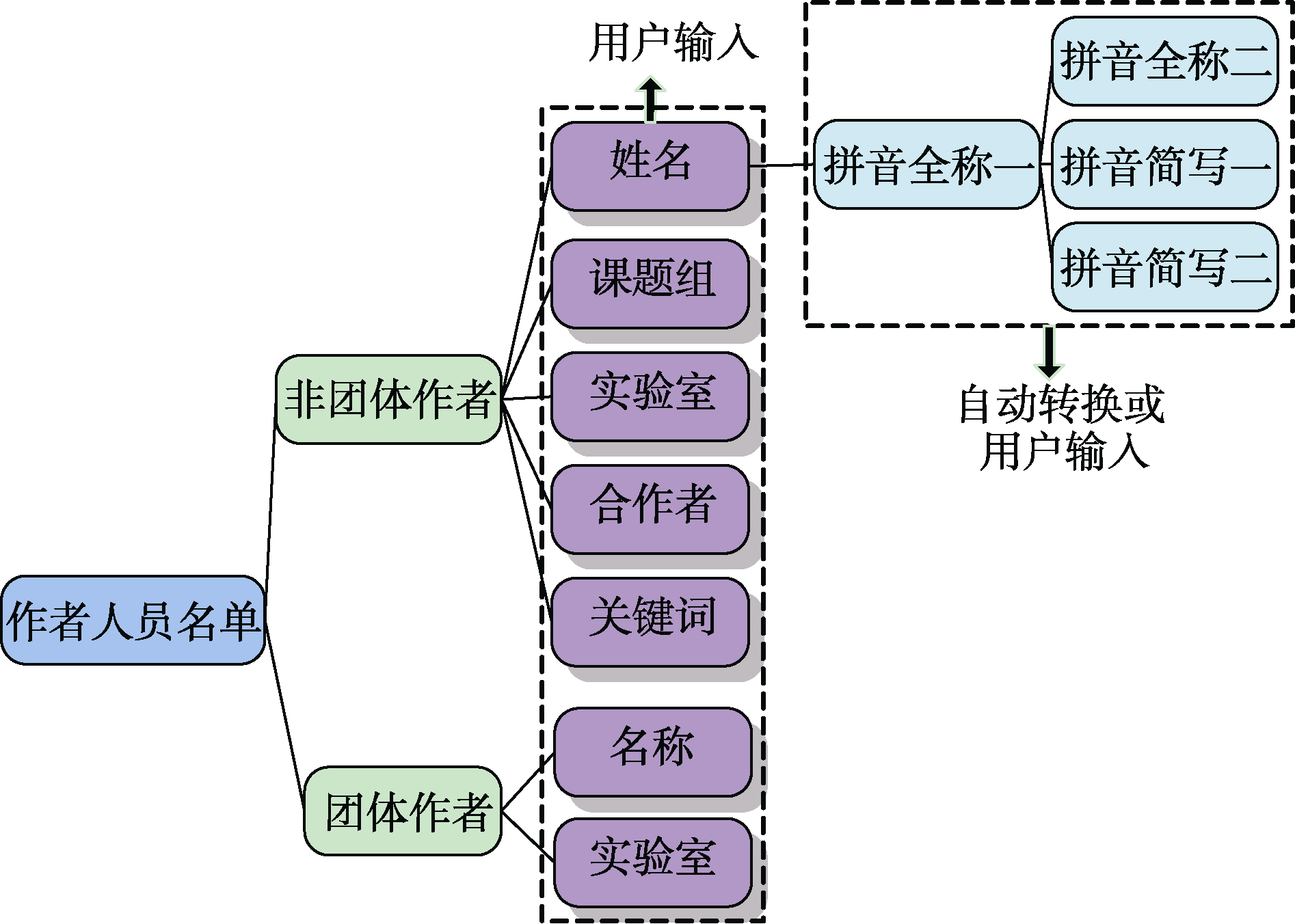
根据实际需求, 本模块考虑了团体作者和非团体作者两种不同情形, 并相应设置了两种机构人员名单所需字段, 如图1所示。
非团体作者含5个字段, 分别是汉字写法、拼音全称一(姓名所有单字以空格隔开)、拼音全称二(仅姓和名以空格隔开)、拼音简写一(姓全拼+空格+名所有单字首字母)和拼音简写二(姓全拼+空格+名首字的首字母)。
 | 图1 机构人员名单字段 |
非团体作者包含了两个附加信息字段, 即自定义唯一合作者和自定义唯一关键词字段, 帮助用户应对软件甄别结束后甄别结果中仍然存在重名作者的情况。此时, 用户需要人工甄别重名作者, 在甄别完成后, 可据此甄别经验, 在机构人员名单中自定义输入用以区分该重名作者的合作者或关键词。
本模块将首先识别SCI论文的作者是否为团体作者, 即SCI论文数据表中的字段CA是否不空。若是团体作者, 则直接进入下一个作者甄别模块; 若是非团体作者, 则首先提取目标机构全部作者并进入下一模块。
| 表1 SCI论文数据表非团体作者相关字段 |
SCI论文数据表中字段C1的格式共有两种, 如表1所示, 即作者(写法同字段AF)+作者机构或者仅作者机构。当C1字段为作者+作者机构时, 本模块将根据SCI论文数据表中的字段C1和用户从软件界面输入的目标机构名称的唯一标识词来识别并提取出作者。当C1字段只含作者机构时, 表明所有作者同属于一个机构, 本模块将根据SCI论文数据表中的字段AF和目标机构唯一标识词提取出作者。
对于团体作者论文, 本模块将根据机构人员名单中的团体作者信息字段进行甄别。对于非团体作者论文, 本模块根据机构人员名单中的人员信息字段来甄别。在完成一篇论文的所有作者甄别后, 本模块将进行该论文所属实验室的赋值, 赋值原则为首先选取第一作者的实验室为该论文所属实验室, 若第一作者实验室不存在, 则选取作者最多的实验室为该论文所属实验室。
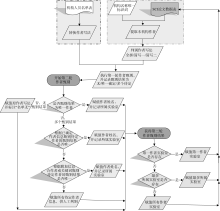
本软件是在VB 6.0环境下开发的, 完整流程从调用机构人员名单Excel文件对象和SCI论文数据表Excel对象开始, 到甄别完成后将甄别作者姓名和所属实验室值写入SCI论文数据表Excel文件对象结束, 如图2所示:
软件将用户输入人员姓名自动转换为拼音全称[ 11], 继而转换为SCI数据库中的拼音全称和拼音简写, 以作者“钱学森”为例, 作者姓名的转换过程为: “钱学森—qian xue sen—qian xuesen—qian xs—qian x”; 英文姓名全称的自动转换过程相对较为简单, 以“albert einstein”为例, 其转换过程为: “albert einstein—albert einstein—albert einstein—albert e— albert e”。
为了解决多音姓氏问题, 本软件内置了常见多音姓氏的自动转换, 包括黑/仇/区/朴/折/单/查/解/繁/缪/员/种/笮/万俟/单于/尉迟等。如果用户的机构人员名单中存在其他多音字, 则需要人工输入含多音字作者的拼音写法。
本软件通过SCI论文表中C1字段来识别目标机构作者, 因此正确提取作者的关键是解决目标机构写法的输入问题。
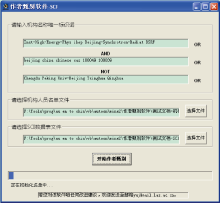
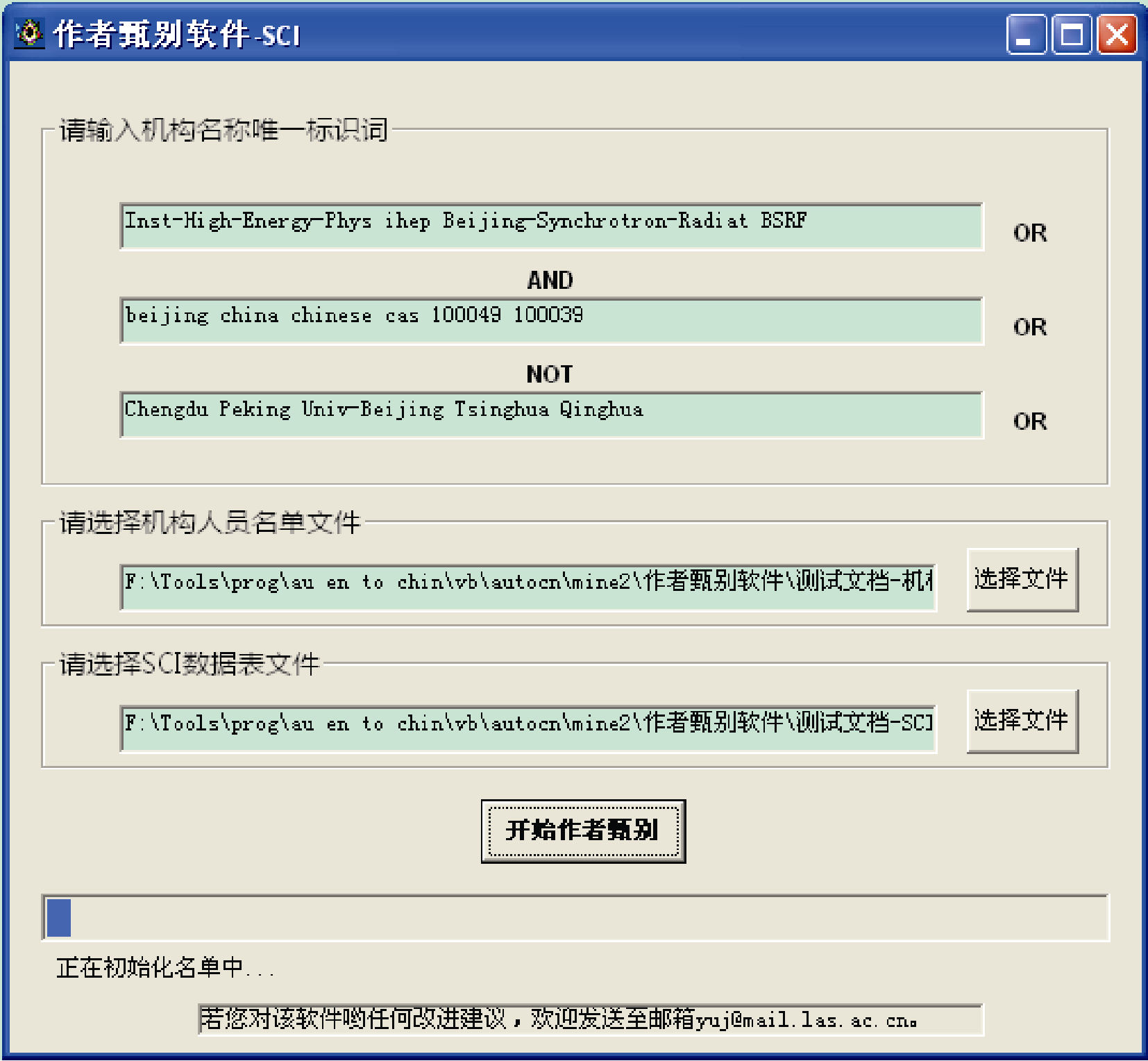
为了方便用户使用, 软件识别目标机构写法的设计思路与在SCI数据库中检索目标机构论文的方法相似。用户只需根据目标机构的地址在SCI数据库中的写法(包括机构名称、城市、国家或邮编)组合成机构唯一标识词进行输入即可。例如, 中国科学院高能物理所(简称“中科院高能所”)在SCI数据库中的通常写法为“Chinese Acad Sci, Inst High Energy Phys, Beijing 100049, Peoples R China”。根据工作经验, 除了中科院+高能所的标准写法以外, 高能所+北京或高能所+邮编(100049或100039)均大致可唯一确定为中科院高能所, 只需排除成都电子科技大学高能电子研究所、北京大学高能物理研究中心、清华大学高能物理研究中心即可; 此外, 中科院高能所内的某些实验室, 例如同步辐射实验室+北京或同步辐射实验室+邮编(100049或100039)也可唯一确定为中科院高能所, 因此在SCI数据库中检索高能所论文时, 通常会使用检索式“("Inst High Energy Phys" OR ihep OR "Beijing Synchrotron Radiat" OR BSRF) SAME (beijing OR china OR chinese OR cas OR 100039 OR 100049) NOT (Chengdu OR Peking OR "Univ Beijing" OR Tsinghua OR Qinghua) ”来进行检索。同理, 本软件允许用户在软件使用界面做类似的目标机构输入, 便可准确识别目标机构并提取作者。
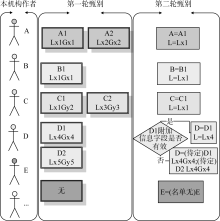
为了解决作者重名写法的问题, 软件对所提取作者进行两轮甄别, 如图3所示:
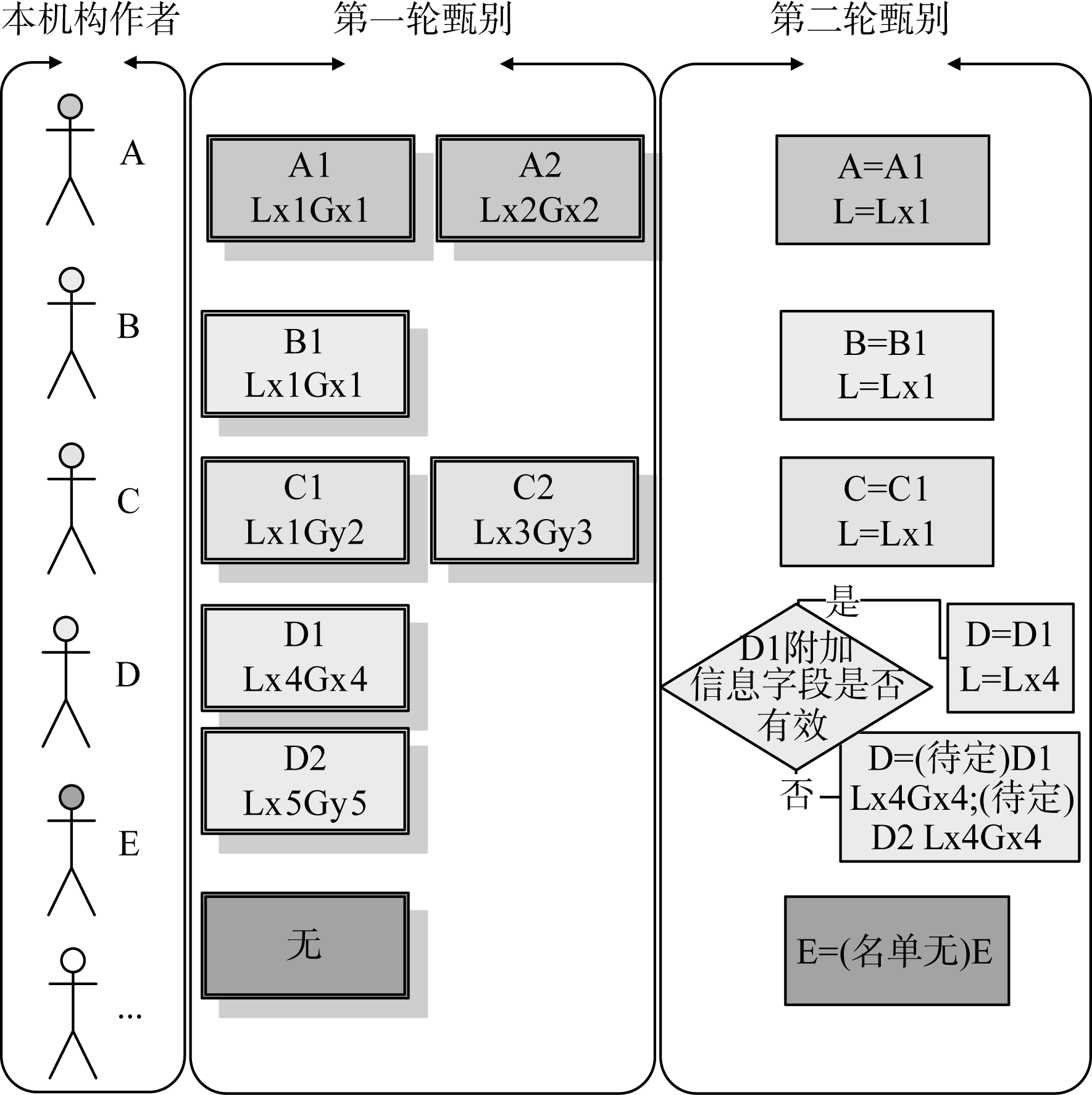 | 图3 重名作者甄别过程示例模型(注: A表示作者; L表示实验室(部门); G表示课题组) |
第一轮首先确定提取作者的拼音全称或简写, 并据此进入机构人员名单中进行甄别, 记录下每位作者的所有可能作者信息, 包括姓名、课题组和实验室。
SCI论文数据表中字段AU是SCI数据库加工人员规范化后的作者拼音简写, 字段AF是SCI论文原文中的作者写法, 可能是拼音全称或拼音简写。因此, 软件可通过对比AF和AU两个字段来判断是拼音全称(如表1中论文1所示)或是简写。若是简写, 则继续判断是拼音简写一(如表1中论文2所示)还是拼音简写二(如表1中论文3所示)。
第二轮甄别分三种情况处理: 若第一轮未甄别到任何作者信息, 则为该作者最终甄别结果赋值SCI论文中原作者写法, 并标注“名单无”; 若第一轮甄别到唯一作者, 直接赋值该作者姓名; 若第一轮甄别到多个作者, 则首先根据其合作者中已确定作者的课题组或实验室来进行甄别, 若是仍无法确定, 则根据附加信息字段自定义唯一合作者或关键词来进行甄别, 最后若仍无法确定, 则为该作者最终甄别结果赋值所有可能的作者信息, 并标注“待定”。
笔者使用该软件来测试甄别中国科学院高能物理研究所2008年-2012年发表SCI论文的作者和所属实验室。
首先使用软件包自带的Excel文件机构人员名单模板来制作一份目标机构人员名单, 如图4所示。软件所需的另外一个Excel文件SCI论文数据表可以从SCI数据库下载获取, 在SCI数据库中保存文件格式为Tab-delimited(win)并导入Excel文件即可。若已保存文件格式为Plain Text, 则需要使用SCI转换工具转换为本软件所需的Excel文件[ 12]。
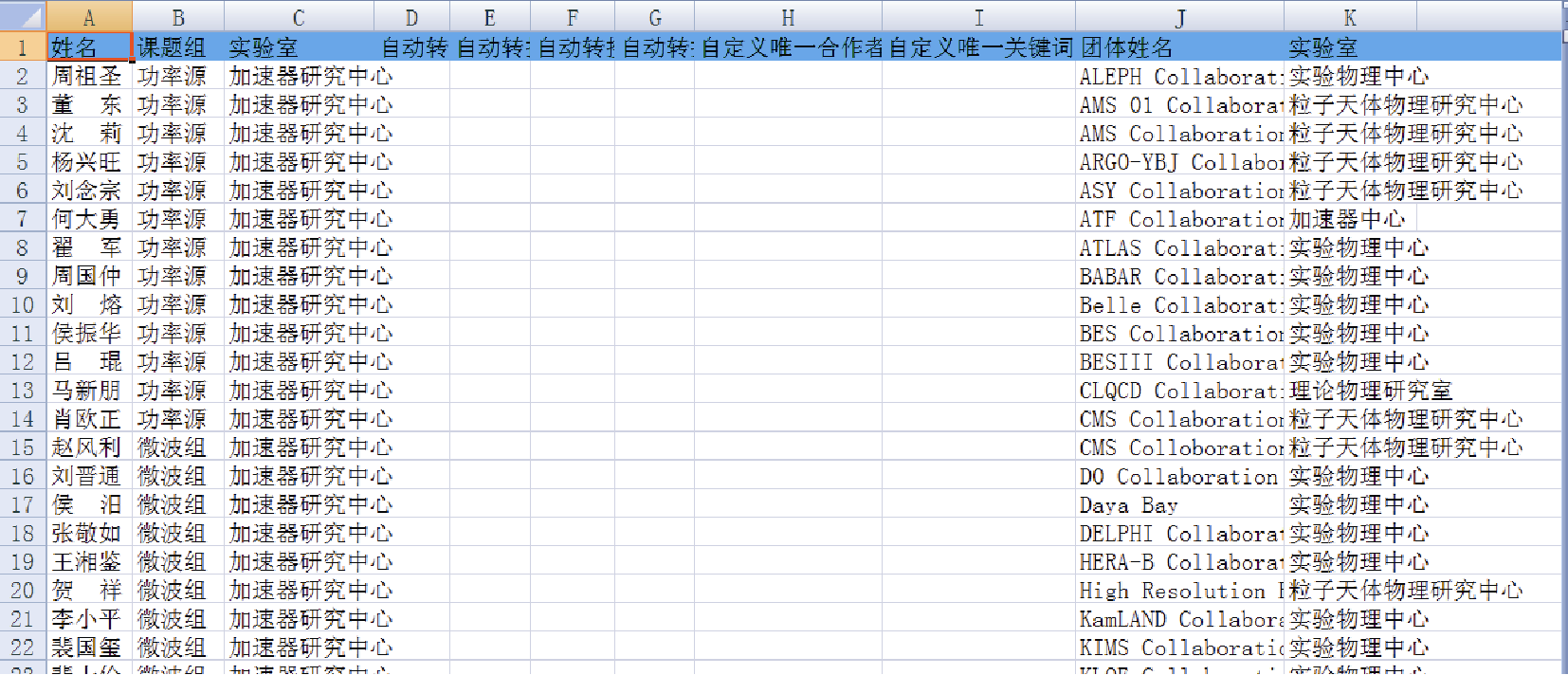 | 图4 机构人员名单 |
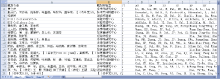
在软件界面输入中科院高能所名称的唯一标识词, 如图5所示, 并选择机构人员名单和SCI数据表Excel文件路径, 单击按钮开始作者甄别, 甄别完成以后的SCI数据表如图6所示。
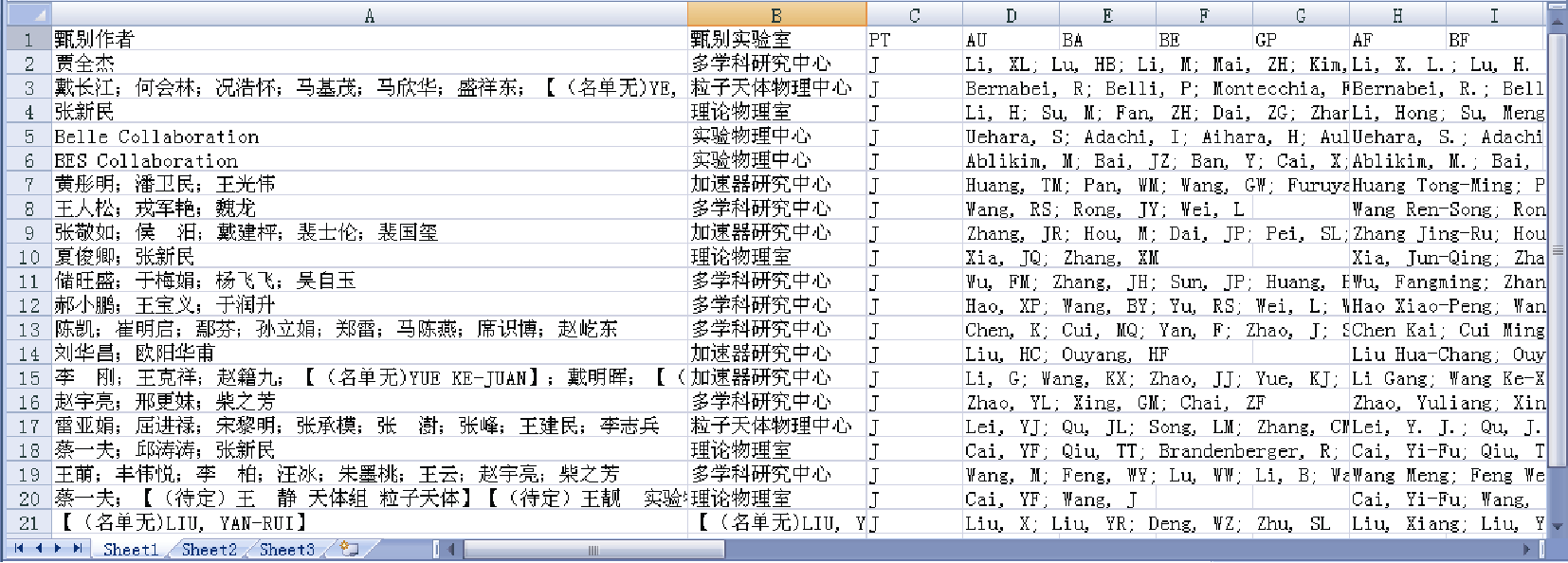 | 图6 SCI论文表甄别结果 |
从名单初始化到甄别完成测试数据表约需1分钟, 图7显示了此次测试甄别作者的结果统计情况。全部论文的作者总人次约为12 114, 作者总人数约为 2 041, 其中准确甄别到作者总人次约为10 526, 作者总人数约为1 235, 标记(名单无)的作者总人次和总人数分别约为1 190和684, 标记(待定)的作者总人次和总人数分别约为398和122。从甄别结果可以看出, 不考虑用户工作经验所积累的SCI检索式写法完整度和SCI数据库地址字段标引错误的人为因素, 本软件的甄别准确性完全取决于机构人员名单的准确性, 只要机构人员名单中已有作者信息, 软件已经全部甄别到作者和实验室; 而对于名单中缺少的作者, 软件已标记(名单无), 供用户后续核实并在机构人员名单中添加, 这样软件今后也将能够甄别到该作者。对于软件无法唯一确定的重名作者, 软件已标记(待定), 用户可以根据人工甄别经验, 在机构人员名单的自定义唯一合作者或自定义唯一关键词字段中自行输入区分这些重名作者的合作者或关键词, 这样软件以后将能够据此来区分甄别。由此可见, 随着机构人员名单的完善, 软件的识别率将不断提高, 使机构论文统计人员通过日常经验积累脱离作者识别上的繁琐人工干预工作。
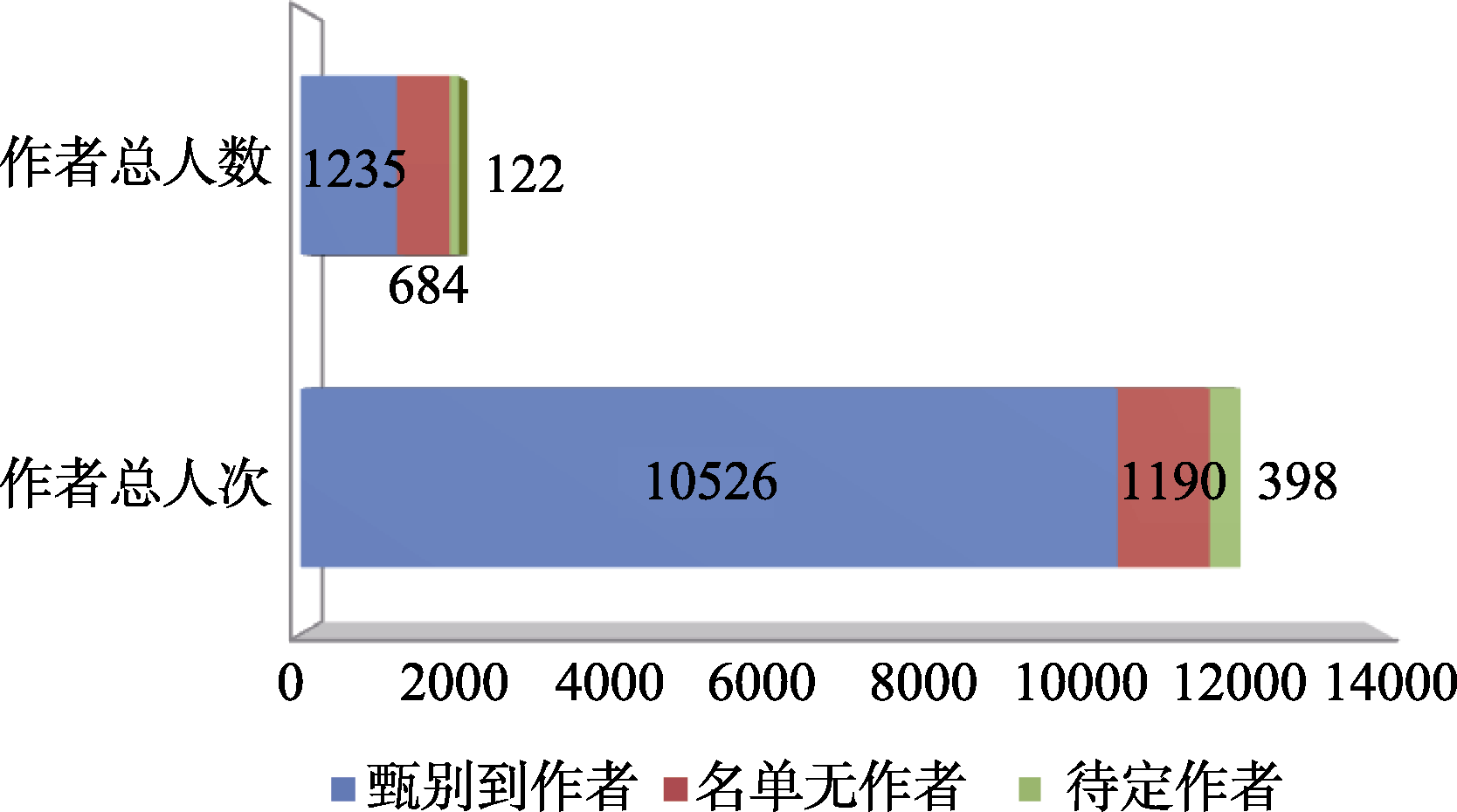 | 图7 SCI论文表的作者甄别结果统计 |
本文从实际需求出发, 开发了一款用于机构SCI论文统计服务的作者甄别软件, 以辅助提高科研论文管理效率和准确性。该软件除了实现甄别功能以外, 还可以通过人机交互和用户对机构人员名单信息的持续完善使软件甄别率不断提高。该软件在实现甄别功能的同时也具有清理机构论文数据的功能, 排除用户目标机构名称唯一标识词输入不全的因素, 提取不到目标机构作者信息的论文很可能不是目标机构所发表的论文。此外, 该软件虽然是针对SCI论文统计服务设计的, 但是也可直接应用于论文数据字段格式相同的WOS其他数据库(如CPCI)的论文统计, 其设计思路也同样适用于EI或其他数据库。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|