{kind=link}
{kind=link}
典籍英译作者身份识别研究
[祁瑞华1  , 霍跃红
, 霍跃红2 , 郭旭1 , 刘彩虹1 ]
, 霍跃红|
|


作者贡献声明:
祁瑞华: 提出研究思路, 设计研究方案, 论文起草和最终版本修订;
霍跃红: 设计研究方案, 调查、采集和分析数据;
郭旭: 数据清洗和分析;
刘彩虹: 论文最终版本修订。
【目的】分析典籍英译作者身份识别的关键问题, 提出不完整数据作者身份识别的有效方法。【方法】针对诗词典籍篇幅短小和语料不平衡的特点, 建立基于词汇、句子和语篇层面的文体特征向量空间模型, 提出用于不完整数据作者身份识别的加权朴素信念分类算法。【结果】加权朴素信念分类算法可以有效改善朴素信念分类算法性能, 与目前主流分类算法对比实验表明其在不完整数据集上具有很好的综合性能。【局限】需进一步扩展数据集的样本数量和作者数量, 在大数据集上提高文体特征提取效率和作者身份识别的准确性。【结论】提出的多层面文体特征模型和加权朴素信念分类算法在诗词典籍英译作品集上具有较好的准确性和应用性。
[Objective] This paper analyzes the key issues of the authorship indentification in English translations of Chinese classics and proposes the effective way to identify the authorship of incomplete data.[Methods] Based on the stylistic features composed of vocabulary level, sentence level and discourse level, the stylistic feature vector space model for poetry translation texts is established. From the angle of the characteristics of imbalance poetry corpus, the Weighted Naïve Credal Classifier is proposed.[Results] The output of the contrast experiments verifies the effectiveness of the Weighted Naïve Credal Classifier.[Limitations] The size of the data set and the number of the authors should be further expanded, so that the efficiency and the accuracy of authorship identification on large data sets can be improved.[Conclusions] The method proposed in this paper has good accuracy and applicability on poetry translation collections.
典籍是一个国家的重要文献、典册和书籍, 是文化遗产精华传承和弘扬的重要载体。典籍英译是传承和弘扬中国传统文化、促进中外文化交流的重要途径。典籍英译作品的作者身份识别在对外作品推荐、匿名文本鉴定等方面具有重要的意义。布封和斯皮彻等人认为, 文体实际上是一种个人的行为方式, 作家在写作行为中会自觉或不自觉地将其个性和个人社会背景融入或体现于作品中[1]。作者身份识别正是基于这一理论, 以文本分类视角根据匿名文本的内容自动确定其作者归属的映射过程, 属于模式分类和自然语言处理的交叉学科。
本文选择典籍英译诗歌作品作为研究对象, 与其他文本分类问题相比较, 典籍英译诗歌作品具有文本短小、数据不完整、特征稀疏以及高维特征空间等特点, 因此本文侧重基于不完整数据分类算法开展作者身份识别研究。
作者身份识别研究中有两个关键问题: 文体特征选择和作者身份识别算法。文体特征是能有效识别作者身份的独特文档属性和写作风格, 传统基于统计的特征包括字、词、短语、语句、N元组等, 下面从语料角度, 分别综述英文、中文和诗词文体特征研究现状:
(1) 英文作者身份识别主要代表性研究有: Gamon[2]使用浅层和深层语言分析组成的多层面特征集, 对勃朗特三姐妹英语作品的作者识别实验准确率有了较大提高; Abbasi等[3]证实了段落数、段落长度、字符格式和空格缩格等结构特征的作用; Baayen等[4]建立基于重写规则频率语法标注语料, 比传统的基于词的分析方法获得更高的识别率。
(2) 中文作者身份识别比较经典的是针对《红楼梦》作者身份的研究, 如陈炳藻[5]基于词汇统计, 李贤平[6]基于47个虚字的频率得出前80回和后40回语言风格存在明显差异的结论; 施建军[7]采用支持向量机算法, 以44个文言虚字频率分析《红楼梦》写作风格差异, 证明了机器学习方法和文言虚字文体特征对于古典文学作者身份识别的有效性。此外, 吕英杰等[8]探索性地提出从用户生成内容抽取词汇特征、句法特征、结构特征和内容特征能有效识别BBS论坛和博客文本作者写作风格。
(3) 诗词方面, 吴春龙等[9]提出频繁关键字共现的概念提高了宋词风格分类的准确率; 易勇[10]采用以“ 字” 为最小结构单位的计算机辅助研究, 通过层次聚类法揭示了豪放词和婉约词用字风格特点, 取得了88.5%的正确率。
从作者身份识别算法的角度, 相关研究主要采用的算法有: 基于概率模型的朴素贝叶斯及其改进算法、基于向量空间模型的判别分析方法、支持向量机、决策树、神经网络和遗传算法以及基于相似度度量的最近邻法等。例如, Zhao等[11]以美联社TREC语料库中7位作者的文章功能词作为特征, 分别采用贝叶斯网络、朴素贝叶斯、最近邻法、K最近邻法和决策树算法识别作者身份, 实验表明贝叶斯分类最有效, 而决策树效率最低; 针对中文近现代小说语料数据稀疏问题, 张全等[12]引入分层网络概念克服数据稀疏, 通过混合句类分解降低句类向量维度, 证实了最近邻算法在此特征集上的有效性; 针对数据不完整问题, 雷蕾等[13]分析了各种分类器在不完整数据上的灵敏度, 当数据集含有超过20%的缺失数据项时, 预测准确率将明显下降。国内外学者基于决策树、神经网络、贝叶斯网络和最近邻法提出了多种不完整数据的处理方法, 其中Zaffalon[14]提出的朴素信念分类算法突破了数据随机缺失假设的限制, 有效提高了不完整数据集分类效率和正确率。
综上所述, 现有研究为典籍英译诗歌作品作者身份识别奠定了坚实的基础, 但是仍然存在一些问题:
(1) 典籍诗歌文本内容精炼内聚, 具有短文本的特殊性, 采用传统的特征表示将造成部分数据缺失或数据稀疏, 需要结合多层面文体特征, 抽取更具有表现和刻画能力的文体特征向量空间模型;
(2) 这些缺失的特征包含着很多隐含信息, 现有算法不能充分利用这些隐含信息, 导致作者身份识别准确率明显下降, 因此亟需能够处理不完整数据的作者身份识别算法。
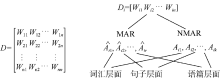
作者身份识别基于文本中隐含着作者无意识的写作风格的假设, 文体特征就是对这些隐含写作风格的量化。本文基于主题无关的准则, 建立多层面文体特征向量模型。由于研究的对象是古诗译文, 文章篇幅较短, 并非所有特征都能够提取有效的统计结果, 因此提取的特征集是不完整的数据集。造成数据集不完整的原因可以分为随机缺失过程MAR和非随机缺失过程NMAR。对于文本数据集D中的每一篇文档Di, 分别从词汇、句子和语篇层面抽取文体特征组成n维向量 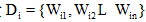
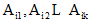
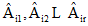
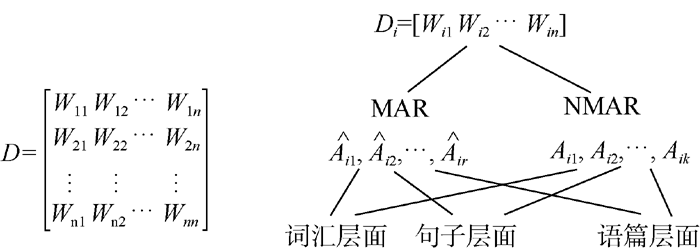 | 图1 文体特征向量空间模型 |
(1) 词汇层面特征包括: 缩略语出现的频率, 体现作者使用语言时力求经济、简便的自然心理趋势; 自造词数量, 典籍翻译是文学二次创作的过程, 自造词既反映了作家语言习惯和对语言的审美追求, 又体现其对表达效果和读者接受的考虑; 感叹词数量, 体现译者翻译过程中的感情色彩; 词汇密度, 即实词/虚词比, 词汇密度大意味着实义词的比重大、篇幅简练, 能够使用更少的词汇表达得更准确完整, 反之则功能词比重偏大, 结构清晰易懂, 但有文本冗余; 类符形符比, 类符是文本中不同的词语, 形符是所有的词形, 类符形符比值反映了不同词汇量的大小; 平均单词长度, 英文作品中单词越简短, 难度就越低。
(2) 句子层面特征包括: 人称代词频率, 上下文的指代和衔接可以反映文本明确程度, 即译者是遵循汉语言习惯还是增加指代清晰度; 平均句长, 体现对原文信息的传达特点, 如果短句出现的频率高则意味着作者尽量保持诗词原文的表达风格, 如果长句出现的频率高意味着作者倾向于在原文基础上补充信息; 倒装结构, 体现译者为体现诗歌音韵美或突出强调某个词的创作习惯。
(3) 语篇层面特征包括: 标点符号, 中国古典诗歌很少有标点符号, 而从语法和文体学角度, 标点符号可以反映译者翻译的文体习惯和倾向性, 同时也反映了隐性衔接手段的运用习惯。通常如果译文中分号使用频繁则倾向于接近目标语言文化, 如果译文中使用句号、问号、感叹号和逗号较多则倾向于汉语习惯; 衔接词That, 汉语没有从句概念, 衔接词That的频率能反映译者是倾向于原文的语法和行文习惯还是倾向于英语的语法规则; 显性衔接词, 汉语本身作为意合语言, 对上下文句子的前后衔接关注较少, 而英语为形合语言, 对词之间和句子之间的衔接非常注重。因此, 显性连接词的出现频率可反映对源语文化和目的语文化的关注程度。在显性衔接词的提取中笔者分别统计以下几类: 并列连词and, or, but的频率; 因果连词because, since, for的频率; 转折连词though, although, as though的频率; 时间连词when, while, until, before, after, as的频率; 假设连词if, as if的频率。
作者身份识别本质上是分类问题, 从机器学习的角度作者身份识别可以看作多类别、单标签文本分类任务。分类任务的一个重要问题是缺失数据的处理, 在此笔者提出不完整数据集的加权朴素信念分类算法, 应用于典籍英译作品作者身份识别。
令 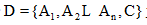
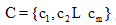
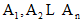
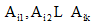
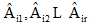
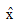
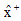
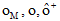
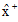
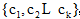
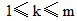
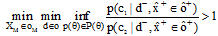 |
笔者在公式(1)中引入特征Ai的权值wi, 利用相关系数来表示数据集中各个特征变量与类变量之间的直线关系和密切程度。设训练集样本的特征为 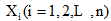
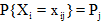
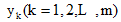
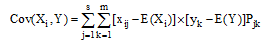 |
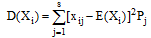 |
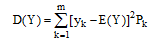 |
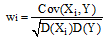 |
令c为类别, aij为第i个实例的第j个特征值, 根据贝叶斯定理有公式(6), 将公式(6)代入公式(1), 引入特征权值, 得到公式(7)中成对比较类取值的加权保守推理规则, 如果成立, 则称类c1优于类c1, 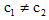
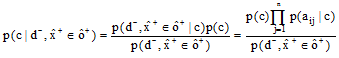 |
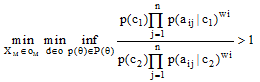 |
加权朴素信念分类主要过程分为: 数据预处理、学习过程和分类过程。数据预处理过程的任务包括: 样本数据特征属性离散化、确定样本数据Non-MAR属性和MAR属性。学习过程和分类过程算法如下:
(1) 加权朴素信念学习算法
WeightedNaï veCredalClassifier_training(training_set, NMAR_features, MAR_features, C)
//输入: 训练集training_set, NMAR特征集NMAR_features, MAR特征集MAR_features, 类别集C
{计算各特征变量和类别变量之间的协方差和方差;
计算各特征变量的权值列表;
foreach (feature f_mar in MAR_features )
//受MAR过程影响的特征
foreach (class c in C)
{计算各类别出现的次数 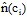
计算类别与各特征值的联合概率分布 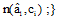
foreach (feature f_nmar in NMAR_features )
//受NMAR过程影响的特征
foreach (class c in C)
{计算各类别出现的次数n(ci);
计算类别与各特征值的联合概率分布的上界 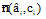
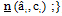
(2) 加权朴素信念分类算法
WeightedNaï veCredalClassifier(testing_set, NMAR_features,
MAR_features, C)
//输入: 测试集testing_set, NMAR属性集NMAR_features,
MAR属性集MAR_features, 类别集C
{ foreach (instance x in tesing_set
{ NonDominatedClasses [ ] =C
//设置优势类集合为待分类样本所有可能分类结果
foreach (class c1 in C)
//对于优势类集合中的每一个类别c1, 与优势类集合中的其他类别基于加权保守推理规则进行优势比较
if c2 is dominated by c1
Drop c2 from NonDominatedClasses;
//如果c1优于c2, 则从优势类集合中删除c2
output NonDominatedClasses;
//返回优势类集合, 即当前样本的分类结果}}
本文选择国内外三位在典籍英译领域有重要影响的作者: 汪榕培、许渊冲和James Legge的692篇中国古典诗歌英译作品, 共万余行诗句作为语料, 三位作者作品数量基本相当, 属于平衡语料。在数据预处理阶段, 首先完成文档的采集、整理统一文本格式、去除文本中诗歌题目、作者信息和注释等数据预处理工作。
由于研究的对象是古诗译文, 文章篇幅较短, 并非所有特征都能够提取有效的统计结果, 因此提取的特征集是不完整的数据集, 具体缺失情况如表1所示:
| 表1 特征选取及缺失比例 |
数据集共有19个特征, 其中15个特征有不同程度的缺失, 占总特征数78.95%, 各个特征的平均缺失比例为58.4%, 缺失情况严重的特征的缺失比例达90%以上。
现有典籍英译作品数据集决策类数为3, 各类样本数分布较平均, 属于平衡数据集。为提高数据集文体风格分类知识挖掘的效率, 分别基于信息增益和χ 2统计量进行特征选择, 观察到两种特征选择方法得到的结果一致, 最终保留词汇密度、类符形符比、平均单词长度、平均句长、倒装、感叹号、句号、分号、衔接词That和并列连词形成新的文体特征集, 其中仍然有6个特征缺失比例从2.96%到82.4%不等, 平均缺失比例为41.13%。
(1) 为验证多层面特征的有效性, 以词汇层面特征作为基准特征集采用加权朴素信念分类模型进行作者身份识别实验, 在此基础上依次增加句子层面和语篇层面特征, 分别得到不同特征组合的作者身份识别实验结果, 分析增加特征层面是否有助于提高分类正确率。
(2) 为验证本文提出的加权朴素信念分类模型在典籍英译作品不完整数据集上的有效性, 选择朴素贝叶斯、支持向量机、最近邻法、朴素信念分类和本文提出的加权朴素信念分类算法共5种分类算法进行作者身份识别对比实验, 实验平台为Weka3.5.8[15], 实验中训练集和测试集的划分采用十折交叉验证, 所有实验程序均在相同的机器配置下运行。作者身份识别属于多类别分类问题, 实验结果采用分类问题通用的评价指标, 包括查全率、查准率、F1测量值, 以及算法预测结果的总体宏平均、微平均和分类正确率。
分别从文体特征向量空间模型的特征选择和作者身份识别分类算法两方面对本文提出的典籍英译作品作者身份识别方法进行评价。
(1) 特征选择方法评价
多层面特征对照实验结果如表2所示:
| 表2 多层面特征对照实验结果 |
可以看到在不同特征组合对照实验结果中, 随着特征层面的增加, 作者身份识别的正确率有明显增长, 当同时使用词汇层面、句子层面和语篇层面特征时, 正确率达到最高值, 说明本文建立的典籍英译作者身份识别文体特征向量空间模型的各个层面特征在分类过程中均具有有效区分的作用。此外, 不同层面特征组合的对照实验中, 分类正确率的标准差值维持较低数值, 说明分类正确率在十折交叉验证中具有良好的稳定性。
(2) 作者身份识别分类算法评价
朴素贝叶斯(NBC)、支持向量机(SMO)、最近邻法(IBK)、朴素信念分类(Naï ve Credal Classifier2, NCC2)和加权朴素信念分类(Weighted Naï ve Credal Classifier, WNCC) 5种分类算法的作者身份识别对比实验结果如表3和图2所示:
| 表3 加权朴素信念分类与对照算法实验结果 |
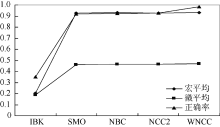
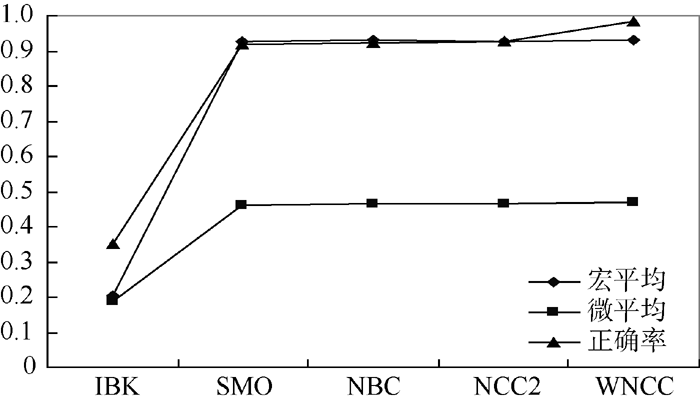 | 图2 加权朴素信念分类与对照算法实验结果 |
从表3和图2可以看出5种分类算法中, SMO、NBC、NCC2和WNCC算法在作者身份识别数据集上的综合性能比较好。其中:
①从查全率来看, WNCC在两个类别上获得最高的查全率, 说明作者身份识别正确样本数与这两个类别应有的样本数的比例最高; 而在第三个类别上WNCC的查全率不理想, 分析其原因是WNCC对不完整数据分类需要维护一个类别集合, 如果不能在这个集合中确定最具优势的类别, WNCC就无法给出明确的分类预测, 导致有些样本得不到明确的分类结果;
②从查准率来看, WNCC在三个类别上都达到最高的查准率, 即在各个类别的样本上WNCC都具有最高的准确率, 其原因在于, 相对于其他算法简单丢弃缺失数据, 朴素信念分类算法能够充分挖掘缺失数据中的隐含信息, WNCC又进一步量化了特征对分类预测的影响权重;
③F1测试值是对查全率和查准率的综合评价, 是分类性能的重要指标, WNCC在两个类别上得到了最高F1测试值, 在第三个类别上的F1测试值位居第4, 原因是受到在这一类别查全率不高的影响, 这是WNCC考虑所有缺失数据可能性的代价;
④从分类结果的宏平均和微平均来看, SMO、NBC和NCC2的宏平均和微平均分别稳定在0.927和0.465上下; WNCC的宏平均为0.931, 是5种算法中的最高值, 与NCC2相当, 说明WNCC和NCC2算法在所有类别作者身份识别的正确率算术平均值最高; WNCC的微平均高于SMO、NBC和NCC2, 达到最高值0.468, 说明WNCC算法在每一个类别上取得了最高的作者身份识别正确率算术平均值。综合来看, WNCC无论是在各个类别还是所有类别上均具有最好的分类性能;
⑤从分类的正确率来看, WNCC的分类正确率为0.982, 是5种分类算法中的最高值, 说明WNCC在所有样本上对作者归属的预测正确率最高。
综上所述, 5种算法中WNCC在典籍英译语料上具有最高的宏平均、微平均和分类正确率, 证明了引入特征权重能有效改善朴素信念分类算法性能, 从现有指标观察, 加权朴素信念分类是典籍英译语料上综合性能最好的分类算法。
本文基于典籍英译诗词作品词汇层面、句子层面和语篇层面文体特征分析, 针对诗词典籍的短文本不完整数据集的特点, 采用权重量化不完整数据中属性变量与类别之间的相关程度, 提出加权朴素信念不完整数据分类算法应用于作者身份识别。通过与现有主要分类算法的对比实验表明, 本文方法在诗词典籍英译作品集上具有较好的准确性和应用性。今后的工作将进一步扩展数据集的样本数量和作者数量, 在大数据集上提高文本特征提取效率和作者身份识别的准确性, 完善典籍英译作者身份识别技术框架。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|