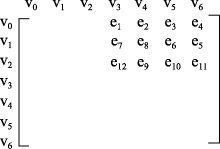

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Web生活服务信息的组织与可视化研究*
引用本文
夏立新, 蔡昕, 石义金, 孙丹霞, 王忠义. Web生活服务信息的组织与可视化研究* . 现代图书情报技术, 2014, 30(4): 85-92
Xia Lixin, Cai Xin, Shi Yijin, Sun Danxia, Wang Zhongyi. Organization and Visualization of Web Life Service Information Research. New technology of library and information service, 2014, 30(4): 85-92
Permissions
Xia Lixin, Cai Xin, Shi Yijin, Sun Danxia, Wang Zhongyi. Organization and Visualization of Web Life Service Information Research. New technology of library and information service, 2014, 30(4): 85-92
Copyright©2014, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
Web生活服务信息的组织与可视化研究*
作者贡献声明:
夏立新: 提出研究方向与方法;
蔡昕: 设计研究方案;
石义金: 实证设计与实证实践;
孙丹霞: 论文起草及论文修订;
王忠义: 论文最终版本修订。
摘要
【目的】降低用户获取Web生活服务信息的细节觉察成本和决策成本。【应用背景】Web环境下的生活服务信息, 需要结合用户的情景, 帮助用户快速获取信息。【方法】分析总结4种常见的用户需求, 结合出行链理论和信息可视化技术中的Bertin编码原则, 基于加权图的性质设计算法, 进行Web生活服务信息可视化。【结果】以团购类Web生活服务信息为例, 对该交互原型设计进行实现。【结论】验证Web生活服务信息可视化可以帮助用户快速建立心理定位。
关键词:
信息可视化; Bertin编码原则; Web生活服务信息; 加权图
中图分类号:G252 文章编号:2014-4-85-92
文献标志码:分类号: G252 文章编号:2014-4-85-92
文章编号:2014-4-85-92
Organization and Visualization of Web Life Service Information Research
Abstract
[Objective] Reduce the costs of detail perceived and decision-making of users to get Web life service information. [Context] Life service information based on the Web environment need to combine the users’ situation that help the users get information quickly.[Methods] This paper summarizes four kinds of ordinary requirements of users, which refer to the trip chain theory and Bertin coding principle in information visualization technology and base on the nature of weighted graph to design the algorithm, and implement the information visualization of Web life service.[Results] Taking the Web life service information in group buying for example, this paper realizes the interactive prototype.[Conclusions] It is verified that the Web life service information visualization can help users create psychological orientation quickly.
Keyword:
Information visualization; Bertin coding principle; Web life service information; Weighted graph
1 引言
随着互联网的快速发展, Web生活服务类信息已逐步渗透到人类的生活中并急剧膨胀。为避免人们陷入“信息超载”的困境, 多种信息组织方式被应用到对生活服务类信息的组织中。具体来说, 主要包括基于分类和基于位置两种方式。分类是组织与揭示网络信息资源的重要方法[ 1], 但当信息数量较大时, 这种传统条目信息展示方式, 会消耗用户庞大的细节察觉成本, 费时又费力。由于人类80%的活动均与空间位置相关[ 2], 人类习惯从自身所处位置出发思考问题, 与附近的人和事物产生关系的可能性更大[ 3], 于是基于位置的组织方式颇受青睐。它通过地标建筑或行政区域, 为用户组织信息。然而, 由于行政区域的不规则性和空间的方向性, 这种方法难以为用户构建与目标距离的心理定位。
实验心理学家赤瑞特拉(Treicher)通过大量实验证实, 人类获取的信息83%来自视觉[ 4]。可见, 用户更易通过视觉感知获取信息。1989年, Robertson、Card与Mackinlay首次提出“信息可视化”这一术语[ 5]。信息可视化是充分利用人们对可视模式快速识别的自然能力将数据信息和知识转化为一种视觉形式的过程[ 6]。通过此过程, 可以帮助人们在短时间内直观地获取大量信息[ 7], 其不仅在揭示信息资源的广度与深度上有很大的优势, 而且它能够将隐藏在信息资源内部的、复杂的、抽象的语义以直观的图形方式呈现给读者[ 8]。
因此, 本文为了协助用户快速构建Web生活服务信息心理认知, 辅助用户信息决策, 首先从用户角度出发, 以用户需求为中心, 分析总结了用户的需求; 然后对Web生活服务信息的组织设计算法; 最后结合分类和基于位置的优势, 采用可视化技术, 设计了一个Web生活服务信息可视化交互原型, 并以团购类Web生活服务信息为例, 对该原型进行实证。
2 Web生活服务信息的用户需求分析
根据用户需求的特点, 本文分析总结了4种常见的用户需求: 单用户单信息需求、单用户多信息需求、多用户单信息需求、多用户多信息需求。
2.1 单用户单信息需求
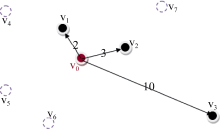
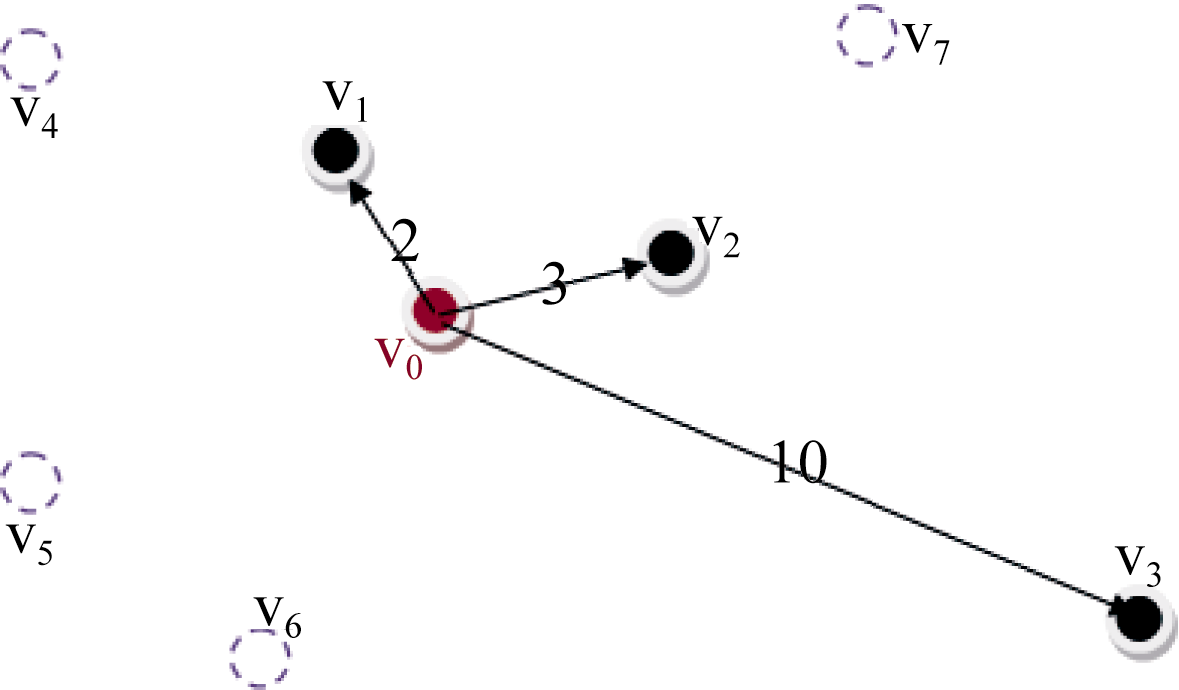
单用户单信息需求是所有方式中最简单的, 涉及的用户只有一个, 信息需求只有一种。以看电影为例, 用户只存在看电影一种信息需求, 最终只会选择前往一个电影院, 所以用户只要一种信息中的其中一条。如图1所示, 用户v0会在v1、v2、v3中选择一个前往。
 | 图1 单用户单信息需求模式 |
2.2 单用户多信息需求
单用户多信息需求, 涉及的用户只有一个, 而信息需求有两种或两种以上。以企业年会为例, 假设用户先需要到餐馆聚餐, 接着需要到会议室聚会, 最后要回到酒店住宿, 此时信息需求存在顺序决策的问题, 如图2所示。由于用户在做出前一种需求信息的选择之后, 其位置会随之改变, 因此后一种信息需求选择会受到前一种信息需求选择的影响。
 | 图2 单用户多信息需求模式 |
该情况下可采用两种方式为用户提供需求信息: 组合式和向导式。
(1) 组合式: 将用户所需求信息进行组合, 然后进行距离求和, 最后将特定组合信息排序, 序化后提供给用户。
(2) 向导式: 按用户需求顺序来提供信息, 一步步的引导, 做前一种信息需求决策时不考虑后一种信息需求的干扰。用户以前一信息决策为起点, 重新考虑后一信息决策, 直至完成所有决策。
2.3 多用户单信息需求
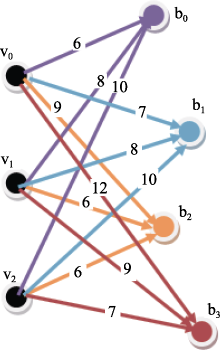
多用户的单信息需求, 涉及用户有两个或两个以上, 但信息需求只有一种。以聚餐为例, 三个不在同一位置的用户想要在其附近的某家餐厅组织一次聚餐, 如图3所示, 三用户v0、v1、v2要聚餐, 有b0、b1、b2、b3等4个候选餐厅。此时, 需要考虑多个位置点, 综合多个用户的位置来组织Web生活服务信息。
 | 图3 多用户单信息需求模式 |
2.4 多用户多信息需求
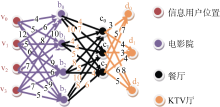
多用户多信息需求, 涉及用户有两个或两个以上, 信息需求也有两种或两种以上, 且多用户具有同顺序的信息需求。以朋友聚会为例, 多用户先要看电影, 接着需要就餐, 最后去KTV。此时不仅要考虑多个位置点, 还需要考虑后一种信息需求对前一种信息需求的影响, 必须综合多个用户的位置和多种信息需求来组织Web生活服务信息, 如图4所示:
 | 图4 多用户多信息需求模式 |
该需求模式的信息组织方式跟单用户多信息需求模式的一样, 也可采用组合式和向导式两种方式, 实现方法非常类似, 只存在所涉及用户数量的差异。
3 Web生活服务信息的用户需求加权图 描述和组织算法
Web生活服务信息的用户需求可以采用加权图来描述, 并可以根据加权图的结构, 为Web生活服务信息的组织设计算法。
3.1 基于加权图的用户需求描述
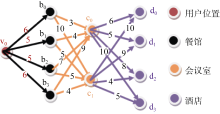
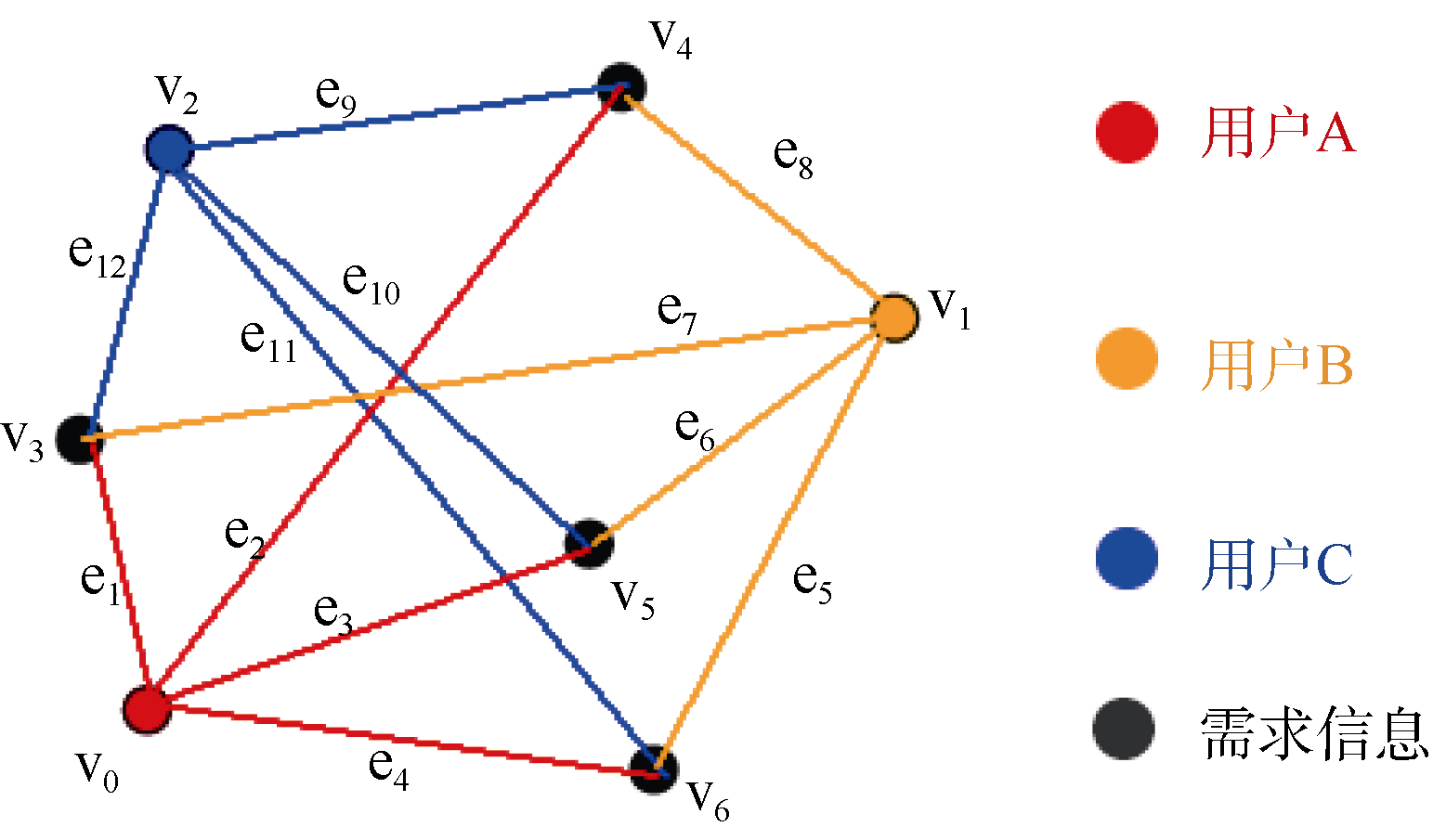
Web生活服务信息的用户需求可以采用加权图来描述, 用户位置和Web生活服务信息的位置用点集合V表示, 用户与需求的Web生活服务信息用有向边集合E表示, 用户的位置与Web生活服务信息的位置的距离用边集合E上的权值表示, 那么用户与Web生活服务信息的关系就可以用加权有向图G(V,E)表示[ 9], 而用户的位置到需求的Web生活服务信息的位置可以用路集合P来表示。对路集合P的序化过程, 即对Web生活服务信息的组织过程。如图5所示:
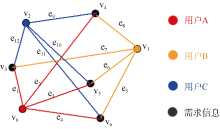
 | 图5 用户与Web生活服务信息关系 |
其中, v0、v1、v2为用户的位置, v3、v4、v5、v6为生活服务信息的位置, 其中e1、e2、e3、e4、e5、e6、e7、e8、e9、e10、e11、e12表示用户与用户需求的信息相对距离。有向加权图可以采用矩阵来表示, 换言之, 用户与Web生活服务信息的关系也可以用矩阵来表示, 如图6所示。用户与Web生活服务信息的关系运算转化为矩阵运算。
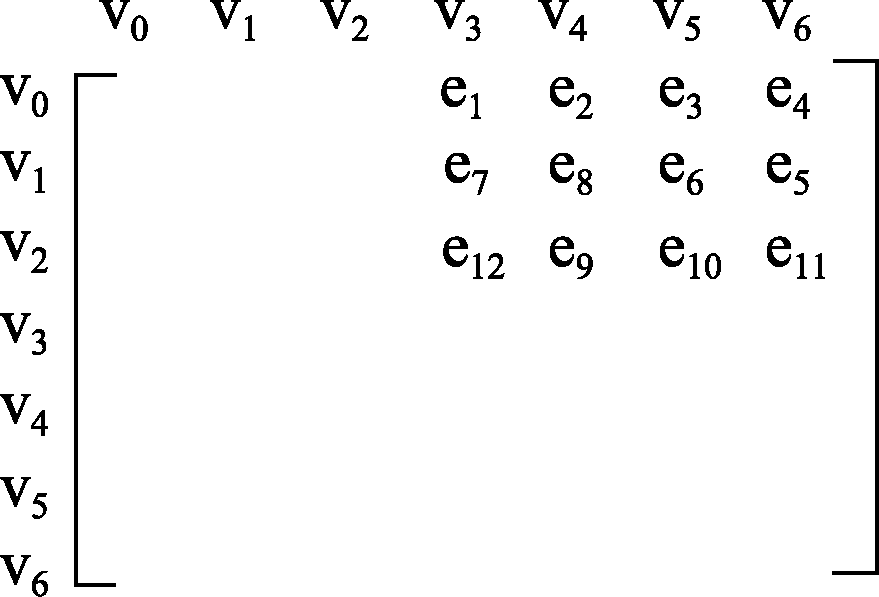 | 图6 有向加权图的矩阵描述 |
3.2 Web生活服务信息组织的算法
Dijkstra算法[ 9]、Prim算法[ 9]、Kruskal算法[ 9]等都是图中常用到的求路径的算法。在众多的路径搜索算法中, Dijkstra算法提供了从图的一个节点到另一个节点的最短路径, 经过一次Dijkstra算法计算, 可以得到从起点到图内被其搜索到的所有节点的最短路径, 其时间复杂度为o(n2)(其中n为图的节点数)[ 10], 适宜于解决单源最短路径问题, 即从图中某个源点到图中其
余各顶点的最短路径。然而, 由于Dijkstra算法立足于单源, 当涉及多用户时并不适用, 需要重新设计算法。因此, 本文根据加权图的相关性质, 设计了多用户多信息需求模式的算法。单用户是多用户的特例, 单需求也是多需求的特例, 所以适合多用户多信息需求模式的算法同样适用于单用户单需求的模式。
该多用户多信息需求模式的算法, 可以归纳为一种已知起点和已知终点的排列组合, 先遍历这些组合的起点与终点的所有路径, 然后对这些路径进行排序, 最后生成用户与需求信息之间相对距离和的序列, 辅助用户决策。
(1) 算法描述及关键代码
①设计边数据结构, 边包含有三个属性, 边的起点和终点与权重。
//定义边为对象, 有三个属性, 边的起点, 边的终点, 权重
edge = function (begin,end,length){
this.begin=begin;
this.end=end;
this.length=length; }
edge.prototype={
begin:"", //边的起点
end:"",//边的终点
length:0//权重 }
②设计递归函数, 包含两个参数, 一个是以边的起点为索引建立的存储边的数组, 另一个为边的起点。递归的条件是边的终点是否为叶子, 通过递归调用可以遍历符合条件的路经过的边以及边的权重和。
functiongetDistance(arrayEdge,b){
//根据边的索引, 遍历边
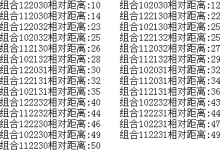
for(vari=0;i var edge1=arrayEdge[b][i]; //判断该边的终点是否为叶子节点 if(arrayEdge[edge1.end]==undefined){ var index = s+""+edge1.end;//计算路经过的顶点组合 distance[index] = d+edge1.length;//计算路经过的边的权 重和 result[count++] = index;//存储组合序号 }else{ s = s+edge1.end;//添加路经过的当前顶点 d = d+edge1.length;//添加路经过的当前边的权重和 getDistance(arrayEdge,edge1.end);//递归调用, 遍历所有符合条件的路 d = d-edge1.length;//去掉路经过的当前顶点 s = s.substring(0,s.length-2);//去掉路经过的当前边的权 重和}}} ③输入多组位置信息, 其中第一组为用户位置坐标, 其他组为需求信息位置坐标, 每组位置信息用“|”隔开, 每组中每条需求信息用空格隔开, X轴坐标和Y轴坐标用“, ”隔开。 ④先根据“|”切分出每组位置信息, 再根据空格切分出每组中每条位置信息, 最后根据“,”切分出每条需求信息的X轴和Y轴坐标。 //位置信息[其中第一组为用户位置信息, 其他组为需求信息位置信息] functiongetInfonn(a){....... //计算每个完全二分子图中, 边的距离 for(var m =1;m var pbj1 = pbGroup[m].split(" ");//完全二分子图, 第一组顶点 var pbj2 = pbGroup[m-1].split(" "); //完全二分子图, 第二组顶点 for(vari =0;i for(var j =0;j //根据两点间的距离计算公式, 计算 两点的距离 vardd = Math.sqrt((x0-x)*(x0-x)+(y0-y)* (y0-y)); var edge1 = new edge((m-1)+""+i,m+""+j,dd);//创建边信息 arrayEdge[(m-1)+""+i][j]=edge1;//以边的起点为索引, 记录边信息}}} //分别计算所有信息用户到第一种需求信息的相对距离和 ...... //采用递归的方法, 遍历所有符合条件的路分别所经过的边的权重和 ..... //冒泡排序算法, 可以根据需要更换其他排序算法 ....... //输出 ...... } (2) 算法验证及运行结果 ①本文根据算法描述, 采用JavaScript运行算法实现。为了对算法进行验证, 假设用户坐标分别为(4,3)、(3,4)、(1,0), 第一需求信息坐标为(2,1)、(1,2)、(3,3), 第二需求信息坐标为(5,1)、(11,2)、(23,3), 第三需求信息坐标为(3,1)、(15,20)、(13,13)。运行算法, 代码如下: getInfonn("4,3 3,4 1,0|2,1 1,2 3,3|5,1 11,2 23,3|3,1 15,20 13,13"); ②运行结果如图7所示。
4 Web生活服务信息可视化交互原型及实证
Web信息可视化不仅吻合人类的信息感知模式, 而且降低用户认知成本, 因此, 本文根据Card等[ 11]提出的信息可视化的一个简单参考模型, 采用Bertin编码规则[ 12]作为信息可视化编码规则, 设计了Web生活服务信息可视化交互平台, 并以团购类Web生活服务信息为例进行实证。
4.1 可视化交互原型设计
本文所设计的可视化交互原型从以往的以信息结构为主导地位的信息可视化方式向以用户为中心迁移, 更注重用户需求、用户兴趣、用户体验、用户认知。以现有的信息可视化参考模型[ 11]为基础, 将出行链理论[ 13, 14]和Web生活服务信息的组织集成到Web生活服务信息可视化中, 并结合Bertin编码规则[ 12], 为Web生活服务信息可视化提供了方向。它既汲取了信息可视化的优势, 促进用户对Web生活服务信息的认知, 又融入了Web生活服务信息的用户的需求模式, 增强了用户在交互过程中的重要程度, 从而保障了该设计可以为用户提供更好的信息决策辅助, 提高了用户获取信息的效率。具体设计如下:
(1) 布局设计: 原型采用上左右式布局, 上部分为交互选择区, 左边为用户输入区和备选项区, 右边为电子地图标注区(见图8);
(2) 功能设计: 包括电子地图、信息标注、交互式选择、信息过滤、备选项设置、信息备选项排序、信息备选项对比、细节查看和多用户模式等功能(见图8);
(3) 编码设计: 位置信息采用地图标注、相对距离通过绘制圆形表示, 分类采用不同形状表示, 价格高低采用颜色深浅表示, 评价好坏采用图中黑点密度表示;
(4) 交互设计: 用户点击交互选择区的形状和表示价格深浅的图形, 电子地图标注区根据用户的选择, 显示形状和价格深浅对应的信息; 用户点击电子地图区的地图, 可以根据用户需要进行放大和缩小; 用户点击电子地图中的标注, 可以显示该信息具体价格、图片、位置文字等和用户添加为备选项的按钮; 点击用于添加备选项的添加按钮后, 该信息将被添加到左边的备选项区, 用户可以在该区域执行排序、删除等操作; 在用户输入区, 用户可以设置期望的距离半径和用户所处的位置(见图8);
(5) 服务设计: 提供服务接口、按钮和链接, 方便用户选择信息后, 将其发送到邮箱, 或分享给好友, 或通过SNS网站分享, 或生成二维码格式用于扫描。
4.2 以团购类Web生活服务信息为例实证
为了对该基于相对位置的Web生活服务信息组织方式的应用可行性进行验证, 本文以团购类生活服务信息为实验数据进行了相关实证。团购类信息作为最受大众欢迎的Web生活服务信息之一, 也是用户获取Web生活服务信息的重要渠道。截至2013年6月底, 我国团购网民数为1.01亿, 使用率提升至17.1%, 较 2012年底提升2.3个百分点。与2012年12月底相比, 团购网民规模增长了 21.2%, 依然保持着相对较高的增长率[ 15]。因而, 选择团购类生活服务信息作为实验数据, 具有一定的代表性。
具体来说, 主要选择了美团网、拉手网、糯米网等几个团购网站, 从其网站开放API中获取团购信息, 并存储到数据库中。然后分别以单用户和多用户参与的效果截图。
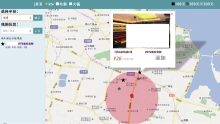
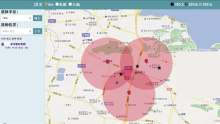
(1) 单用户获取KTV团购信息的结果, 如图8所示:
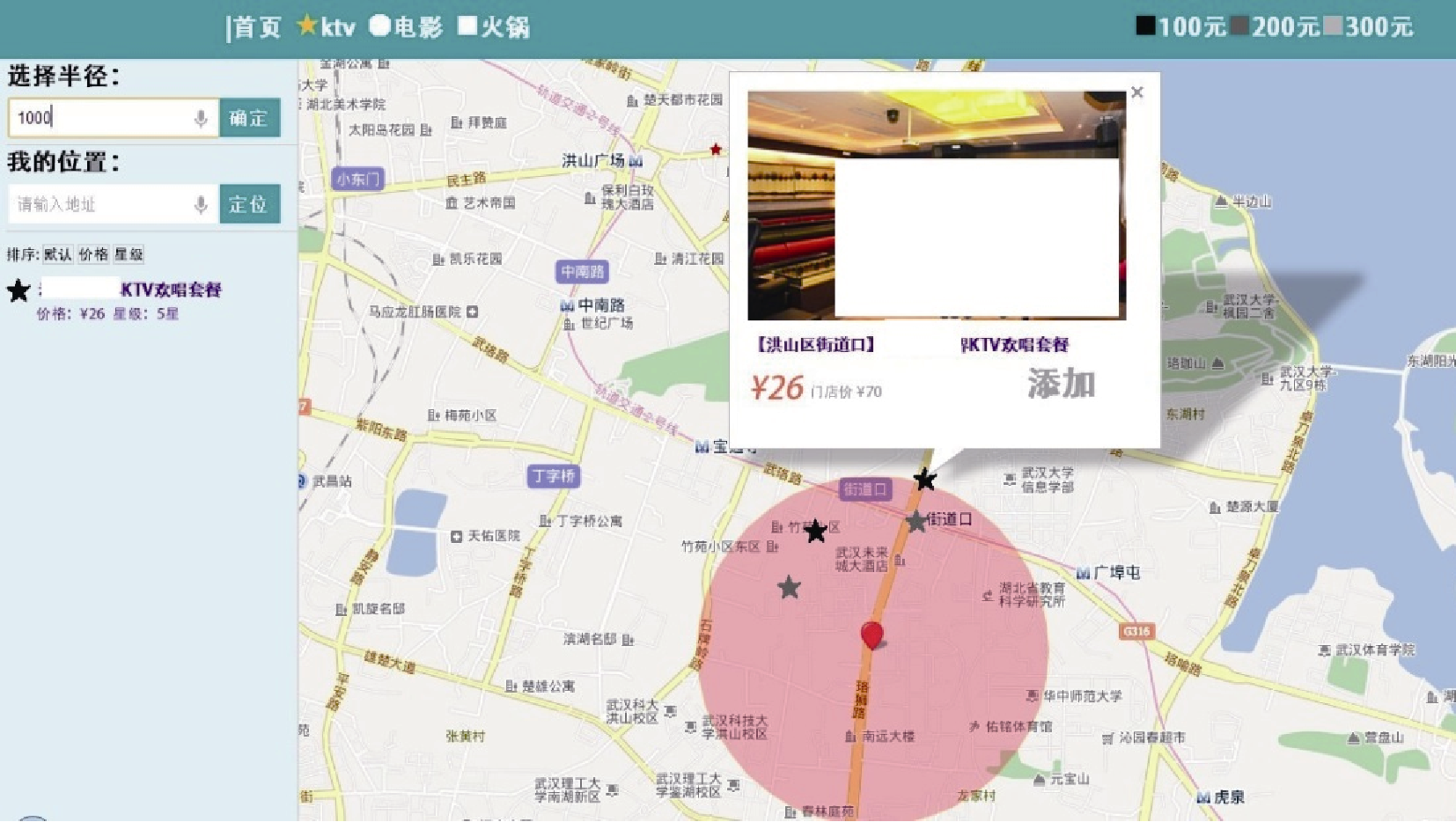 | 图8 单用户的获取KTV团购的信息可视化截图 |
红色图标标注用户位置, 且期望获取距离1 000米内的信息; 半透明区域是以用户位置为圆心, 1 000米为半径的圆; 在圆内和圆周边显示了满足需求的所有KTV团购信息, 并通过颜色深浅显示KTV的价位。用户点击标注KTV的五角星形状, 可显示其所有细节信息, 点击“添加”按钮, 可将其添加到备选项中。
(2) 多用户获取KTV团购信息, 如图9所示:
 | 图9 多用户的获取KTV团购的信息可视化截图 |
红色图标标注三个用户位置, 且他们均期望获取距离1 000米内的信息; 三个半透明区域是分别为以三个用户位置为圆心, 1 000米为半径的圆; 三个圆之间有重叠, 落在重叠区域内的是符合期望信息, 在重叠区域外的为不符合期望的信息, 在重叠区域边缘是敏感信息。同样, 颜色的深浅显示KTV的价位, 用户可点击五角星查看其细节, 并将其添加到备选项中。
5 结 语
为方便用户快捷高效地获取贴近实际需求的信息, 提高用户获取信息的效率, 降低用户决策难度, 本文从用户角度出发, 分析总结了Web生活服务信息的用户的4种常见需求, 进一步采用加权图对其进行描述, 并对Web生活服务信息的组织设计了算法。此外, 还采用信息可视化的编码原则, 借鉴信息可视化参考模型, 设计了一个Web生活服务信息可视化交互原型, 并以团购类生活服务信息为例, 对原型进行了实现。该原型的优势体现在以下三点: 符合出行链理论, 能辅助用户优化出行决策; 基于相对位置的信息组织方式, 从用户角度出发定位, 符合用户获取信息的心理认知; 可视化交互展示, 不仅提高了用户的参与度与主动选择能力, 改善了用户获取信息的体验, 而且一目了然的标注降低了用户选择的难度, 同时提供了敏感度信息、备选项信息排序与筛选, 方便用户做二次选择, 降低时间成本。但该原型仍有部分细节需要优化, 如用户界面的美观性、色彩的搭配等, 在今后的深入探索中, 还需要做出更大的努力, 以满足实际生产环境的应用要求。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|